หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
Cosmos DB เป็นฐานข้อมูลการวินิจฉัย schema ที่ช่วยให้คุณสามารถทําซ้ําในแอปพลิเคชันของคุณโดยไม่ต้องจัดการกับ schema หรือการจัดการดัชนี สิ่งนี้เรียกอีกอย่างว่า สคีมาในการอ่าน ซึ่งหมายความว่า Cosmos DB จะไม่บังคับใช้ Schema กับข้อมูลของคุณเมื่อเขียนลงในฐานข้อมูล แต่ Schema ของคุณจะถูกฉายภาพลงในคลาสที่คุณกําหนดภายในแอปพลิเคชันของคุณเมื่อคุณ deserialize ข้อมูลจากฐานข้อมูลเมื่อคุณอ่านหรือสืบค้นข้อมูลของคุณ
การทําดัชนีภายใน Cosmos DB ใน Microsoft Fabric ถูกออกแบบมาเพื่อส่งมอบประสิทธิภาพคิวรีที่รวดเร็วและยืดหยุ่น ไม่ว่าข้อมูลของคุณจะพัฒนาขึ้นอย่างไร ตามค่าเริ่มต้น Cosmos DB ทําดัชนีคุณสมบัติทุกรายการสําหรับทุกรายการในคอนเทนเนอร์ของคุณโดยอัตโนมัติโดยไม่ต้องกําหนด schema ใด ๆ หรือกําหนดค่าดัชนีรอง
แผนผังแนวคิด
ทุกครั้งที่จัดเก็บรายการในคอนเทนเนอร์ เนื้อหาจะถูกคาดการณ์เป็นเอกสาร JSON จากนั้นจะถูกแปลงเป็นตัวแทนทรี การแปลงนี้หมายความว่าทุกคุณสมบัติของสินค้านั้นจะถูกแสดงเป็นโหนดในแผนภูมิ โหนดราก pseudo ถูกสร้างขึ้นเป็นคุณสมบัติระดับแรกทั้งหมดของหน่วยข้อมูล โหนดใบไม้ประกอบด้วยค่าสเกลาจริงที่ดําเนินการโดยสินค้า
ตัวอย่างเช่น ให้พิจารณารายการนี้:
{
"locations": [
{
"country": "Germany",
"city": "Berlin"
},
{
"country": "France",
"city": "Paris"
}
],
"headquarters": {
"country": "Belgium",
"employees": 250
},
"exports": [
{
"city": "Moscow"
},
{
"city": "Athens"
}
]
}
แผนภูมิแนวคิดนี้แสดงถึงรายการ JSON ตัวอย่าง:
locations0-
country:Germany -
city:Berlin
-
1-
country:France -
city:Paris
-
headquarters-
country:Belgium -
employees:250
-
exports0-
city:Moscow
-
1-
city:Athens
-
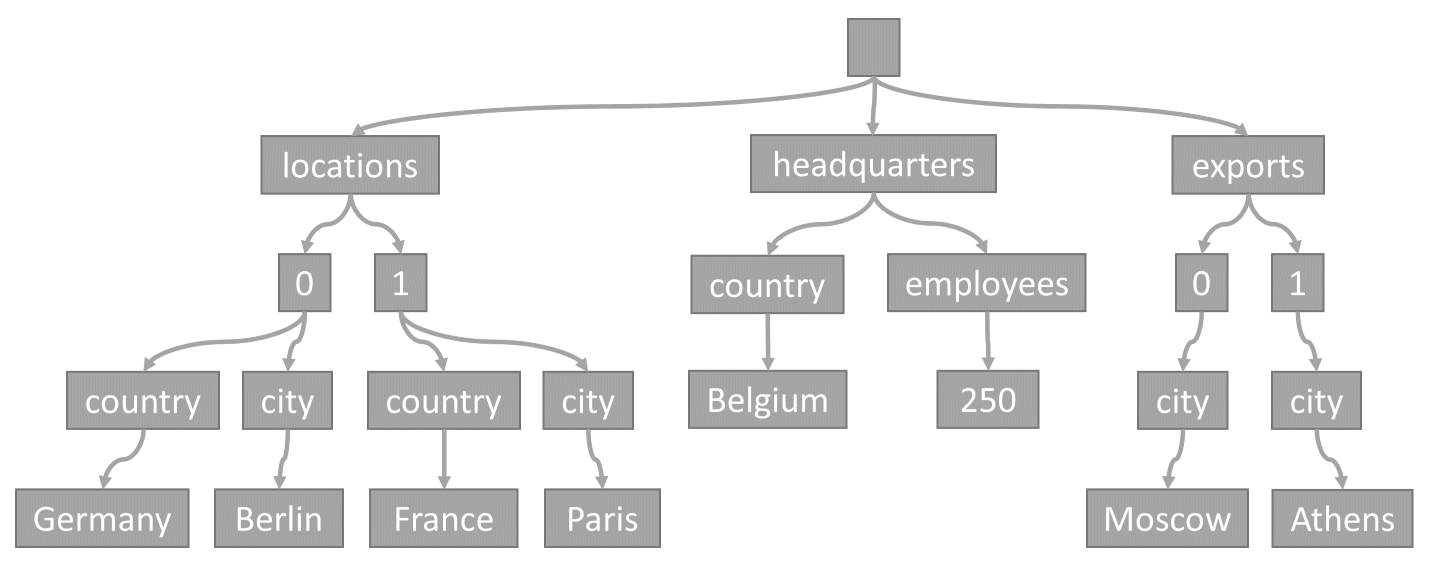
แผนผังต้นไม้ที่แสดงโหนดรากที่มีสามสาขา: "ตําแหน่งที่ตั้ง", "สํานักงานใหญ่" และ "ส่งออก" "ตําแหน่งที่ตั้ง" แยกเป็นโหนดลําดับเลขสองรายการ โดยแต่ละโหนดย่อยที่เกี่ยวข้องกับตําแหน่งที่ตั้ง ("Germany หรือ Berlin" และ "France หรือ Paris") "สํานักงานใหญ่" มี "เบลเยียม" สําหรับตําแหน่งที่ตั้งและ "พนักงาน" ("250") "ส่งออก" แยกเป็นโหนดที่มีตัวเลขสองโหนด โดยแต่ละโหนดย่อย "city" ("มอสโก" และ "Athens")
ให้ความสนใจกับวิธีการเข้ารหัสอาร์เรย์ในทรี: ทุกรายการในอาร์เรย์จะได้รับโหนดขั้นกลางที่มีชื่อว่าดัชนีของรายการนั้นภายในอาร์เรย์ ตัวอย่างเช่น รายการแรกคือ 0 และรายการที่สองคือ1
เส้นทางคุณสมบัติ
Cosmos DB แปลงรายการเป็นต้นไม้เนื่องจากจะช่วยให้ระบบสามารถอ้างอิงคุณสมบัติโดยใช้เส้นทางภายในทรีเหล่านั้น เมื่อต้องการรับเส้นทางสําหรับคุณสมบัติ เราสามารถสํารวจต้นไม้จากโหนดรากไปยังคุณสมบัตินั้น และเชื่อมป้ายกํากับของแต่ละโหนดที่ตรวจสอบแล้วเข้าด้วยกัน
ต่อไปนี้เป็นเส้นทางสําหรับแต่ละคุณสมบัติจากรายการตัวอย่างที่อธิบายไว้ก่อนหน้านี้:
| Path | Value |
|---|---|
/locations/0/country |
"Germany" |
/locations/0/city |
"Berlin" |
/locations/1/country |
"France" |
/locations/1/city |
"Paris" |
/headquarters/country |
"Belgium" |
/headquarters/employees |
250 |
/exports/0/city |
"Moscow" |
/exports/1/city |
"Athens" |
Cosmos DB ทําดัชนีเส้นทางของคุณสมบัติแต่ละเส้นทางและค่าที่สอดคล้องกันอย่างมีประสิทธิภาพเมื่อรายการถูกเขียน
ชนิดดัชนี
ในขณะนี้ Cosmos DB สนับสนุนดัชนีสี่ประเภท
คุณสามารถกําหนดค่าชนิดดัชนีเหล่านี้ได้เมื่อกําหนดนโยบายการทําดัชนี
ดัชนีช่วง
ดัชนีช่วงจะขึ้นอยู่กับโครงสร้างคล้ายต้นไม้ที่เรียงลําดับ นี่คือชนิดดัชนีดีฟอลต์ และไม่จําเป็นต้องระบุเมื่อกําหนดนโยบายดัชนี มีการใช้ชนิดดัชนีช่วงสําหรับ:
คําถามเกี่ยวกับความเท่าเทียมกัน:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM container c WHERE c.property IN ("value1", "value2", "value3")การจับคู่ความเท่ากันบนองค์ประกอบอาร์เรย์
SELECT * FROM container c WHERE ARRAY_CONTAINS(c.tags, "tag1")แบบสอบถามช่วง:
SELECT * FROM container c WHERE c.property > 0Note
ทํางานสําหรับ
>,<,>=,<=!=กําลังตรวจสอบการปรากฏของคุณสมบัติ:
SELECT * FROM container c WHERE IS_DEFINED(c.property)ฟังก์ชันระบบสตริง:
SELECT * FROM container c WHERE CONTAINS(c.property, "value")SELECT * FROM container c WHERE STRINGEQUALS(c.property, "value")ORDER BYแบบ สอบ ถาม:SELECT * FROM container c ORDER BY c.propertyJOINแบบ สอบ ถาม:SELECT d FROM container c JOIN d IN c.properties WHERE d = 'value'
สามารถใช้ดัชนีช่วงกับค่าสเกลา (สตริงหรือตัวเลข) นโยบายการทําดัชนีเริ่มต้นสําหรับคอนเทนเนอร์ที่สร้างขึ้นใหม่จะบังคับใช้ดัชนีช่วงสําหรับสตริงหรือตัวเลขใด ๆ
Note
ORDER BYส่วนคําสั่งที่เรียงลําดับตามคุณสมบัติเดียวจําเป็นต้องมีดัชนีช่วงเสมอ และล้มเหลวหากเส้นทางที่อ้างอิงไม่มีดัชนี ในทํานองเดียวกัน แบบORDER BYสอบถามที่เรียงลําดับตามคุณสมบัติหลายรายการจําเป็นต้องมีดัชนีแบบรวมเสมอ
ดัชนีเชิงพื้นที่
ดัชนีเชิงพื้นที่ช่วยให้สามารถสืบค้นวัตถุเชิงพื้นที่ได้อย่างมีประสิทธิภาพ เช่น จุด เส้น รูปหลายเหลี่ยม และรูปหลายเหลี่ยม คิวรีเหล่านี้ใช้ ST_DISTANCEST_WITHINST_INTERSECTS คําสําคัญ ต่อไปนี้คือตัวอย่างบางส่วนที่ใช้ชนิดดัชนีเชิงพื้นที่:
คิวรีทางภูมิศาสตร์ทางไกล:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Geospatial ภายในคิวรี:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })คิวรีอินเทอร์เซกส์เชิงพื้นที่:
SELECT * FROM container c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
ดัชนีเชิงพื้นที่สามารถใช้กับออบเจ็กต์ GeoJSON ที่จัดรูปแบบได้อย่างถูกต้อง Points, LineStrings, Polygons และ MultiPolygons ได้รับการรองรับในขณะนี้
ดัชนีคอมโพสิต
ดัชนีแบบรวมจะเพิ่มประสิทธิภาพเมื่อคุณดําเนินการในหลายฟิลด์ ชนิดของดัชนีแบบรวมใช้สําหรับ:
ORDER BYคิวรีบนคุณสมบัติหลายรายการ:SELECT * FROM container c ORDER BY c.property1, c.property2คิวรีที่มีตัวกรอง และ
ORDER BYคิวรีเหล่านี้สามารถใช้ดัชนีแบบรวมได้ถ้าคุณสมบัติตัวกรองถูกORDER BYเพิ่มลงในส่วนคําสั่งSELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2คิวรีที่มีตัวกรองบนคุณสมบัติอย่างน้อยสองรายการที่มีคุณสมบัติอย่างน้อยหนึ่งอย่างเป็นตัวกรองความเท่ากัน:
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
ตราบใดที่เพรดิเคตตัวกรองหนึ่งรายการใช้ชนิดดัชนีชนิดใดชนิดหนึ่ง กลไกจัดการคิวรีจะประเมินว่าก่อนการสแกนส่วนที่เหลือ ตัวอย่างเช่น ถ้าคุณมีคิวรี SQL เช่น SELECT * FROM c WHERE c.department = "Information Technology" and CONTAINS(c.team, "Pilot"):
คิวรีนี้ใช้ตัวกรองสําหรับรายการที่
department = "Information Technology"โดยใช้ดัชนีก่อน จากนั้นจะส่งผ่านรายการทั้งหมดdepartment = "Information Technology"ผ่านไปป์ไลน์ถัดไปเพื่อประเมินCONTAINSเพรดิเคตตัวกรองคุณสามารถเพิ่มความเร็วของคิวรีและหลีกเลี่ยงการสแกนคอนเทนเนอร์เต็มรูปแบบเมื่อใช้ฟังก์ชันที่ทําการสแกนเต็มรูปแบบเช่น
CONTAINSคุณสามารถเพิ่มเพรดิเคตตัวกรองเพิ่มเติมที่ใช้ดัชนีเพื่อเพิ่มความเร็วคิวรีเหล่านี้ได้ ลําดับของส่วนคําสั่งตัวกรองไม่สําคัญ กลไกจัดการคิวรีจะหาเพรดิเคตที่เลือกมากขึ้นและเรียกใช้คิวรีตามลําดับ
ดัชนีเวกเตอร์
ดัชนีเวกเตอร์เพิ่มประสิทธิภาพเมื่อทําการค้นหาเวกเตอร์โดยใช้VECTORDISTANCEฟังก์ชันระบบ การค้นหาเวกเตอร์มีเวลาแฝงต่ํากว่า ปริมาณงานที่สูงขึ้น และปริมาณการใช้ RU น้อยลงเมื่อใช้ดัชนีเวกเตอร์ Cosmos DB สนับสนุนการฝังเวกเตอร์ใด ๆ (ข้อความรูปภาพหลายมิติ ฯลฯ ) ภายใต้ขนาด 4,096 ขนาด
ORDER BYคิวรีค้นหาเวกเตอร์:SELECT TOP 10 * FROM container c ORDER BY VECTORDISTANCE(c.vector1, c.vector2)การคาดการณ์ของคะแนนความคล้ายคลึงกันในคิวรีการค้นหาเวกเตอร์:
SELECT TOP 10 c.name, VECTORDISTANCE(c.vector1, c.vector2) AS score FROM container c ORDER BY VECTORDISTANCE(c.vector1, c.vector2)ตัวกรองช่วงบนคะแนนความคล้ายคลึงกัน
SELECT TOP 10 * FROM container c WHERE VECTORDISTANCE(c.vector1, c.vector2) > 0.8 ORDER BY VECTORDISTANCE(c.vector1, c.vector2)
Important
นโยบายเวกเตอร์และดัชนีเวกเตอร์ไม่สามารถใช้งานได้หลังจากการสร้าง เมื่อต้องการเปลี่ยนแปลง ให้สร้างคอลเลกชันใหม่
การใช้ดัชนี
มีห้าวิธีที่กลไกจัดการคิวรีสามารถประเมินตัวกรองคิวรี โดยเรียงลําดับตามมีประสิทธิภาพมากที่สุดเพื่อประสิทธิภาพน้อยที่สุด:
- ดัชนีแสวงหา
- สแกนดัชนีที่แม่นยํา
- การสแกนดัชนีแบบขยาย
- การสแกนดัชนีแบบเต็ม
- สแกนแบบเต็ม
เมื่อคุณทําดัชนีเส้นทางของคุณสมบัติ กลไกจัดการคิวรีจะใช้ดัชนีโดยอัตโนมัติอย่างมีประสิทธิภาพที่สุดเท่าที่เป็นไปได้ นอกเหนือจากการจัดทําดัชนีเส้นทางคุณสมบัติใหม่ คุณไม่จําเป็นต้องกําหนดค่าใด ๆ เพื่อปรับวิธีการใช้คิวรีให้เหมาะสม ค่าธรรมเนียม RU ของคิวรีคือการรวมกันของทั้งค่าธรรมเนียม RU จากการใช้งานดัชนีและค่าธรรมเนียม RU จากการโหลดรายการ
ตารางต่อไปนี้สรุปวิธีการต่าง ๆ ในการใช้ดัชนีใน Cosmos DB:
| ชนิดการค้นหา | Description | ตัวอย่างทั่วไป | ค่าธรรมเนียมจากการใช้งานดัชนี | ค่าธรรมเนียมจากการโหลดสินค้าจากที่เก็บข้อมูลทางธุรกรรม |
|---|---|---|---|---|
| ดัชนีแสวงหา | อ่านค่าที่มีการจัดทําดัชนีที่จําเป็นเท่านั้น และโหลดเฉพาะรายการที่ตรงกันจากที่เก็บข้อมูลทางธุรกรรม | ตัวกรองความเท่ากัน IN | ตัวกรองความเท่ากันคงที่ | เพิ่มตามจํานวนรายการในผลลัพธ์คิวรี |
| สแกนดัชนีที่แม่นยํา | ค้นหาค่าที่เป็นดัชนีไบนารีและโหลดเฉพาะรายการที่ตรงกันจากที่เก็บข้อมูลทรานแซคชัน | การเปรียบเทียบช่วง (>, , <<= หรือ >=), StartsWith | เปรียบเทียบกับการค้นหาดัชนี เพิ่มเล็กน้อยตามคาร์ดินาลลิตี้ของคุณสมบัติที่จัดทําดัชนี | เพิ่มตามจํานวนรายการในผลลัพธ์คิวรี |
| การสแกนดัชนีแบบขยาย | การค้นหาที่ปรับให้เหมาะสม (แต่มีประสิทธิภาพน้อยกว่าการค้นหาไบนารี) ของค่าที่มีการจัดทําดัชนี และโหลดเฉพาะรายการที่ตรงกันจากที่เก็บข้อมูลทรานแซคชัน | StartsWith (ไม่ตรงตามตัวพิมพ์ใหญ่-เล็ก), StringEquals (ไม่ตรงตามตัวพิมพ์ใหญ่-เล็ก) | เพิ่มขึ้นเล็กน้อยขึ้นอยู่กับคาร์ดินาลลิตี้ของคุณสมบัติที่จัดทําดัชนี | เพิ่มตามจํานวนรายการในผลลัพธ์คิวรี |
| การสแกนดัชนีแบบเต็ม | อ่านชุดค่าดัชนีที่แตกต่างกันและโหลดเฉพาะรายการที่ตรงกันจากที่เก็บข้อมูลเชิงธุรกรรม | ประกอบด้วย, EndsWith, RegexMatch, LIKE | เพิ่มเชิงเส้นตามคาร์ดินาลลิตี้ของคุณสมบัติที่จัดทําดัชนี | เพิ่มตามจํานวนรายการในผลลัพธ์คิวรี |
| สแกนแบบเต็ม | โหลดสินค้าทั้งหมดจากที่เก็บข้อมูลธุรกรรม | บน, ล่าง | N/A | เพิ่มตามจํานวนสินค้าในคอนเทนเนอร์ |
เมื่อเขียนคิวรี คุณควรใช้เพรดิเคตตัวกรองที่ใช้ดัชนีอย่างมีประสิทธิภาพที่สุดเท่าที่เป็นไปได้ ตัวอย่างเช่นถ้า StartsWith หรือ Contains จะทํางานสําหรับกรณีการใช้งานของคุณ คุณควรเลือก StartsWith ใช้เนื่องจากเป็นการสแกนดัชนีที่แม่นยําแทนที่จะเป็นการสแกนดัชนีเต็มรูปแบบ
รายละเอียดการใช้ดัชนี
Tip
ส่วนนี้ครอบคลุมรายละเอียดเพิ่มเติมเกี่ยวกับวิธีการใช้ดัชนีคิวรี ระดับรายละเอียดนี้ไม่จําเป็นต้องเรียนรู้วิธีการเริ่มต้นใช้งาน Cosmos DB แต่ได้รับการจัดทําเป็นเอกสารในรายละเอียดสําหรับผู้ใช้ที่อยากรู้อยากเห็น เราอ้างอิงรายการตัวอย่างที่ใช้ร่วมกันก่อนหน้านี้ในเอกสารนี้:
พิจารณาสองรายการตัวอย่างเหล่านี้:
[
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
},
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
]
Cosmos DB ใช้ดัชนีผกผุด ดัชนีทํางานโดยการแมปเส้นทาง JSON แต่ละเส้นทางไปยังชุดของรายการที่ประกอบด้วยค่านั้น การแมปรหัสรายการจะแสดงในหน้าดัชนีที่แตกต่างกันมากมายสําหรับคอนเทนเนอร์ นี่คือไดอะแกรมตัวอย่างของดัชนีผกผลักสําหรับคอนเทนเนอร์ที่มีสองรายการตัวอย่าง:
| Path | Value | รายการตัวระบุหน่วยข้อมูล |
|---|---|---|
/locations/0/country |
Germany |
[1] |
/locations/0/country |
Ireland |
[2] |
/locations/0/city |
Berlin |
[1] |
/locations/0/city |
Dublin |
[2] |
/locations/1/country |
France |
[1] |
/locations/1/city |
Paris |
[1] |
/headquarters/country |
Belgium |
[1, 2] |
/headquarters/employees |
200 |
[2] |
/headquarters/employees |
250 |
[1] |
ดัชนีแบบผกผกผสองมีแอตทริบิวต์ที่สําคัญสองอย่าง:
สําหรับเส้นทางที่กําหนด ค่าจะเรียงลําดับจากน้อยไปหามาก ดังนั้น กลไกจัดการคิวรีสามารถให้บริการ
ORDER BYได้อย่างง่ายดายจากดัชนีสําหรับเส้นทางที่กําหนด กลไกจัดการคิวรีสามารถสแกนผ่านชุดค่าที่เป็นไปได้ที่แตกต่างกันเพื่อระบุหน้าดัชนีที่มีผลลัพธ์
กลไกจัดการคิวรีสามารถใช้ประโยชน์จากดัชนีผกผังในสี่วิธีที่แตกต่างกัน:
ดัชนีแสวงหา
พิจารณาคิวรีต่อไปนี้:
SELECT
location
FROM
location IN company.locations
WHERE
location.country = 'France'
เพรดิเคตคิวรี (การกรองบนรายการที่มีตําแหน่งที่ตั้งใด ๆ มี "ฝรั่งเศส" เป็นภูมิภาคของมัน) จะตรงกับเส้นทางที่ถูกเรียกมาที่นี่:
locations1-
country:France
-
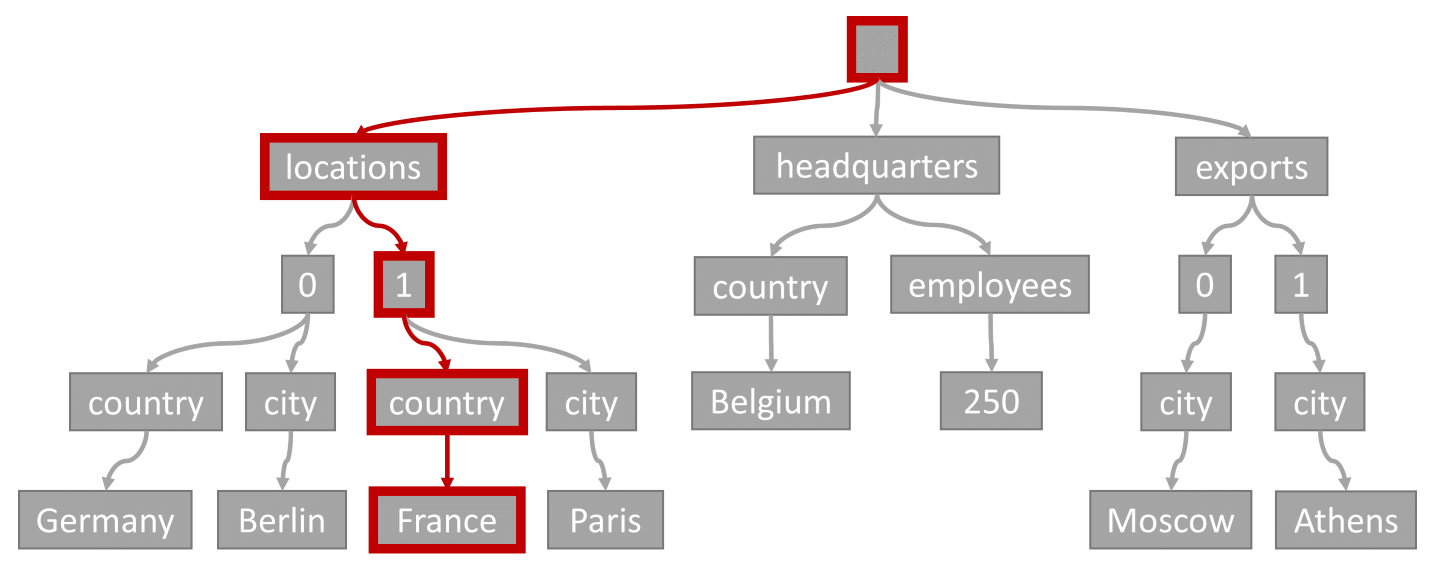
แผนผังต้นไม้ที่แสดงโหนดรากที่มีสามสาขา: "ตําแหน่งที่ตั้ง", "สํานักงานใหญ่" และ "ส่งออก" "ตําแหน่งที่ตั้ง" แยกเป็นโหนดลําดับเลขสองรายการ โดยแต่ละโหนดย่อยที่เกี่ยวข้องกับตําแหน่งที่ตั้ง ("Germany/Berlin" และ "France/Paris") "สํานักงานใหญ่" มี "เบลเยียม" สําหรับตําแหน่งที่ตั้งและ "พนักงาน" ("250") "ส่งออก" แยกเป็นโหนดที่มีตัวเลขสองโหนด โดยแต่ละโหนดย่อย "city" ("มอสโก" และ "Athens") เส้นทางสําหรับ "ตําแหน่งที่ตั้ง" "1" ตําแหน่ง และ "ฝรั่งเศส" จะถูกเน้น
เนื่องจากคิวรีนี้มีตัวกรองความเท่ากัน หลังจากย้อนกลับทรีนี้ เราสามารถระบุหน้าดัชนีที่มีผลลัพธ์คิวรีได้อย่างรวดเร็ว ในกรณีนี้ กลไกจัดการคิวรีจะอ่านหน้าดัชนีที่ประกอบด้วยหน่วยข้อมูล 1 การค้นหาดัชนีเป็นวิธีที่มีประสิทธิภาพที่สุดในการใช้ดัชนี ด้วยการค้นหาดัชนี เราจะอ่านเฉพาะหน้าดัชนีที่จําเป็นและโหลดเฉพาะรายการในผลลัพธ์คิวรีเท่านั้น ดังนั้นเวลาในการค้นหาดัชนีและค่าธรรมเนียม RU จากการค้นหาดัชนีจึงต่ําอย่างไม่น่าเชื่อ โดยไม่คํานึงถึงปริมาณข้อมูลทั้งหมด
สแกนดัชนีที่แม่นยํา
พิจารณาคิวรีต่อไปนี้:
SELECT
*
FROM
company
WHERE
company.headquarters.employees > 200
เพรดิเคตคิวรี (การกรองบนรายการที่มีพนักงานมากกว่า 200 คน) สามารถประเมินได้ด้วยการสแกนดัชนีที่แม่นยําของ headquarters/employees เส้นทาง เมื่อทําการสแกนดัชนีที่แม่นยํา กลไกจัดการคิวรีเริ่มต้นโดยทําการค้นหาแบบไบนารีของชุดค่าที่แตกต่างกันเพื่อหาตําแหน่งที่ตั้งของค่า 200 สําหรับ headquarters/employees เส้นทาง เนื่องจากค่าสําหรับแต่ละเส้นทางจะเรียงลําดับจากน้อยไปหามาก จึงเป็นเรื่องง่ายสําหรับเครื่องมือคิวรีที่จะทําการค้นหาไบนารี หลังจากที่กลไกจัดการคิวรีพบค่า 200แล้ว จะเริ่มอ่านหน้าดัชนีที่เหลือทั้งหมด (ไปในทิศทางจากน้อยไปหามาก)
เนื่องจากกลไกจัดการคิวรีสามารถทําการค้นหาไบนารีเพื่อหลีกเลี่ยงการสแกนหน้าดัชนีที่ไม่จําเป็น การสแกนดัชนีที่แม่นยําจึงมีแนวโน้มที่จะมีความล่าช้าที่เปรียบเทียบและค่าใช้จ่าย RU ในการทําดัชนีการค้นหาการดําเนินการ
การสแกนดัชนีแบบขยาย
พิจารณาคิวรีต่อไปนี้:
SELECT
*
FROM
company
WHERE
STARTSWITH(company.headquarters.country, "United", true)
เพรดิเคตคิวรี (การกรองรายการที่มีสํานักงานใหญ่ในตําแหน่งที่ตั้งที่เริ่มต้นด้วย "United") ที่ไม่ตรงตามตัวพิมพ์ใหญ่-เล็ก) สามารถประเมินได้ด้วยการสแกนดัชนีแบบขยายของ headquarters/country เส้นทาง การดําเนินการที่ทําการสแกนดัชนีแบบขยายมีการปรับให้เหมาะสมซึ่งสามารถช่วยหลีกเลี่ยงความต้องการในการสแกนทุกหน้าดัชนี แต่มีราคาแพงกว่าการค้นหาไบนารีของดัชนีที่แม่นยําเล็กน้อย
ตัวอย่างเช่น เมื่อประเมินค่าที่ไม่ตรงตาม StartsWithตัวพิมพ์ใหญ่-เล็ก กลไกจัดการคิวรีจะตรวจสอบดัชนีสําหรับการรวมที่เป็นไปได้ที่แตกต่างกันของค่าตัวพิมพ์ใหญ่และตัวพิมพ์เล็ก การปรับให้เหมาะสมนี้ช่วยให้กลไกจัดการคิวรีสามารถหลีกเลี่ยงการอ่านหน้าดัชนีส่วนใหญ่ได้ ฟังก์ชันระบบที่แตกต่างกันมีการปรับให้เหมาะสมที่แตกต่างกันที่พวกเขาสามารถใช้เพื่อหลีกเลี่ยงการอ่านทุกหน้าดัชนีเพื่อให้มีการจัดประเภทอย่างกว้างขวางเป็นการสแกนดัชนีที่ขยาย
การสแกนดัชนีแบบเต็ม
พิจารณาคิวรีต่อไปนี้:
SELECT
*
FROM
company
WHERE
CONTAINS(company.headquarters.country, "United")
เพรดิเคตคิวรี (การกรองบนรายการที่มีสํานักงานใหญ่ในตําแหน่งที่ตั้งที่มี "สหรัฐ") สามารถประเมินได้ด้วยการสแกนดัชนีของ headquarters/country เส้นทาง การสแกนดัชนีแบบเต็มจะสแกนผ่านชุดค่าที่เป็นไปได้ที่แตกต่างกันเพื่อระบุหน้าดัชนีที่มีผลลัพธ์ซึ่งไม่เหมือนกับการสแกนดัชนีที่แม่นยํา ในกรณีนี้ CONTAINS จะถูกเรียกใช้บนดัชนี เวลาในการค้นหาดัชนีและค่าธรรมเนียม RU สําหรับการสแกนดัชนีเพิ่มขึ้นเมื่อคาร์ดินาลลิตี้ของเส้นทางเพิ่มขึ้น กล่าวอีกนัยหนึ่ง คือ ยิ่งค่าที่แตกต่างกันมากขึ้นเท่าใด กลไกจัดการคิวรีจําเป็นต้องสแกน ก็จะยิ่งความล่าช้าและค่าธรรมเนียม RU เกี่ยวข้องในการสแกนดัชนีเต็มรูปแบบสูงขึ้นเท่านั้น
ตัวอย่างเช่น พิจารณาคุณสมบัติสองประการ: town และcountry คาร์ดินาลลิตี้ของเมืองคือ 5,000 และคาร์ดินาลลิตี้ของ country คือ 200 ต่อไปนี้คือคิวรีตัวอย่างสองรายการที่แต่ละรายการมี CONTAINS ฟังก์ชันระบบที่ทําการสแกนดัชนีเต็มรูปแบบกับ town คุณสมบัติ คิวรีแรกใช้หน่วยคําขอเพิ่มเติม (RUs) มากกว่าคิวรีที่สองเนื่องจากคาร์ดินาลลิตี้ของเมืองสูงกว่าcountry
SELECT
*
FROM
container c
WHERE
CONTAINS(c.town, "Red", false)
SELECT
*
FROM
c
WHERE
CONTAINS(c.country, "States", false)
สแกนแบบเต็ม
ในบางกรณี กลไกจัดการคิวรีอาจไม่สามารถประเมินตัวกรองคิวรีโดยใช้ดัชนีได้ ในกรณีนี้ กลไกจัดการคิวรีจําเป็นต้องโหลดรายการทั้งหมดจากที่เก็บทรานแซคชันเพื่อประเมินตัวกรองคิวรี การสแกนแบบเต็มรูปแบบไม่ได้ใช้ดัชนีและมีค่าใช้จ่าย RU ที่เพิ่มขึ้นเชิงเส้นด้วยขนาดข้อมูลทั้งหมด โชคดีที่การดําเนินการที่จําเป็นต้องมีการสแกนอย่างเต็มรูปแบบนั้นหายาก
คิวรีเวกเตอร์ค้นหาโดยไม่มีดัชนีเวกเตอร์ที่กําหนด
ถ้าคุณไม่ได้กําหนดนโยบายดัชนีเวกเตอร์และใช้ VECTORDISTANCE ฟังก์ชันระบบใน ORDER BY คําสั่งย่อย คิวรีนี้จะส่งผลให้มีการสแกนเต็มรูปแบบและมีค่าธรรมเนียม RU สูงกว่านโยบายดัชนีเวกเตอร์หากคุณกําหนดนโยบายดัชนีเวกเตอร์ ความคล้ายคลึงกัน หากคุณใช้กับ VECTORDISTANCE ค่าบูลีนเดรัจฉานที่ตั้งค่าเป็น จริง และไม่มี flat ดัชนีที่กําหนดไว้สําหรับเส้นทางเวกเตอร์ การสแกนแบบเต็มจะเกิดขึ้น
คิวรีที่มีนิพจน์ตัวกรองที่ซับซ้อน
ในตัวอย่างก่อนหน้านี้ เราพิจารณาเฉพาะคิวรีที่มีนิพจน์ตัวกรองอย่างง่าย (ตัวอย่างเช่น คิวรีที่มีเพียงตัวกรองความเท่ากันหรือช่วงเดียว) ในความเป็นจริง คิวรีส่วนใหญ่มีนิพจน์ตัวกรองที่ซับซ้อนมากขึ้น
พิจารณาคิวรีต่อไปนี้:
SELECT
*
FROM
company
WHERE
company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
เมื่อต้องดําเนินการคิวรีนี้ กลไกจัดการคิวรีจะต้องค้นหาดัชนีheadquarters/employeesและการสแกนดัชนีเต็มรูปแบบบนheadquarters/country กลไกจัดการคิวรีมีฮิวริสติกภายในที่ใช้ในการประเมินนิพจน์ตัวกรองคิวรีอย่างมีประสิทธิภาพที่สุดเท่าที่เป็นไปได้ ในกรณีนี้ กลไกจัดการคิวรีจะหลีกเลี่ยงความจําเป็นในการอ่านหน้าดัชนีที่ไม่จําเป็น โดยการดําเนินการค้นหาดัชนีก่อน ตัวอย่างเช่น ถ้ามีเพียง 50 รายการเท่านั้นที่ตรงกับตัวกรองความเท่ากัน กลไกจัดการคิวรีจะต้องประเมิน CONTAINS บนหน้าดัชนีที่มี 50 รายการเหล่านั้น การสแกนดัชนีแบบเต็มของคอนเทนเนอร์ทั้งหมดจะไม่จําเป็น
การใช้ดัชนีสําหรับฟังก์ชันการรวมสเกลา
คิวรีที่มีฟังก์ชันการรวมต้องขึ้นอยู่กับดัชนีเท่านั้นจึงจะสามารถใช้งานได้
ในบางกรณี ดัชนีสามารถส่งกลับค่าบวกเท็จ ตัวอย่างเช่น เมื่อประเมิน CONTAINS ผลดัชนี จํานวนรายการที่ตรงกันในดัชนีอาจเกินจํานวนผลลัพธ์คิวรี กลไกจัดการคิวรีจะโหลดรายการที่ตรงกันของดัชนีทั้งหมด ประเมินตัวกรองบนรายการที่โหลด และแสดงเฉพาะผลลัพธ์ที่ถูกต้องเท่านั้น
สําหรับคิวรีส่วนใหญ่ การโหลดรายการที่ตรงกันกับดัชนีค่าบวกเท็จจะไม่มีผลกระทบใด ๆ ที่เห็นได้ชัดเจนต่อการใช้ดัชนี
ตัวอย่างเช่น ให้พิจารณาคิวรีต่อไปนี้:
SELECT
*
FROM
company
WHERE
CONTAINS(company.headquarters.country, "United")
ฟังก์ชัน CONTAINS ระบบอาจส่งกลับค่าที่ตรงกันเชิงบวกเท็จ ดังนั้นกลไกจัดการคิวรีจําเป็นต้องตรวจสอบว่ารายการที่โหลดแต่ละรายการตรงกับนิพจน์ตัวกรองหรือไม่ ในตัวอย่างนี้ กลไกจัดการคิวรีอาจจําเป็นต้องโหลดรายการเพิ่มเติมเพียงไม่กี่รายการ เท่านั้น ดังนั้นผลกระทบต่อการใช้ดัชนีและค่าธรรมเนียม RU จึงมีไม่มาก
อย่างไรก็ตาม คิวรีที่มีฟังก์ชันการรวมจะต้องพึ่งพาดัชนีเป็นพิเศษเพื่อใช้งาน ตัวอย่างเช่น พิจารณาคิวรีต่อไปนี้ที่มี COUNT การรวม:
SELECT
COUNT(1)
FROM
company
WHERE
CONTAINS(company.headquarters.country, "United")
เช่นเดียวกับในตัวอย่าง CONTAINS แรก ฟังก์ชันระบบอาจส่งคืนการจับคู่ค่าบวกเท็จบางอย่าง
SELECT *อย่างไรก็ตาม แตกต่างจากคิวรี อย่างไรก็ตาม COUNT คิวรีไม่สามารถประเมินนิพจน์ตัวกรองบนรายการที่โหลดเพื่อตรวจสอบรายการดัชนีทั้งหมดที่ตรงกัน คิวรี COUNT ต้องพึ่งพาดัชนีโดยเฉพาะ ดังนั้นถ้ามีโอกาสที่นิพจน์ตัวกรองจะส่งกลับค่าที่ตรงกันเชิงบวกเท็จ กลไกจัดการคิวรีจะเริ่มต้นการสแกนเต็มรูปแบบ
คิวรีที่มีฟังก์ชันการรวมต่อไปนี้ต้องขึ้นอยู่กับดัชนีเท่านั้น ดังนั้นการประเมินฟังก์ชันระบบบางอย่างต้องมีการสแกนเต็มรูปแบบ