หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
บทความนี้สรุปวิธีการใช้กิจกรรมการคัดลอกในไปป์ไลน์เพื่อคัดลอกข้อมูลจากและไปยังอินสแตนซ์ที่มีการจัดการของ Azure SQL
การกําหนดค่าที่รองรับ
สําหรับการกําหนดค่าของแต่ละแท็บภายใต้กิจกรรมการคัดลอก ให้ไปที่ส่วนต่อไปนี้ตามลําดับ
General
โปรดดูคําแนะนําการตั้งค่าทั่วไปเพื่อกําหนดค่าแท็บ การตั้งค่าทั่วไป
ที่มา
คุณสมบัติต่อไปนี้ได้รับการสนับสนุนสําหรับอินสแตนซ์ที่มีการจัดการของ Azure SQL ภายใต้แท็บ แหล่งที่มา ของกิจกรรมการคัดลอก
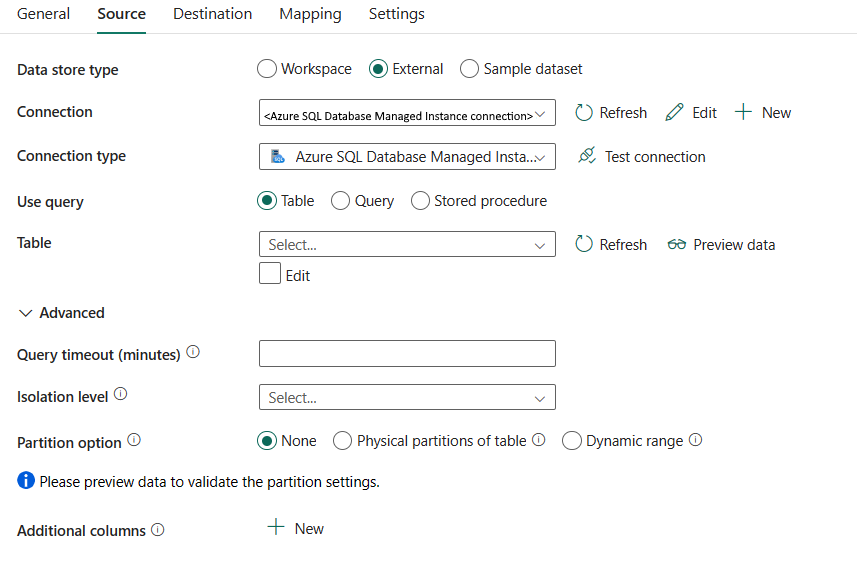
คุณสมบัติต่อไปนี้ เป็นสิ่งจําเป็น:
การเชื่อมต่อ: เลือกการเชื่อมต่อ Azure SQL Managed Instance จากรายการการเชื่อมต่อ หากไม่มีการเชื่อมต่อ ให้สร้างการเชื่อมต่อ Azure SQL Managed Instance ใหม่โดยเลือก สร้าง
ชนิดการเชื่อมต่อ: เลือก Azure SQL Managed Instance
ใช้แบบสอบถาม: ระบุวิธีการอ่านข้อมูล คุณสามารถเลือก ตารางแบบสอบถาม หรือ กระบวนงานที่เก็บไว้ รายการต่อไปนี้อธิบายการกําหนดค่าของการตั้งค่าแต่ละรายการ:
ตาราง: อ่านข้อมูลจากตารางที่ระบุ เลือกตารางต้นทางของคุณจากรายการดรอปดาวน์ หรือเลือก แก้ไข เพื่อป้อนด้วยตนเอง
คิวรี: ระบุคิวรี SQL แบบกําหนดเองเพื่ออ่านข้อมูล ตัวอย่างคือ
select * from MyTable. หรือเลือกไอคอนดินสอเพื่อแก้ไขในตัวแก้ไขโค้ด
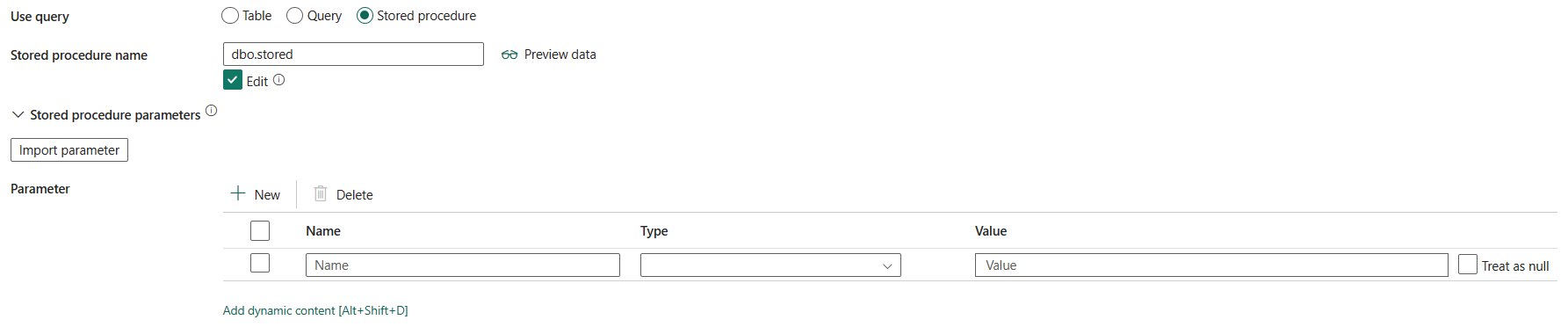
กระบวนงานที่เก็บไว้: ใช้กระบวนงานที่เก็บไว้ที่อ่านข้อมูลจากตารางต้นฉบับ คําสั่ง SQL สุดท้ายต้องเป็นคําสั่ง SELECT ในกระบวนงานที่เก็บไว้
ชื่อกระบวนงานที่เก็บไว้: เลือกกระบวนงานที่เก็บไว้หรือระบุชื่อกระบวนงานที่เก็บไว้ด้วยตนเองเมื่อเลือก แก้ไข เพื่ออ่านข้อมูลจากตารางต้นทาง
พารามิเตอร์กระบวนงานที่เก็บไว้: ระบุค่าสําหรับพารามิเตอร์กระบวนงานที่เก็บไว้ ค่าที่อนุญาตคือคู่ชื่อหรือค่า ชื่อและตัวพิมพ์ใหญ่ของพารามิเตอร์ต้องตรงกับชื่อและตัวพิมพ์ใหญ่ของพารามิเตอร์กระบวนงานที่เก็บไว้ คุณสามารถเลือก นําเข้าพารามิเตอร์ เพื่อรับพารามิเตอร์กระบวนงานที่เก็บไว้ของคุณ
ภายใต้ ขั้นสูง คุณสามารถระบุฟิลด์ต่อไปนี้:
การหมดเวลาของคิวรี (นาที): ระบุการหมดเวลาสําหรับการดําเนินการคําสั่งคิวรี ค่าเริ่มต้นคือ 120 นาที ถ้าตั้งค่าพารามิเตอร์สําหรับคุณสมบัตินี้ ค่าที่อนุญาตคือช่วงเวลา เช่น "02:00:00" (120 นาที)
ระดับการแยก: ระบุลักษณะการล็อกธุรกรรมสําหรับแหล่งข้อมูล SQL ค่าที่อนุญาตคือ: Read committed, Read uncommitted, Repeatable read, Serializable, Snapshot ถ้าไม่ได้ระบุ ระดับการแยกเริ่มต้นของฐานข้อมูลจะถูกใช้ อ้างถึง IsolationLevel Enum สําหรับรายละเอียดเพิ่มเติม
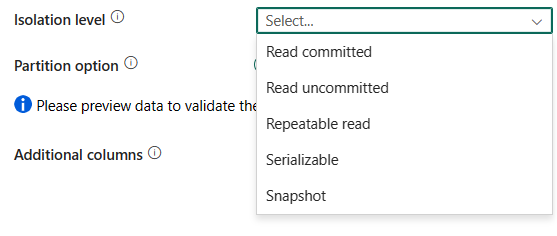
ตัวเลือกพาร์ติชัน: ระบุตัวเลือกการแบ่งพาร์ติชันข้อมูลที่ใช้ในการโหลดข้อมูลจาก Azure SQL Managed Instance ค่าที่อนุญาตคือ: ไม่มี (ค่าเริ่มต้น) พาร์ติชันทางกายภาพของตาราง และช่วงไดนามิก เมื่อเปิดใช้งานตัวเลือกพาร์ติชัน (นั่นคือ ไม่ใช่ ไม่มี) ระดับของความขนานในการโหลดข้อมูลพร้อมกันจากอินสแตนซ์ที่มีการจัดการของ Azure SQL จะถูกควบคุมโดย แท็บ ระดับของการคัดลอกแบบขนาน ในการตั้งค่ากิจกรรมการคัดลอก
ไม่มี: เลือกการตั้งค่านี้เพื่อไม่ใช้พาร์ติชัน
พาร์ติชันทางกายภาพของตาราง: เมื่อคุณใช้พาร์ติชันทางกายภาพ คอลัมน์พาร์ติชันและกลไกจะถูกกําหนดโดยอัตโนมัติตามข้อกําหนดของตารางทางกายภาพของคุณ
ช่วงไดนามิก: เมื่อคุณใช้คิวรีที่เปิดใช้งานแบบขนาน จําเป็นต้องใช้พารามิเตอร์พาร์ติชันช่วง (
?DfDynamicRangePartitionCondition) ตัวอย่างแบบสอบถาม:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.ชื่อคอลัมน์พาร์ติชัน: ระบุชื่อของคอลัมน์ต้นฉบับเป็นจํานวนเต็มหรือชนิดวันที่/วันที่และเวลา (
int,smallint, ,bigint,date,smalldatetimedatetimedatetime2หรือdatetimeoffset) ที่ใช้โดยการแบ่งพาร์ติชันช่วงสําหรับการคัดลอกแบบขนาน หากไม่ได้ระบุ ดัชนีหรือคีย์หลักของตารางจะถูกตรวจพบโดยอัตโนมัติและใช้เป็นคอลัมน์พาร์ติชันถ้าคุณใช้แบบสอบถามเพื่อดึงข้อมูลต้นฉบับ ให้ขอเกี่ยว
?DfDynamicRangePartitionConditionในส่วนคําสั่ง WHERE สําหรับตัวอย่าง โปรดดูส่วน สําเนาแบบขนานจากอินสแตนซ์ที่มีการจัดการของ Azure SQLขอบเขตบนของพาร์ติชัน: ระบุค่าสูงสุดของคอลัมน์พาร์ติชันสําหรับการแยกช่วงพาร์ติชัน ค่านี้ใช้เพื่อกําหนดการก้าวของพาร์ติชัน ไม่ใช่สําหรับการกรองแถวในตาราง แถวทั้งหมดในตารางหรือผลลัพธ์แบบสอบถามจะถูกแบ่งพาร์ติชันและคัดลอก หากไม่ได้ระบุ ให้คัดลอกกิจกรรมจะตรวจหาค่าโดยอัตโนมัติ สําหรับตัวอย่าง โปรดดูส่วน สําเนาแบบขนานจากอินสแตนซ์ที่มีการจัดการของ Azure SQL
ขอบเขตล่างของพาร์ติชัน: ระบุค่าต่ําสุดของคอลัมน์พาร์ติชันสําหรับการแยกช่วงพาร์ติชัน ค่านี้ใช้เพื่อกําหนดการก้าวของพาร์ติชัน ไม่ใช่สําหรับการกรองแถวในตาราง แถวทั้งหมดในตารางหรือผลลัพธ์แบบสอบถามจะถูกแบ่งพาร์ติชันและคัดลอก หากไม่ได้ระบุ ให้คัดลอกกิจกรรมจะตรวจหาค่าโดยอัตโนมัติ สําหรับตัวอย่าง โปรดดูส่วน สําเนาแบบขนานจากอินสแตนซ์ที่มีการจัดการของ Azure SQL
คอลัมน์เพิ่มเติม: เพิ่มคอลัมน์ข้อมูลเพิ่มเติมเพื่อจัดเก็บเส้นทางสัมพัทธ์หรือค่าคงที่ของไฟล์ต้นฉบับ นิพจน์ได้รับการสนับสนุนสําหรับรุ่นหลัง
สังเกตประเด็นต่อไปนี้:
- ถ้า มีการระบุคิวรี สําหรับแหล่งข้อมูล กิจกรรมการคัดลอกจะเรียกใช้คิวรีนี้กับแหล่งข้อมูลอินสแตนซ์ที่มีการจัดการของ Azure SQL เพื่อรับข้อมูล คุณยังสามารถระบุกระบวนงานที่เก็บไว้ได้ด้วยการระบุ ชื่อกระบวนงานที่เก็บไว้ และ พารามิเตอร์กระบวนงานที่เก็บไว้ ถ้ากระบวนงานที่เก็บไว้ใช้พารามิเตอร์
- เมื่อใช้กระบวนงานที่เก็บไว้ในแหล่งข้อมูลเพื่อดึงข้อมูล โปรดสังเกตว่ากระบวนงานที่เก็บไว้ของคุณได้รับการออกแบบให้ส่งกลับ Schema ที่แตกต่างกันเมื่อมีการส่งผ่านค่าพารามิเตอร์ที่แตกต่างกัน คุณอาจพบความล้มเหลว หรือเห็นผลลัพธ์ที่ไม่คาดคิดเมื่อนําเข้า Schema จาก UI หรือเมื่อคัดลอกข้อมูลไปยังฐานข้อมูล SQL ด้วยการสร้างตารางอัตโนมัติ
จุดหมาย
คุณสมบัติต่อไปนี้ได้รับการสนับสนุนสําหรับอินสแตนซ์ที่มีการจัดการของ Azure SQL ภายใต้แท็บ ปลายทาง ของกิจกรรมการคัดลอก
คุณสมบัติต่อไปนี้ เป็นสิ่งจําเป็น:
การเชื่อมต่อ: เลือกการเชื่อมต่อ Azure SQL Managed Instance จากรายการการเชื่อมต่อ หากไม่มีการเชื่อมต่อ ให้สร้างการเชื่อมต่อ Azure SQL Managed Instance ใหม่โดยเลือก สร้าง
ชนิดการเชื่อมต่อ: เลือก Azure SQL Managed Instance
ตัวเลือกตาราง: คุณสามารถเลือก ใช้ที่มีอยู่ เพื่อใช้ตารางที่ระบุ หรือเลือก สร้างตารางอัตโนมัติ เพื่อสร้างตารางปลายทางโดยอัตโนมัติถ้าตารางไม่มีอยู่ใน Schema ต้นทาง และโปรดสังเกตว่าการเลือกนี้ไม่ได้รับการสนับสนุนเมื่อใช้กระบวนงานที่เก็บไว้เป็นลักษณะการเขียน
หากคุณ เลือกใช้ที่มีอยู่:
- ตาราง: เลือกตารางในฐานข้อมูลปลายทางของคุณจากรายการดรอปดาวน์ หรือตรวจสอบ แก้ไข เพื่อป้อนชื่อตารางของคุณด้วยตนเอง
หากคุณเลือก: สร้างตารางอัตโนมัติ
- ตาราง: ระบุชื่อสําหรับตารางปลายทางที่สร้างขึ้นโดยอัตโนมัติ
ภายใต้ ขั้นสูง คุณสามารถระบุฟิลด์ต่อไปนี้:
พฤติกรรมการเขียน: กําหนดลักษณะการเขียนเมื่อแหล่งที่มาเป็นไฟล์จากที่เก็บข้อมูลแบบไฟล์ คุณสามารถเลือก แทรก **Upsert หรือกระบวนงานที่เก็บไว้
แทรก: เลือกตัวเลือกนี้ใช้ลักษณะการแทรกการเขียนเพื่อโหลดข้อมูลลงในอินสแตนซ์ที่มีการจัดการ Azure SQL
อัปเซิร์ต: เลือกตัวเลือกนี้ใช้พฤติกรรมการเขียนอัปเซิร์ตเพื่อโหลดข้อมูลลงในอินสแตนซ์ที่มีการจัดการของ Azure SQL
ใช้ TempDB: ระบุว่าจะใช้ตารางชั่วคราวส่วนกลางหรือตารางทางกายภาพเป็นตารางชั่วคราวสําหรับ upsert โดยค่าเริ่มต้น บริการจะใช้ตารางชั่วคราวส่วนกลางเป็นตารางชั่วคราว และคุณสมบัตินี้จะถูกเลือก
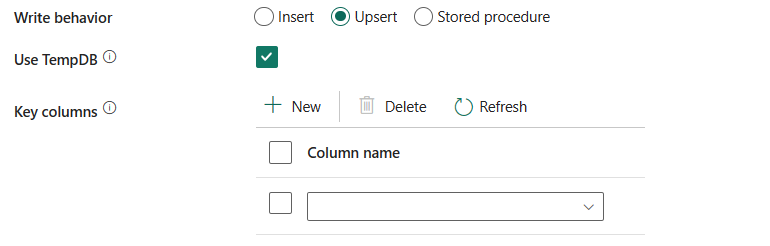
เลือก Schema DB ของผู้ใช้: เมื่อไม่ได้เลือก ใช้ TempDB ให้ระบุ Schema ชั่วคราวสําหรับการสร้างตารางชั่วคราวหากใช้ตารางทางกายภาพ
Note
คุณต้องมีสิทธิ์ในการสร้างและลบตาราง โดยค่าเริ่มต้น ตารางชั่วคราวจะใช้ Schema เดียวกันกับตารางปลายทาง
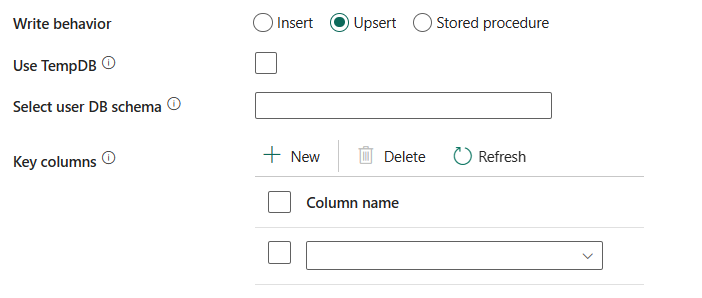
คอลัมน์หลัก: ระบุชื่อคอลัมน์สําหรับการระบุแถวที่ไม่ซ้ํากัน สามารถใช้ปุ่มเดียวหรือชุดปุ่มก็ได้ หากไม่ได้ระบุ จะใช้คีย์หลัก
กระบวนงานที่เก็บไว้: ใช้กระบวนงานที่เก็บไว้ซึ่งกําหนดวิธีการนําข้อมูลต้นฉบับไปใช้กับตารางเป้าหมาย กระบวนงานที่เก็บไว้นี้ถูกเรียกใช้ต่อชุดงาน สําหรับการดําเนินการที่เรียกใช้เพียงครั้งเดียวและไม่มีส่วนเกี่ยวข้องกับข้อมูลต้นฉบับ เช่น ลบหรือตัดทอน ให้ใช้คุณสมบัติสคริปต์คัดลอกล่วงหน้า
ชื่อกระบวนงานที่เก็บไว้: เลือกกระบวนงานที่เก็บไว้หรือระบุชื่อกระบวนงานที่เก็บไว้ด้วยตนเองเมื่อตรวจสอบไฟล์ แก้ไข เพื่ออ่านข้อมูลจากตารางต้นทาง
พารามิเตอร์กระบวนงานที่เก็บไว้:
- ชนิดตาราง: ระบุชื่อชนิดตารางที่จะใช้ในกระบวนงานที่เก็บไว้ กิจกรรมการคัดลอกทําให้ข้อมูลที่กําลังย้ายพร้อมใช้งานในตารางชั่วคราวด้วยชนิดตารางนี้ รหัสกระบวนงานที่เก็บไว้สามารถผสานข้อมูลที่กําลังคัดลอกกับข้อมูลที่มีอยู่ได้
- ชื่อพารามิเตอร์ชนิดตาราง: ระบุชื่อพารามิเตอร์ของชนิดตารางที่ระบุในกระบวนงานที่เก็บไว้
- พารามิเตอร์: ระบุค่าสําหรับพารามิเตอร์กระบวนงานที่เก็บไว้ ค่าที่อนุญาตคือคู่ชื่อหรือค่า ชื่อและตัวพิมพ์ใหญ่ของพารามิเตอร์ต้องตรงกับชื่อและตัวพิมพ์ใหญ่ของพารามิเตอร์กระบวนงานที่เก็บไว้ คุณสามารถเลือก นําเข้าพารามิเตอร์ เพื่อรับพารามิเตอร์กระบวนงานที่เก็บไว้ของคุณ
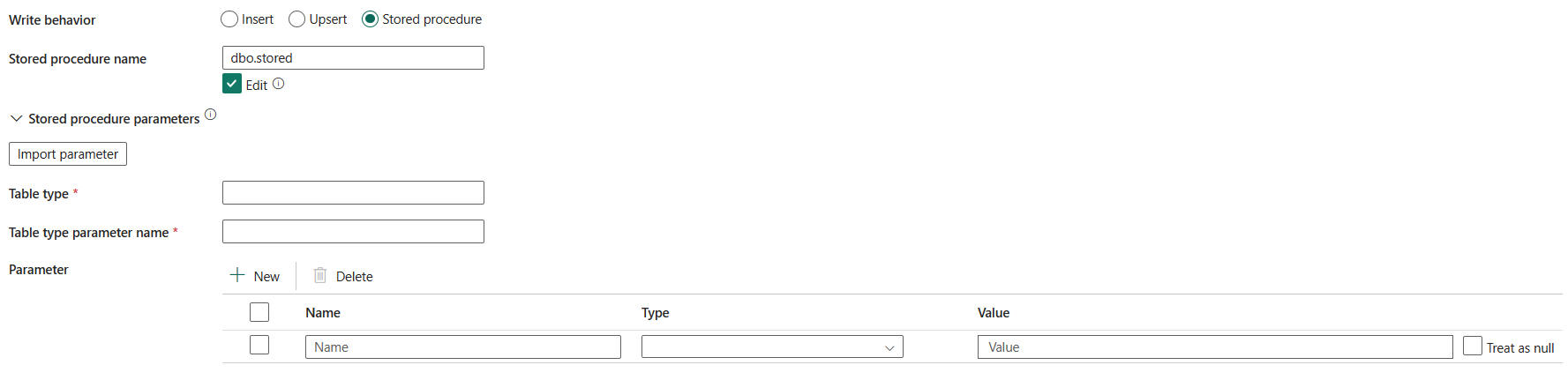
การล็อกตารางแทรกจํานวนมาก: เลือก ใช่ หรือ ไม่ใช่ (ค่าเริ่มต้น) ใช้การตั้งค่านี้เพื่อปรับปรุงประสิทธิภาพการคัดลอกในระหว่างการดําเนินการแทรกจํานวนมากบนตารางที่ไม่มีดัชนีจากไคลเอ็นต์หลายตัว คุณสามารถระบุคุณสมบัตินี้เมื่อคุณเลือก แทรก หรือ อัปเซิร์ต เป็นลักษณะการเขียนของคุณ สําหรับข้อมูลเพิ่มเติม ไปที่ BULK INSERT (Transact-SQL)
สคริปต์คัดลอกล่วงหน้า: ระบุสคริปต์สําหรับกิจกรรมการคัดลอกที่จะดําเนินการก่อนที่จะเขียนข้อมูลลงในตารางปลายทางในการเรียกใช้แต่ละครั้ง คุณสามารถใช้คุณสมบัตินี้เพื่อล้างข้อมูลที่โหลดไว้ล่วงหน้า
การหมดเวลาของชุดการเขียน: ระบุเวลารอให้การดําเนินการแทรกชุดงานเสร็จสิ้นก่อนที่จะหมดเวลา ค่าที่อนุญาตคือช่วงเวลา ถ้าไม่มีการระบุค่า การหมดเวลาจะมีค่าเริ่มต้นเป็น "02:00:00"
เขียนขนาดแบทช์: ระบุจํานวนแถวที่จะแทรกลงในตาราง SQL ต่อแบทช์ ค่าที่อนุญาตคือจํานวนเต็ม (จํานวนแถว) โดยค่าเริ่มต้น บริการจะกําหนดขนาดชุดงานที่เหมาะสมแบบไดนามิกตามขนาดแถว
การเชื่อมต่อพร้อมกันสูงสุด: ขีดจํากัดสูงสุดของการเชื่อมต่อพร้อมกันที่สร้างไปยังที่เก็บข้อมูลในระหว่างการเรียกใช้กิจกรรม ระบุค่าเมื่อคุณต้องการจํากัดการเชื่อมต่อที่เกิดขึ้นพร้อมกันเท่านั้น
การแม็ป
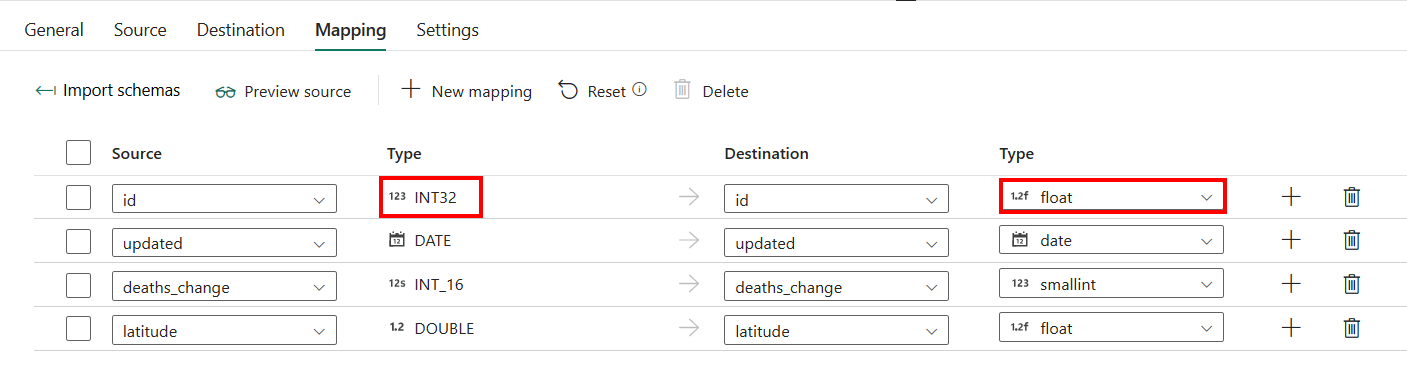
สําหรับการกําหนดค่าแท็บ การแม็ป หากคุณไม่ได้ใช้ Azure SQL Managed Instance ที่มีการสร้างตารางอัตโนมัติเป็นปลายทางของคุณ ให้ไปที่ การแม็ป
หากคุณใช้อินสแตนซ์ที่มีการจัดการ Azure SQL ที่มีตารางสร้างอัตโนมัติเป็นปลายทางของคุณ ยกเว้นการกําหนดค่าในการ แมป คุณสามารถแก้ไขชนิดสําหรับคอลัมน์ปลายทางของคุณได้ หลังจากเลือก นําเข้า Schema คุณสามารถระบุชนิดคอลัมน์ในปลายทางของคุณได้
ตัวอย่างเช่น ชนิดของคอลัมน์ ID ในแหล่งที่มาคือ int และคุณสามารถเปลี่ยนเป็นชนิดลอยได้เมื่อแม็ปกับคอลัมน์ปลายทาง
การตั้งค่า
สําหรับการกําหนดค่าแท็บการตั้งค่า ให้ไปที่ กําหนดการตั้งค่าอื่นๆ ภายใต้แท็บการตั้งค่า
สําเนาแบบขนานจากอินสแตนซ์ที่มีการจัดการของ Azure SQL
ตัวเชื่อมต่อ Azure SQL Managed Instance ในกิจกรรมการคัดลอกให้การแบ่งพาร์ติชันข้อมูลในตัวเพื่อคัดลอกข้อมูลแบบขนาน คุณสามารถค้นหาตัวเลือกการแบ่งพาร์ติชันข้อมูลได้ที่แท็บ แหล่งที่มา ของกิจกรรมการคัดลอก
เมื่อคุณเปิดใช้งานการคัดลอกแบบแบ่งพาร์ติชัน กิจกรรมการคัดลอกจะเรียกใช้คิวรีแบบขนานกับแหล่งข้อมูลอินสแตนซ์ที่มีการจัดการ Azure SQL ของคุณเพื่อโหลดข้อมูลตามพาร์ติชัน องศาขนานถูกควบคุมโดย ระดับการคัดลอกแบบขนาน ในแท็บการตั้งค่ากิจกรรมการคัดลอก ตัวอย่างเช่น ถ้าคุณตั้งค่า ระดับการคัดลอกแบบขนาน เป็น 4 บริการจะสร้างและเรียกใช้คิวรีสี่รายการพร้อมกันตามตัวเลือกและการตั้งค่าพาร์ติชันที่คุณระบุ และแต่ละคิวรีจะดึงข้อมูลบางส่วนจากอินสแตนซ์ที่มีการจัดการ Azure SQL ของคุณ
ขอแนะนําให้คุณเปิดใช้งานการคัดลอกแบบขนานด้วยการแบ่งพาร์ติชันข้อมูล โดยเฉพาะอย่างยิ่งเมื่อคุณโหลดข้อมูลจํานวนมากจากอินสแตนซ์ที่มีการจัดการ Azure SQL ของคุณ ต่อไปนี้เป็นการตั้งค่าคอนฟิกที่แนะนําสําหรับสถานการณ์ต่างๆ เมื่อคัดลอกข้อมูลไปยังที่เก็บข้อมูลตามไฟล์ ขอแนะนําให้เขียนลงในโฟลเดอร์เป็นหลายไฟล์ (ระบุเฉพาะชื่อโฟลเดอร์) ซึ่งในกรณีนี้ประสิทธิภาพจะดีกว่าการเขียนไปยังไฟล์เดียว
| สถานการณ์สมมติ | การตั้งค่าที่แนะนํา |
|---|---|
| โหลดเต็มที่จากโต๊ะขนาดใหญ่พร้อมพาร์ติชันทางกายภาพ |
ตัวเลือกพาร์ติชัน: พาร์ติชันทางกายภาพของตาราง ในระหว่างการดําเนินการ บริการจะตรวจพบพาร์ติชันทางกายภาพโดยอัตโนมัติ และคัดลอกข้อมูลตามพาร์ติชัน หากต้องการตรวจสอบว่าตารางของคุณมีพาร์ติชันจริงหรือไม่ คุณสามารถอ้างถึงแบบสอบถามนี้ |
| โหลดเต็มจากตารางขนาดใหญ่โดยไม่มีพาร์ติชันทางกายภาพในขณะที่มีคอลัมน์จํานวนเต็มหรือวันที่และเวลาสําหรับการแบ่งพาร์ติชันข้อมูล |
ตัวเลือกพาร์ติชัน: พาร์ติชันช่วงไดนามิก คอลัมน์พาร์ติชัน (ไม่บังคับ): ระบุคอลัมน์ที่ใช้ในการแบ่งพาร์ติชันข้อมูล หากไม่ได้ระบุ จะใช้คอลัมน์ดัชนีหรือคีย์หลัก ขอบเขตบนของพาร์ติชัน และ ขอบเขตล่างของพาร์ติชัน (ไม่บังคับ): ระบุว่าคุณต้องการกําหนดก้าวของพาร์ติชันหรือไม่ นี่ไม่ได้มีไว้สําหรับการกรองแถวในตารางแถวทั้งหมดในตารางจะถูกแบ่งพาร์ติชันและคัดลอก หากไม่ได้ระบุ กิจกรรมคัดลอกจะตรวจหาค่าโดยอัตโนมัติ ตัวอย่างเช่น ถ้าคอลัมน์พาร์ติชัน "ID" ของคุณมีค่าตั้งแต่ 1 ถึง 100 และคุณตั้งค่าขอบเขตล่างเป็น 20 และขอบเขตบนเป็น 80 โดยมีการคัดลอกแบบขนานเป็น 4 บริการจะดึงข้อมูลโดย 4 พาร์ติชัน - ID ในช่วง <=20, [21, 50], [51, 80] และ >=81 ตามลําดับ |
| โหลดข้อมูลจํานวนมากโดยใช้คิวรีแบบกําหนดเอง โดยไม่มีพาร์ติชันทางกายภาพ ในขณะที่มีคอลัมน์จํานวนเต็มหรือวันที่ / วันที่และเวลาสําหรับการแบ่งพาร์ติชันข้อมูล |
ตัวเลือกพาร์ติชัน: พาร์ติชันช่วงไดนามิก แบบสอบถาม: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.คอลัมน์พาร์ติชัน: ระบุคอลัมน์ที่ใช้ในการแบ่งพาร์ติชันข้อมูล ขอบเขตบนของพาร์ติชัน และ ขอบเขตล่างของพาร์ติชัน (ไม่บังคับ): ระบุว่าคุณต้องการกําหนดก้าวของพาร์ติชันหรือไม่ นี่ไม่ได้มีไว้สําหรับการกรองแถวในตาราง แถวทั้งหมดในผลลัพธ์แบบสอบถามจะถูกแบ่งพาร์ติชันและคัดลอก หากไม่ได้ระบุ ให้คัดลอกกิจกรรมจะตรวจหาค่าโดยอัตโนมัติ ตัวอย่างเช่น ถ้าคอลัมน์พาร์ติชัน "ID" ของคุณมีค่าตั้งแต่ 1 ถึง 100 และคุณตั้งค่าขอบเขตล่างเป็น 20 และขอบเขตบนเป็น 80 โดยมีการคัดลอกแบบขนานเป็น 4 บริการจะดึงข้อมูลโดย 4 พาร์ติชัน - ID ในช่วง <=20, [21, 50], [51, 80] และ >=81 ตามลําดับ ต่อไปนี้เป็นตัวอย่างการสืบค้นเพิ่มเติมสําหรับสถานการณ์ต่างๆ •สอบถามทั้งตาราง: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition•แบบสอบถามจากตารางที่มีการเลือกคอลัมน์และตัวกรอง where-clause เพิ่มเติม: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>•แบบสอบถามด้วยแบบสอบถามย่อย: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>•แบบสอบถามด้วยพาร์ติชันในแบบสอบถามย่อย: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
แนวทางปฏิบัติที่ดีที่สุดในการโหลดข้อมูลด้วยตัวเลือกพาร์ติชัน:
- เลือกคอลัมน์ที่ไม่ซ้ํากันเป็นคอลัมน์พาร์ติชัน (เช่น คีย์หลักหรือคีย์เฉพาะ) เพื่อหลีกเลี่ยงการเบ้ของข้อมูล
- หากตารางมีพาร์ติชันในตัว ให้ใช้ตัวเลือกพาร์ติชัน พาร์ติชันทางกายภาพของตาราง เพื่อให้ได้ประสิทธิภาพที่ดีขึ้น
คิวรีตัวอย่างเพื่อตรวจสอบพาร์ติชันทางกายภาพ
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
หากตารางมีพาร์ติชันจริงคุณจะเห็น "HasPartition" เป็น "ใช่" ดังต่อไปนี้

ข้อมูลสรุปของตาราง
ดูตารางต่อไปนี้สําหรับข้อมูลสรุปและข้อมูลเพิ่มเติมสําหรับกิจกรรมการคัดลอกอินสแตนซ์ที่มีการจัดการของ Azure SQL
แหล่งข้อมูล
| ชื่อ | คำอธิบาย | ค่า | ต้องระบุ | คุณสมบัติสคริปต์ JSON |
|---|---|---|---|---|
| การเชื่อมต่อ | การเชื่อมต่อของคุณกับที่เก็บข้อมูลต้นทาง | < การเชื่อมต่อของคุณ > | ใช่ | การเชื่อมต่อ |
| ชนิดการเชื่อมต่อ | ชนิดการเชื่อมต่อของคุณ เลือก Azure SQL Managed Instance | อินสแตนซ์ที่จัดการแล้วของ Azure SQL | ใช่ | / |
| ใช้คิวรี | คิวรี SQL แบบกําหนดเองเพื่ออ่านข้อมูล | •โต๊ะ •สอบถาม • ขั้นตอนที่เก็บไว้ |
ใช่ | / |
| ตาราง | ตารางข้อมูลต้นทางของคุณ | < ชื่อตารางของคุณ> | ไม่ใช่ | schema ตาราง |
| คิวรี | คิวรี SQL แบบกําหนดเองเพื่ออ่านข้อมูล | < แบบสอบถามของคุณ > | ไม่ใช่ | sqlReader แบบสอบถาม |
| ชื่อกระบวนงานที่เก็บไว้ | คุณสมบัตินี้เป็นชื่อของกระบวนงานที่เก็บไว้ที่อ่านข้อมูลจากตารางต้นฉบับ คําสั่ง SQL สุดท้ายต้องเป็นคําสั่ง SELECT ในกระบวนงานที่เก็บไว้ | < ชื่อกระบวนงานที่เก็บไว้ > | ไม่ใช่ | sqlReaderStoredProcedureName |
| พารามิเตอร์กระบวนงานที่เก็บไว้ | พารามิเตอร์เหล่านี้ใช้สําหรับกระบวนงานที่เก็บไว้ ค่าที่อนุญาตคือคู่ชื่อหรือค่า ชื่อและตัวพิมพ์ใหญ่ของพารามิเตอร์ต้องตรงกับชื่อและตัวพิมพ์ใหญ่ของพารามิเตอร์กระบวนงานที่เก็บไว้ | < คู่ชื่อหรือค่า > | ไม่ใช่ | storedProcedureParameters |
| การหมดเวลาของคิวรี | การหมดเวลาสําหรับการดําเนินการคําสั่งคิวรี | timespan (ค่าเริ่มต้นคือ 120 นาที) |
ไม่ใช่ | queryTimeout |
| ระดับการแยก | ระบุลักษณะการล็อกธุรกรรมสําหรับแหล่งข้อมูล SQL | •อ่านมุ่งมั่น •อ่านโดยไม่ได้ผูกมัด •อ่านซ้ําได้ • อนุกรมได้ •ภาพถ่าย |
ไม่ใช่ | ระดับการแยก: • อ่านมุ่งมั่น • อ่านไม่ผูกมัด • ทําซ้ําได้อ่าน • อนุกรมได้ •ภาพถ่าย |
| ตัวเลือกพาร์ติชัน | ตัวเลือกการแบ่งพาร์ติชันข้อมูลที่ใช้ในการโหลดข้อมูลจาก Azure SQL Managed Instance | • ไม่มี (ค่าเริ่มต้น) •พาร์ติชันทางกายภาพของตาราง • ช่วงไดนามิก |
ไม่ใช่ | partitionOption: • ไม่มี (ค่าเริ่มต้น) • PhysicalPartitionsOfTable • ไดนามิกเรนจ์ |
| ชื่อคอลัมน์พาร์ติชัน | ชื่อของคอลัมน์ต้นฉบับในชนิดจํานวนเต็มหรือวันที่/วันที่และเวลา (int, , smallint, bigintdate, smalldatetime, datetimedatetime2, หรือ datetimeoffset) ที่ใช้โดยการแบ่งพาร์ติชันช่วงสําหรับสําเนาแบบขนาน หากไม่ได้ระบุ ดัชนีหรือคีย์หลักของตารางจะถูกตรวจพบโดยอัตโนมัติและใช้เป็นคอลัมน์พาร์ติชัน ถ้าคุณใช้แบบสอบถามเพื่อดึงข้อมูลต้นฉบับ ให้ขอเกี่ยว ?DfDynamicRangePartitionCondition ในส่วนคําสั่ง WHERE |
< ชื่อคอลัมน์พาร์ติชันของคุณ > | ไม่ใช่ | partitionColumnName |
| พาร์ติชันบนขอบเขต | ค่าสูงสุดของคอลัมน์พาร์ติชันสําหรับการแยกช่วงพาร์ติชัน ค่านี้ใช้เพื่อกําหนดการก้าวของพาร์ติชัน ไม่ใช่สําหรับการกรองแถวในตาราง แถวทั้งหมดในตารางหรือผลลัพธ์แบบสอบถามจะถูกแบ่งพาร์ติชันและคัดลอก หากไม่ได้ระบุ ให้คัดลอกกิจกรรมจะตรวจหาค่าโดยอัตโนมัติ | < พาร์ติชันบนของคุณ > | ไม่ใช่ | partitionUpperBound |
| พาร์ติชันขอบเขตล่าง | ค่าต่ําสุดของคอลัมน์พาร์ติชันสําหรับการแยกช่วงพาร์ติชัน ค่านี้ใช้เพื่อกําหนดการก้าวของพาร์ติชัน ไม่ใช่สําหรับการกรองแถวในตาราง แถวทั้งหมดในตารางหรือผลลัพธ์แบบสอบถามจะถูกแบ่งพาร์ติชันและคัดลอก หากไม่ได้ระบุ ให้คัดลอกกิจกรรมจะตรวจหาค่าโดยอัตโนมัติ | < ขอบเขตล่างของพาร์ติชันของคุณ > | ไม่ใช่ | partitionLowerBound |
| คอลัมน์เพิ่มเติม | เพิ่มคอลัมน์ข้อมูลเพิ่มเติมเพื่อจัดเก็บเส้นทางสัมพัทธ์หรือค่าคงที่ของไฟล์ต้นฉบับ นิพจน์ได้รับการสนับสนุนสําหรับรุ่นหลัง | •ชื่อ •ค่า |
ไม่ใช่ | คอลัมน์เพิ่มเติม: •ชื่อ •ค่า |
ข้อมูลจุดหมายปลายทาง
| ชื่อ | คำอธิบาย | ค่า | ต้องระบุ | คุณสมบัติสคริปต์ JSON |
|---|---|---|---|---|
| การเชื่อมต่อ | การเชื่อมต่อของคุณไปยังที่เก็บข้อมูลปลายทาง | < การเชื่อมต่อของคุณ > | ใช่ | การเชื่อมต่อ |
| ชนิดการเชื่อมต่อ | ชนิดการเชื่อมต่อของคุณ เลือก Azure SQL Managed Instance | อินสแตนซ์ที่จัดการแล้วของ Azure SQL | ใช่ | / |
| ตัวเลือกตาราง | ระบุว่าจะสร้างตารางปลายทางโดยอัตโนมัติหรือไม่หากไม่มีอยู่ตาม Schema ต้นทาง | •ใช้ที่มีอยู่ •สร้างตารางอัตโนมัติ |
ใช่ | tableOption: •สร้างอัตโนมัติ |
| ตาราง | ตารางข้อมูลปลายทางของคุณ | <ชื่อตารางของคุณ> | ใช่ | schema ตาราง |
| พฤติกรรมการเขียน | ลักษณะการเขียนสําหรับกิจกรรมการคัดลอกเพื่อโหลดข้อมูลลงในฐานข้อมูล Azure SQL Managed Instance | •สอด • อัพเซิร์ต • ขั้นตอนที่เก็บไว้ |
ไม่ใช่ | เขียนพฤติกรรม: •สอด • อัพเซิร์ต sqlWriterStoredProcedureName, sqlWriterTableType, storedProcedureTableTypeParameterName, storedProcedureParameters |
| ใช้ TempDB | จะใช้ตารางชั่วคราวส่วนกลางหรือตารางทางกายภาพเป็นตารางชั่วคราวสําหรับ upsert | เลือก (ค่าเริ่มต้น) หรือไม่ได้เลือก | ไม่ใช่ | ใช้ TempDB: จริง (ค่าเริ่มต้น) หรือเท็จ |
| เลือก Schema ฐานข้อมูลของผู้ใช้ | สคีมาชั่วคราวสําหรับการสร้างตารางชั่วคราวถ้าใช้ตารางทางกายภาพ หมายเหตุ: ผู้ใช้ต้องมีสิทธิ์ในการสร้างและลบตาราง โดยค่าเริ่มต้น ตารางชั่วคราวจะใช้ Schema เดียวกันกับตารางปลายทาง ใช้เมื่อคุณไม่ได้เลือกใช้ TempDB | เลือก (ค่าเริ่มต้น) หรือไม่ได้เลือก | ไม่ใช่ | interimSchemaName |
| คอลัมน์หลัก | ชื่อคอลัมน์สําหรับการระบุแถวที่ไม่ซ้ํากัน สามารถใช้ปุ่มเดียวหรือชุดปุ่มก็ได้ หากไม่ได้ระบุ จะใช้คีย์หลัก | < คอลัมน์หลักของคุณ> | ไม่ใช่ | คีย์ |
| ชื่อกระบวนงานที่เก็บไว้ | ชื่อของกระบวนงานที่เก็บไว้ที่กําหนดวิธีการนําข้อมูลต้นฉบับไปใช้กับตารางเป้าหมาย กระบวนงานที่เก็บไว้นี้ถูกเรียกใช้ต่อชุดงาน สําหรับการดําเนินการที่เรียกใช้เพียงครั้งเดียวและไม่มีส่วนเกี่ยวข้องกับข้อมูลต้นฉบับ เช่น ลบหรือตัดทอน ให้ใช้คุณสมบัติ คัดลอกสคริปต์ล่วงหน้า | < ชื่อกระบวนงานที่เก็บไว้ของคุณ > | ไม่ใช่ | sqlWriterStoredProcedureName |
| ประเภทตาราง | ชื่อชนิดตารางที่จะใช้ในกระบวนงานที่เก็บไว้ กิจกรรมการคัดลอกทําให้ข้อมูลที่กําลังย้ายพร้อมใช้งานในตารางชั่วคราวด้วยชนิดตารางนี้ รหัสกระบวนงานที่เก็บไว้สามารถผสานข้อมูลที่กําลังคัดลอกกับข้อมูลที่มีอยู่ได้ | < ชื่อประเภทตารางของคุณ > | ไม่ใช่ | sqlWriterTableType |
| ชื่อพารามิเตอร์ชนิดตาราง | ชื่อพารามิเตอร์ของชนิดตารางที่ระบุในกระบวนงานที่เก็บไว้ | < ชื่อพารามิเตอร์ของคุณของชนิดตาราง > | ไม่ใช่ | storedProcedureTableTypeParameterName |
| พารามิเตอร์ | พารามิเตอร์สําหรับกระบวนงานที่เก็บไว้ ค่าที่อนุญาตคือคู่ชื่อและค่า ชื่อและตัวพิมพ์ใหญ่ของพารามิเตอร์ต้องตรงกับชื่อและตัวพิมพ์ใหญ่ของพารามิเตอร์กระบวนงานที่เก็บไว้ | < คู่ชื่อและค่า > | ไม่ใช่ | storedProcedureParameters |
| ล็อคโต๊ะแทรกจํานวนมาก | ใช้การตั้งค่านี้เพื่อปรับปรุงประสิทธิภาพการคัดลอกในระหว่างการดําเนินการแทรกจํานวนมากบนตารางที่ไม่มีดัชนีจากไคลเอ็นต์หลายตัว | ใช่หรือไม่ใช่ (ค่าเริ่มต้น) | ไม่ใช่ | sqlWriterUseTableLock: จริง หรือ เท็จ (ค่าเริ่มต้น) |
| สคริปต์สําเนาล่วงหน้า | สคริปต์สําหรับกิจกรรมการคัดลอกที่จะดําเนินการก่อนที่จะเขียนข้อมูลลงในตารางปลายทางในการเรียกใช้แต่ละครั้ง คุณสามารถใช้คุณสมบัตินี้เพื่อล้างข้อมูลที่โหลดไว้ล่วงหน้า |
< สคริปต์คัดลอกล่วงหน้า > (สตริง) |
ไม่ใช่ | preCopyScript |
| การหมดเวลาชุดการเขียน | เวลารอให้การดําเนินการแทรกแบทช์เสร็จสิ้นก่อนที่จะหมดเวลา | timespan (ค่าเริ่มต้นคือ "02:00:00") |
ไม่ใช่ | writeBatchTimeout |
| เขียนขนาดแบทช์ | จํานวนแถวที่จะแทรกลงในตาราง SQL ต่อชุดงาน โดยค่าเริ่มต้น บริการจะกําหนดขนาดชุดงานที่เหมาะสมแบบไดนามิกตามขนาดแถว |
< จํานวนแถว > (จํานวนเต็ม) |
ไม่ใช่ | เขียนขนาดแบทช์ |
| การเชื่อมต่อพร้อมกันสูงสุด | ขีดจํากัดบนของการเชื่อมต่อพร้อมกันที่สร้างขึ้นไปยังที่เก็บข้อมูลระหว่างการเรียกใช้กิจกรรม ระบุค่าเมื่อคุณต้องการจํากัดการเชื่อมต่อที่เกิดขึ้นพร้อมกันเท่านั้น |
< ขีดจํากัดสูงสุดของการเชื่อมต่อพร้อมกัน > (จํานวนเต็ม) |
ไม่ใช่ | max การเชื่อมต่อพร้อมกัน |