หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
นําไปใช้กับ:✅ คลังสินค้าใน Microsoft Fabric
บทความนี้เน้นคุณลักษณะและนวัตกรรมในสถาปัตยกรรมของ Fabric คลังข้อมูล ที่ขับเคลื่อนประสิทธิภาพ ความสามารถในการปรับขนาด และประสิทธิภาพด้านต้นทุน
Fabric คลังข้อมูล ทํางานบนสถาปัตยกรรมที่พร้อมสําหรับอนาคตในแพลตฟอร์มข้อมูลที่หลอมรวม ด้วยรูปแบบที่เก็บข้อมูล Delta แบบเปิดและการรวม OneLake ข้อมูลของคุณใน Fabric คลังข้อมูล จึงพร้อมสําหรับการวิเคราะห์
สถาปัตยกรรมระดับสูง

Fabric คลังข้อมูล สร้างขึ้นตามวัตถุประสงค์สําหรับการวิเคราะห์ตามขนาดด้วยส่วนประกอบต่อไปนี้:
| การสร้างบล็อก | คำอธิบาย: |
|---|---|
| เครื่องมือเพิ่มประสิทธิภาพคิวรีแบบรวม | สร้างแผนการดําเนินการที่เหมาะสมที่สุดสําหรับสภาพแวดล้อมระบบคลาวด์แบบกระจาย โดยไม่คํานึงถึงคุณภาพของการสืบค้น SQL ที่ผู้ใช้เขียน |
| การประมวลผลคิวรีแบบกระจาย | รองรับการดําเนินการสืบค้นแบบขนานขนาดใหญ่ด้วยโครงสร้างพื้นฐานระบบคลาวด์ที่ปรับขนาดอัตโนมัติอย่างรวดเร็ว ปริมาณงาน SELECT และ DML ที่แยกจากกันใช้พูลที่แตกต่างกันเพื่อการดําเนินการที่มีประสิทธิภาพและแยกจากกัน |
| กลไกการดําเนินการแบบสอบถาม | กลไกที่ใช้ SQL สําหรับดําเนินการสืบค้นการวิเคราะห์กับข้อมูลจํานวนมากด้วยประสิทธิภาพที่รวดเร็วและการทํางานพร้อมกันสูง |
| ข้อมูลเมตาและการจัดการธุรกรรม | ข้อมูลเมตาอยู่ในส่วนหน้า แบ็กเอนด์ และทั้งในแคช SSD ในเครื่องและที่เก็บข้อมูล OneLake ระยะไกล รองรับการทําธุรกรรมพร้อมกันและรับรองการปฏิบัติตาม ACID |
| ที่เก็บข้อมูลใน OneLake | ตารางที่มีโครงสร้างบันทึกที่ใช้งานโดยใช้ รูปแบบตารางเดลต้าแบบเปิด ซึ่งเป็นโมเดลเลคเฮาส์ที่มีที่เก็บข้อมูลแบบเปิดที่ปลอดภัย |
| แพลตฟอร์มผ้า | Fabric Platform มีรูปแบบการรับรองความถูกต้องและความปลอดภัยแบบครบวงจร คลังข้อมูล Fabric ของคุณจะพร้อมใช้งานโดยอัตโนมัติสําหรับบริการแพลตฟอร์ม Fabric อื่นๆ เพื่อตอบสนองความต้องการทางธุรกิจ รวมถึง Power BI, ไปป์ไลน์ข้อมูลใน Data Factory, Real-Time Intelligence และอื่นๆ |
กลไกจัดการเพิ่มประสิทธิภาพคิวรีแบบรวม
เครื่องมือเพิ่มประสิทธิภาพคิวรีแบบรวมใน Fabric คลังข้อมูล เป็นกลไกจัดการที่ตัดสินใจวิธีที่ชาญฉลาดที่สุดในการเรียกใช้คิวรี SQL ของคุณ
เมื่อคุณส่งคิวรี เครื่องมือเพิ่มประสิทธิภาพคิวรีแบบรวมจะพิจารณาวิธีที่เป็นไปได้ในการดําเนินการ ได้แก่ วิธีรวมตาราง ตําแหน่งที่จะย้ายข้อมูล และวิธีใช้ทรัพยากร เช่น CPU, หน่วยความจํา และเครือข่าย เครื่องมือเพิ่มประสิทธิภาพคิวรีแบบรวมไม่เพียงแต่เลือกตัวเลือกแรก แต่ยังเลือกแผนที่เหมาะสมที่สุดภายในเวลาที่อนุญาตโดยการประเมินต้นทุนจากปัจจัยเหล่านี้และข้อมูลเมตาและสถิติที่มีอยู่
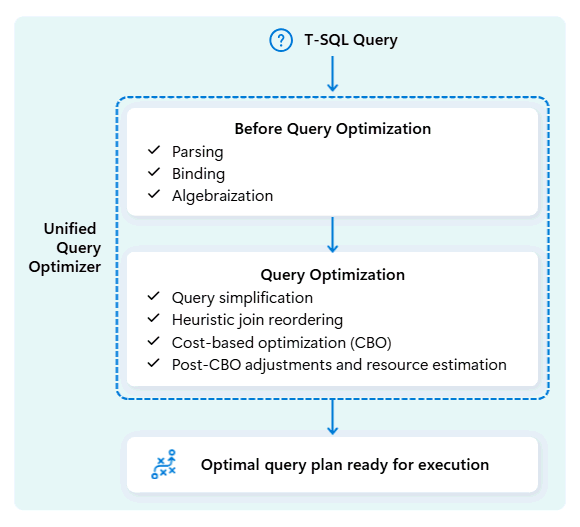
เมื่อปรับแผนการดําเนินการของคิวรีให้เหมาะสม เครื่องมือเพิ่มประสิทธิภาพคิวรีแบบรวมจะพิจารณาทุกอย่างในคราวเดียว: รูปร่างของคิวรี การกระจายข้อมูลของตาราง และค่าใช้จ่ายในการย้ายข้อมูลเทียบกับการประมวลผลภายในเครื่อง เครื่องมือเพิ่มประสิทธิภาพการสืบค้นแบบรวมสามารถทําการแลกเปลี่ยนอย่างชาญฉลาด เช่น การตัดสินใจว่าการออกอากาศตารางขนาดเล็กมีราคาถูกกว่าการสับเปลี่ยนตารางขนาดใหญ่หรือไม่ การใช้การประมวลผลที่ดีขึ้นและประสิทธิภาพที่เร็วขึ้นแม้สําหรับคิวรี T-SQL ที่ซับซ้อนหรือเขียนได้ไม่ดี
ประสิทธิภาพที่สอดคล้องกันไม่จําเป็นต้องให้นักพัฒนาใช้เวลากับการปรับแต่งคิวรี T-SQL ด้วยตนเอง ตัวอย่างเช่น คุณไม่จําเป็นต้องกําหนดลําดับที่ดีที่สุดใน JOIN คิวรีด้วยตนเอง ถ้า SQL ของคุณแสดงรายการตารางขนาดใหญ่ก่อน และตารางข้อมูลที่เล็กกว่าและเลือกได้สูงเป็นอันดับสอง เครื่องมือเพิ่มประสิทธิภาพสามารถสลับตําแหน่งได้โดยอัตโนมัติเพื่อประสิทธิภาพที่ดีขึ้น จะใช้ตารางที่เล็กกว่าเป็นจุดเริ่มต้นสําหรับการจับคู่แถว (ด้าน "สร้าง") และตารางที่ใหญ่กว่าเป็นตารางที่จะค้นหา (ด้าน "โพรบ" ตรวจสอบการจับคู่) วิธีนี้ช่วยลดการใช้หน่วยความจํา ลดการเคลื่อนย้ายข้อมูล และปรับปรุงความขนาน ในขณะที่ยังคงให้ผลลัพธ์ที่แม่นยํา
เครื่องมือเพิ่มประสิทธิภาพการสืบค้นแบบรวมจะเรียนรู้อย่างต่อเนื่องจากการดําเนินการสืบค้นที่ผ่านมาเมื่อปริมาณงานพัฒนา โดยปรับแต่งอัลกอริทึมการเพิ่มประสิทธิภาพเพื่อมอบประสิทธิภาพที่ดีที่สุด ผู้ใช้จะได้รับประโยชน์จากการดําเนินการสืบค้นที่รวดเร็วโดยอัตโนมัติโดยไม่คํานึงถึงความซับซ้อนและไม่จําเป็นต้องเข้าไปแทรกแซง
กลไกการประมวลผลแบบสอบถามแบบกระจาย
ใน Fabric คลังข้อมูล กลไกการประมวลผลคิวรีแบบกระจายจะจัดสรรทรัพยากรการคํานวณให้กับงานในแผนคิวรี กลไกการประมวลผลคิวรีแบบกระจายสามารถกําหนดเวลางานข้ามโหนดคอมพิวท์ เพื่อให้แต่ละโหนดเรียกใช้ส่วนหนึ่งของแผนคิวรี รายงานที่ซับซ้อนในชุดข้อมูลขนาดใหญ่จะได้รับประโยชน์จากการประมวลผลคิวรีแบบกระจาย
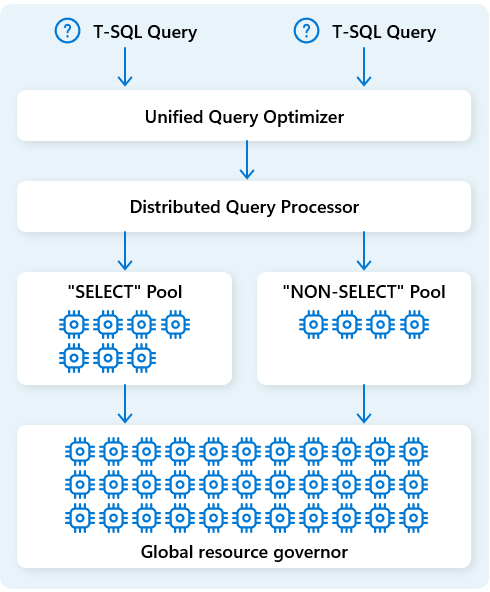
เพื่อเพิ่มประสิทธิภาพทรัพยากรเพิ่มเติม กลไกการประมวลผลคิวรีแบบกระจายจะแยกทรัพยากรการคํานวณออกเป็นสองพูล: สําหรับ SELECT คิวรีและสําหรับงานการนําเข้าข้อมูล (NON-SELECT คิวรี) ปริมาณงานแต่ละรายการจะได้รับทรัพยากรเฉพาะตามความจําเป็น ตัวอย่างเช่น ซึ่งหมายความว่างาน ETL ทุกคืนของคุณจะไม่ทําให้แดชบอร์ดตอนเช้าล่าช้า
ด้วยการจัดเตรียมโหนดอย่างรวดเร็วในระบบคลาวด์ กลไกการประมวลผลการสืบค้นแบบกระจายจะปรับขนาดทรัพยากรการประมวลผลขึ้นหรือลงโดยอัตโนมัติเพื่อตอบสนองต่อการเปลี่ยนแปลงของปริมาณการสืบค้น Fabric คลังข้อมูล มีความสามารถในการประมวลผลแบบขนานสําหรับชุดข้อมูลขนาดเล็กหรือข้อมูลที่ระดับหลายเพตะไบต์
กลไกการดําเนินการคิวรี
กลไกการดําเนินการคิวรีเป็นกระบวนการที่เรียกใช้ส่วนต่างๆ ของแผนการดําเนินการแบบกระจายที่กําหนดให้กับโหนดการประมวลผลแต่ละโหนด กลไกการดําเนินการคิวรีใช้กลไกจัดการเดียวกันกับที่ใช้โดย SQL Server และฐานข้อมูล Azure SQL เพื่อใช้การดําเนินการ โหมดแบทช์ และรูปแบบข้อมูล แบบคอลัมน์ สําหรับการวิเคราะห์ข้อมูลขนาดใหญ่ที่มีประสิทธิภาพด้วยต้นทุนที่เหมาะสมที่สุด
เอ็นจิ้นการดําเนินการสืบค้นจะอ่านข้อมูลโดยตรงจากไฟล์ Delta Parquet ที่จัดเก็บไว้ใน Fabric OneLake และใช้ประโยชน์จากเลเยอร์แคชหลายเลเยอร์ (หน่วยความจําและ SSD) เพื่อเร่งประสิทธิภาพการสืบค้นและทําให้แน่ใจว่าการสืบค้นจะดําเนินการด้วยความเร็วที่เหมาะสมที่สุด กลไกการดําเนินการสืบค้นจะประมวลผลข้อมูลในหน่วยความจํา และเมื่อจําเป็น จะดึงข้อมูลเพิ่มเติมจากแคช SSD หรือที่เก็บข้อมูล OneLake
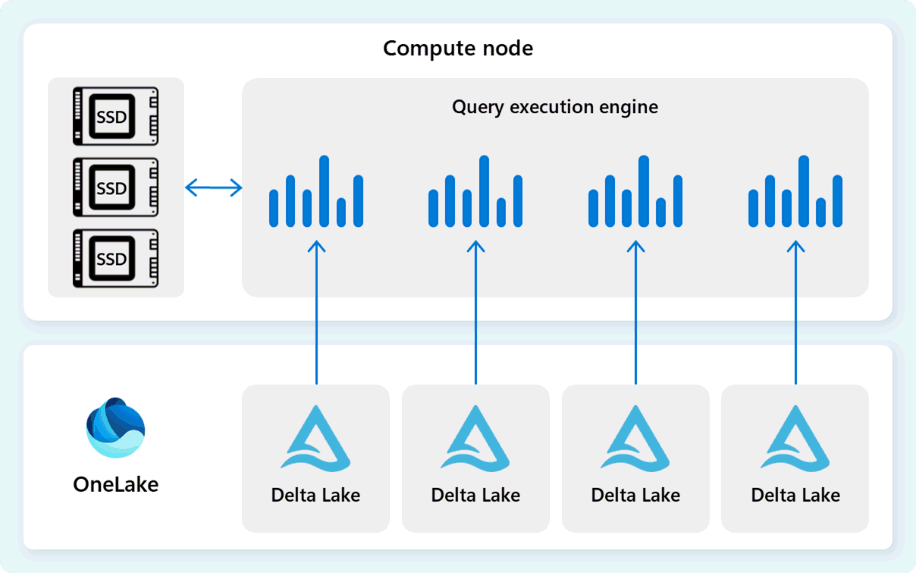
ขณะที่ประมวลผลข้อมูล กลไกการดําเนินการคิวรีจะทําการกําจัดคอลัมน์และกลุ่มแถวเพื่อข้ามเซ็กเมนต์ที่ไม่เกี่ยวข้องกับคิวรี การเพิ่มประสิทธิภาพนี้ช่วยลดปริมาณข้อมูลที่สแกนจากไฟล์และแคชหน่วยความจํา ซึ่งช่วยลดการใช้ทรัพยากรและปรับปรุงเวลาดําเนินการโดยรวม
กลไกการดําเนินการคิวรีมีความเชี่ยวชาญในการกรองและรวมแถวหลายพันล้านแถว ซึ่งสนับสนุนรูปแบบการวิเคราะห์ข้อมูลทั่วไปที่ใช้ในโซลูชันคลังข้อมูลสมัยใหม่ การดําเนินการในโหมดแบทช์ใช้ประโยชน์จากความสามารถของ CPU ที่ทันสมัยในการประมวลผลหลายแถวพร้อมกัน ซึ่งช่วยลดค่าใช้จ่ายลงอย่างมาก และทําให้การสืบค้นทํางานเร็วขึ้นหลายร้อยเท่าเมื่อเทียบกับการดําเนินการแบบแถวต่อแถวแบบเดิม
ข้อมูลเมตาและการจัดการธุรกรรม
กลไกจัดการคลังสินค้าใช้เมตาดาต้าเพื่ออธิบาย Schema ตาราง การจัดระเบียบไฟล์ ประวัติรุ่น และสถานะธุรกรรม ข้อมูลเมตานี้ช่วยให้กลไกจัดการคลังสินค้าสามารถจัดการและสืบค้นข้อมูลได้อย่างมีประสิทธิภาพ Fabric คลังข้อมูล นําเสนอสถาปัตยกรรมการจัดการธุรกรรมและข้อมูลเมตาที่แข็งแกร่งและครอบคลุม โดยขยายตัวจัดการธุรกรรม OLTP เพื่อประสานการดําเนินการข้อมูลเมตาที่เกิดขึ้นพร้อมกันสูงและรับรองการปฏิบัติตามข้อกําหนดของ ACID
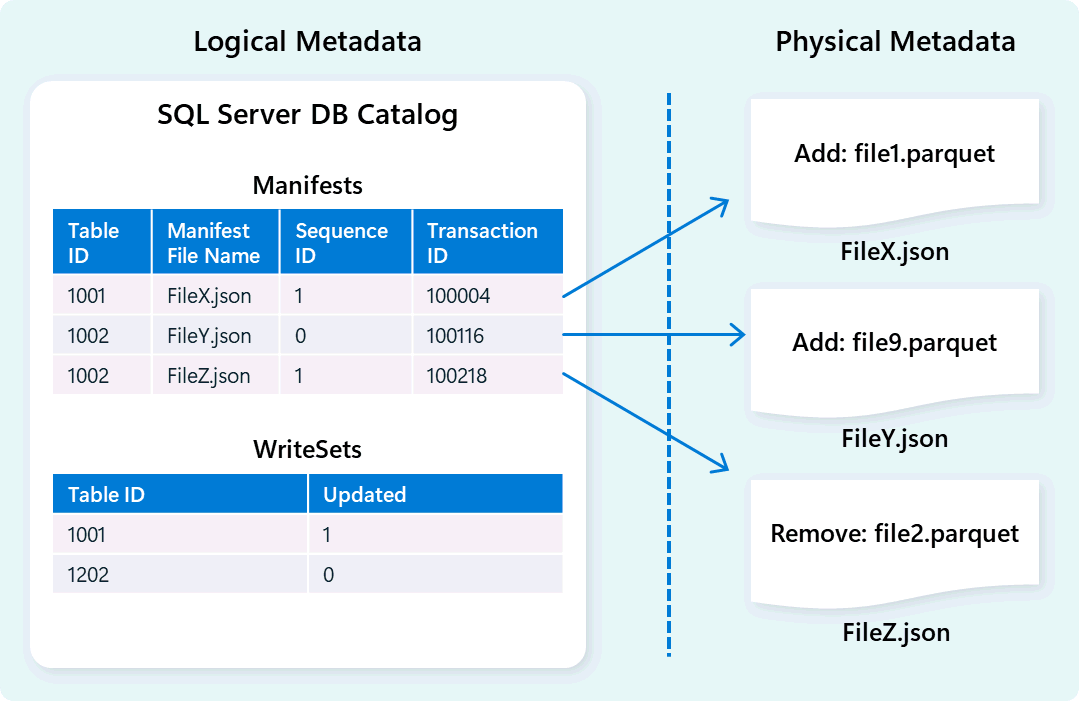
การออกแบบนี้ช่วยให้สามารถนําทางสถานะธุรกรรมได้อย่างรวดเร็วและเชื่อถือได้ โดยรองรับปริมาณงานที่มีการทํางานพร้อมกันสูงในขณะที่มั่นใจได้ถึงความสอดคล้องกัน
พื้นที่เก็บข้อมูลและการนําเข้าข้อมูล
Fabric คลังข้อมูล ใช้สถาปัตยกรรมเลคเฮาส์ที่มีรูปแบบเดลต้าแบบโอเพนซอร์สสําหรับพื้นที่จัดเก็บข้อมูลที่ปรับขนาดได้ ปลอดภัย และมีประสิทธิภาพสูง รูปแบบตารางเดลต้ารองรับการกําหนดเวอร์ชันข้อมูล ทําให้สามารถเข้าถึงสแนปช็อตในอดีตได้ทันทีผ่าน การเดินทางข้ามเวลา และการ โคลนแบบไม่มีสําเนา เพื่อการทดสอบที่ปลอดภัยและการดําเนินการย้อนกลับ ข้อมูลผู้ใช้จะถูกจัดเก็บไว้ใน OneLake ทําให้กลไก Fabric ทั้งหมดสามารถเข้าถึงข้อมูลที่แชร์ได้อย่างมีประสิทธิภาพโดยไม่มีความซ้ําซ้อน
Fabric คลังข้อมูล ได้รับการออกแบบมาเพื่อมอบประสิทธิภาพการนําเข้าข้อมูลที่เหมาะสมที่สุดโดยมุ่งเน้นที่ความเรียบง่ายและความยืดหยุ่น เอ็นจิ้นจัดการการจัดเก็บข้อมูลตารางอย่างมีประสิทธิภาพผ่าน การบดอัดข้อมูลอัตโนมัติ ซึ่งจะรวมไฟล์ที่แยกส่วนไว้ในพื้นหลังเพื่อลดการสแกนข้อมูลที่ไม่จําเป็น วิธีการกระจายข้อมูลอัจฉริยะแบ่งและจัดระเบียบข้อมูลออกเป็นเซลล์แบบไมโครพาร์ติชันเพื่อเพิ่มการประมวลผลแบบขนานและปรับปรุงผลการสืบค้น ความสามารถเหล่านี้ทํางานโดยอัตโนมัติโดยไม่จําเป็นต้องปรับด้วยตนเอง