หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
ใช้พูล Spark แบบกําหนดเองเพื่อปรับแต่งการประมวลผลสําหรับปริมาณงานของคุณใน Fabric คุณสามารถเลือกขนาดโหนด กําหนดค่าพฤติกรรมการปรับขนาดอัตโนมัติ และเปิดใช้งานการจัดสรรตัวดําเนินการแบบไดนามิกได้
พูลแบบกําหนดเองช่วยให้คุณสร้างสมดุลระหว่างประสิทธิภาพและต้นทุนโดยให้คุณตั้งค่าขีดจํากัดการปรับขนาดที่ตรงกับความต้องการของปริมาณงาน
Note
พูล Spark แบบกําหนดเองสามารถเริ่มต้นเซสชันได้ประมาณ 5 วินาทีเมื่อกําหนดค่าเป็น พูลสดแบบกําหนดเอง ด้วยสภาพแวดล้อมที่ใช้โหมดเต็มสําหรับการเผยแพร่ไลบรารี หากไม่มีการกําหนดค่าพูลแบบสด พูล Spark แบบกําหนดเองจะใช้เวลาประมาณสามนาทีในการเริ่มต้น
หากคุณใช้พูลเริ่มต้นอยู่แล้ว พูลแบบกําหนดเองเป็นตัวเลือกเสริมเมื่อคุณต้องการควบคุมพฤติกรรมการปรับขนาดและการปรับขนาดสําหรับปริมาณงานที่เฉพาะเจาะจงได้มากขึ้น ใช้พูลเริ่มต้นสําหรับการเริ่มต้นอย่างรวดเร็วและการตั้งค่าเริ่มต้น และย้ายไปยังพูลแบบกําหนดเองเมื่อคุณต้องการการปรับแต่งการประมวลผลเฉพาะปริมาณงาน หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับพูลเริ่มต้น โปรดดู กําหนดค่าพูลเริ่มต้นใน Fabric
ข้อกําหนดเบื้องต้น
วิธีสร้างพูล Spark แบบกําหนดเอง
- คุณต้องมีบทบาท ผู้ดูแลระบบ ในพื้นที่ทํางาน
- ผู้ดูแลระบบความจุต้องเปิดใช้งาน พูลพื้นที่ทํางานแบบกําหนดเอง ในการตั้งค่า Spark Compute สําหรับความจุ
สําหรับข้อมูลเพิ่มเติม โปรดดู กําหนดค่าและจัดการการตั้งค่าวิศวกรรมข้อมูลและวิทยาศาสตร์ข้อมูลสําหรับความจุ Fabric
สร้างพูล Spark แบบกําหนดเอง
เมื่อต้องสร้างหรือจัดการพูล Spark ที่เชื่อมโยงกับพื้นที่ทํางานของคุณ:
ไปที่พื้นที่ทํางานของคุณ แล้วเลือก การตั้งค่าพื้นที่ทํางาน

เลือกตัวเลือก วิศวกรรมข้อมูล/วิทยาศาสตร์
เพื่อขยายเมนู จากนั้นเลือก การตั้งค่า Spark 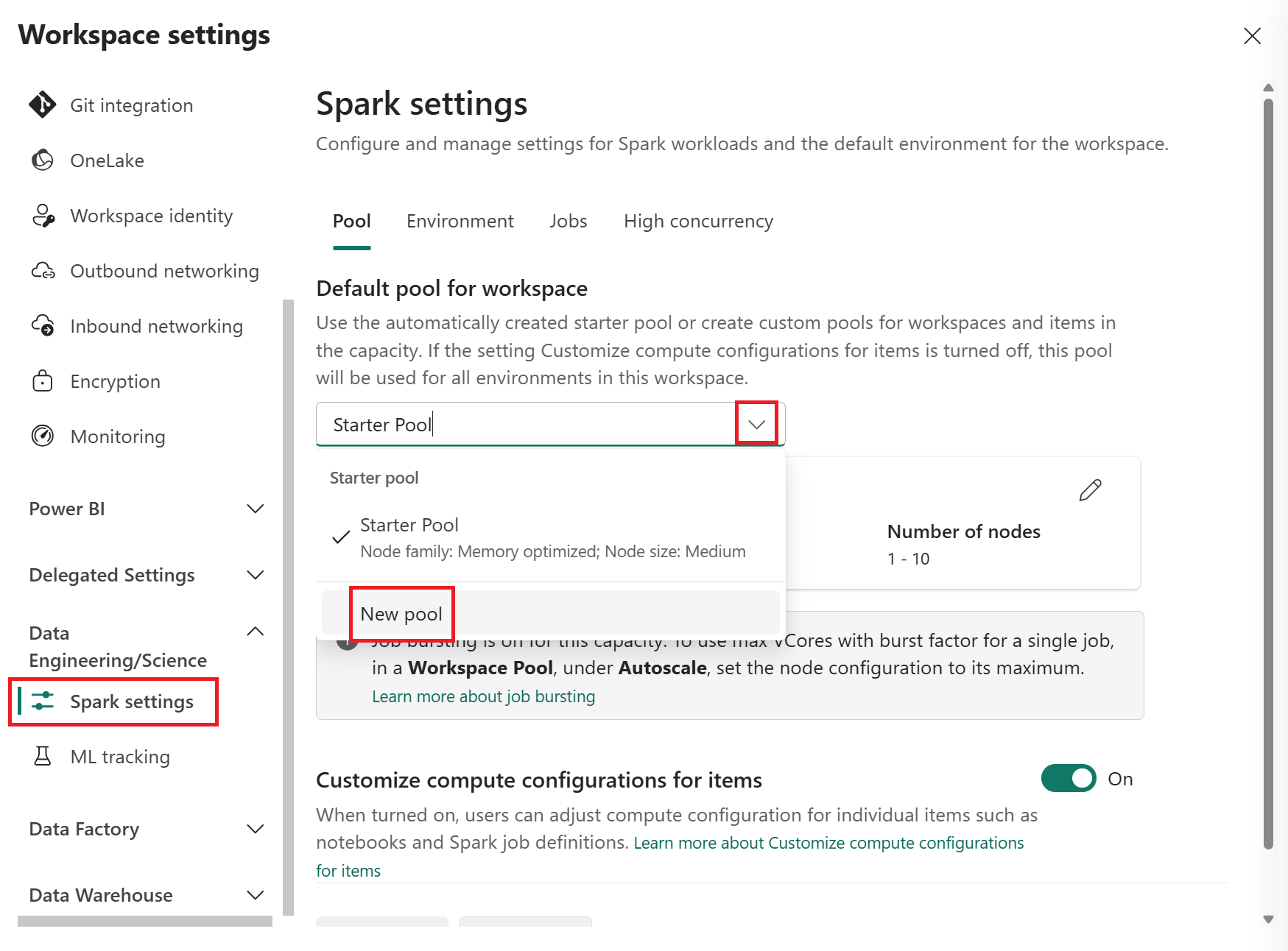
เลือก พูลใหม่ จากดรอปดาวน์ พูลเริ่มต้นสําหรับพื้นที่ทํางาน เพื่อสร้างพูล Spark แบบกําหนดเองใหม่ คุณสามารถสร้างพูลแบบกําหนดเองได้หลายพูล และเลือกพูลใดก็ได้เป็นพูลเริ่มต้นสําหรับพื้นที่ทํางานของคุณ
บนหน้า สร้างพูลใหม่ ให้ป้อนชื่อพูล เลือก ตระกูลโหนด (เช่น หน่วยความจําที่ปรับให้เหมาะสม) และ ขนาดโหนด ตามความต้องการปริมาณงาน สําหรับข้อมูลเพิ่มเติมเกี่ยวกับขนาดโหนด โปรดดูส่วน ตัวเลือกขนาดโหนด ด้านล่าง
เคล็ดลับ
ขนาดโหนดถูกกําหนดโดย หน่วยความจุ (CU) ซึ่งแสดงถึงความสามารถในการประมวลผลที่กําหนดให้กับแต่ละโหนด
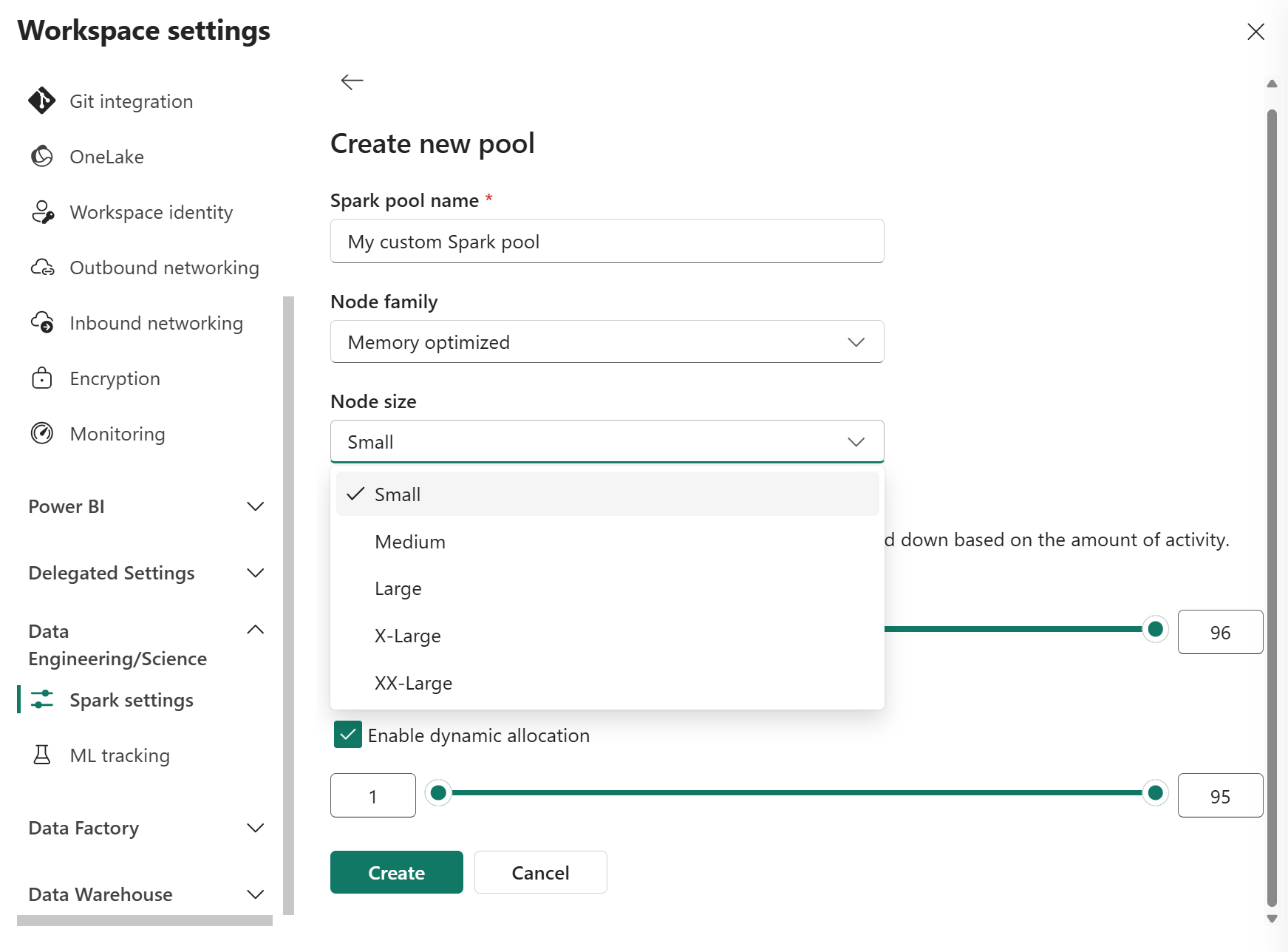
ในมุมมองแก้ไข ให้กําหนดค่า ปรับขนาดอัตโนมัติ และ จัดสรรตัวดําเนินการแบบไดนามิก
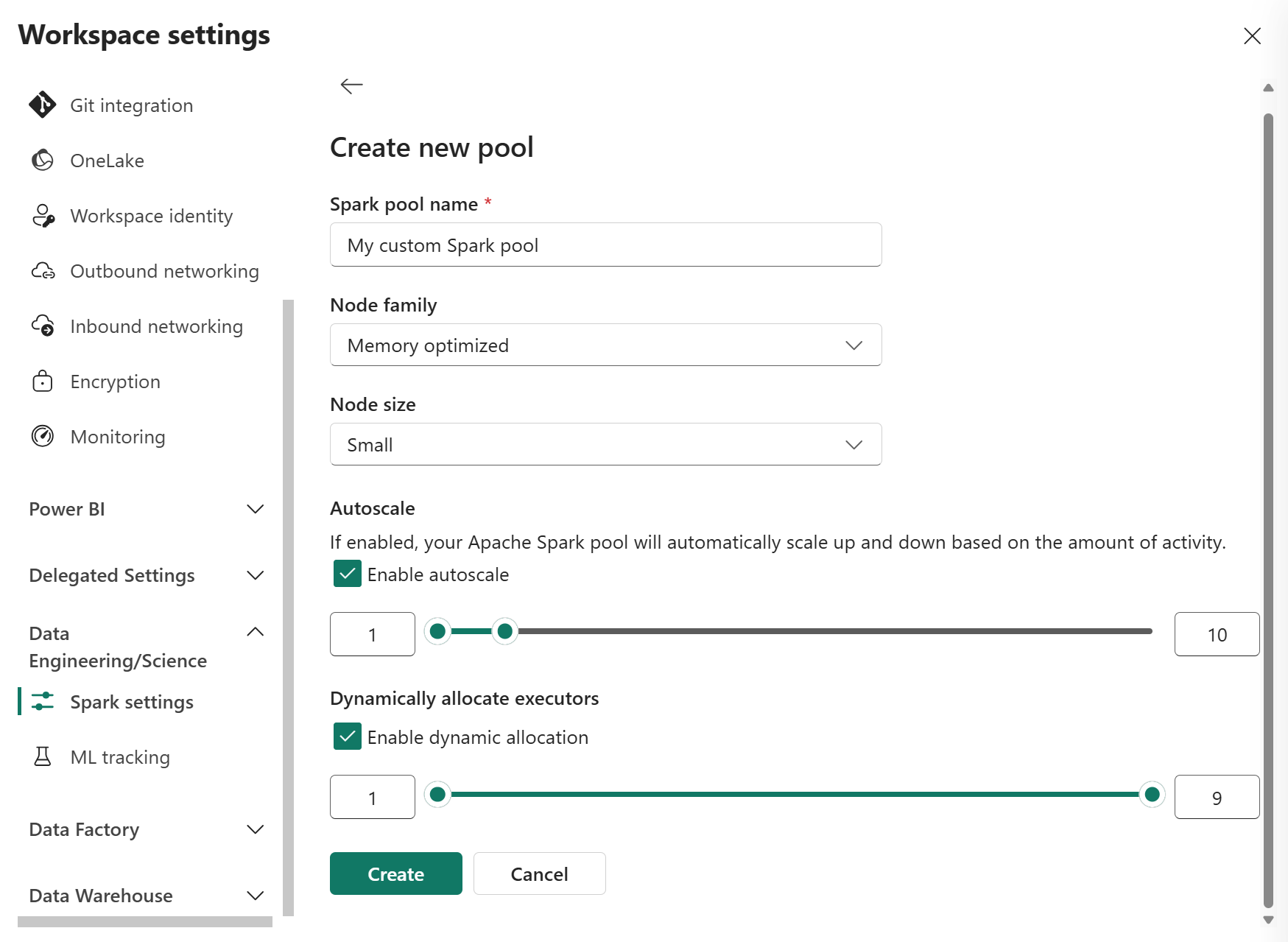
ใช้แถบเลื่อนเพื่อเพิ่มหรือลดการตั้งค่าแต่ละรายการตามความต้องการปริมาณงานของคุณ
หากเปิดใช้งาน การปรับขนาดอัตโนมัติ พูลจะปรับขนาดระหว่างค่าโหนดต่ําสุดและสูงสุดที่กําหนดค่าไว้ตามกิจกรรม
ถ้าเปิดใช้งาน จัดสรรตัวดําเนินการแบบไดนามิก Fabric จะปรับการปันส่วนตัวดําเนินการตามความต้องการปริมาณงานภายในขอบเขตที่กําหนดค่าไว้
เลือก สร้าง




เคล็ดลับ
หลังจากที่คุณสร้างพูล Spark แบบกําหนดเอง ระยะเวลาการปรับใช้ไลบรารีจะขึ้นอยู่กับโหมดการเผยแพร่ในสภาพแวดล้อมที่แนบมา โหมดด่วนจะเผยแพร่ในเวลาประมาณ 5 วินาที และติดตั้งไลบรารีเมื่อเริ่มต้นเซสชัน โหมดเต็มใช้เวลา 3 ถึง 6 นาทีในการเผยแพร่และปรับใช้ไลบรารีเป็นส่วนหนึ่งของการเริ่มต้นเซสชัน (1 ถึง 3 นาที) เพื่อประสบการณ์ที่เร็วที่สุด ให้กําหนดค่าพูลเป็น พูลสดแบบกําหนดเอง ด้วยโหมดเต็มเพื่อให้เซสชันเริ่มต้นได้ประมาณ 5 วินาที
พูลแบบกําหนดเองมีระยะเวลาหยุดชั่วคราวอัตโนมัติเริ่มต้นที่ 2 นาทีหลังจากไม่มีการใช้งาน เมื่อถึงการหยุดชั่วคราวอัตโนมัติ เซสชันจะหมดอายุและคลัสเตอร์จะยกเลิกการจัดสรร การเรียกเก็บเงินจะมีผลเฉพาะในขณะที่มีการใช้การประมวลผลเท่านั้น ปัจจุบันพูล Spark แบบกําหนดเองใน Microsoft Fabric รองรับขีดจํากัดโหนดสูงสุดที่ 200 ดังนั้นตรวจสอบให้แน่ใจว่าค่าการปรับขนาดอัตโนมัติต่ําสุดและสูงสุดของคุณยังคงอยู่ภายในขีดจํากัดนี้
ตัวเลือกขนาดโหนด
เมื่อคุณตั้งค่าพูล Spark แบบกําหนดเอง คุณจะเลือกจากขนาดโหนดต่อไปนี้:
| ขนาดโหนด | วีคอร์ | หน่วยความจํา (GB) | คำอธิบาย |
|---|---|---|---|
| เล็ก | 4 | 32 | ·สําหรับงานพัฒนาและทดสอบที่มีน้ําหนักเบา |
| ขนาดปานกลาง | 8 | 64 | สําหรับปริมาณงานทั่วไปและการทํางานทั่วไป |
| ใหญ่ | 16 | 128 | สําหรับงานที่ต้องใช้หน่วยความจํามากหรืองานประมวลผลข้อมูลขนาดใหญ่ |
| X-Large | 32 | 256 | สําหรับปริมาณงาน Spark ที่มีความต้องการมากที่สุดซึ่งต้องการทรัพยากรจํานวนมาก |
| XX-ขนาดใหญ่ | 64 | 512 | สําหรับปริมาณงาน Spark ที่ใหญ่ที่สุดที่ต้องการการประมวลผลและหน่วยความจําสูงสุดต่อโหนด |
เนื้อหาที่เกี่ยวข้อง
- เรียนรู้เพิ่มเติมจากคู่มือสาธารณะของ Apache Spark
- เริ่มต้นใช้งานการตั้งค่าการดูแลพื้นที่ทํางาน Spark ใน Microsoft Fabric
- จัดการไลบรารีในสภาพแวดล้อม Fabric