หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
นําไปใช้กับ:✅ Warehouse ใน Microsoft Fabric
บทความนี้แสดงวิธีการโยกย้ายคลังข้อมูลในพูล SQL เฉพาะของ Azure Synapse Analytics ไปยัง Microsoft Fabric Warehouse
เคล็ดลับ
สําหรับข้อมูลเพิ่มเติมเกี่ยวกับกลยุทธ์และการวางแผนการโยกย้ายของคุณ โปรดดูที่การวางแผนการโยกย้าย : กลุ่ม Azure Synapse Analytics เฉพาะ SQL สําหรับ Fabric Data Warehouse
ประสบการณ์อัตโนมัติสําหรับการโยกย้ายจากกลุ่ม SQL เฉพาะของ Azure Synapse Analytics สามารถใช้งานได้โดยใช้ Fabric Migration Assistant สําหรับ Data Warehouse ส่วนที่เหลือของบทความนี้ประกอบด้วยขั้นตอนการโยกย้ายข้อมูลด้วยตนเองเพิ่มเติม
ตารางนี้จะสรุปข้อมูลสําหรับ Schema ข้อมูล (DDL) รหัสฐานข้อมูล (DML) และวิธีการโยกย้ายข้อมูล เราจะขยายเพิ่มเติมในแต่ละสถานการณ์ในภายหลังในบทความนี้ ซึ่งเชื่อมโยงในคอลัมน์ตัวเลือก
| หมายเลขตัวเลือก | ตัวเลือก | สิ่งที่ทำ | ทักษะ/การกําหนดลักษณะ | บทภาพยนตร์ |
|---|---|---|---|---|
| 1 | โรงงานข้อมูล | การแปลงเค้าร่าง (DDL) การดึงข้อมูล การนำเข้าข้อมูล |
ADF/ไปป์ไลน์ | ทําให้ทุกอย่างง่ายขึ้นในสคีมาหนึ่ง (DDL) และการโยกย้ายข้อมูล แนะนําสําหรับ ตารางมิติ |
| 2 | Data Factory พร้อมพาร์ติชัน | การแปลงเค้าร่าง (DDL) การดึงข้อมูล การนำเข้าข้อมูล |
ADF/ไปป์ไลน์ | การใช้ตัวเลือกการแบ่งพาร์ติชันเพื่อเพิ่มการทํางานแบบขนานในการอ่าน/เขียน ซึ่งมีอัตราความเร็วเทียบกับตัวเลือกที่ 1 สิบครั้ง แนะนําสําหรับตารางข้อเท็จจริง |
| 3 | Data Factory ที่มีรหัสเร่ง | การแปลงเค้าร่าง (DDL) | ADF/ไปป์ไลน์ | แปลงและโยกย้าย Schema (DDL) ก่อน จากนั้นใช้ CETAS เพื่อแยกและคัดลอก/โรงงานข้อมูลไปยังการนําเข้าข้อมูลเพื่อประสิทธิภาพการนําเข้าโดยรวมที่ดีที่สุด |
| 4 | โค้ดเร่งขั้นตอนที่จัดเก็บไว้ | การแปลงเค้าร่าง (DDL) การดึงข้อมูล การประเมินโค้ด |
T-SQL | ผู้ใช้ SQL ที่ใช้ IDE ที่มีการควบคุมงานที่ละเอียดมากขึ้นซึ่งพวกเขาต้องการใช้งาน ใช้คัดลอก/โรงงานข้อมูลเพื่อนําเข้าข้อมูล |
| 5 | ส่วนขยายโครงการฐานข้อมูล SQL สําหรับ Visual Studio Code | การแปลงเค้าร่าง (DDL) การดึงข้อมูล การประเมินโค้ด |
โครงการ SQL | โครงการฐานข้อมูล SQL สําหรับการปรับใช้ด้วยการรวมกันของตัวเลือกที่ 4 ใช้คัดลอกหรือโรงงานข้อมูลเพื่อนําเข้าข้อมูล |
| 6 | สร้างตารางภายนอกเป็นการเลือก (CETAS) | การดึงข้อมูล | T-SQL | ค่าใช้จ่ายในการแยกข้อมูลที่มีประสิทธิภาพและประสิทธิภาพสูงลงใน Azure Data Lake Storage (ADLS) Gen2 ใช้คัดลอก/โรงงานข้อมูลเพื่อนําเข้าข้อมูล |
| 7 | โยกย้ายโดยใช้ dbt | การแปลงเค้าร่าง (DDL) การแปลงรหัสฐานข้อมูล (DML) |
dbt | ผู้ใช้ dbt ที่มีอยู่สามารถใช้ตัวปรับต่อ dbt Fabric เพื่อแปลง DDL และ DML ของพวกเขาได้ จากนั้นคุณต้องโยกย้ายข้อมูลโดยใช้ตัวเลือกอื่นในตารางนี้ |
เลือกปริมาณงานสําหรับการโยกย้ายเบื้องต้น
เมื่อคุณกําลังตัดสินใจว่าจะเริ่มต้นจากพูลการโยกย้ายของ Synapse Dedicated SQL ไปยังโครงการการโยกย้าย Fabric Warehouse อย่างไร ให้เลือกพื้นที่ทํางานที่คุณสามารถที่จะ:
- พิสูจน์ความมีชีวิตชีวาของการโยกย้ายข้อมูลไปยัง Fabric Warehouse ด้วยการส่งมอบประโยชน์ของสภาพแวดล้อมใหม่อย่างรวดเร็ว เริ่มต้นด้วยขนาดเล็กและเรียบง่าย เตรียมพร้อมสําหรับการโยกย้ายข้อมูลขนาดเล็กหลายรายการ
- ช่วยให้พนักงานด้านเทคนิคของคุณจะได้รับประสบการณ์ที่เกี่ยวข้องกับกระบวนการและเครื่องมือที่พวกเขาใช้เมื่อโยกย้ายข้อมูลไปยังพื้นที่อื่น ๆ
- สร้างเทมเพลตสําหรับการโยกย้ายเพิ่มเติมที่เฉพาะเจาะจงกับสภาพแวดล้อม Synapse ต้นทาง และเครื่องมือและกระบวนการเพื่อช่วย
เคล็ดลับ
สร้างคลังวัตถุที่จําเป็นต้องโยกย้าย และจัดทําเอกสารกระบวนการโยกย้ายตั้งแต่ต้นจนจบ เพื่อให้สามารถทําซ้ําสําหรับพูล SQL หรือปริมาณงานอื่นๆ โดยเฉพาะได้
ปริมาณของข้อมูลที่ถูกโยกย้ายข้อมูลในการโยกย้ายข้อมูลเบื้องต้นควรมีขนาดใหญ่พอที่จะแสดงให้เห็นถึงความสามารถและประโยชน์ของสภาพแวดล้อม Fabric Warehouse แต่ไม่ใหญ่เกินกว่าที่จะแสดงค่าได้อย่างรวดเร็ว ขนาดในช่วง 1-10 เทราไบต์เป็นเรื่องปกติ
การย้ายข้อมูลด้วยโรงงานข้อมูล Fabric
ในส่วนนี้ เราจะกล่าวถึงตัวเลือกโดยใช้ Data Factory สําหรับ persona แบบ low-code/no-code ที่คุ้นเคยกับ Azure Data Factory และ Synapse Pipeline ตัวเลือก UI แบบลากแล้วปล่อยนี้จะให้ขั้นตอนง่ายๆ ในการแปลง DDL และโยกย้ายข้อมูล
โรงงานข้อมูลผ้าสามารถทํางานต่อไปนี้:
- แปลง schema (DDL) เป็นไวยากรณ์ Fabric Warehouse
- สร้าง Schema (DDL) บน Fabric Warehouse
- ย้ายข้อมูลไปยัง Fabric Warehouse
ตัวเลือกที่ 1 การโยกย้าย Schema/ข้อมูล - ตัวช่วยสร้างการคัดลอกและกิจกรรมการคัดลอกของ ForEach
วิธีนี้ใช้ตัวช่วย Data Factory Copy เพื่อเชื่อมต่อกับแหล่งพูล SQL เฉพาะ แปลงไวยากรณ์ DDL ของพูล SQL เฉพาะเป็น Fabric และคัดลอกข้อมูลไปยัง Fabric Warehouse คุณสามารถเลือกตารางเป้าหมายอย่างน้อยหนึ่งตาราง (สําหรับ TPC-DS ชุดข้อมูลมี 22 ตาราง) จะสร้าง ForEach เพื่อวนรอบผ่านรายการของตารางที่เลือกใน UI และสร้างเธรดกิจกรรมการคัดลอกแบบขนาน 22 รายการ
- 22 คิวรี SELECT (หนึ่งคิวรีสําหรับแต่ละตารางที่เลือก) ถูกสร้างขึ้นและดําเนินการในกลุ่ม SQL เฉพาะ
- ตรวจสอบให้แน่ใจว่า คุณมี DWU และคลาสทรัพยากรที่เหมาะสมเพื่ออนุญาตให้คิวรีที่สร้างขึ้นเพื่อดําเนินการ สําหรับกรณีนี้ คุณจําเป็นต้องมี DWU1000
staticrc10ขั้นต่ําเพื่อให้มีคิวรีได้สูงสุด 32 คิวรีสําหรับการจัดการ 22 คิวรีที่ส่ง - ข้อมูลโรงงานคัดลอกโดยตรงจากกลุ่ม SQL เฉพาะไปยัง Fabric Warehouse จําเป็นต้องมีการจัดเตรียม กระบวนการการนําเข้าข้อมูลประกอบด้วยสองขั้นตอน
- ระยะแรกจะประกอบด้วยการดึงข้อมูลจากพูล SQL เฉพาะลงใน ADLS และเรียกว่าการจัดเตรียม
- ระยะที่สองประกอบด้วยการนําเข้าข้อมูลจากการจัดเตรียมลงใน Fabric Warehouse เวลาการนําเข้าข้อมูลส่วนใหญ่อยู่ในระยะการจัดเตรียม โดยสรุป สเตจจิ้งมีผลต่อประสิทธิภาพการนําเข้าอย่างมาก
การใช้งานที่แนะนำ
การใช้ตัวช่วยสร้างการคัดลอกเพื่อสร้าง ForEach มี UI อย่างง่ายเพื่อแปลง DDL และนําเข้าตารางที่เลือกจากกลุ่ม SQL เฉพาะไปยัง Fabric Warehouse ในขั้นตอนเดียว
อย่างไรก็ตาม การดําเนินการนี้ไม่เหมาะสมกับปริมาณงานโดยรวม ข้อกําหนดในการใช้การจัดเตรียม ความจําเป็นในการอ่านและการเขียนแบบขนานสําหรับขั้นตอน "แหล่งที่มาไปยังลําดับขั้น" เป็นปัจจัยหลักสําหรับเวลาแฝงด้านประสิทธิภาพการทํางาน ขอแนะนําให้ใช้ตัวเลือกนี้สําหรับตารางมิติเท่านั้น
ตัวเลือกที่ 2 DDL/การโยกย้ายข้อมูล - ไปป์ไลน์โดยใช้ตัวเลือกพาร์ติชัน
หากต้องการปรับปรุงปริมาณงานเพื่อโหลดตารางข้อเท็จจริงที่ใหญ่ขึ้นโดยใช้ไปป์ไลน์ Fabric ขอแนะนําให้ใช้กิจกรรมการคัดลอกสําหรับแต่ละตารางข้อเท็จจริงพร้อมตัวเลือกพาร์ติชัน ซึ่งมีประสิทธิภาพที่ดีที่สุดด้วยกิจกรรมการคัดลอก
คุณมีตัวเลือกในการใช้การแบ่งพาร์ติชันจริงของตารางต้นทาง ถ้ามี ถ้าตารางไม่มีพาร์ติชันจริง คุณต้องระบุคอลัมน์พาร์ติชันและใส่ค่าต่ําสุด/สูงสุดเพื่อใช้การแบ่งพาร์ติชันแบบไดนามิก ในภาพหน้าจอต่อไปนี้ ตัวเลือก แหล่งที่มา ของไปป์ไลน์กําลังระบุช่วงไดนามิกของพาร์ติชันตาม ws_sold_date_sk คอลัมน์
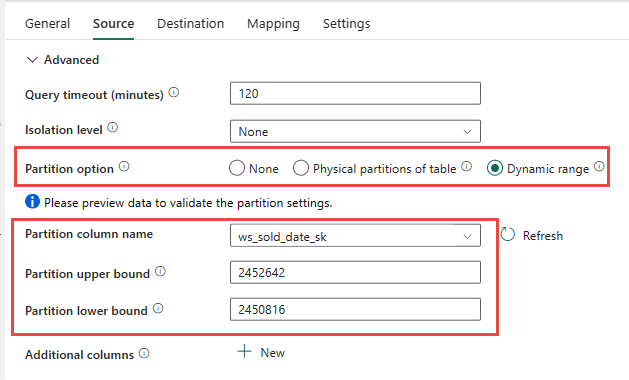
ในขณะที่ใช้พาร์ติชันสามารถเพิ่มปริมาณงานด้วยขั้นตอนการแบ่งระยะ มีข้อควรพิจารณาเพื่อทําการปรับเปลี่ยนที่เหมาะสม:
- ซึ่งอาจใช้สล็อตพร้อมกันทั้งหมดเนื่องจากอาจสร้างคิวรีมากกว่า 128 คิวรีบนพูล SQL เฉพาะ ทั้งนี้ขึ้นอยู่กับช่วงของพาร์ติชันของคุณ
- คุณจําเป็นต้องปรับมาตราส่วนเป็น DWU6000 น้อยที่สุดเพื่อให้สามารถดําเนินการคิวรีทั้งหมดได้
- ตัวอย่างเช่น สําหรับตาราง TPC DS
web_salesคิวรี 163 รายการจะถูกส่งไปยังกลุ่ม SQL เฉพาะ ที่ DWU6000 มีการดําเนินการคิวรี 128 รายการในขณะที่มีคิวคิวรี 35 รายการ - พาร์ติชันแบบไดนามิกจะเลือกพาร์ติชันช่วงโดยอัตโนมัติ ในกรณีนี้ เป็นช่วง 11 วันสําหรับแต่ละคิวรี SELECT ที่ส่งไปยังกลุ่ม SQL เฉพาะ ตัวอย่าง:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
การใช้งานที่แนะนำ
สําหรับตารางข้อเท็จจริง เราแนะนําให้ใช้ Data Factory กับตัวเลือกการแบ่งพาร์ติชันเพื่อเพิ่มปริมาณงาน
อย่างไรก็ตาม การอ่านแบบขนานที่เพิ่มขึ้นจําเป็นต้องมีพูล SQL เฉพาะเพื่อปรับขนาดเป็น DWU ที่สูงขึ้นเพื่อให้สามารถดําเนินการคิวรีแยกได้ การใช้ประโยชน์จากการแบ่งพาร์ติชัน อัตราได้รับการปรับปรุงสิบครั้งผ่านตัวเลือกไม่มีพาร์ติชัน คุณสามารถเพิ่ม DWU เพื่อรับปริมาณงานเพิ่มเติมผ่านทรัพยากรการคํานวณ แต่กลุ่ม SQL เฉพาะมีคิวรีที่ใช้งานอยู่สูงสุดที่อนุญาต 128 รายการ
สําหรับข้อมูลเพิ่มเติมเกี่ยวกับ Synapse DWU ไปยัง Fabric map โปรดดู ที่ บล็อก: การแมปกลุ่ม SQL เฉพาะของ Azure Synapse ไปยังการคํานวณคลังข้อมูล Fabric
ตัวเลือกที่ 3 การโยกย้าย DDL - ตัวช่วยสร้างการคัดลอกกิจกรรมการคัดลอกของ ForEach
ตัวเลือกสองข้อก่อนหน้านี้เป็นตัวเลือกการโยกย้ายข้อมูลที่ยอดเยี่ยมสําหรับฐานข้อมูลที่มีขนาดเล็กลง แต่ถ้าคุณต้องการปริมาณงานที่สูงขึ้น เราขอแนะนําให้เลือกตัวเลือกอื่น:
- แยกข้อมูลจากกลุ่ม SQL เฉพาะเป็น ADLS ดังนั้นจึงลดค่าใช้จ่ายด้านประสิทธิภาพการทํางานของขั้นตอน
- ใช้ Data Factory หรือคําสั่ง COPY เพื่อนําเข้าข้อมูลลงใน Fabric Warehouse
การใช้งานที่แนะนำ
คุณสามารถใช้ Data Factory เพื่อแปลง Schema (DDL) ของคุณได้ต่อไป ด้วยการใช้ตัวช่วยสร้างสําเนา คุณสามารถเลือกตารางเฉพาะหรือ ตารางทั้งหมดได้ โดยการออกแบบ การดําเนินการนี้จะย้าย Schema และข้อมูลในขั้นตอนเดียว การแยก schema โดยไม่มีแถวโดยใช้เงื่อนไข TOP 0 เท็จในคําสั่งคิวรี
ตัวอย่างรหัสต่อไปนี้ครอบคลุมการโยกย้าย schema (DDL) ด้วย Data Factory
ตัวอย่างโค้ด: การย้าย Schema (DDL) ด้วย Data Factory
คุณสามารถใช้ Fabric Pipelines เพื่อโยกย้ายผ่าน DDL (สคีมา) ของคุณสําหรับออบเจ็กต์ตารางจากฐานข้อมูล Azure SQL ต้นทางหรือพูล SQL เฉพาะได้อย่างง่ายดาย ไปป์ไลน์นี้โยกย้ายผ่าน Schema (DDL) สําหรับตารางพูล SQL เฉพาะต้นทางไปยัง Fabric Warehouse
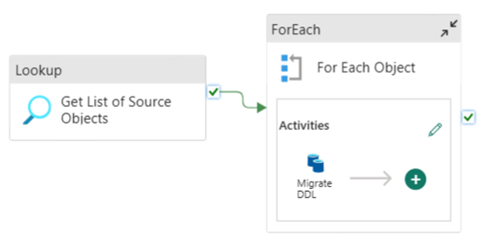
การออกแบบไปป์ไลน์: พารามิเตอร์
ไปป์ไลน์นี้ยอมรับพารามิเตอร์ SchemaNameซึ่งช่วยให้คุณสามารถระบุสคีมาที่จะย้ายได้ เค้าร่าง dbo เป็นค่าเริ่มต้น
ในเขตข้อมูล ค่าเริ่มต้น ให้ใส่รายการแบบคั่นด้วยจุลภาคของ Schema ตารางที่ระบุว่า Schema ใดที่จะโยกย้าย: 'dbo','tpch' เพื่อให้สอง schema dbo และtpch
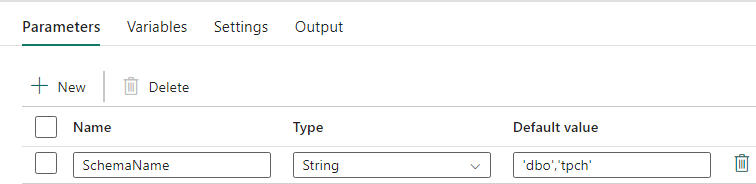
การออกแบบไปป์ไลน์: กิจกรรมการค้นหา
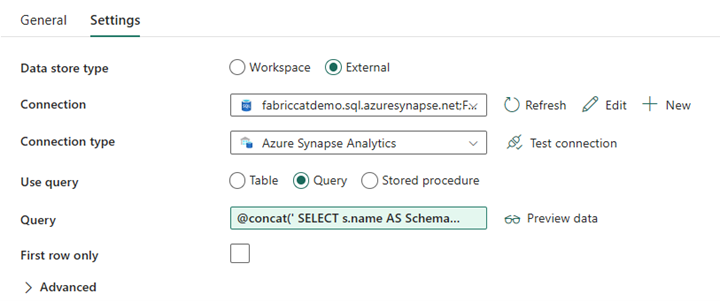
สร้างกิจกรรมการค้นหา และตั้งค่าการเชื่อมต่อเพื่อชี้ไปยังฐานข้อมูลต้นทางของคุณ
ในแท็บ การตั้งค่า :
ตั้งค่าชนิดที่เก็บข้อมูลเป็นภายนอก
การเชื่อมต่อ คือกลุ่ม SQL เฉพาะของ Azure Synapse ของคุณ ชนิดการเชื่อมต่อคือ Azure Synapse Analytics
ใช้คิวรีถูกตั้งค่าเป็นคิวรี
จําเป็นต้อง สร้างเขตข้อมูลคิวรี โดยใช้นิพจน์แบบไดนามิก ที่อนุญาตให้ใช้พารามิเตอร์ SchemaName ในคิวรีที่แสดงรายการของตารางแหล่งข้อมูลเป้าหมาย เลือก คิวรี จากนั้นเลือก เพิ่มเนื้อหาแบบไดนามิก
นิพจน์นี้ภายในกิจกรรม LookUp สร้างคําสั่ง SQL เพื่อคิวรีมุมมองระบบเพื่อเรียกใช้รายการของสคีมาและตาราง อ้างอิงพารามิเตอร์ SchemaName เพื่ออนุญาตให้มีการกรองบน SQL schema ผลลัพธ์ของนี่คืออาร์เรย์ของ SCHEMA SQL และตารางที่จะใช้เป็นข้อมูลป้อนเข้าในกิจกรรม ForEach
ใช้รหัสต่อไปนี้เพื่อแสดงรายการตารางผู้ใช้ทั้งหมดที่มีชื่อแผนการ
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
การออกแบบไปป์ไลน์: ForEach Loop
สําหรับ ForEach Loop ให้กําหนดค่าตัวเลือกต่อไปนี้ใน แท็บ การตั้งค่า :
- ปิดใช้งาน ตามลําดับ เพื่ออนุญาตให้มีการวนซ้ําหลายๆ ครั้งเพื่อเรียกใช้พร้อมกัน
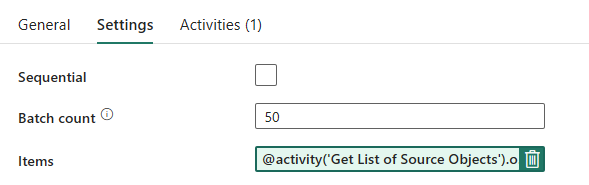
- กําหนด จํานวน ชุดงานเป็น
50โดยจํากัดจํานวนสูงสุดของการทําซ้ําที่เกิดขึ้นพร้อมกัน - เขตข้อมูลรายการจําเป็นต้องใช้เนื้อหาแบบไดนามิกเพื่ออ้างอิงผลลัพธ์ของกิจกรรม LookUp ใช้ส่วนย่อยของโค้ดต่อไปนี้:
@activity('Get List of Source Objects').output.value
การออกแบบไปป์ไลน์: คัดลอกกิจกรรมภายใน ForEach Loop
ภายในกิจกรรม ForEach เพิ่มกิจกรรมการคัดลอก วิธีนี้ใช้ภาษานิพจน์แบบไดนามิกภายในไปป์ไลน์เพื่อสร้าง a SELECT TOP 0 * FROM <TABLE> เพื่อโยกย้ายเฉพาะ Schema ที่ไม่มีข้อมูลไปยัง Fabric Warehouse
ในแท็บ แหล่งข้อมูล :
- ตั้งค่าชนิดที่เก็บข้อมูลเป็นภายนอก
- การเชื่อมต่อ คือกลุ่ม SQL เฉพาะของ Azure Synapse ของคุณ ชนิดการเชื่อมต่อคือ Azure Synapse Analytics
- ตั้งค่า ใช้คิวรี เป็น คิวรี
- ใน เขตข้อมูลคิวรี ให้วางในคิวรีเนื้อหาแบบไดนามิกและใช้นิพจน์นี้ซึ่งจะส่งกลับแถวศูนย์ เฉพาะสคีมาของตาราง:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

ใน แท็บปลายทาง :
- ตั้งค่าประเภทที่เก็บข้อมูลเป็นพื้นที่ทํางาน
- ประเภทที่เก็บข้อมูลพื้นที่ทํางานคือคลังข้อมูลและคลังข้อมูลได้รับการตั้งค่าเป็น Fabric Warehouse
- สคีมาและชื่อของตารางปลายทางจะถูกกําหนดโดยใช้เนื้อหาแบบไดนามิก
- Schema อ้างอิงถึงเขตข้อมูลของการเกิดซ้ําปัจจุบัน SchemaName ที่มีส่วนย่อย:
@item().SchemaName - ตารางจะอ้างอิง TableName ด้วยส่วนย่อย:
@item().TableName
- Schema อ้างอิงถึงเขตข้อมูลของการเกิดซ้ําปัจจุบัน SchemaName ที่มีส่วนย่อย:

การออกแบบไปป์ไลน์: จม
สําหรับอ่างล้างหน้า ให้ชี้ไปที่คลังสินค้าของคุณและอ้างอิง Schema ต้นทางและชื่อตาราง
เมื่อคุณเรียกใช้ไปป์ไลน์นี้ คุณจะเห็นคลังข้อมูลของคุณที่เติมด้วยแต่ละตารางในแหล่งข้อมูลของคุณด้วยสคีมาที่เหมาะสม
การโยกย้ายโดยใช้ขั้นตอนที่จัดเก็บไว้ในพูล SQL เฉพาะ Synapse
ตัวเลือกนี้ใช้ขั้นตอนที่จัดเก็บไว้เพื่อดําเนินการ Fabric Migration
คุณสามารถรับตัวอย่างโค้ดได้ที่ microsoft/fabric-migration บน GitHub.com โค้ดนี้ถูกแชร์เป็นโอเพนซอร์ส (Open Source) ดังนั้นอย่าลังเลที่จะมีส่วนร่วมในการทํางานร่วมกันและช่วยเหลือชุมชน
ขั้นตอนการโยกย้ายที่เก็บไว้สามารถทําอะไรได้บ้าง:
- แปลง schema (DDL) เป็นไวยากรณ์ Fabric Warehouse
- สร้าง Schema (DDL) บน Fabric Warehouse
- แยกข้อมูลจากพูล SQL เฉพาะ Synapse ไปยัง ADLS
- ค่าสถานะไวยากรณ์ Fabric ที่ไม่รองรับสําหรับรหัส T-SQL (กระบวนงานที่เก็บไว้ ฟังก์ชัน มุมมอง)
การใช้งานที่แนะนำ
นี่เป็นตัวเลือกที่ยอดเยี่ยมสําหรับผู้ที่:
- คุ้นเคยกับ T-SQL
- ต้องการใช้สภาพแวดล้อมการพัฒนาแบบรวม เช่น SQL Server Management Studio (SSMS)
- ต้องการควบคุมอย่างละเอียดมากขึ้นว่างานใดที่พวกเขาต้องการใช้งาน
คุณสามารถดําเนินการกระบวนงานที่จัดเก็บเฉพาะสําหรับการแปลง Schema (DDL) การแยกข้อมูล หรือการประเมินรหัส T-SQL
สําหรับการโยกย้ายข้อมูล คุณต้องใช้ทั้ง COPY INTO หรือ Data Factory เพื่อนําเข้าข้อมูลลงใน Fabric Warehouse
โยกย้ายโดยใช้โครงการฐานข้อมูล SQL
Microsoft Fabric Data Warehouse ได้รับการสนับสนุนในส่วนขยายโครงการฐานข้อมูล SQL ที่มีอยู่ภายใน Visual Studio Code
ส่วนขยายนี้พร้อมใช้งานภายใน Visual Studio Code คุณลักษณะนี้ช่วยให้สามารถควบคุมแหล่งข้อมูล การทดสอบฐานข้อมูล และการตรวจสอบเค้าร่างได้
สําหรับข้อมูลเพิ่มเติมเกี่ยวกับตัวควบคุมแหล่งข้อมูลสําหรับคลังสินค้าใน Microsoft Fabric รวมถึงการรวม Git และไปป์ไลน์การปรับใช้ ดูตัวควบคุมแหล่งที่มากับ Warehouse
การใช้งานที่แนะนำ
นี่เป็นตัวเลือกที่ยอดเยี่ยมสําหรับผู้ที่ต้องการใช้โครงการฐานข้อมูล SQL สําหรับการปรับใช้ของพวกเขา ตัวเลือกนี้ทําการผสานรวมกระบวนการจัดเก็บ Fabric Migration ในโครงการฐานข้อมูล SQL เพื่อมอบประสบการณ์การโยกย้ายข้อมูลที่ราบรื่น
โครงการฐานข้อมูล SQL สามารถ:
- แปลง schema (DDL) เป็นไวยากรณ์ Fabric Warehouse
- สร้าง Schema (DDL) บน Fabric Warehouse
- แยกข้อมูลจากพูล SQL เฉพาะ Synapse ไปยัง ADLS
- ตั้งค่าสถานะไวยากรณ์ที่ไม่รองรับสําหรับรหัส T-SQL (กระบวนงานที่เก็บไว้ ฟังก์ชัน มุมมอง)
สําหรับการโยกย้ายข้อมูล คุณจะใช้ทั้งคัดลอกลงในหรือโรงงานข้อมูลเพื่อนําเข้าข้อมูลลงใน Fabric Warehouse
ทีมงาน Microsoft Fabric CAT ได้จัดเตรียมชุดสคริปต์ PowerShell เพื่อจัดการการแยก การสร้าง และการปรับใช้สคีมา (DDL) และรหัสฐานข้อมูล (DML) ผ่านโครงการฐานข้อมูล SQL สําหรับการฝึกปฏิบัติของการใช้โครงการฐานข้อมูล SQL ด้วยสคริปต์ PowerShell ที่เป็นประโยชน์ของเรา โปรดดูที่ microsoft/fabric-migration บน GitHub.com
สําหรับข้อมูลเพิ่มเติมเกี่ยวกับโครงการฐานข้อมูล SQL ดูเริ่มต้นใช้งานส่วนขยายโครงการฐานข้อมูล SQL และ สร้างและเผยแพร่โครงการ
การโยกย้ายข้อมูลด้วย CETAS
คําสั่ง T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) มีวิธีการที่คุ้มค่าและเหมาะสมที่สุดในการดึงข้อมูลจากพูล SQL เฉพาะ Synapse ไปยัง Azure Data Lake Storage (ADLS) Gen2
CETAS ทําอะไรได้บ้าง:
- แยกข้อมูลลงใน ADLS
- ตัวเลือกนี้ต้องการให้ผู้ใช้สร้าง schema (DDL) บน Fabric Warehouse ก่อนที่จะนําเข้าข้อมูล พิจารณาตัวเลือกในบทความนี้เพื่อโยกย้าย schema (DDL)
ข้อดีของตัวเลือกนี้คือ:
- ส่งคิวรีเดียวต่อตารางกับกลุ่ม SQL เฉพาะ Synapse ต้นทางเท่านั้น การดําเนินการนี้จะไม่ใช้ช่องสัญญาณพร้อมกันทั้งหมด และจะไม่บล็อก ETL/คิวรีการผลิตของลูกค้าพร้อมกัน
- ไม่จําเป็นต้องปรับขนาดไปยัง DWU6000 เนื่องจากมีการใช้สล็อตพร้อมกันเดียวสําหรับแต่ละตาราง เพื่อให้ลูกค้าสามารถใช้ DWUs ที่ต่ํากว่าได้
- การแยกจะทํางานควบคู่ไปกับโหนดการคํานวณทั้งหมด และนี่คือกุญแจสําคัญในการปรับปรุงประสิทธิภาพการทํางาน
การใช้งานที่แนะนำ
ใช้ CETAS เพื่อแยกข้อมูลไปยังไฟล์ ADLS เป็นไฟล์ Parquet ไฟล์ Parquet ให้ประโยชน์ของพื้นที่จัดเก็บข้อมูลที่มีประสิทธิภาพพร้อมการบีบอัดแบบคอลัมน์ซึ่งจะใช้แบนด์วิดธ์น้อยกว่าเมื่อย้ายผ่านเครือข่าย นอกจากนี้ เนื่องจาก Fabric จัดเก็บข้อมูลเป็นรูปแบบ Delta parquet การนําเข้าข้อมูลจะเร็วขึ้น 2.5 เท่าเมื่อเทียบกับรูปแบบไฟล์ข้อความ เนื่องจากไม่มีการแปลงเป็นค่าใช้จ่ายของรูปแบบ Delta ในระหว่างการนําเข้า
เมื่อต้องการเพิ่มปริมาณงาน CETAS:
- เพิ่มการดําเนินการ CETAS แบบขนาน เพิ่มการใช้ช่องสัญญาณพร้อมกัน แต่ให้ปริมาณงานเพิ่มขึ้น
- ปรับมาตราส่วน DWU บนพูล SQL เฉพาะ Synapse
การโยกย้ายผ่าน dbt
ในส่วนนี้ เราจะกล่าวถึงตัวเลือก dbt สําหรับลูกค้าที่กําลังใช้ dbt ในสภาพแวดล้อมพูล SQL เฉพาะของ Synapse ปัจจุบัน
dbt ทําอะไรได้บ้าง:
- แปลง schema (DDL) เป็นไวยากรณ์ Fabric Warehouse
- สร้าง Schema (DDL) บน Fabric Warehouse
- แปลงรหัสฐานข้อมูล (DML) เป็นไวยากรณ์ Fabric
เฟรมเวิร์ก dbt สร้าง DDL และ DML (สคริปต์ SQL) ในระหว่างเดินทางพร้อมกับการดําเนินการแต่ละครั้ง ด้วยไฟล์แบบจําลองที่แสดงในคําสั่ง SELECT สามารถแปล DDL/DML ได้ทันทีไปยังแพลตฟอร์มเป้าหมายใด ๆ โดยการเปลี่ยนโปรไฟล์ (สายอักขระการเชื่อมต่อ) และประเภทอะแด็ปเตอร์
การใช้งานที่แนะนำ
เฟรมเวิร์ก dbt คือแนวทางแรกสําหรับโค้ด ข้อมูลต้องถูกโยกย้ายโดยใช้ตัวเลือกที่แสดงในเอกสารนี้ เช่น CETAS หรือ COPY/Data Factory
อะแดปเตอร์ dbt สําหรับ Microsoft Fabric Data Warehouse ช่วยให้โครงการ dbt ที่มีอยู่ซึ่งมีการกําหนดเป้าหมายไปยังแพลตฟอร์มต่าง ๆ เช่น กลุ่ม SQL Synapse เฉพาะ, Snowflake, Databricks, Google Big Query หรือ Amazon Redshift เพื่อโยกย้ายไปยัง Fabric Warehouse ที่มีการเปลี่ยนแปลงการกําหนดค่าอย่างง่าย
เมื่อต้องการเริ่มต้นด้วยโครงการ dbt ที่กําหนดเป้าหมาย Fabric Warehouse โปรดดูบทช่วยสอน: ตั้งค่า dbt สําหรับ Fabric Data Warehouse เอกสารนี้ยังแสดงรายการตัวเลือกเพื่อย้ายระหว่างคลังสินค้า/แพลตฟอร์มต่างๆ
การนําเข้าข้อมูลลงในคลังผ้า
สําหรับการนําเข้าลงใน Fabric Warehouse ให้ใช้ COPY INTO หรือ Fabric Data Factory ขึ้นอยู่กับการกําหนดลักษณะของคุณ ทั้งสองวิธีเป็นตัวเลือกที่แนะนําและมีประสิทธิภาพดีที่สุดเนื่องจากมีปริมาณงานประสิทธิภาพที่เทียบเท่าเนื่องจากข้อกําหนดเบื้องต้นที่ไฟล์ได้รับการแยกออกเป็น Azure Data Lake Storage (ADLS) Gen2 แล้ว
ปัจจัยหลายประการที่ควรทราบเพื่อให้คุณสามารถออกแบบกระบวนการของคุณเพื่อประสิทธิภาพการทํางานสูงสุด:
- ด้วย Fabric จะไม่มีข้อจํากัดด้านทรัพยากรใด ๆ เมื่อโหลดหลายตารางจาก ADLS ไปยัง Fabric Warehouse พร้อมกัน ผลที่ได้คือไม่มีประสิทธิภาพการทํางานลดลงเมื่อโหลดเธรดขนาน ปริมาณการนําเข้าข้อมูลสูงสุดจะถูกจํากัดด้วยกําลังการคํานวณของความจุ Fabric ของคุณเท่านั้น
- การจัดการปริมาณงานผ้ามีการแยกทรัพยากรที่จัดสรรสําหรับการโหลดและคิวรี ไม่มีการช่วงระยะของทรัพยากรในขณะที่คิวรีและข้อมูลกําลังโหลดที่ดําเนินการในเวลาเดียวกัน