หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
Apache Kafka เป็นแพลตฟอร์มการสตรีมแบบกระจายสําหรับการสร้างไปป์ไลน์ข้อมูลการสตรีมในเวลาจริงที่ย้ายข้อมูลระหว่างระบบหรือแอปพลิเคชันอย่างเชื่อถือได้ Kafka Connect เป็นเครื่องมือสําหรับการสตรีมข้อมูลที่ปรับขนาดได้และเชื่อถือได้ระหว่าง Apache Kafka กับระบบข้อมูลอื่น ๆ Kusto Kafka Sink ทําหน้าที่เป็นตัวเชื่อมต่อจาก Kafka และไม่จําเป็นต้องใช้รหัส ดาวน์โหลด jar ตัวเชื่อมต่อจมจาก Git repo หรือ ฮับตัวเชื่อมต่อ Confluent
บทความนี้แสดงวิธีการเก็บข้อมูลด้วย Kafka โดยใช้การตั้งค่า Docker แบบติดตั้งในตัวเพื่อลดความซับซ้อนของคลัสเตอร์ Kafka และการตั้งค่าคลัสเตอร์ตัวเชื่อมต่อ Kafka
สําหรับข้อมูลเพิ่มเติม ให้ดูตัวเชื่อมต่อ Git repo และ ข้อมูลจําเพาะของเวอร์ชัน
ข้อกำหนดเบื้องต้น
- การสมัครใช้งาน Azure สร้าง บัญชี Azure ฟรี
- ฐานข้อมูล KQL ใน Microsoft Fabric
- ฐานข้อมูล ingestion URI ของคุณ และ URI คิวรีเพื่อใช้ใน ไฟล์ JSON การกําหนดค่า สําหรับข้อมูลเพิ่มเติม ดูคัดลอก URI
- Azure CLI
- Docker และ Docker Compose
สร้างบริการหลัก Microsoft Entra
บริการหลัก Microsoft Entra สามารถสร้างขึ้นผ่าน พอร์ทัล Azure หรือผ่านโปรแกรมได้ ตามตัวอย่างต่อไปนี้
บริการหลักนี้คือข้อมูลประจําตัวที่ใช้โดยตัวเชื่อมต่อเพื่อเขียนข้อมูลตารางของคุณใน Kusto คุณให้สิทธิ์แก่โครงร่างสําคัญของบริการนี้เพื่อเข้าถึงทรัพยากร Kusto
ลงชื่อเข้าใช้การสมัครใช้งาน Azure ของคุณผ่านทาง Azure CLI จากนั้นรับรองความถูกต้องในเบราว์เซอร์
az loginเลือกการสมัครใช้งานเพื่อโฮสต์โครงร่างสําคัญ ขั้นตอนนี้จําเป็นเมื่อคุณมีการสมัครใช้งานหลายรายการ
az account set --subscription YOUR_SUBSCRIPTION_GUIDสร้างบริการหลัก ในตัวอย่างนี้ โครงร่างสําคัญของบริการเรียกว่า
my-service-principalaz ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}จากข้อมูล JSON ที่ส่งกลับ ให้
appIdpasswordคัดลอก และtenantสําหรับการใช้งานในอนาคต{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
คุณได้สร้างแอปพลิเคชัน Microsoft Entra และบริการหลักของคุณแล้ว
สร้างตารางเป้าหมาย
จากสภาพแวดล้อมคิวรีของคุณ สร้างตารางที่เรียกว่า
Stormsโดยใช้คําสั่งต่อไปนี้:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)สร้างการแมป
Storms_CSV_Mappingตารางที่สอดคล้องกันสําหรับข้อมูลที่นําเข้าโดยใช้คําสั่งต่อไปนี้:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'สร้างนโยบายการรวมกลุ่มข้อมูลบนตาราง สําหรับเวลาแฝงในการนําเข้าที่อยู่ในคิวที่สามารถกําหนดค่าได้
เคล็ดลับ
นโยบายการรวมกลุ่มเป็นตัวปรับประสิทธิภาพการทํางานให้เหมาะสมและมีสามพารามิเตอร์ เงื่อนไขแรกที่พอใจจะทริกเกอร์การนําเข้าลงในตาราง
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'ใช้โครงร่างสําคัญของบริการจาก สร้างบริการหลัก Microsoft Entra เพื่อให้สิทธิ์ในการทํางานกับฐานข้อมูล
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
เรียกใช้แล็บ
แล็บต่อไปนี้ออกแบบมาเพื่อมอบประสบการณ์การเริ่มต้นสร้างข้อมูล การตั้งค่าตัวเชื่อมต่อ Kafka และการสตรีมข้อมูลนี้ จากนั้นคุณสามารถดูข้อมูลที่นําเข้าได้
ลอกแบบ git repo
โคลน git repo ของแล็บ
สร้างไดเรกทอรีภายในเครื่องของคุณ
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holลอกแบบ repo
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
เนื้อหาของ repo ที่ถูกลอกแบบ
เรียกใช้คําสั่งต่อไปนี้เพื่อแสดงรายการเนื้อหาของ repo ที่ถูกโคลน:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
ผลลัพธ์ของการค้นหานี้คือ:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
ตรวจทานไฟล์ใน repo ที่ถูกโคลน
ส่วนต่อไปนี้อธิบายส่วนสําคัญของไฟล์ในทรีไฟล์ด้านบน
adx-sink-config.json
ไฟล์นี้ประกอบด้วยไฟล์คุณสมบัติจม Kusto ที่คุณจะอัปเดตรายละเอียดการกําหนดค่าเฉพาะ:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "<ingestion URI per prerequisites>",
"kusto.query.url": "<query URI per prerequisites>",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
แทนที่ค่าสําหรับแอททริบิวต์ต่อไปนี้ตามการตั้งค่าของคุณ: aad.auth.authority, aad.auth.appid, aad.auth.appkey, kusto.tables.topics.mapping (ชื่อฐานข้อมูล) และ kusto.ingestion.urlkusto.query.url
ตัวเชื่อมต่อ - Dockerfile
ไฟล์นี้มีคําสั่งเพื่อสร้างรูปภาพ docker สําหรับอินสแตนซ์ของตัวเชื่อมต่อ ซึ่งรวมถึงการดาวน์โหลดตัวเชื่อมต่อจากไดเรกทอรีการเผยแพร่ git repo
ไดเรกทอรี Storm-events-producer
ไดเรกทอรีนี้มีโปรแกรม Go ที่อ่านไฟล์ "StormEvents.csv" ภายในเครื่องและเผยแพร่ข้อมูลไปยังหัวข้อ Kafka
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
เริ่มคอนเทนเนอร์
ในเทอร์มินัล ให้เริ่มคอนเทนเนอร์:
docker-compose upแอปพลิเคชันผู้ผลิตเริ่มต้นส่งเหตุการณ์ไปยัง
storm-eventsหัวข้อ คุณควรเห็นรายการบันทึกที่คล้ายกับบันทึกต่อไปนี้:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....หากต้องการตรวจสอบรายการบันทึก ให้เรียกใช้คําสั่งต่อไปนี้ในเทอร์มินัลแยกต่างหาก:
docker-compose logs -f | grep kusto-connect
เริ่มตัวเชื่อมต่อ
ใช้ Kafka Connect REST call เพื่อเริ่มตัวเชื่อมต่อ
ในเทอร์มินัลแยกต่างหาก ให้เรียกใช้งานจมด้วยคําสั่งต่อไปนี้:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsเมื่อต้องการตรวจสอบสถานะ ให้เรียกใช้คําสั่งต่อไปนี้ในเทอร์มินัลแยกต่างหาก:
curl http://localhost:8083/connectors/storm/status
ตัวเชื่อมต่อเริ่มต้นกระบวนการส่งเข้าคิว
หมายเหตุ
ถ้าคุณมีปัญหาตัวเชื่อมต่อรายการบันทึก ให้สร้างปัญหา
สอบถามและตรวจทานข้อมูล
ยืนยันการนําเข้าข้อมูล
เมื่อข้อมูลเข้ามาในตาราง
Stormsแล้ว ให้ยืนยันการถ่ายโอนข้อมูลโดยตรวจสอบจํานวนแถว:Storms | countยืนยันว่าไม่มีความล้มเหลวในกระบวนการการนําเข้าข้อมูล:
.show ingestion failuresเมื่อคุณเห็นข้อมูล ให้ลองคิวรีสองถึงสามรายการ
คิวรีข้อมูล
เมื่อต้องการดูระเบียนทั้งหมด ให้เรียกใช้คิวรีต่อไปนี้:
Storms | take 10ใช้
whereและprojectเพื่อกรองข้อมูลที่ระบุ:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdใช้ตัว
summarizeดําเนินการ:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart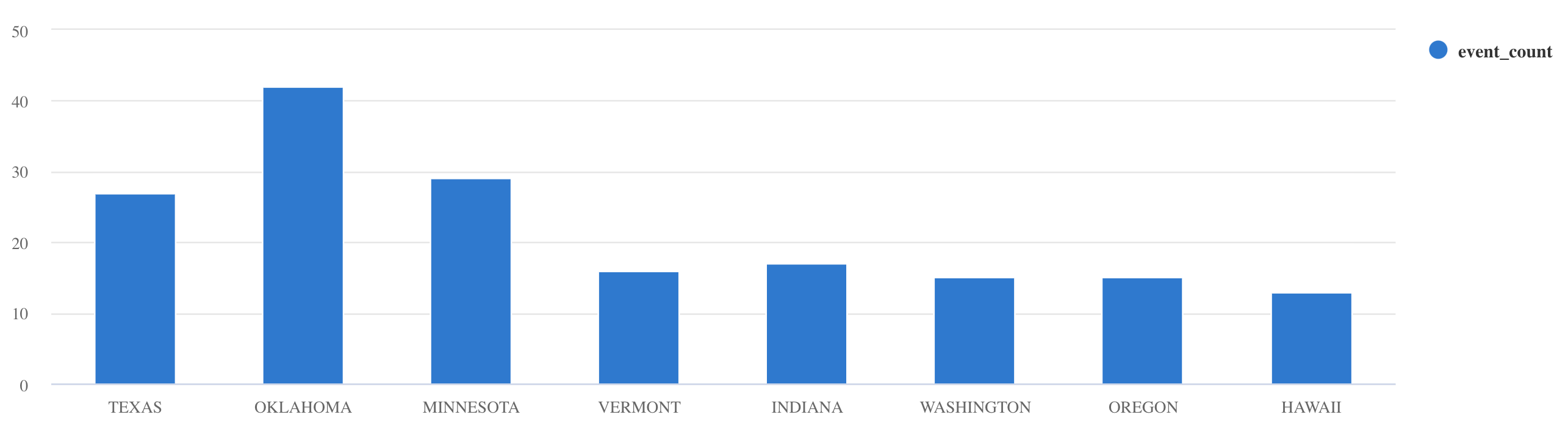
สําหรับตัวอย่างและคําแนะนําคิวรีเพิ่มเติม โปรดดูที่เอกสารเขียนคิวรีใน KQL และ Kusto Query Language
Reset
เมื่อต้องการรีเซ็ต ให้ทําตามขั้นตอนต่อไปนี้:
- หยุดคอนเทนเนอร์ (
docker-compose down -v) - ลบ (
drop table Storms) - สร้าง
Stormsตารางใหม่ - สร้างการแมปตารางใหม่
- รีสตาร์ตคอนเทนเนอร์ (
docker-compose up)
ล้างแหล่งข้อมูล
ล้างรายการที่สร้างขึ้นโดยการนําทางไปยังพื้นที่ทํางานที่สร้างขึ้น
ในพื้นที่ทํางานของคุณ ให้วางเมาส์เหนือฐานข้อมูลของคุณและเลือกเมนู เพิ่มเติม [...] > ลบ
เลือก ลบ คุณไม่สามารถกู้คืนรายการที่ถูกลบได้
การปรับแต่งตัวเชื่อมต่อ Kafka Sink
ปรับแต่งตัว เชื่อมต่อ Kafka Sink ให้ทํางานกับ นโยบายการรวมกลุ่ม:
- ปรับแต่งขีดจํากัดขนาดอ่างล้างหน้า
flush.size.bytesของ Kafka เริ่มต้นจาก 1 MB โดยเพิ่มหน่วยครั้งละ 10 MB หรือ 100 MB - เมื่อใช้ Kafka Sink ข้อมูลจะถูกรวมสองครั้ง ในข้อมูลด้านตัวเชื่อมต่อจะรวมตามการตั้งค่าการล้างข้อมูลและในด้านบริการตามนโยบายการชุดงาน ถ้าเวลาในการชุดงานสั้นเกินไป ดังนั้นเวลาในการชุดงานจะไม่สามารถรวบรวมข้อมูลได้โดยทั้งตัวเชื่อมต่อและบริการ ตั้งค่าขนาดชุดงานที่ 1 GB และเพิ่มหรือลดลงโดยเพิ่มทีละ 100 MB ตามความจําเป็น ตัวอย่างเช่น ถ้าขนาดการล้างข้อมูลคือ 1 MB และขนาดนโยบายการทําชุดงานคือ 100 MB ตัวเชื่อมต่อ Kafka Sink จะรวมข้อมูลเป็นชุดขนาด 100 MB จากนั้น ชุดงานจะส่งผ่านโดยบริการ ถ้าเวลานโยบายชุดงานคือ 20 วินาที และตัวเชื่อมต่อ Kafka Sink แสดง 50 MB ในช่วงเวลา 20 วินาที จากนั้นบริการจะนําเข้าชุดขนาด 50 MB
- คุณสามารถปรับมาตราส่วนได้โดยการเพิ่มอินสแตนซ์และ พาร์ติชัน Kafka เพิ่ม
tasks.maxเป็นจํานวนพาร์ติชัน สร้างพาร์ติชันถ้าคุณมีข้อมูลเพียงพอที่จะสร้าง blob ขนาดของflush.size.bytesการตั้งค่า ถ้า blob มีขนาดเล็กกว่า ชุดงานจะถูกประมวลผลเมื่อถึงขีดจํากัดเวลา ดังนั้นพาร์ติชันจึงไม่ได้รับอัตราความเร็วเพียงพอ จํานวนพาร์ติชันที่มีขนาดใหญ่หมายถึงค่าใช้จ่ายในการประมวลผลเพิ่มเติม