หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
การแปลงทางลัดจะแปลงไฟล์ดิบ (CSV, Parquet และ JSON) เป็นตารางเดลต้าที่ซิงค์กับข้อมูลต้นฉบับอยู่เสมอ การแปลงจะดําเนินการโดย การคํานวณ Fabric Spark ซึ่งจะคัดลอกข้อมูลที่อ้างอิงโดยทางลัด OneLake ไปยังตารางเดลต้าที่มีการจัดการ คุณจึงไม่ต้องสร้างและประสานไปป์ไลน์การแยก แปลง โหลด (ETL) แบบดั้งเดิมด้วยตัวคุณเอง ด้วยการจัดการสคีมาอัตโนมัติ ความสามารถในการทําให้แบนราบลึก และการรองรับรูปแบบการบีบอัดหลายรูปแบบ การแปลงทางลัดจะช่วยขจัดความซับซ้อนในการสร้างและบํารุงรักษาไปป์ไลน์ ETL
Note
การแปลงทางลัดอยู่ใน การแสดงตัวอย่างสาธารณะ และอาจมีการเปลี่ยนแปลง
เหตุใดจึงใช้การแปลงทางลัด
- ไม่มีไปป์ไลน์ด้วยตนเอง – Fabric จะคัดลอกและแปลงไฟล์ต้นฉบับเป็นรูปแบบ Delta โดยอัตโนมัติ คุณไม่จําเป็นต้องปรับการโหลดแบบเพิ่มหน่วย
- รีเฟรชบ่อยครั้ง – Fabric จะตรวจสอบทางลัดทุกๆ 2 นาที และซิงโครไนซ์การเปลี่ยนแปลงใดๆ เกือบจะในทันที
- เปิดและพร้อมสําหรับการวิเคราะห์ – เอาต์พุตคือตาราง Delta Lake ที่เครื่องมือที่เข้ากันได้กับ Apache Spark ใด ๆ สามารถคิวรีได้
- การกํากับดูแลแบบครบวงจร – ทางลัดสืบทอดสายข้อมูล สิทธิ์ และนโยบาย Microsoft Purview ของ OneLake
- ตาม Spark – แปลงสร้างตามขนาด
Prerequisites
| Requirement | Details |
|---|---|
| Microsoft Fabric SKU | ความจุหรือการทดลองใช้ที่รองรับปริมาณงาน Lakehouse |
| แหล่งข้อมูล | โฟลเดอร์ที่มีไฟล์ CSV, Parquet หรือ JSON ที่เป็นเนื้อเดียวกัน |
| บทบาทพื้นที่ทํางาน | ผู้สนับสนุนหรือสูงกว่า |
แหล่งที่มา รูปแบบ และปลายทางที่รองรับ
แหล่งข้อมูลทั้งหมดที่รองรับใน OneLake ได้รับการสนับสนุน
| รูปแบบไฟล์ต้นฉบับ | ปลายทาง | ส่วนขยายที่รองรับ | ประเภทการบีบอัดที่รองรับ | หมาย เหตุ |
|---|---|---|---|---|
| ซีเอสวี (UTF-8, UTF-16) | ตาราง Delta Lake ในโฟลเดอร์ Lakehouse / Tables | .csv,.txt(ตัวคั่น), .tsv (แยกแท็บ), .psv (แยกท่อ), | .csv.gz.csv.bz2 | .csv.zip.csv.snappy ไม่ได้รับการสนับสนุน ณ วันที่ |
| Parquet | ตาราง Delta Lake ในโฟลเดอร์ Lakehouse / Tables | .ปาร์เก้ | .parquet.snappy,.parquet.gzip,.parquet.lz4,.parquet.brotli,.parquet.zstd | |
| JSON | ตาราง Delta Lake ในโฟลเดอร์ Lakehouse / Tables | .json,.jsonl,.ndjson | .json.gz,.json.bz2,.jsonl.gz,.ndjson.gz,.jsonl.bz2,.ndjson.bz2 | .json.zip.json.snappy ไม่ได้รับการสนับสนุน ณ วันที่ |
- การสนับสนุนไฟล์ Excel เป็นส่วนหนึ่งของแผนงาน
- การแปลง AI พร้อมใช้งานเพื่อรองรับรูปแบบไฟล์ที่ไม่มีโครงสร้าง (.txt, .doc, .docx) ด้วยกรณีการใช้งาน Text Analytics พร้อมการปรับปรุงเพิ่มเติมที่กําลังจะมาถึง
ตั้งค่าการแปลงทางลัด
ในส่วนเลคเฮาส์ของคุณ ให้เลือก ทางลัดตารางใหม่ในส่วนตาราง ซึ่งเป็นการแปลงทางลัด (พรีวิว) และเลือกแหล่งที่มาของคุณ (ตัวอย่างเช่น Azure Data Lake, Azure Blob Storage, Dataverse, Amazon S3, GCP, SharePoint, OneDrive เป็นต้น)
เลือกไฟล์ กําหนดค่าการแปลง และสร้างทางลัด – เรียกดูทางลัด OneLake ที่มีอยู่ซึ่งชี้ไปที่โฟลเดอร์ที่มีไฟล์ CSV กําหนดค่าพารามิเตอร์ และเริ่มการสร้าง
- ตัวคั่น ในไฟล์ CSV – เลือกอักขระที่ใช้ในการแยกคอลัมน์ (จุลภาค อัฒภาค ไปป์ แท็บ เครื่องหมายและ ช่องว่าง)
- แถวแรกเป็นส่วนหัว – ระบุว่าแถวแรกมีชื่อคอลัมน์หรือไม่
- ชื่อทางลัดตาราง – ระบุชื่อที่จําง่าย Fabric สร้างภายใต้ /Tables
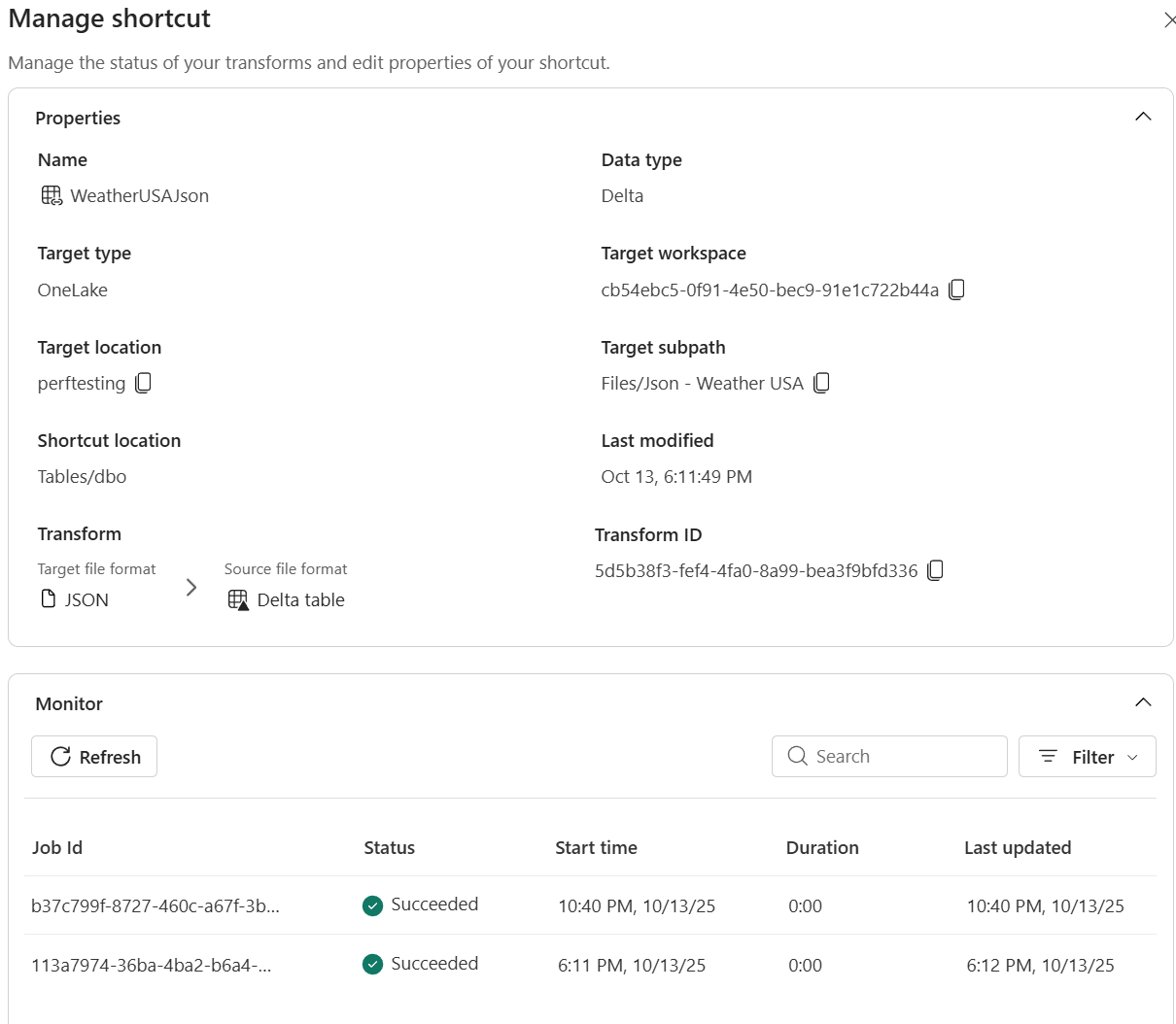
ติดตามการรีเฟรชและดูบันทึกเพื่อความโปร่งใสในฮับจัดการการตรวจสอบทางลัด
การคํานวณ Fabric Spark คัดลอกข้อมูลลงในตารางเดลต้า และแสดงความคืบหน้าในบานหน้าต่าง จัดการทางลัด การแปลงทางลัดมีอยู่ในรายการเลคเฮาส์ พวกเขาสร้างตาราง Delta Lake ในโฟลเดอร์ Lakehouse / Tables
การซิงโครไนซ์ทํางานอย่างไร
หลังจากการโหลดเริ่มต้น การคํานวณ Fabric Spark:
- สํารวจเป้าหมายปุ่มลัดทุก 2 นาที
- ตรวจพบ ไฟล์ใหม่หรือไฟล์ที่ปรับเปลี่ยน และผนวกหรือเขียนทับแถวตามนั้น
- ตรวจหา ไฟล์ที่ถูกลบ และลบแถวที่เกี่ยวข้อง
ตรวจสอบและแก้ไขปัญหา
การแปลงทางลัดรวมถึงการตรวจสอบและการจัดการข้อผิดพลาดเพื่อช่วยคุณติดตามสถานะการนําเข้าและวินิจฉัยปัญหา
- เปิดเลคเฮาส์แล้วคลิกขวาที่ทางลัดที่ป้อนการแปลงของคุณ
- เลือก จัดการทางลัด
- ในบานหน้าต่างรายละเอียด คุณสามารถดูสิ่งต่อไปนี้ได้
- สถานะ – ผลการสแกนล่าสุดและสถานะการซิงค์ปัจจุบัน
-
ประวัติการรีเฟรช – รายการตามลําดับเวลาของการดําเนินการซิงค์ที่มีจํานวนแถวและรายละเอียดข้อผิดพลาดใดๆ
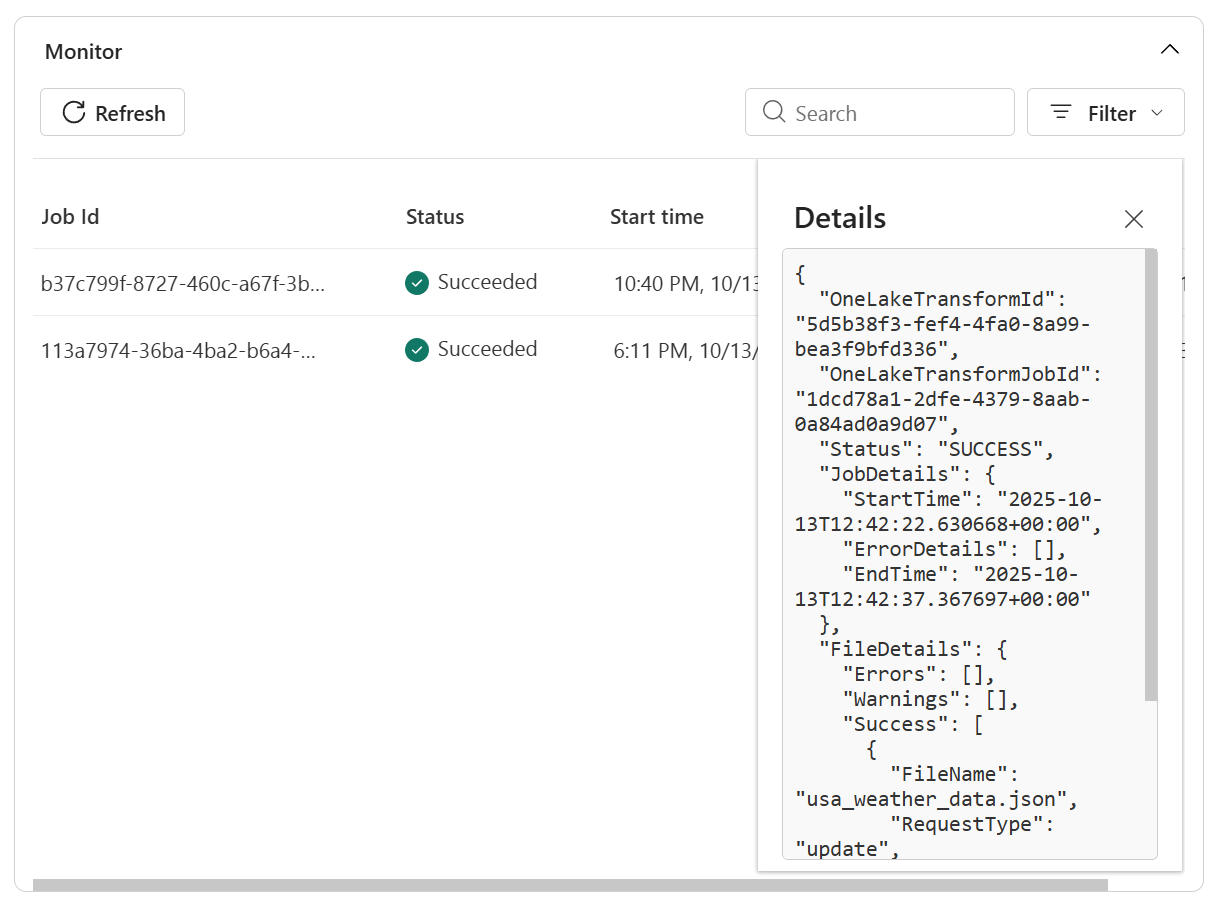
- ดูรายละเอียดเพิ่มเติมในบันทึกเพื่อแก้ไขปัญหา
Note
หยุดชั่วคราว หรือ ลบ การแปลงจากแท็บนี้เป็นส่วนหนึ่งของคุณลักษณะที่กําลังจะมาถึงของแผนงาน
Limitations
ข้อจํากัดในปัจจุบันของการแปลงทางลัด:
- รองรับเฉพาะรูปแบบไฟล์ CSV, Parquet, JSON เท่านั้น
- ไฟล์ต้องใช้สคีมาที่เหมือนกัน ยังไม่ได้รับการสนับสนุนการดริฟท์สคีมา
- การแปลงได้รับการ ปรับให้เหมาะสมกับการอ่าน คําสั่ง MERGE INTO หรือ DELETE โดยตรงบนตารางจะถูกบล็อก
- ใช้ได้เฉพาะในรายการ Lakehouse (ไม่ใช่คลังสินค้าหรือฐานข้อมูล KQL)
- ชนิดข้อมูลที่ไม่รองรับสําหรับ CSV: คอลัมน์ชนิดข้อมูลผสม, Timestamp_Nanos, ชนิดตรรกะที่ซับซ้อน - MAP/LIST/STRUCT, ไบนารีดิบ
- ชนิดข้อมูลที่ไม่รองรับสําหรับ Parquet: Timestamp_nanos, ทศนิยมที่มี INT32/INT64, INT96, ประเภทจํานวนเต็มที่ไม่ได้กําหนด - UINT_8/UINT_16/UINT_64, ประเภทตรรคณิตศาสตร์ที่ซับซ้อน - MAP/LIST/STRUCT)
- ชนิดข้อมูลที่ไม่รองรับสําหรับ JSON: ประเภทข้อมูลแบบผสมในอาร์เรย์ Blobs ไบนารีดิบภายใน JSON Timestamp_Nanos
- การแบนประเภทข้อมูลอาร์เรย์ใน JSON: ประเภทข้อมูลอาร์เรย์จะถูกเก็บไว้ในตารางเดลต้าและข้อมูลที่เข้าถึงได้ด้วย Spark SQL & Pyspark ซึ่งสําหรับการแปลงเพิ่มเติม Fabric Materialized Lake Views สามารถใช้สําหรับเลเยอร์เงินได้
- รูปแบบแหล่งที่มา: รองรับเฉพาะไฟล์ CSV, JSON และ Parquet เท่านั้น ณ วันที่
- ความลึกของการแบนราบใน JSON: โครงสร้างที่ซ้อนกันจะถูกทําให้แบนราบลึกถึงห้าระดับ การซ้อนที่ลึกขึ้นต้องมีการประมวลผลล่วงหน้า
- การดําเนินการเขียน: การแปลงได้รับการ ปรับให้เหมาะสมกับการอ่าน คําสั่ง MERGE INTO หรือ DELETE โดยตรงบนตารางเป้าหมายการแปลงไม่ได้รับการสนับสนุน
- ความพร้อมใช้งานของพื้นที่ทํางาน: พร้อมใช้งานเฉพาะในรายการ Lakehouse (ไม่ใช่คลังข้อมูลหรือฐานข้อมูล KQL)
- ความสอดคล้องของสคีมาไฟล์: ไฟล์ต้องใช้สคีมาที่เหมือนกัน
Note
การเพิ่มการสนับสนุนสําหรับบางส่วนข้างต้นและการลดข้อจํากัดเป็นส่วนหนึ่งของแผนงานของเรา ติดตามการสื่อสารการเผยแพร่ของเราเพื่อรับการอัปเดตเพิ่มเติม
ล้างข้อมูล
เมื่อต้องการหยุดการซิงโครไนซ์ ให้ลบการแปลงทางลัดจาก lakehouse UI
การลบการแปลงไม่ได้เป็นการลบไฟล์พื้นฐาน