Performance considerations for EF 4, 5, and 6
By David Obando, Eric Dettinger and others
Published: April 2012
Last updated: May 2014
1. Introduction
Object-Relational Mapping frameworks are a convenient way to provide an abstraction for data access in an object-oriented application. For .NET applications, Microsoft's recommended O/RM is Entity Framework. With any abstraction though, performance can become a concern.
This whitepaper was written to show the performance considerations when developing applications using Entity Framework, to give developers an idea of the Entity Framework internal algorithms that can affect performance, and to provide tips for investigation and improving performance in their applications that use Entity Framework. There are a number of good topics on performance already available on the web, and we've also tried pointing to these resources where possible.
Performance is a tricky topic. This whitepaper is intended as a resource to help you make performance related decisions for your applications that use Entity Framework. We have included some test metrics to demonstrate performance, but these metrics aren't intended as absolute indicators of the performance you will see in your application.
For practical purposes, this document assumes Entity Framework 4 is run under .NET 4.0 and Entity Framework 5 and 6 are run under .NET 4.5. Many of the performance improvements made for Entity Framework 5 reside within the core components that ship with .NET 4.5.
Entity Framework 6 is an out of band release and does not depend on the Entity Framework components that ship with .NET. Entity Framework 6 work on both .NET 4.0 and .NET 4.5, and can offer a big performance benefit to those who haven’t upgraded from .NET 4.0 but want the latest Entity Framework bits in their application. When this document mentions Entity Framework 6, it refers to the latest version available at the time of this writing: version 6.1.0.
2. Cold vs. Warm Query Execution
The very first time any query is made against a given model, the Entity Framework does a lot of work behind the scenes to load and validate the model. We frequently refer to this first query as a "cold" query. Further queries against an already loaded model are known as "warm" queries, and are much faster.
Let’s take a high-level view of where time is spent when executing a query using Entity Framework, and see where things are improving in Entity Framework 6.
First Query Execution – cold query
| Code User Writes | Action | EF4 Performance Impact | EF5 Performance Impact | EF6 Performance Impact |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Context creation | Medium | Medium | Low |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Query expression creation | Low | Low | Low |
var c1 = q1.First(); |
LINQ query execution | - Metadata loading: High but cached - View generation: Potentially very high but cached - Parameter evaluation: Medium - Query translation: Medium - Materializer generation: Medium but cached - Database query execution: Potentially high + Connection.Open + Command.ExecuteReader + DataReader.Read Object materialization: Medium - Identity lookup: Medium |
- Metadata loading: High but cached - View generation: Potentially very high but cached - Parameter evaluation: Low - Query translation: Medium but cached - Materializer generation: Medium but cached - Database query execution: Potentially high (Better queries in some situations) + Connection.Open + Command.ExecuteReader + DataReader.Read Object materialization: Medium - Identity lookup: Medium |
- Metadata loading: High but cached - View generation: Medium but cached - Parameter evaluation: Low - Query translation: Medium but cached - Materializer generation: Medium but cached - Database query execution: Potentially high (Better queries in some situations) + Connection.Open + Command.ExecuteReader + DataReader.Read Object materialization: Medium (Faster than EF5) - Identity lookup: Medium |
} |
Connection.Close | Low | Low | Low |
Second Query Execution – warm query
| Code User Writes | Action | EF4 Performance Impact | EF5 Performance Impact | EF6 Performance Impact |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Context creation | Medium | Medium | Low |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Query expression creation | Low | Low | Low |
var c1 = q1.First(); |
LINQ query execution | - Metadata - View - Parameter evaluation: Medium - Query - Materializer - Database query execution: Potentially high + Connection.Open + Command.ExecuteReader + DataReader.Read Object materialization: Medium - Identity lookup: Medium |
- Metadata - View - Parameter evaluation: Low - Query - Materializer - Database query execution: Potentially high (Better queries in some situations) + Connection.Open + Command.ExecuteReader + DataReader.Read Object materialization: Medium - Identity lookup: Medium |
- Metadata - View - Parameter evaluation: Low - Query - Materializer - Database query execution: Potentially high (Better queries in some situations) + Connection.Open + Command.ExecuteReader + DataReader.Read Object materialization: Medium (Faster than EF5) - Identity lookup: Medium |
} |
Connection.Close | Low | Low | Low |
There are several ways to reduce the performance cost of both cold and warm queries, and we'll take a look at these in the following section. Specifically, we'll look at reducing the cost of model loading in cold queries by using pre-generated views, which should help alleviate performance pains experienced during view generation. For warm queries, we'll cover query plan caching, no tracking queries, and different query execution options.
2.1 What is View Generation?
In order to understand what view generation is, we must first understand what “Mapping Views” are. Mapping Views are executable representations of the transformations specified in the mapping for each entity set and association. Internally, these mapping views take the shape of CQTs (canonical query trees). There are two types of mapping views:
- Query views: these represent the transformation necessary to go from the database schema to the conceptual model.
- Update views: these represent the transformation necessary to go from the conceptual model to the database schema.
Keep in mind that the conceptual model might differ from the database schema in various ways. For example, one single table might be used to store the data for two different entity types. Inheritance and non-trivial mappings play a role in the complexity of the mapping views.
The process of computing these views based on the specification of the mapping is what we call view generation. View generation can either take place dynamically when a model is loaded, or at build time, by using "pre-generated views"; the latter are serialized in the form of Entity SQL statements to a C# or VB file.
When views are generated, they are also validated. From a performance standpoint, the vast majority of the cost of view generation is actually the validation of the views which ensures that the connections between the entities make sense and have the correct cardinality for all the supported operations.
When a query over an entity set is executed, the query is combined with the corresponding query view, and the result of this composition is run through the plan compiler to create the representation of the query that the backing store can understand. For SQL Server, the final result of this compilation will be a T-SQL SELECT statement. The first time an update over an entity set is performed, the update view is run through a similar process to transform it into DML statements for the target database.
2.2 Factors that affect View Generation performance
The performance of view generation step not only depends on the size of your model but also on how interconnected the model is. If two Entities are connected via an inheritance chain or an Association, they are said to be connected. Similarly if two tables are connected via a foreign key, they are connected. As the number of connected Entities and tables in your schemas increase, the view generation cost increases.
The algorithm that we use to generate and validate views is exponential in the worst case, though we do use some optimizations to improve this. The biggest factors that seem to negatively affect performance are:
- Model size, referring to the number of entities and the amount of associations between these entities.
- Model complexity, specifically inheritance involving a large number of types.
- Using Independent Associations, instead of Foreign Key Associations.
For small, simple models the cost may be small enough to not bother using pre-generated views. As model size and complexity increase, there are several options available to reduce the cost of view generation and validation.
2.3 Using Pre-Generated Views to decrease model load time
For detailed information on how to use pre-generated views on Entity Framework 6 visit Pre-Generated Mapping Views
2.3.1 Pre-Generated views using the Entity Framework Power Tools Community Edition
You can use the Entity Framework 6 Power Tools Community Edition to generate views of EDMX and Code First models by right-clicking the model class file and using the Entity Framework menu to select “Generate Views”. The Entity Framework Power Tools Community Edition work only on DbContext-derived contexts.
2.3.2 How to use Pre-generated views with a model created by EDMGen
EDMGen is a utility that ships with .NET and works with Entity Framework 4 and 5, but not with Entity Framework 6. EDMGen allows you to generate a model file, the object layer and the views from the command line. One of the outputs will be a Views file in your language of choice, VB or C#. This is a code file containing Entity SQL snippets for each entity set. To enable pre-generated views, you simply include the file in your project.
If you manually make edits to the schema files for the model, you will need to re-generate the views file. You can do this by running EDMGen with the /mode:ViewGeneration flag.
2.3.3 How to use Pre-Generated Views with an EDMX file
You can also use EDMGen to generate views for an EDMX file - the previously referenced MSDN topic describes how to add a pre-build event to do this - but this is complicated and there are some cases where it isn't possible. It's generally easier to use a T4 template to generate the views when your model is in an edmx file.
The ADO.NET team blog has a post that describes how to use a T4 template for view generation ( <https://learn.microsoft.com/archive/blogs/adonet/how-to-use-a-t4-template-for-view-generation>). This post includes a template that can be downloaded and added to your project. The template was written for the first version of Entity Framework, so they aren’t guaranteed to work with the latest versions of Entity Framework. However, you can download a more up-to-date set of view generation templates for Entity Framework 4 and 5from the Visual Studio Gallery:
- VB.NET: <http://visualstudiogallery.msdn.microsoft.com/118b44f2-1b91-4de2-a584-7a680418941d>
- C#: <http://visualstudiogallery.msdn.microsoft.com/ae7730ce-ddab-470f-8456-1b313cd2c44d>
If you’re using Entity Framework 6 you can get the view generation T4 templates from the Visual Studio Gallery at <http://visualstudiogallery.msdn.microsoft.com/18a7db90-6705-4d19-9dd1-0a6c23d0751f>.
2.4 Reducing the cost of view generation
Using pre-generated views moves the cost of view generation from model loading (run time) to design time. While this improves startup performance at runtime, you will still experience the pain of view generation while you are developing. There are several additional tricks that can help reduce the cost of view generation, both at compile time and run time.
2.4.1 Using Foreign Key Associations to reduce view generation cost
We have seen a number of cases where switching the associations in the model from Independent Associations to Foreign Key Associations dramatically improved the time spent in view generation.
To demonstrate this improvement, we generated two versions of the Navision model by using EDMGen. Note: see appendix C for a description of the Navision model. The Navision model is interesting for this exercise due to its very large amount of entities and relationships between them.
One version of this very large model was generated with Foreign Keys Associations and the other was generated with Independent Associations. We then timed how long it took to generate the views for each model. Entity Framework 5 test used the GenerateViews() method from class EntityViewGenerator to generate the views, while the Entity Framework 6 test used the GenerateViews() method from class StorageMappingItemCollection. This due to code restructuring that occurred in the Entity Framework 6 codebase.
Using Entity Framework 5, view generation for the model with Foreign Keys took 65 minutes in a lab machine. It's unknown how long it would have taken to generate the views for the model that used independent associations. We left the test running for over a month before the machine was rebooted in our lab to install monthly updates.
Using Entity Framework 6, view generation for the model with Foreign Keys took 28 seconds in the same lab machine. View generation for the model that uses Independent Associations took 58 seconds. The improvements done to Entity Framework 6 on its view generation code mean that many projects won’t need pre-generated views to obtain faster startup times.
It’s important to remark that pre-generating views in Entity Framework 4 and 5 can be done with EDMGen or the Entity Framework Power Tools. For Entity Framework 6 view generation can be done via the Entity Framework Power Tools or programmatically as described in Pre-Generated Mapping Views.
2.4.1.1 How to use Foreign Keys instead of Independent Associations
When using EDMGen or the Entity Designer in Visual Studio, you get FKs by default, and it only takes a single checkbox or command line flag to switch between FKs and IAs.
If you have a large Code First model, using Independent Associations will have the same effect on view generation. You can avoid this impact by including Foreign Key properties on the classes for your dependent objects, though some developers will consider this to be polluting their object model. You can find more information on this subject in <http://blog.oneunicorn.com/2011/12/11/whats-the-deal-with-mapping-foreign-keys-using-the-entity-framework/>.
| When using | Do this |
|---|---|
| Entity Designer | After adding an association between two entities, make sure you have a referential constraint. Referential constraints tell Entity Framework to use Foreign Keys instead of Independent Associations. For additional details visit <https://learn.microsoft.com/archive/blogs/efdesign/foreign-keys-in-the-entity-framework>. |
| EDMGen | When using EDMGen to generate your files from the database, your Foreign Keys will be respected and added to the model as such. For more information on the different options exposed by EDMGen visit http://msdn.microsoft.com/library/bb387165.aspx. |
| Code First | See the "Relationship Convention" section of the Code First Conventions topic for information on how to include foreign key properties on dependent objects when using Code First. |
2.4.2 Moving your model to a separate assembly
When your model is included directly in your application's project and you generate views through a pre-build event or a T4 template, view generation and validation will take place whenever the project is rebuilt, even if the model wasn't changed. If you move the model to a separate assembly and reference it from your application's project, you can make other changes to your application without needing to rebuild the project containing the model.
Note: when moving your model to separate assemblies remember to copy the connection strings for the model into the application configuration file of the client project.
2.4.3 Disable validation of an edmx-based model
EDMX models are validated at compile time, even if the model is unchanged. If your model has already been validated, you can suppress validation at compile time by setting the "Validate on Build" property to false in the properties window. When you change your mapping or model, you can temporarily re-enable validation to verify your changes.
Note that performance improvements were made to the Entity Framework Designer for Entity Framework 6, and the cost of the “Validate on Build” is much lower than in previous versions of the designer.
3 Caching in the Entity Framework
Entity Framework has the following forms of caching built-in:
- Object caching – the ObjectStateManager built into an ObjectContext instance keeps track in memory of the objects that have been retrieved using that instance. This is also known as first-level cache.
- Query Plan Caching - reusing the generated store command when a query is executed more than once.
- Metadata caching - sharing the metadata for a model across different connections to the same model.
Besides the caches that EF provides out of the box, a special kind of ADO.NET data provider known as a wrapping provider can also be used to extend Entity Framework with a cache for the results retrieved from the database, also known as second-level caching.
3.1 Object Caching
By default when an entity is returned in the results of a query, just before EF materializes it, the ObjectContext will check if an entity with the same key has already been loaded into its ObjectStateManager. If an entity with the same keys is already present EF will include it in the results of the query. Although EF will still issue the query against the database, this behavior can bypass much of the cost of materializing the entity multiple times.
3.1.1 Getting entities from the object cache using DbContext Find
Unlike a regular query, the Find method in DbSet (APIs included for the first time in EF 4.1) will perform a search in memory before even issuing the query against the database. It’s important to note that two different ObjectContext instances will have two different ObjectStateManager instances, meaning that they have separate object caches.
Find uses the primary key value to attempt to find an entity tracked by the context. If the entity is not in the context then a query will be executed and evaluated against the database, and null is returned if the entity is not found in the context or in the database. Note that Find also returns entities that have been added to the context but have not yet been saved to the database.
There is a performance consideration to be taken when using Find. Invocations to this method by default will trigger a validation of the object cache in order to detect changes that are still pending commit to the database. This process can be very expensive if there are a very large number of objects in the object cache or in a large object graph being added to the object cache, but it can also be disabled. In certain cases, you may perceive over an order of magnitude of difference in calling the Find method when you disable auto detect changes. Yet a second order of magnitude is perceived when the object actually is in the cache versus when the object has to be retrieved from the database. Here is an example graph with measurements taken using some of our microbenchmarks, expressed in milliseconds, with a load of 5000 entities:

Example of Find with auto-detect changes disabled:
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
context.Configuration.AutoDetectChangesEnabled = true;
...
What you have to consider when using the Find method is:
- If the object is not in the cache the benefits of Find are negated, but the syntax is still simpler than a query by key.
- If auto detect changes is enabled the cost of the Find method may increase by one order of magnitude, or even more depending on the complexity of your model and the amount of entities in your object cache.
Also, keep in mind that Find only returns the entity you are looking for and it does not automatically loads its associated entities if they are not already in the object cache. If you need to retrieve associated entities, you can use a query by key with eager loading. For more information see 8.1 Lazy Loading vs. Eager Loading.
3.1.2 Performance issues when the object cache has many entities
The object cache helps to increase the overall responsiveness of Entity Framework. However, when the object cache has a very large amount of entities loaded it may affect certain operations such as Add, Remove, Find, Entry, SaveChanges and more. In particular, operations that trigger a call to DetectChanges will be negatively affected by very large object caches. DetectChanges synchronizes the object graph with the object state manager and its performance will determined directly by the size of the object graph. For more information about DetectChanges, see Tracking Changes in POCO Entities.
When using Entity Framework 6, developers are able to call AddRange and RemoveRange directly on a DbSet, instead of iterating on a collection and calling Add once per instance. The advantage of using the range methods is that the cost of DetectChanges is only paid once for the entire set of entities as opposed to once per each added entity.
3.2 Query Plan Caching
The first time a query is executed, it goes through the internal plan compiler to translate the conceptual query into the store command (for example, the T-SQL which is executed when run against SQL Server). If query plan caching is enabled, the next time the query is executed the store command is retrieved directly from the query plan cache for execution, bypassing the plan compiler.
The query plan cache is shared across ObjectContext instances within the same AppDomain. You don't need to hold onto an ObjectContext instance to benefit from query plan caching.
3.2.1 Some notes about Query Plan Caching
- The query plan cache is shared for all query types: Entity SQL, LINQ to Entities, and CompiledQuery objects.
- By default, query plan caching is enabled for Entity SQL queries, whether executed through an EntityCommand or through an ObjectQuery. It is also enabled by default for LINQ to Entities queries in Entity Framework on .NET 4.5, and in Entity Framework 6
- Query plan caching can be disabled by setting the EnablePlanCaching property (on EntityCommand or ObjectQuery) to false. For example:
var query = from customer in context.Customer
where customer.CustomerId == id
select new
{
customer.CustomerId,
customer.Name
};
ObjectQuery oQuery = query as ObjectQuery;
oQuery.EnablePlanCaching = false;
- For parameterized queries, changing the parameter's value will still hit the cached query. But changing a parameter's facets (for example, size, precision, or scale) will hit a different entry in the cache.
- When using Entity SQL, the query string is part of the key. Changing the query at all will result in different cache entries, even if the queries are functionally equivalent. This includes changes to casing or whitespace.
- When using LINQ, the query is processed to generate a part of the key. Changing the LINQ expression will therefore generate a different key.
- Other technical limitations may apply; see Autocompiled Queries for more details.
3.2.2 Cache eviction algorithm
Understanding how the internal algorithm works will help you figure out when to enable or disable query plan caching. The cleanup algorithm is as follows:
- Once the cache contains a set number of entries (800), we start a timer that periodically (once-per-minute) sweeps the cache.
- During cache sweeps, entries are removed from the cache on a LFRU (Least frequently – recently used) basis. This algorithm takes both hit count and age into account when deciding which entries are ejected.
- At the end of each cache sweep, the cache again contains 800 entries.
All cache entries are treated equally when determining which entries to evict. This means the store command for a CompiledQuery has the same chance of eviction as the store command for an Entity SQL query.
Note that the cache eviction timer is kicked in when there are 800 entities in the cache, but the cache is only swept 60 seconds after this timer is started. That means that for up to 60 seconds your cache may grow to be quite large.
3.2.3 Test Metrics demonstrating query plan caching performance
To demonstrate the effect of query plan caching on your application's performance, we performed a test where we executed a number of Entity SQL queries against the Navision model. See the appendix for a description of the Navision model and the types of queries which were executed. In this test, we first iterate through the list of queries and execute each one once to add them to the cache (if caching is enabled). This step is untimed. Next, we sleep the main thread for over 60 seconds to allow cache sweeping to take place; finally, we iterate through the list a 2nd time to execute the cached queries. Additionally, the SQL Server plan cache is flushed before each set of queries is executed so that the times we obtain accurately reflect the benefit given by the query plan cache.
3.2.3.1 Test Results
| Test | EF5 no cache | EF5 cached | EF6 no cache | EF6 cached |
|---|---|---|---|---|
| Enumerating all 18723 queries | 124 | 125.4 | 124.3 | 125.3 |
| Avoiding sweep (just the first 800 queries, regardless of complexity) | 41.7 | 5.5 | 40.5 | 5.4 |
| Just the AggregatingSubtotals queries (178 total - which avoids sweep) | 39.5 | 4.5 | 38.1 | 4.6 |
All times in seconds.
Moral - when executing lots of distinct queries (for example, dynamically created queries), caching doesn't help and the resulting flushing of the cache can keep the queries that would benefit the most from plan caching from actually using it.
The AggregatingSubtotals queries are the most complex of the queries we tested with. As expected, the more complex the query is, the more benefit you will see from query plan caching.
Because a CompiledQuery is really a LINQ query with its plan cached, the comparison of a CompiledQuery versus the equivalent Entity SQL query should have similar results. In fact, if an app has lots of dynamic Entity SQL queries, filling the cache with queries will also effectively cause CompiledQueries to “decompile” when they are flushed from the cache. In this scenario, performance may be improved by disabling caching on the dynamic queries to prioritize the CompiledQueries. Better yet, of course, would be to rewrite the app to use parameterized queries instead of dynamic queries.
3.3 Using CompiledQuery to improve performance with LINQ queries
Our tests indicate that using CompiledQuery can bring a benefit of 7% over autocompiled LINQ queries; this means that you’ll spend 7% less time executing code from the Entity Framework stack; it does not mean your application will be 7% faster. Generally speaking, the cost of writing and maintaining CompiledQuery objects in EF 5.0 may not be worth the trouble when compared to the benefits. Your mileage may vary, so exercise this option if your project requires the extra push. Note that CompiledQueries are only compatible with ObjectContext-derived models, and not compatible with DbContext-derived models.
For more information on creating and invoking a CompiledQuery, see Compiled Queries (LINQ to Entities).
There are two considerations you have to take when using a CompiledQuery, namely the requirement to use static instances and the problems they have with composability. Here follows an in-depth explanation of these two considerations.
3.3.1 Use static CompiledQuery instances
Since compiling a LINQ query is a time-consuming process, we don’t want to do it every time we need to fetch data from the database. CompiledQuery instances allow you to compile once and run multiple times, but you have to be careful and procure to re-use the same CompiledQuery instance every time instead of compiling it over and over again. The use of static members to store the CompiledQuery instances becomes necessary; otherwise you won’t see any benefit.
For example, suppose your page has the following method body to handle displaying the products for the selected category:
// Warning: this is the wrong way of using CompiledQuery
using (NorthwindEntities context = new NorthwindEntities())
{
string selectedCategory = this.categoriesList.SelectedValue;
var productsForCategory = CompiledQuery.Compile<NorthwindEntities, string, IQueryable<Product>>(
(NorthwindEntities nwnd, string category) =>
nwnd.Products.Where(p => p.Category.CategoryName == category)
);
this.productsGrid.DataSource = productsForCategory.Invoke(context, selectedCategory).ToList();
this.productsGrid.DataBind();
}
this.productsGrid.Visible = true;
In this case, you will create a new CompiledQuery instance on the fly every time the method is called. Instead of seeing performance benefits by retrieving the store command from the query plan cache, the CompiledQuery will go through the plan compiler every time a new instance is created. In fact, you will be polluting your query plan cache with a new CompiledQuery entry every time the method is called.
Instead, you want to create a static instance of the compiled query, so you are invoking the same compiled query every time the method is called. One way to so this is by adding the CompiledQuery instance as a member of your object context. You can then make things a little cleaner by accessing the CompiledQuery through a helper method:
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IEnumerable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IEnumerable<Product> GetProductsForCategory(string categoryName)
{
return productsForCategoryCQ.Invoke(this, categoryName).ToList();
}
This helper method would be invoked as follows:
this.productsGrid.DataSource = context.GetProductsForCategory(selectedCategory);
3.3.2 Composing over a CompiledQuery
The ability to compose over any LINQ query is extremely useful; to do this, you simply invoke a method after the IQueryable such as Skip() or Count(). However, doing so essentially returns a new IQueryable object. While there’s nothing to stop you technically from composing over a CompiledQuery, doing so will cause the generation of a new IQueryable object that requires passing through the plan compiler again.
Some components will make use of composed IQueryable objects to enable advanced functionality. For example, ASP.NET’s GridView can be data-bound to an IQueryable object via the SelectMethod property. The GridView will then compose over this IQueryable object to allow sorting and paging over the data model. As you can see, using a CompiledQuery for the GridView would not hit the compiled query but would generate a new autocompiled query.
One place where you may run into this is when adding progressive filters to a query. For example, suppose you had a Customers page with several drop-down lists for optional filters (for example, Country and OrdersCount). You can compose these filters over the IQueryable results of a CompiledQuery, but doing so will result in the new query going through the plan compiler every time you execute it.
using (NorthwindEntities context = new NorthwindEntities())
{
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployee();
if (this.orderCountFilterList.SelectedItem.Value != defaultFilterText)
{
int orderCount = int.Parse(orderCountFilterList.SelectedValue);
myCustomers = myCustomers.Where(c => c.Orders.Count > orderCount);
}
if (this.countryFilterList.SelectedItem.Value != defaultFilterText)
{
myCustomers = myCustomers.Where(c => c.Address.Country == countryFilterList.SelectedValue);
}
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
To avoid this re-compilation, you can rewrite the CompiledQuery to take the possible filters into account:
private static readonly Func<NorthwindEntities, int, int?, string, IQueryable<Customer>> customersForEmployeeWithFiltersCQ = CompiledQuery.Compile(
(NorthwindEntities context, int empId, int? countFilter, string countryFilter) =>
context.Customers.Where(c => c.Orders.Any(o => o.EmployeeID == empId))
.Where(c => countFilter.HasValue == false || c.Orders.Count > countFilter)
.Where(c => countryFilter == null || c.Address.Country == countryFilter)
);
Which would be invoked in the UI like:
using (NorthwindEntities context = new NorthwindEntities())
{
int? countFilter = (this.orderCountFilterList.SelectedIndex == 0) ?
(int?)null :
int.Parse(this.orderCountFilterList.SelectedValue);
string countryFilter = (this.countryFilterList.SelectedIndex == 0) ?
null :
this.countryFilterList.SelectedValue;
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployeeWithFilters(
countFilter, countryFilter);
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
A tradeoff here is the generated store command will always have the filters with the null checks, but these should be fairly simple for the database server to optimize:
...
WHERE ((0 = (CASE WHEN (@p__linq__1 IS NOT NULL) THEN cast(1 as bit) WHEN (@p__linq__1 IS NULL) THEN cast(0 as bit) END)) OR ([Project3].[C2] > @p__linq__2)) AND (@p__linq__3 IS NULL OR [Project3].[Country] = @p__linq__4)
3.4 Metadata caching
The Entity Framework also supports Metadata caching. This is essentially caching of type information and type-to-database mapping information across different connections to the same model. The Metadata cache is unique per AppDomain.
3.4.1 Metadata Caching algorithm
Metadata information for a model is stored in an ItemCollection for each EntityConnection.
- As a side note, there are different ItemCollection objects for different parts of the model. For example, StoreItemCollections contains the information about the database model; ObjectItemCollection contains information about the data model; EdmItemCollection contains information about the conceptual model.
If two connections use the same connection string, they will share the same ItemCollection instance.
Functionally equivalent but textually different connection strings may result in different metadata caches. We do tokenize connection strings, so simply changing the order of the tokens should result in shared metadata. But two connection strings that seem functionally the same may not be evaluated as identical after tokenization.
The ItemCollection is periodically checked for use. If it is determined that a workspace has not been accessed recently, it will be marked for cleanup on the next cache sweep.
Merely creating an EntityConnection will cause a metadata cache to be created (though the item collections in it will not be initialized until the connection is opened). This workspace will remain in-memory until the caching algorithm determines it is not “in use”.
The Customer Advisory Team has written a blog post that describes holding a reference to an ItemCollection in order to avoid "deprecation" when using large models: <https://learn.microsoft.com/archive/blogs/appfabriccat/holding-a-reference-to-the-ef-metadataworkspace-for-wcf-services>.
3.4.2 The relationship between Metadata Caching and Query Plan Caching
The query plan cache instance lives in the MetadataWorkspace's ItemCollection of store types. This means that cached store commands will be used for queries against any context instantiated using a given MetadataWorkspace. It also means that if you have two connections strings that are slightly different and don't match after tokenizing, you will have different query plan cache instances.
3.5 Results caching
With results caching (also known as "second-level caching"), you keep the results of queries in a local cache. When issuing a query, you first see if the results are available locally before you query against the store. While results caching isn't directly supported by Entity Framework, it's possible to add a second level cache by using a wrapping provider. An example wrapping provider with a second-level cache is Alachisoft's Entity Framework Second Level Cache based on NCache.
This implementation of second-level caching is an injected functionality that takes place after the LINQ expression has been evaluated (and funcletized) and the query execution plan is computed or retrieved from the first-level cache. The second-level cache will then store only the raw database results, so the materialization pipeline still executes afterwards.
3.5.1 Additional references for results caching with the wrapping provider
- Julie Lerman has written a "Second-Level Caching in Entity Framework and Windows Azure" MSDN article that includes how to update the sample wrapping provider to use Windows Server AppFabric caching: https://msdn.microsoft.com/magazine/hh394143.aspx
- If you are working with Entity Framework 5, the team blog has a post that describes how to get things running with the caching provider for Entity Framework 5: <https://learn.microsoft.com/archive/blogs/adonet/ef-caching-with-jarek-kowalskis-provider>. It also includes a T4 template to help automate adding the 2nd-level caching to your project.
4 Autocompiled Queries
When a query is issued against a database using Entity Framework, it must go through a series of steps before actually materializing the results; one such step is Query Compilation. Entity SQL queries were known to have good performance as they are automatically cached, so the second or third time you execute the same query it can skip the plan compiler and use the cached plan instead.
Entity Framework 5 introduced automatic caching for LINQ to Entities queries as well. In past editions of Entity Framework creating a CompiledQuery to speed your performance was a common practice, as this would make your LINQ to Entities query cacheable. Since caching is now done automatically without the use of a CompiledQuery, we call this feature “autocompiled queries”. For more information about the query plan cache and its mechanics, see Query Plan Caching.
Entity Framework detects when a query requires to be recompiled, and does so when the query is invoked even if it had been compiled before. Common conditions that cause the query to be recompiled are:
- Changing the MergeOption associated to your query. The cached query will not be used, instead the plan compiler will run again and the newly created plan gets cached.
- Changing the value of ContextOptions.UseCSharpNullComparisonBehavior. You get the same effect as changing the MergeOption.
Other conditions can prevent your query from using the cache. Common examples are:
- Using IEnumerable<T>.Contains<>(T value).
- Using functions that produce queries with constants.
- Using the properties of a non-mapped object.
- Linking your query to another query that requires to be recompiled.
4.1 Using IEnumerable<T>.Contains<T>(T value)
Entity Framework does not cache queries that invoke IEnumerable<T>.Contains<T>(T value) against an in-memory collection, since the values of the collection are considered volatile. The following example query will not be cached, so it will always be processed by the plan compiler:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var query = context.MyEntities
.Where(entity => ids.Contains(entity.Id));
var results = query.ToList();
...
}
Note that the size of the IEnumerable against which Contains is executed determines how fast or how slow your query is compiled. Performance can suffer significantly when using large collections such as the one shown in the example above.
Entity Framework 6 contains optimizations to the way IEnumerable<T>.Contains<T>(T value) works when queries are executed. The SQL code that is generated is much faster to produce and more readable, and in most cases it also executes faster in the server.
4.2 Using functions that produce queries with constants
The Skip(), Take(), Contains() and DefautIfEmpty() LINQ operators do not produce SQL queries with parameters but instead put the values passed to them as constants. Because of this, queries that might otherwise be identical end up polluting the query plan cache, both on the EF stack and on the database server, and do not get reutilized unless the same constants are used in a subsequent query execution. For example:
var id = 10;
...
using (var context = new MyContext())
{
var query = context.MyEntities.Select(entity => entity.Id).Contains(id);
var results = query.ToList();
...
}
In this example, each time this query is executed with a different value for id the query will be compiled into a new plan.
In particular pay attention to the use of Skip and Take when doing paging. In EF6 these methods have a lambda overload that effectively makes the cached query plan reusable because EF can capture variables passed to these methods and translate them to SQLparameters. This also helps keep the cache cleaner since otherwise each query with a different constant for Skip and Take would get its own query plan cache entry.
Consider the following code, which is suboptimal but is only meant to exemplify this class of queries:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
A faster version of this same code would involve calling Skip with a lambda:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(() => i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
The second snippet may run up to 11% faster because the same query plan is used every time the query is run, which saves CPU time and avoids polluting the query cache. Furthermore, because the parameter to Skip is in a closure the code might as well look like this now:
var i = 0;
var skippyCustomers = context.Customers.OrderBy(c => c.LastName).Skip(() => i);
for (; i < count; ++i)
{
var currentCustomer = skippyCustomers.FirstOrDefault();
ProcessCustomer(currentCustomer);
}
4.3 Using the properties of a non-mapped object
When a query uses the properties of a non-mapped object type as a parameter then the query will not get cached. For example:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myObject.MyProperty)
select entity;
var results = query.ToList();
...
}
In this example, assume that class NonMappedType is not part of the Entity model. This query can easily be changed to not use a non-mapped type and instead use a local variable as the parameter to the query:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var myValue = myObject.MyProperty;
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myValue)
select entity;
var results = query.ToList();
...
}
In this case, the query will be able to get cached and will benefit from the query plan cache.
4.4 Linking to queries that require recompiling
Following the same example as above, if you have a second query that relies on a query that needs to be recompiled, your entire second query will also be recompiled. Here’s an example to illustrate this scenario:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var firstQuery = from entity in context.MyEntities
where ids.Contains(entity.Id)
select entity;
var secondQuery = from entity in context.MyEntities
where firstQuery.Any(otherEntity => otherEntity.Id == entity.Id)
select entity;
var results = secondQuery.ToList();
...
}
The example is generic, but it illustrates how linking to firstQuery is causing secondQuery to be unable to get cached. If firstQuery had not been a query that requires recompiling, then secondQuery would have been cached.
5 NoTracking Queries
5.1 Disabling change tracking to reduce state management overhead
If you are in a read-only scenario and want to avoid the overhead of loading the objects into the ObjectStateManager, you can issue "No Tracking" queries. Change tracking can be disabled at the query level.
Note though that by disabling change tracking you are effectively turning off the object cache. When you query for an entity, we can't skip materialization by pulling the previously-materialized query results from the ObjectStateManager. If you are repeatedly querying for the same entities on the same context, you might actually see a performance benefit from enabling change tracking.
When querying using ObjectContext, ObjectQuery and ObjectSet instances will remember a MergeOption once it is set, and queries that are composed on them will inherit the effective MergeOption of the parent query. When using DbContext, tracking can be disabled by calling the AsNoTracking() modifier on the DbSet.
5.1.1 Disabling change tracking for a query when using DbContext
You can switch the mode of a query to NoTracking by chaining a call to the AsNoTracking() method in the query. Unlike ObjectQuery, the DbSet and DbQuery classes in the DbContext API don’t have a mutable property for the MergeOption.
var productsForCategory = from p in context.Products.AsNoTracking()
where p.Category.CategoryName == selectedCategory
select p;
5.1.2 Disabling change tracking at the query level using ObjectContext
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
((ObjectQuery)productsForCategory).MergeOption = MergeOption.NoTracking;
5.1.3 Disabling change tracking for an entire entity set using ObjectContext
context.Products.MergeOption = MergeOption.NoTracking;
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
5.2 Test Metrics demonstrating the performance benefit of NoTracking queries
In this test we look at the cost of filling the ObjectStateManager by comparing Tracking to NoTracking queries for the Navision model. See the appendix for a description of the Navision model and the types of queries which were executed. In this test, we iterate through the list of queries and execute each one once. We ran two variations of the test, once with NoTracking queries and once with the default merge option of "AppendOnly". We ran each variation 3 times and take the mean value of the runs. Between the tests we clear the query cache on the SQL Server and shrink the tempdb by running the following commands:
- DBCC DROPCLEANBUFFERS
- DBCC FREEPROCCACHE
- DBCC SHRINKDATABASE (tempdb, 0)
Test Results, median over 3 runs:
| NO TRACKING – WORKING SET | NO TRACKING – TIME | APPEND ONLY – WORKING SET | APPEND ONLY – TIME | |
|---|---|---|---|---|
| Entity Framework 5 | 460361728 | 1163536 ms | 596545536 | 1273042 ms |
| Entity Framework 6 | 647127040 | 190228 ms | 832798720 | 195521 ms |
Entity Framework 5 will have a smaller memory footprint at the end of the run than Entity Framework 6 does. The additional memory consumed by Entity Framework 6 is the result of additional memory structures and code that enable new features and better performance.
There’s also a clear difference in memory footprint when using the ObjectStateManager. Entity Framework 5 increased its footprint by 30% when keeping track of all the entities we materialized from the database. Entity Framework 6 increased its footprint by 28% when doing so.
In terms of time, Entity Framework 6 outperforms Entity Framework 5 in this test by a large margin. Entity Framework 6 completed the test in roughly 16% of the time consumed by Entity Framework 5. Additionally, Entity Framework 5 takes 9% more time to complete when the ObjectStateManager is being used. In comparison, Entity Framework 6 is using 3% more time when using the ObjectStateManager.
6 Query Execution Options
Entity Framework offers several different ways to query. We'll take a look at the following options, compare the pros and cons of each, and examine their performance characteristics:
- LINQ to Entities.
- No Tracking LINQ to Entities.
- Entity SQL over an ObjectQuery.
- Entity SQL over an EntityCommand.
- ExecuteStoreQuery.
- SqlQuery.
- CompiledQuery.
6.1 LINQ to Entities queries
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Pros
- Suitable for CUD operations.
- Fully materialized objects.
- Simplest to write with syntax built into the programming language.
- Good performance.
Cons
- Certain technical restrictions, such as:
- Patterns using DefaultIfEmpty for OUTER JOIN queries result in more complex queries than simple OUTER JOIN statements in Entity SQL.
- You still can’t use LIKE with general pattern matching.
6.2 No Tracking LINQ to Entities queries
When the context derives ObjectContext:
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
When the context derives DbContext:
var q = context.Products.AsNoTracking()
.Where(p => p.Category.CategoryName == "Beverages");
Pros
- Improved performance over regular LINQ queries.
- Fully materialized objects.
- Simplest to write with syntax built into the programming language.
Cons
- Not suitable for CUD operations.
- Certain technical restrictions, such as:
- Patterns using DefaultIfEmpty for OUTER JOIN queries result in more complex queries than simple OUTER JOIN statements in Entity SQL.
- You still can’t use LIKE with general pattern matching.
Note that queries that project scalar properties are not tracked even if the NoTracking is not specified. For example:
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages").Select(p => new { p.ProductName });
This particular query doesn’t explicitly specify being NoTracking, but since it’s not materializing a type that’s known to the object state manager then the materialized result is not tracked.
6.3 Entity SQL over an ObjectQuery
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
Pros
- Suitable for CUD operations.
- Fully materialized objects.
- Supports query plan caching.
Cons
- Involves textual query strings which are more prone to user error than query constructs built into the language.
6.4 Entity SQL over an Entity Command
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
while (reader.Read())
{
// manually 'materialize' the product
}
}
Pros
- Supports query plan caching in .NET 4.0 (plan caching is supported by all other query types in .NET 4.5).
Cons
- Involves textual query strings which are more prone to user error than query constructs built into the language.
- Not suitable for CUD operations.
- Results are not automatically materialized, and must be read from the data reader.
6.5 SqlQuery and ExecuteStoreQuery
SqlQuery on Database:
// use this to obtain entities and not track them
var q1 = context.Database.SqlQuery<Product>("select * from products");
SqlQuery on DbSet:
// use this to obtain entities and have them tracked
var q2 = context.Products.SqlQuery("select * from products");
ExecuteStoreQuery:
var beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued, P.DiscontinuedDate
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
Pros
- Generally fastest performance since plan compiler is bypassed.
- Fully materialized objects.
- Suitable for CUD operations when used from the DbSet.
Cons
- Query is textual and error prone.
- Query is tied to a specific backend by using store semantics instead of conceptual semantics.
- When inheritance is present, handcrafted query needs to account for mapping conditions for the type requested.
6.6 CompiledQuery
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
…
var q = context.InvokeProductsForCategoryCQ("Beverages");
Pros
- Provides up to a 7% performance improvement over regular LINQ queries.
- Fully materialized objects.
- Suitable for CUD operations.
Cons
- Increased complexity and programming overhead.
- The performance improvement is lost when composing on top of a compiled query.
- Some LINQ queries can't be written as a CompiledQuery - for example, projections of anonymous types.
6.7 Performance Comparison of different query options
Simple microbenchmarks where the context creation was not timed were put to the test. We measured querying 5000 times for a set of non-cached entities in a controlled environment. These numbers are to be taken with a warning: they do not reflect actual numbers produced by an application, but instead they are a very accurate measurement of how much of a performance difference there is when different querying options are compared apples-to-apples, excluding the cost of creating a new context.
| EF | Test | Time (ms) | Memory |
|---|---|---|---|
| EF5 | ObjectContext ESQL | 2414 | 38801408 |
| EF5 | ObjectContext Linq Query | 2692 | 38277120 |
| EF5 | DbContext Linq Query No Tracking | 2818 | 41840640 |
| EF5 | DbContext Linq Query | 2930 | 41771008 |
| EF5 | ObjectContext Linq Query No Tracking | 3013 | 38412288 |
| EF6 | ObjectContext ESQL | 2059 | 46039040 |
| EF6 | ObjectContext Linq Query | 3074 | 45248512 |
| EF6 | DbContext Linq Query No Tracking | 3125 | 47575040 |
| EF6 | DbContext Linq Query | 3420 | 47652864 |
| EF6 | ObjectContext Linq Query No Tracking | 3593 | 45260800 |
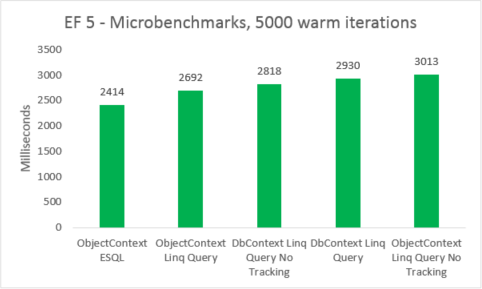

Microbenchmarks are very sensitive to small changes in the code. In this case, the difference between the costs of Entity Framework 5 and Entity Framework 6 are due to the addition of interception and transactional improvements. These microbenchmarks numbers, however, are an amplified vision into a very small fragment of what Entity Framework does. Real-world scenarios of warm queries should not see a performance regression when upgrading from Entity Framework 5 to Entity Framework 6.
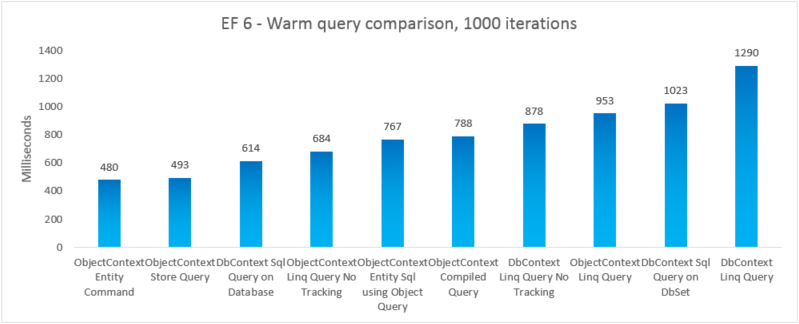
To compare the real-world performance of the different query options, we created 5 separate test variations where we use a different query option to select all products whose category name is "Beverages". Each iteration includes the cost of creating the context, and the cost of materializing all returned entities. 10 iterations are run untimed before taking the sum of 1000 timed iterations. The results shown are the median run taken from 5 runs of each test. For more information, see Appendix B which includes the code for the test.
| EF | Test | Time (ms) | Memory |
|---|---|---|---|
| EF5 | ObjectContext Entity Command | 621 | 39350272 |
| EF5 | DbContext Sql Query on Database | 825 | 37519360 |
| EF5 | ObjectContext Store Query | 878 | 39460864 |
| EF5 | ObjectContext Linq Query No Tracking | 969 | 38293504 |
| EF5 | ObjectContext Entity Sql using Object Query | 1089 | 38981632 |
| EF5 | ObjectContext Compiled Query | 1099 | 38682624 |
| EF5 | ObjectContext Linq Query | 1152 | 38178816 |
| EF5 | DbContext Linq Query No Tracking | 1208 | 41803776 |
| EF5 | DbContext Sql Query on DbSet | 1414 | 37982208 |
| EF5 | DbContext Linq Query | 1574 | 41738240 |
| EF6 | ObjectContext Entity Command | 480 | 47247360 |
| EF6 | ObjectContext Store Query | 493 | 46739456 |
| EF6 | DbContext Sql Query on Database | 614 | 41607168 |
| EF6 | ObjectContext Linq Query No Tracking | 684 | 46333952 |
| EF6 | ObjectContext Entity Sql using Object Query | 767 | 48865280 |
| EF6 | ObjectContext Compiled Query | 788 | 48467968 |
| EF6 | DbContext Linq Query No Tracking | 878 | 47554560 |
| EF6 | ObjectContext Linq Query | 953 | 47632384 |
| EF6 | DbContext Sql Query on DbSet | 1023 | 41992192 |
| EF6 | DbContext Linq Query | 1290 | 47529984 |

Note
For completeness, we included a variation where we execute an Entity SQL query on an EntityCommand. However, because results are not materialized for such queries, the comparison isn't necessarily apples-to-apples. The test includes a close approximation to materializing to try making the comparison fairer.
In this end-to-end case, Entity Framework 6 outperforms Entity Framework 5 due to performance improvements made on several parts of the stack, including a much lighter DbContext initialization and faster MetadataCollection<T> lookups.
7 Design time performance considerations
7.1 Inheritance Strategies
Another performance consideration when using Entity Framework is the inheritance strategy you use. Entity Framework supports 3 basic types of inheritance and their combinations:
- Table per Hierarchy (TPH) – where each inheritance set maps to a table with a discriminator column to indicate which particular type in the hierarchy is being represented in the row.
- Table per Type (TPT) – where each type has its own table in the database; the child tables only define the columns that the parent table doesn’t contain.
- Table per Class (TPC) – where each type has its own full table in the database; the child tables define all their fields, including those defined in parent types.
If your model uses TPT inheritance, the queries which are generated will be more complex than those that are generated with the other inheritance strategies, which may result on longer execution times on the store. It will generally take longer to generate queries over a TPT model, and to materialize the resulting objects.
See the "Performance Considerations when using TPT (Table per Type) Inheritance in the Entity Framework" MSDN blog post: <https://learn.microsoft.com/archive/blogs/adonet/performance-considerations-when-using-tpt-table-per-type-inheritance-in-the-entity-framework>.
7.1.1 Avoiding TPT in Model First or Code First applications
When you create a model over an existing database that has a TPT schema, you don't have many options. But when creating an application using Model First or Code First, you should avoid TPT inheritance for performance concerns.
When you use Model First in the Entity Designer Wizard, you will get TPT for any inheritance in your model. If you want to switch to a TPH inheritance strategy with Model First, you can use the "Entity Designer Database Generation Power Pack" available from the Visual Studio Gallery ( <http://visualstudiogallery.msdn.microsoft.com/df3541c3-d833-4b65-b942-989e7ec74c87/>).
When using Code First to configure the mapping of a model with inheritance, EF will use TPH by default, therefore all entities in the inheritance hierarchy will be mapped to the same table. See the "Mapping with the Fluent API" section of the "Code First in Entity Framework4.1" article in MSDN Magazine ( http://msdn.microsoft.com/magazine/hh126815.aspx) for more details.
7.2 Upgrading from EF4 to improve model generation time
A SQL Server-specific improvement to the algorithm that generates the store-layer (SSDL) of the model is available in Entity Framework 5 and 6, and as an update to Entity Framework 4 when Visual Studio 2010 SP1 is installed. The following test results demonstrate the improvement when generating a very big model, in this case the Navision model. See Appendix C for more details about it.
The model contains 1005 entity sets and 4227 association sets.
| Configuration | Breakdown of time consumed |
|---|---|
| Visual Studio 2010, Entity Framework 4 | SSDL Generation: 2 hr 27 min Mapping Generation: 1 second CSDL Generation: 1 second ObjectLayer Generation: 1 second View Generation: 2 h 14 min |
| Visual Studio 2010 SP1, Entity Framework 4 | SSDL Generation: 1 second Mapping Generation: 1 second CSDL Generation: 1 second ObjectLayer Generation: 1 second View Generation: 1 hr 53 min |
| Visual Studio 2013, Entity Framework 5 | SSDL Generation: 1 second Mapping Generation: 1 second CSDL Generation: 1 second ObjectLayer Generation: 1 second View Generation: 65 minutes |
| Visual Studio 2013, Entity Framework 6 | SSDL Generation: 1 second Mapping Generation: 1 second CSDL Generation: 1 second ObjectLayer Generation: 1 second View Generation: 28 seconds. |
It's worth noting that when generating the SSDL, the load is almost entirely spent on the SQL Server, while the client development machine is waiting idle for results to come back from the server. DBAs should particularly appreciate this improvement. It's also worth noting that essentially the entire cost of model generation takes place in View Generation now.
7.3 Splitting Large Models with Database First and Model First
As model size increases, the designer surface becomes cluttered and difficult to use. We typically consider a model with more than 300 entities to be too large to effectively use the designer. The following blog post describes several options for splitting large models: <https://learn.microsoft.com/archive/blogs/adonet/working-with-large-models-in-entity-framework-part-2>.
The post was written for the first version of Entity Framework, but the steps still apply.
7.4 Performance considerations with the Entity Data Source Control
We've seen cases in multi-threaded performance and stress tests where the performance of a web application using the EntityDataSource Control deteriorates significantly. The underlying cause is that the EntityDataSource repeatedly calls MetadataWorkspace.LoadFromAssembly on the assemblies referenced by the Web application to discover the types to be used as entities.
The solution is to set the ContextTypeName of the EntityDataSource to the type name of your derived ObjectContext class. This turns off the mechanism that scans all referenced assemblies for entity types.
Setting the ContextTypeName field also prevents a functional problem where the EntityDataSource in .NET 4.0 throws a ReflectionTypeLoadException when it can't load a type from an assembly via reflection. This issue has been fixed in .NET 4.5.
7.5 POCO entities and change tracking proxies
Entity Framework enables you to use custom data classes together with your data model without making any modifications to the data classes themselves. This means that you can use "plain-old" CLR objects (POCO), such as existing domain objects, with your data model. These POCO data classes (also known as persistence-ignorant objects), which are mapped to entities that are defined in a data model, support most of the same query, insert, update, and delete behaviors as entity types that are generated by the Entity Data Model tools.
Entity Framework can also create proxy classes derived from your POCO types, which are used when you want to enable features such as lazy loading and automatic change tracking on POCO entities. Your POCO classes must meet certain requirements to allow Entity Framework to use proxies, as described here: http://msdn.microsoft.com/library/dd468057.aspx.
Chance tracking proxies will notify the object state manager each time any of the properties of your entities has its value changed, so Entity Framework knows the actual state of your entities all the time. This is done by adding notification events to the body of the setter methods of your properties, and having the object state manager processing such events. Note that creating a proxy entity will typically be more expensive than creating a non-proxy POCO entity due to the added set of events created by Entity Framework.
When a POCO entity does not have a change tracking proxy, changes are found by comparing the contents of your entities against a copy of a previous saved state. This deep comparison will become a lengthy process when you have many entities in your context, or when your entities have a very large amount of properties, even if none of them changed since the last comparison took place.
In summary: you’ll pay a performance hit when creating the change tracking proxy, but change tracking will help you speed up the change detection process when your entities have many properties or when you have many entities in your model. For entities with a small number of properties where the amount of entities doesn’t grow too much, having change tracking proxies may not be of much benefit.
8 Loading Related Entities
8.1 Lazy Loading vs. Eager Loading
Entity Framework offers several different ways to load the entities that are related to your target entity. For example, when you query for Products, there are different ways that the related Orders will be loaded into the Object State Manager. From a performance standpoint, the biggest question to consider when loading related entities will be whether to use Lazy Loading or Eager Loading.
When using Eager Loading, the related entities are loaded along with your target entity set. You use an Include statement in your query to indicate which related entities you want to bring in.
When using Lazy Loading, your initial query only brings in the target entity set. But whenever you access a navigation property, another query is issued against the store to load the related entity.
Once an entity has been loaded, any further queries for the entity will load it directly from the Object State Manager, whether you are using lazy loading or eager loading.
8.2 How to choose between Lazy Loading and Eager Loading
The important thing is that you understand the difference between Lazy Loading and Eager Loading so that you can make the correct choice for your application. This will help you evaluate the tradeoff between multiple requests against the database versus a single request that may contain a large payload. It may be appropriate to use eager loading in some parts of your application and lazy loading in other parts.
As an example of what's happening under the hood, suppose you want to query for the customers who live in the UK and their order count.
Using Eager Loading
using (NorthwindEntities context = new NorthwindEntities())
{
var ukCustomers = context.Customers.Include(c => c.Orders).Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Using Lazy Loading
using (NorthwindEntities context = new NorthwindEntities())
{
context.ContextOptions.LazyLoadingEnabled = true;
//Notice that the Include method call is missing in the query
var ukCustomers = context.Customers.Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
When using eager loading, you'll issue a single query that returns all customers and all orders. The store command looks like:
SELECT
[Project1].[C1] AS [C1],
[Project1].[CustomerID] AS [CustomerID],
[Project1].[CompanyName] AS [CompanyName],
[Project1].[ContactName] AS [ContactName],
[Project1].[ContactTitle] AS [ContactTitle],
[Project1].[Address] AS [Address],
[Project1].[City] AS [City],
[Project1].[Region] AS [Region],
[Project1].[PostalCode] AS [PostalCode],
[Project1].[Country] AS [Country],
[Project1].[Phone] AS [Phone],
[Project1].[Fax] AS [Fax],
[Project1].[C2] AS [C2],
[Project1].[OrderID] AS [OrderID],
[Project1].[CustomerID1] AS [CustomerID1],
[Project1].[EmployeeID] AS [EmployeeID],
[Project1].[OrderDate] AS [OrderDate],
[Project1].[RequiredDate] AS [RequiredDate],
[Project1].[ShippedDate] AS [ShippedDate],
[Project1].[ShipVia] AS [ShipVia],
[Project1].[Freight] AS [Freight],
[Project1].[ShipName] AS [ShipName],
[Project1].[ShipAddress] AS [ShipAddress],
[Project1].[ShipCity] AS [ShipCity],
[Project1].[ShipRegion] AS [ShipRegion],
[Project1].[ShipPostalCode] AS [ShipPostalCode],
[Project1].[ShipCountry] AS [ShipCountry]
FROM ( SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax],
1 AS [C1],
[Extent2].[OrderID] AS [OrderID],
[Extent2].[CustomerID] AS [CustomerID1],
[Extent2].[EmployeeID] AS [EmployeeID],
[Extent2].[OrderDate] AS [OrderDate],
[Extent2].[RequiredDate] AS [RequiredDate],
[Extent2].[ShippedDate] AS [ShippedDate],
[Extent2].[ShipVia] AS [ShipVia],
[Extent2].[Freight] AS [Freight],
[Extent2].[ShipName] AS [ShipName],
[Extent2].[ShipAddress] AS [ShipAddress],
[Extent2].[ShipCity] AS [ShipCity],
[Extent2].[ShipRegion] AS [ShipRegion],
[Extent2].[ShipPostalCode] AS [ShipPostalCode],
[Extent2].[ShipCountry] AS [ShipCountry],
CASE WHEN ([Extent2].[OrderID] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C2]
FROM [dbo].[Customers] AS [Extent1]
LEFT OUTER JOIN [dbo].[Orders] AS [Extent2] ON [Extent1].[CustomerID] = [Extent2].[CustomerID]
WHERE N'UK' = [Extent1].[Country]
) AS [Project1]
ORDER BY [Project1].[CustomerID] ASC, [Project1].[C2] ASC
When using lazy loading, you'll issue the following query initially:
SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax]
FROM [dbo].[Customers] AS [Extent1]
WHERE N'UK' = [Extent1].[Country]
And each time you access the Orders navigation property of a customer another query like the following is issued against the store:
exec sp_executesql N'SELECT
[Extent1].[OrderID] AS [OrderID],
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[EmployeeID] AS [EmployeeID],
[Extent1].[OrderDate] AS [OrderDate],
[Extent1].[RequiredDate] AS [RequiredDate],
[Extent1].[ShippedDate] AS [ShippedDate],
[Extent1].[ShipVia] AS [ShipVia],
[Extent1].[Freight] AS [Freight],
[Extent1].[ShipName] AS [ShipName],
[Extent1].[ShipAddress] AS [ShipAddress],
[Extent1].[ShipCity] AS [ShipCity],
[Extent1].[ShipRegion] AS [ShipRegion],
[Extent1].[ShipPostalCode] AS [ShipPostalCode],
[Extent1].[ShipCountry] AS [ShipCountry]
FROM [dbo].[Orders] AS [Extent1]
WHERE [Extent1].[CustomerID] = @EntityKeyValue1',N'@EntityKeyValue1 nchar(5)',@EntityKeyValue1=N'AROUT'
For more information, see the Loading Related Objects.
8.2.1 Lazy Loading versus Eager Loading cheat sheet
There’s no such thing as a one-size-fits-all to choosing eager loading versus lazy loading. Try first to understand the differences between both strategies so you can do a well informed decision; also, consider if your code fits to any of the following scenarios:
| Scenario | Our Suggestion |
|---|---|
| Do you need to access many navigation properties from the fetched entities? | No - Both options will probably do. However, if the payload your query is bringing is not too big, you may experience performance benefits by using Eager loading as it’ll require less network round trips to materialize your objects. Yes - If you need to access many navigation properties from the entities, you’d do that by using multiple include statements in your query with Eager loading. The more entities you include, the bigger the payload your query will return. Once you include three or more entities into your query, consider switching to Lazy loading. |
| Do you know exactly what data will be needed at run time? | No - Lazy loading will be better for you. Otherwise, you may end up querying for data that you will not need. Yes - Eager loading is probably your best bet; it will help loading entire sets faster. If your query requires fetching a very large amount of data, and this becomes too slow, then try Lazy loading instead. |
| Is your code executing far from your database? (increased network latency) | No - When the network latency is not an issue, using Lazy loading may simplify your code. Remember that the topology of your application may change, so don’t take database proximity for granted. Yes - When the network is a problem, only you can decide what fits better for your scenario. Typically Eager loading will be better because it requires fewer round trips. |
8.2.2 Performance concerns with multiple Includes
When we hear performance questions that involve server response time problems, the source of the issue is frequently queries with multiple Include statements. While including related entities in a query is powerful, it's important to understand what's happening under the covers.
It takes a relatively long time for a query with multiple Include statements in it to go through our internal plan compiler to produce the store command. The majority of this time is spent trying to optimize the resulting query. The generated store command will contain an Outer Join or Union for each Include, depending on your mapping. Queries like this will bring in large connected graphs from your database in a single payload, which will acerbate any bandwidth issues, especially when there is a lot of redundancy in the payload (for example, when multiple levels of Include are used to traverse associations in the one-to-many direction).
You can check for cases where your queries are returning excessively large payloads by accessing the underlying TSQL for the query by using ToTraceString and executing the store command in SQL Server Management Studio to see the payload size. In such cases you can try to reduce the number of Include statements in your query to just bring in the data you need. Or you may be able to break your query into a smaller sequence of subqueries, for example:
Before breaking the query:
using (NorthwindEntities context = new NorthwindEntities())
{
var customers = from c in context.Customers.Include(c => c.Orders)
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
After breaking the query:
using (NorthwindEntities context = new NorthwindEntities())
{
var orders = from o in context.Orders
where o.Customer.LastName.StartsWith(lastNameParameter)
select o;
orders.Load();
var customers = from c in context.Customers
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
This will work only on tracked queries, as we are making use of the ability the context has to perform identity resolution and association fixup automatically.
As with lazy loading, the tradeoff will be more queries for smaller payloads. You can also use projections of individual properties to explicitly select only the data you need from each entity, but you will not be loading entities in this case, and updates will not be supported.
8.2.3 Workaround to get lazy loading of properties
Entity Framework currently doesn’t support lazy loading of scalar or complex properties. However, in cases where you have a table that includes a large object such as a BLOB, you can use table splitting to separate the large properties into a separate entity. For example, suppose you have a Product table that includes a varbinary photo column. If you don't frequently need to access this property in your queries, you can use table splitting to bring in only the parts of the entity that you normally need. The entity representing the product photo will only be loaded when you explicitly need it.
A good resource that shows how to enable table splitting is Gil Fink's "Table Splitting in Entity Framework" blog post: <http://blogs.microsoft.co.il/blogs/gilf/archive/2009/10/13/table-splitting-in-entity-framework.aspx>.
9 Other considerations
9.1 Server Garbage Collection
Some users might experience resource contention that limits the parallelism they are expecting when the Garbage Collector is not properly configured. Whenever EF is used in a multithreaded scenario, or in any application that resembles a server-side system, make sure to enable Server Garbage Collection. This is done via a simple setting in your application config file:
<?xmlversion="1.0" encoding="utf-8" ?>
<configuration>
<runtime>
<gcServer enabled="true" />
</runtime>
</configuration>
This should decrease your thread contention and increase your throughput by up to 30% in CPU saturated scenarios. In general terms, you should always test how your application behaves using the classic Garbage Collection (which is better tuned for UI and client side scenarios) as well as the Server Garbage Collection.
9.2 AutoDetectChanges
As mentioned earlier, Entity Framework might show performance issues when the object cache has many entities. Certain operations, such as Add, Remove, Find, Entry and SaveChanges, trigger calls to DetectChanges which might consume a large amount of CPU based on how large the object cache has become. The reason for this is that the object cache and the object state manager try to stay as synchronized as possible on each operation performed to a context so that the produced data is guaranteed to be correct under a wide array of scenarios.
It is generally a good practice to leave Entity Framework’s automatic change detection enabled for the entire life of your application. If your scenario is being negatively affected by high CPU usage and your profiles indicate that the culprit is the call to DetectChanges, consider temporarily turning off AutoDetectChanges in the sensitive portion of your code:
try
{
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
...
}
finally
{
context.Configuration.AutoDetectChangesEnabled = true;
}
Before turning off AutoDetectChanges, it’s good to understand that this might cause Entity Framework to lose its ability to track certain information about the changes that are taking place on the entities. If handled incorrectly, this might cause data inconsistency on your application. For more information on turning off AutoDetectChanges, read <http://blog.oneunicorn.com/2012/03/12/secrets-of-detectchanges-part-3-switching-off-automatic-detectchanges/>.
9.3 Context per request
Entity Framework’s contexts are meant to be used as short-lived instances in order to provide the most optimal performance experience. Contexts are expected to be short lived and discarded, and as such have been implemented to be very lightweight and reutilize metadata whenever possible. In web scenarios it’s important to keep this in mind and not have a context for more than the duration of a single request. Similarly, in non-web scenarios, context should be discarded based on your understanding of the different levels of caching in the Entity Framework. Generally speaking, one should avoid having a context instance throughout the life of the application, as well as contexts per thread and static contexts.
9.4 Database null semantics
Entity Framework by default will generate SQL code that has C# null comparison semantics. Consider the following example query:
int? categoryId = 7;
int? supplierId = 8;
decimal? unitPrice = 0;
short? unitsInStock = 100;
short? unitsOnOrder = 20;
short? reorderLevel = null;
var q = from p incontext.Products
where p.Category.CategoryName == "Beverages"
|| (p.CategoryID == categoryId
|| p.SupplierID == supplierId
|| p.UnitPrice == unitPrice
|| p.UnitsInStock == unitsInStock
|| p.UnitsOnOrder == unitsOnOrder
|| p.ReorderLevel == reorderLevel)
select p;
var r = q.ToList();
In this example, we’re comparing a number of nullable variables against nullable properties on the entity, such as SupplierID and UnitPrice. The generated SQL for this query will ask if the parameter value is the same as the column value, or if both the parameter and the column values are null. This will hide the way the database server handles nulls and will provide a consistent C# null experience across different database vendors. On the other hand, the generated code is a bit convoluted and may not perform well when the amount of comparisons in the where statement of the query grows to a large number.
One way to deal with this situation is by using database null semantics. Note that this might potentially behave differently to the C# null semantics since now Entity Framework will generate simpler SQL that exposes the way the database engine handles null values. Database null semantics can be activated per-context with one single configuration line against the context configuration:
context.Configuration.UseDatabaseNullSemantics = true;
Small to medium sized queries will not display a perceptible performance improvement when using database null semantics, but the difference will become more noticeable on queries with a large number of potential null comparisons.
In the example query above, the performance difference was less than 2% in a microbenchmark running in a controlled environment.
9.5 Async
Entity Framework 6 introduced support of async operations when running on .NET 4.5 or later. For the most part, applications that have IO related contention will benefit the most from using asynchronous query and save operations. If your application does not suffer from IO contention, the use of async will, in the best cases, run synchronously and return the result in the same amount of time as a synchronous call, or in the worst case, simply defer execution to an asynchronous task and add extra time to the completion of your scenario.
For information on how asynchronous programming work that will help you deciding if async will improve the performance of your application, see Asynchronous Programming with Async and Await. For more information on the use of async operations on Entity Framework, see Async Query and Save.
9.6 NGEN
Entity Framework 6 does not come in the default installation of .NET framework. As such, the Entity Framework assemblies are not NGEN’d by default which means that all the Entity Framework code is subject to the same JIT’ing costs as any other MSIL assembly. This might degrade the F5 experience while developing and also the cold startup of your application in the production environments. In order to reduce the CPU and memory costs of JIT’ing it is advisable to NGEN the Entity Framework images as appropriate. For more information on how to improve the startup performance of Entity Framework 6 with NGEN, see Improving Startup Performance with NGen.
9.7 Code First versus EDMX
Entity Framework reasons about the impedance mismatch problem between object oriented programming and relational databases by having an in-memory representation of the conceptual model (the objects), the storage schema (the database) and a mapping between the two. This metadata is called an Entity Data Model, or EDM for short. From this EDM, Entity Framework will derive the views to roundtrip data from the objects in memory to the database and back.
When Entity Framework is used with an EDMX file that formally specifies the conceptual model, the storage schema, and the mapping, then the model loading stage only has to validate that the EDM is correct (for example, make sure that no mappings are missing), then generate the views, then validate the views and have this metadata ready for use. Only then can a query be executed or new data be saved to the data store.
The Code First approach is, at its heart, a sophisticated Entity Data Model generator. The Entity Framework has to produce an EDM from the provided code; it does so by analyzing the classes involved in the model, applying conventions and configuring the model via the Fluent API. After the EDM is built, the Entity Framework essentially behaves the same way as it would had an EDMX file been present in the project. Thus, building the model from Code First adds extra complexity that translates into a slower startup time for the Entity Framework when compared to having an EDMX. The cost is completely dependent on the size and complexity of the model that’s being built.
When choosing to use EDMX versus Code First, it’s important to know that the flexibility introduced by Code First increases the cost of building the model for the first time. If your application can withstand the cost of this first-time load then typically Code First will be the preferred way to go.
10 Investigating Performance
10.1 Using the Visual Studio Profiler
If you are having performance issues with the Entity Framework, you can use a profiler like the one built into Visual Studio to see where your application is spending its time. This is the tool we used to generate the pie charts in the “Exploring the Performance of the ADO.NET Entity Framework - Part 1” blog post ( <https://learn.microsoft.com/archive/blogs/adonet/exploring-the-performance-of-the-ado-net-entity-framework-part-1>) that show where Entity Framework spends its time during cold and warm queries.
The "Profiling Entity Framework using the Visual Studio 2010 Profiler" blog post written by the Data and Modeling Customer Advisory Team shows a real-world example of how they used the profiler to investigate a performance problem. <https://learn.microsoft.com/archive/blogs/dmcat/profiling-entity-framework-using-the-visual-studio-2010-profiler>. This post was written for a windows application. If you need to profile a web application the Windows Performance Recorder (WPR) and Windows Performance Analyzer (WPA) tools may work better than working from Visual Studio. WPR and WPA are part of the Windows Performance Toolkit which is included with the Windows Assessment and Deployment Kit.
10.2 Application/Database profiling
Tools like the profiler built into Visual Studio tell you where your application is spending time. Another type of profiler is available that performs dynamic analysis of your running application, either in production or pre-production depending on needs, and looks for common pitfalls and anti-patterns of database access.
Two commercially available profilers are the Entity Framework Profiler ( <http://efprof.com>) and ORMProfiler ( <http://ormprofiler.com>).
If your application is an MVC application using Code First, you can use StackExchange's MiniProfiler. Scott Hanselman describes this tool in his blog at: <http://www.hanselman.com/blog/NuGetPackageOfTheWeek9ASPNETMiniProfilerFromStackExchangeRocksYourWorld.aspx>.
For more information on profiling your application's database activity, see Julie Lerman's MSDN Magazine article titled Profiling Database Activity in the Entity Framework.
10.3 Database logger
If you are using Entity Framework 6 also consider using the built-in logging functionality. The Database property of the context can be instructed to log its activity via a simple one-line configuration:
using (var context = newQueryComparison.DbC.NorthwindEntities())
{
context.Database.Log = Console.WriteLine;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
In this example the database activity will be logged to the console, but the Log property can be configured to call any Action<string> delegate.
If you want to enable database logging without recompiling, and you are using Entity Framework 6.1 or later, you can do so by adding an interceptor in the web.config or app.config file of your application.
<interceptors>
<interceptor type="System.Data.Entity.Infrastructure.Interception.DatabaseLogger, EntityFramework">
<parameters>
<parameter value="C:\Path\To\My\LogOutput.txt"/>
</parameters>
</interceptor>
</interceptors>
For more information on how to add logging without recompiling go to <http://blog.oneunicorn.com/2014/02/09/ef-6-1-turning-on-logging-without-recompiling/>.
11 Appendix
11.1 A. Test Environment
This environment uses a 2-machine setup with the database on a separate machine from the client application. Machines are in the same rack, so network latency is relatively low, but more realistic than a single-machine environment.
11.1.1 App Server
11.1.1.1 Software Environment
- Entity Framework 4 Software Environment
- OS Name: Windows Server 2008 R2 Enterprise SP1.
- Visual Studio 2010 – Ultimate.
- Visual Studio 2010 SP1 (only for some comparisons).
- Entity Framework 5 and 6 Software Environment
- OS Name: Windows 8.1 Enterprise
- Visual Studio 2013 – Ultimate.
11.1.1.2 Hardware Environment
- Dual Processor: Intel(R) Xeon(R) CPU L5520 W3530 @ 2.27GHz, 2261 Mhz8 GHz, 4 Core(s), 84 Logical Processor(s).
- 2412 GB RamRAM.
- 136 GB SCSI250GB SATA 7200 rpm 3GB/s drive split into 4 partitions.
11.1.2 DB server
11.1.2.1 Software Environment
- OS Name: Windows Server 2008 R28.1 Enterprise SP1.
- SQL Server 2008 R22012.
11.1.2.2 Hardware Environment
- Single Processor: Intel(R) Xeon(R) CPU L5520 @ 2.27GHz, 2261 MhzES-1620 0 @ 3.60GHz, 4 Core(s), 8 Logical Processor(s).
- 824 GB RamRAM.
- 465 GB ATA500GB SATA 7200 rpm 6GB/s drive split into 4 partitions.
11.2 B. Query performance comparison tests
The Northwind model was used to execute these tests. It was generated from the database using the Entity Framework designer. Then, the following code was used to compare the performance of the query execution options:
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.Common;
using System.Data.Entity.Infrastructure;
using System.Data.EntityClient;
using System.Data.Objects;
using System.Linq;
namespace QueryComparison
{
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IQueryable<Product> InvokeProductsForCategoryCQ(string categoryName)
{
return productsForCategoryCQ(this, categoryName);
}
}
public class QueryTypePerfComparison
{
private static string entityConnectionStr = @"metadata=res://*/Northwind.csdl|res://*/Northwind.ssdl|res://*/Northwind.msl;provider=System.Data.SqlClient;provider connection string='data source=.;initial catalog=Northwind;integrated security=True;multipleactiveresultsets=True;App=EntityFramework'";
public void LINQIncludingContextCreation()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTracking()
{
using (NorthwindEntities context = new NorthwindEntities())
{
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void CompiledQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.InvokeProductsForCategoryCQ("Beverages");
q.ToList();
}
}
public void ObjectQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
products.ToList();
}
}
public void EntityCommand()
{
using (EntityConnection eConn = new EntityConnection(entityConnectionStr))
{
eConn.Open();
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
List<Product> productsList = new List<Product>();
while (reader.Read())
{
DbDataRecord record = (DbDataRecord)reader.GetValue(0);
// 'materialize' the product by accessing each field and value. Because we are materializing products, we won't have any nested data readers or records.
int fieldCount = record.FieldCount;
// Treat all products as Product, even if they are the subtype DiscontinuedProduct.
Product product = new Product();
product.ProductID = record.GetInt32(0);
product.ProductName = record.GetString(1);
product.SupplierID = record.GetInt32(2);
product.CategoryID = record.GetInt32(3);
product.QuantityPerUnit = record.GetString(4);
product.UnitPrice = record.GetDecimal(5);
product.UnitsInStock = record.GetInt16(6);
product.UnitsOnOrder = record.GetInt16(7);
product.ReorderLevel = record.GetInt16(8);
product.Discontinued = record.GetBoolean(9);
productsList.Add(product);
}
}
}
}
public void ExecuteStoreQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectResult<Product> beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Database.SqlQuery\<QueryComparison.DbC.Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbSet()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Products.SqlQuery(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void LINQIncludingContextCreationDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTrackingDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.AsNoTracking().Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
}
}
11.3 C. Navision Model
The Navision database is a large database used to demo Microsoft Dynamics – NAV. The generated conceptual model contains 1005 entity sets and 4227 association sets. The model used in the test is “flat” – no inheritance has been added to it.
11.3.1 Queries used for Navision tests
The queries list used with the Navision model contains 3 categories of Entity SQL queries:
11.3.1.1 Lookup
A simple lookup query with no aggregations
- Count: 16232
- Example:
<Query complexity="Lookup">
<CommandText>Select value distinct top(4) e.Idle_Time From NavisionFKContext.Session as e</CommandText>
</Query>
11.3.1.2 SingleAggregating
A normal BI query with multiple aggregations, but no subtotals (single query)
- Count: 2313
- Example:
<Query complexity="SingleAggregating">
<CommandText>NavisionFK.MDF_SessionLogin_Time_Max()</CommandText>
</Query>
Where MDF_SessionLogin_Time_Max() is defined in the model as:
<Function Name="MDF_SessionLogin_Time_Max" ReturnType="Collection(DateTime)">
<DefiningExpression>SELECT VALUE Edm.Min(E.Login_Time) FROM NavisionFKContext.Session as E</DefiningExpression>
</Function>
11.3.1.3 AggregatingSubtotals
A BI query with aggregations and subtotals (via union all)
- Count: 178
- Example:
<Query complexity="AggregatingSubtotals">
<CommandText>
using NavisionFK;
function AmountConsumed(entities Collection([CRONUS_International_Ltd__Zone])) as
(
Edm.Sum(select value N.Block_Movement FROM entities as E, E.CRONUS_International_Ltd__Bin as N)
)
function AmountConsumed(P1 Edm.Int32) as
(
AmountConsumed(select value e from NavisionFKContext.CRONUS_International_Ltd__Zone as e where e.Zone_Ranking = P1)
)
----------------------------------------------------------------------------------------------------------------------
(
select top(10) Zone_Ranking, Cross_Dock_Bin_Zone, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking, E.Cross_Dock_Bin_Zone
)
union all
(
select top(10) Zone_Ranking, Cast(null as Edm.Byte) as P2, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking
)
union all
{
Row(Cast(null as Edm.Int32) as P1, Cast(null as Edm.Byte) as P2, AmountConsumed(select value E
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed))
}</CommandText>
<Parameters>
<Parameter Name="MinAmountConsumed" DbType="Int32" Value="10000" />
</Parameters>
</Query>