Tune Azure Data Lake Storage Gen1 for performance
Data Lake Storage Gen1 supports high-throughput for I/O intensive analytics and data movement. In Data Lake Storage Gen1, using all available throughput – the amount of data that can be read or written per second – is important to get the best performance. This is achieved by performing as many reads and writes in parallel as possible.

Data Lake Storage Gen1 can scale to provide the necessary throughput for all analytics scenario. By default, a Data Lake Storage Gen1 account provides automatically enough throughput to meet the needs of a broad category of use cases. For the cases where customers run into the default limit, the Data Lake Storage Gen1 account can be configured to provide more throughput by contacting Microsoft support.
Data ingestion
When ingesting data from a source system to Data Lake Storage Gen1, it's important to consider that the source hardware, source network hardware, and network connectivity to Data Lake Storage Gen1 can be the bottleneck.

It's important to ensure that the data movement is not affected by these factors.
Source hardware
Whether you're using on-premises machines or VMs in Azure, you should carefully select the appropriate hardware. For Source Disk Hardware, prefer SSDs to HDDs and pick disk hardware with faster spindles. For Source Network Hardware, use the fastest NICs possible. On Azure, we recommend Azure D14 VMs that have the appropriately powerful disk and networking hardware.
Network connectivity to Data Lake Storage Gen1
The network connectivity between your source data and Data Lake Storage Gen1 can sometimes be the bottleneck. When your source data is On-Premises, consider using a dedicated link with Azure ExpressRoute . If your source data is in Azure, the performance will be best when the data is in the same Azure region as the Data Lake Storage Gen1 account.
Configure data ingestion tools for maximum parallelization
After you've addressed the source hardware and network connectivity bottlenecks, you're ready to configure your ingestion tools. The following table summarizes the key settings for several popular ingestion tools and provides in-depth performance tuning articles for them. To learn more about which tool to use for your scenario, visit this article.
| Tool | Settings | More Details |
|---|---|---|
| PowerShell | PerFileThreadCount, ConcurrentFileCount | Link |
| AdlCopy | Azure Data Lake Analytics units | Link |
| DistCp | -m (mapper) | Link |
| Azure Data Factory | parallelCopies | Link |
| Sqoop | fs.azure.block.size, -m (mapper) | Link |
Structure your data set
When data is stored in Data Lake Storage Gen1, the file size, number of files, and folder structure affect performance. The following section describes best practices in these areas.
File size
Typically, analytics engines such as HDInsight and Azure Data Lake Analytics have a per-file overhead. If you store your data as many small files, this can negatively affect performance.
In general, organize your data into larger sized files for better performance. As a rule of thumb, organize data sets in files of 256 MB or larger. In some cases such as images and binary data, it is not possible to process them in parallel. In these cases, it is recommended to keep individual files under 2 GB.
Sometimes, data pipelines have limited control over the raw data that has lots of small files. It is recommended to have a "cooking" process that generates larger files to use for downstream applications.
Organize time-series data in folders
For Hive and ADLA workloads, partition pruning of time-series data can help some queries read only a subset of the data, which improves performance.
Those pipelines that ingest time-series data, often place their files with a structured naming for files and folders. The following is a common example we see for data that is structured by date: \DataSet\YYYY\MM\DD\datafile_YYYY_MM_DD.tsv.
Notice that the datetime information appears both as folders and in the filename.
For date and time, the following is a common pattern: \DataSet\YYYY\MM\DD\HH\mm\datafile_YYYY_MM_DD_HH_mm.tsv.
Again, the choice you make with the folder and file organization should optimize for the larger file sizes and a reasonable number of files in each folder.
Optimize I/O intensive jobs on Hadoop and Spark workloads on HDInsight
Jobs fall into one of the following three categories:
- CPU intensive. These jobs have long computation times with minimal I/O times. Examples include machine learning and natural language processing jobs.
- Memory intensive. These jobs use lots of memory. Examples include PageRank and real-time analytics jobs.
- I/O intensive. These jobs spend most of their time doing I/O. A common example is a copy job that does only read and write operations. Other examples include data preparation jobs that read numerous data, performs some data transformation, and then writes the data back to the store.
The following guidance is only applicable to I/O intensive jobs.
General considerations for an HDInsight cluster
- HDInsight versions. For best performance, use the latest release of HDInsight.
- Regions. Place the Data Lake Storage Gen1 account in the same region as the HDInsight cluster.
An HDInsight cluster is composed of two head nodes and some worker nodes. Each worker node provides a specific number of cores and memory, which is determined by the VM-type. When running a job, YARN is the resource negotiator that allocates the available memory and cores to create containers. Each container runs the tasks needed to complete the job. Containers run in parallel to process tasks quickly. Therefore, performance is improved by running as many parallel containers as possible.
There are three layers within an HDInsight cluster that can be tuned to increase the number of containers and use all available throughput.
- Physical layer
- YARN layer
- Workload layer
Physical layer
Run cluster with more nodes and/or larger sized VMs. A larger cluster will enable you to run more YARN containers as shown in the picture below.

Use VMs with more network bandwidth. The amount of network bandwidth can be a bottleneck if there is less network bandwidth than Data Lake Storage Gen1 throughput. Different VMs will have varying network bandwidth sizes. Choose a VM-type that has the largest possible network bandwidth.
YARN layer
Use smaller YARN containers. Reduce the size of each YARN container to create more containers with the same amount of resources.

Depending on your workload, there will always be a minimum YARN container size that is needed. If you pick too small a container, your jobs will run into out-of-memory issues. Typically YARN containers should be no smaller than 1 GB. It's common to see 3 GB YARN containers. For some workloads, you may need larger YARN containers.
Increase cores per YARN container. Increase the number of cores allocated to each container to increase the number of parallel tasks that run in each container. This works for applications like Spark, which run multiple tasks per container. For applications like Hive that run a single thread in each container, it's better to have more containers rather than more cores per container.
Workload layer
Use all available containers. Set the number of tasks to be equal or larger than the number of available containers so that all resources are used.
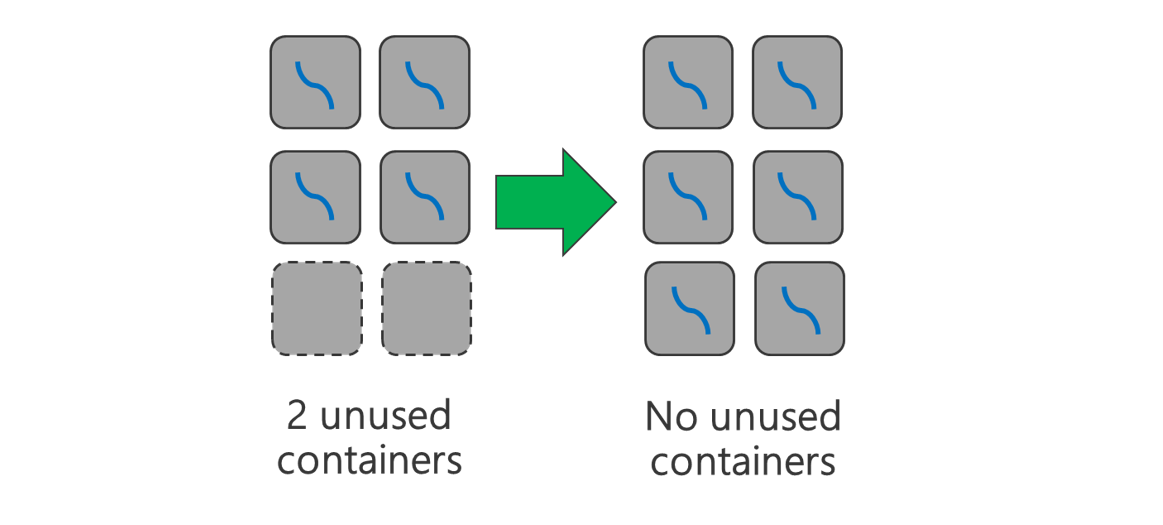
Failed tasks are costly. If each task has a large amount of data to process, then failure of a task results in an expensive retry. Therefore, it's better to create more tasks, each of which processes a small amount of data.
In addition to the general guidelines above, each application has different parameters available to tune for that specific application. The table below lists some of the parameters and links to get started with performance tuning for each application.
| Workload | Parameter to set tasks |
|---|---|
| Spark on HDInsight |
|
| Hive on HDInsight |
|
| MapReduce on HDInsight |
|
| Storm on HDInsight |
|