รับข้อมูลจาก Amazon S3
ในบทความนี้ คุณจะได้เรียนรู้วิธีการรับข้อมูลจาก Amazon S3 ลงในตารางใหม่หรือตารางที่มีอยู่ Amazon S3 เป็นบริการเก็บข้อมูลวัตถุที่สร้างขึ้นเพื่อจัดเก็บและดึงข้อมูล
สําหรับข้อมูลเพิ่มเติมเกี่ยวกับ Amazon S3 สามารถดู ได้ที่ Amazon S3 คืออะไร
ข้อกำหนดเบื้องต้น
- พื้นที่ทํางานที่มีความจุที่เปิดใช้งาน Microsoft Fabric
- ฐานข้อมูล KQL ที่มีสิทธิ์ในการแก้ไข
- บักเก็ต Amazon S3 พร้อมข้อมูล
แหล่งที่มา
ที่ริบบอนด้านล่างของฐานข้อมูล KQL ให้เลือก รับข้อมูล
ในหน้าต่างรับข้อมูล แท็บแหล่งข้อมูลจะถูกเลือก
เลือกแหล่งข้อมูลจากรายการที่พร้อมใช้งาน ในตัวอย่างนี้ คุณกําลังรวบรวมข้อมูลจาก Amazon S3
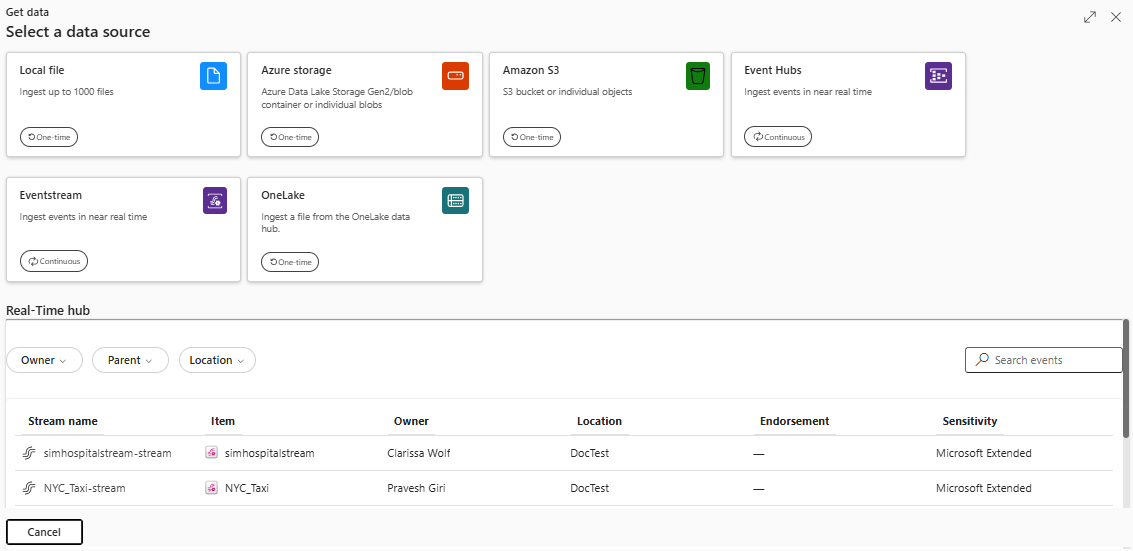

กำหนดค่า
เลือกตารางเป้าหมาย ถ้าคุณต้องการเก็บข้อมูลลงในตารางใหม่ ให้เลือก +ตาราง ใหม่ และป้อนชื่อตาราง
หมายเหตุ
ชื่อตารางสามารถมีได้ถึง 1024 อักขระ รวมถึงช่องว่าง พยัญชนะผสมตัวเลข เครื่องหมายยัติภังค์ และขีดล่าง ไม่รองรับอักขระพิเศษ
ในเขตข้อมูล URI ให้วางสายอักขระการเชื่อมต่อของบักเก็ตเดียวหรือวัตถุแต่ละรายการในรูปแบบต่อไปนี้
บักเก็ต:
https://BucketName.s3.RegionName.amazonaws.com;AwsCredentials=AwsAccessID,AwsSecretKeyอีกทางหนึ่งคือ คุณสามารถใช้ตัวกรองบักเก็ตเพื่อกรองข้อมูลตามนามสกุลไฟล์เฉพาะได้

เลือก ถัดไป

ตรวจ สอบ
แท็บ ตรวจสอบ จะเปิดขึ้นพร้อมกับตัวอย่างของข้อมูล
หากต้องการดําเนินการการนําเข้าให้เสร็จสมบูรณ์ ให้เลือก เสร็จสิ้น

เลือก:
- เลือก ตัว แสดงคําสั่ง เพื่อดูและคัดลอกคําสั่งอัตโนมัติที่สร้างขึ้นจากข้อมูลป้อนเข้าของคุณ
- ใช้ดรอปดาวน์ของ ไฟล์ ข้อกําหนด Schema เพื่อเปลี่ยนไฟล์ที่อนุมาน schema
- เปลี่ยนรูปแบบข้อมูลที่อนุมานโดยอัตโนมัติโดยการเลือกรูปแบบที่ต้องการจากดรอปดาวน์ สําหรับข้อมูลเพิ่มเติม ดูที่รูปแบบข้อมูลที่สนับสนุนโดย Real-Time Intelligence
- แก้ไขคอลัมน์
- สํารวจตัวเลือกขั้นสูงตามชนิดข้อมูล
แก้ไขคอลัมน์
หมายเหตุ
- สําหรับรูปแบบตาราง (CSV, TSV, PSV) คุณไม่สามารถแมปคอลัมน์สองครั้ง เมื่อต้องการแมปไปยังคอลัมน์ที่มีอยู่ ก่อนอื่นให้ลบคอลัมน์ใหม่
- คุณไม่สามารถเปลี่ยนชนิดคอลัมน์ที่มีอยู่ได้ ถ้าคุณพยายามแมปไปยังคอลัมน์ที่มีรูปแบบที่แตกต่างกัน คุณอาจมีคอลัมน์ที่ว่างเปล่า
การเปลี่ยนแปลงที่คุณสามารถทําได้ในตารางขึ้นอยู่กับพารามิเตอร์ต่อไปนี้:
- ชนิดตาราง ใหม่หรือมีอยู่
- ชนิดการแมป ใหม่หรือที่มีอยู่
| ชนิดของตาราง | ชนิดการแมป | การปรับปรุงที่พร้อมใช้งาน |
|---|---|---|
| ตารางใหม่ | การแมปใหม่ | เปลี่ยนชื่อคอลัมน์ เปลี่ยนชนิดข้อมูล เปลี่ยนแหล่งข้อมูล การแมปการแปลง เพิ่มคอลัมน์ ลบคอลัมน์ |
| ตารางที่มีอยู่ | การแมปใหม่ | เพิ่มคอลัมน์ (ซึ่งคุณสามารถเปลี่ยนชนิดข้อมูล เปลี่ยนชื่อ และอัปเดต) |
| ตารางที่มีอยู่ | การแมปที่มีอยู่ | ไม่มี |

การแม็ปการแปลง
การแมปรูปแบบข้อมูลบางอย่าง (Parquet, JSON และ Avro) สนับสนุนการแปลงข้อมูล ingest-time แบบง่าย เมื่อต้องการใช้การแปลงการแมป ให้สร้างหรืออัปเดตคอลัมน์ในหน้าต่าง แก้ไขคอลัมน์
การแปลงข้อมูลการแมปสามารถทําได้ในคอลัมน์ของสตริงชนิดหรือวันที่เวลา ด้วยแหล่งข้อมูลที่มีชนิดข้อมูลเป็น int หรือ long การแปลงการแมปที่สนับสนุนคือ:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
ตัวเลือกขั้นสูงที่ยึดตามชนิดข้อมูล
ตาราง (CSV, TSV, PSV):
ถ้าคุณกําลังจัดเก็บรูปแบบตารางในตารางที่มีอยู่ คุณสามารถเลือกขั้นสูง>เก็บ schema ของตารางได้ ข้อมูลแบบตารางไม่จําเป็นต้องรวมชื่อคอลัมน์ที่ใช้ในการแมปข้อมูลต้นทางไปยังคอลัมน์ที่มีอยู่ เมื่อเลือกตัวเลือกนี้ การแมปจะดําเนินการตามลําดับ และ Schema ของตารางยังคงเหมือนเดิม ถ้าไม่ได้เลือกตัวเลือกนี้ คอลัมน์ใหม่จะถูกสร้างขึ้นสําหรับข้อมูลขาเข้าโดยไม่คํานึงถึงโครงสร้างข้อมูล
หากต้องการใช้แถวแรกเป็นชื่อคอลัมน์ ให้เลือก แถวแรกขั้นสูง>คือส่วนหัวของคอลัมน์

JSON:
หากต้องการกําหนดการแบ่งคอลัมน์ของข้อมูล JSON ให้เลือกระดับที่ซ้อนกันขั้นสูง>จาก 1 ถึง 100
ถ้าคุณเลือกข้ามบรรทัด JSON ขั้นสูง>ที่มีข้อผิดพลาด ข้อมูลจะถูกนําเข้าในรูปแบบ JSON ถ้าคุณยกเลิกการเลือกกล่องกาเครื่องหมายนี้ ระบบจะนําเข้าข้อมูลในรูปแบบ multijson

สรุป
ในหน้าต่างการเตรียมข้อมูล ทั้งสามขั้นตอนจะถูกทําเครื่องหมายด้วยเครื่องหมายถูกสีเขียวเมื่อการนําเข้าข้อมูลเสร็จสิ้นเรียบร้อย คุณสามารถเลือกการ์ดที่จะคิวรี วางข้อมูลนําเข้า หรือดูแดชบอร์ดของสรุปการนําเข้าของคุณได้

เนื้อหาที่เกี่ยวข้อง
- เมื่อต้องการจัดการฐานข้อมูลของคุณ ให้ดู จัดการข้อมูล
- เมื่อต้องการสร้าง จัดเก็บ และส่งออกคิวรี ให้ดู ข้อมูลคิวรีในชุดคิวรี KQL