Tutorial 2: Train credit risk models - Machine Learning Studio (classic)
APPLIES TO:  Machine Learning Studio (classic)
Machine Learning Studio (classic)  Azure Machine Learning
Azure Machine Learning
Important
Support for Machine Learning Studio (classic) will end on 31 August 2024. We recommend you transition to Azure Machine Learning by that date.
Beginning 1 December 2021, you will not be able to create new Machine Learning Studio (classic) resources. Through 31 August 2024, you can continue to use the existing Machine Learning Studio (classic) resources.
- See information on moving machine learning projects from ML Studio (classic) to Azure Machine Learning.
- Learn more about Azure Machine Learning
ML Studio (classic) documentation is being retired and may not be updated in the future.
In this tutorial, you take an extended look at the process of developing a predictive analytics solution. You develop a simple model in Machine Learning Studio (classic). You then deploy the model as a Machine Learning web service. This deployed model can make predictions using new data. This tutorial is part two of a three-part tutorial series.
Suppose you need to predict an individual's credit risk based on the information they gave on a credit application.
Credit risk assessment is a complex problem, but this tutorial will simplify it a bit. You'll use it as an example of how you can create a predictive analytics solution using Machine Learning Studio (classic). You'll use Machine Learning Studio (classic) and a Machine Learning web service for this solution.
In this three-part tutorial, you start with publicly available credit risk data. You then develop and train a predictive model. Finally you deploy the model as a web service.
In part one of the tutorial, you created a Machine Learning Studio (classic) workspace, uploaded data, and created an experiment.
In this part of the tutorial you:
- Train multiple models
- Score and evaluate the models
In part three of the tutorial, you'll deploy the model as a web service.
Prerequisites
Complete part one of the tutorial.
Train multiple models
One of the benefits of using Machine Learning Studio (classic) for creating machine learning models is the ability to try more than one type of model at a time in a single experiment and compare the results. This type of experimentation helps you find the best solution for your problem.
In the experiment we're developing in this tutorial, you'll create two different types of models and then compare their scoring results to decide which algorithm you want to use in our final experiment.
There are various models you could choose from. To see the models available, expand the Machine Learning node in the module palette, and then expand Initialize Model and the nodes beneath it. For the purposes of this experiment, you'll select the Two-Class Support Vector Machine (SVM) and the Two-Class Boosted Decision Tree modules.
You'll add both the Two-Class Boosted Decision Tree module and Two-Class Support Vector Machine module in this experiment.
Two-Class Boosted Decision Tree
First, set up the boosted decision tree model.
Find the Two-Class Boosted Decision Tree module in the module palette and drag it onto the canvas.
Find the Train Model module, drag it onto the canvas, and then connect the output of the Two-Class Boosted Decision Tree module to the left input port of the Train Model module.
The Two-Class Boosted Decision Tree module initializes the generic model, and Train Model uses training data to train the model.
Connect the left output of the left Execute R Script module to the right input port of the Train Model module (in this tutorial you used the data coming from the left side of the Split Data module for training).
Tip
you don't need two of the inputs and one of the outputs of the Execute R Script module for this experiment, so you can leave them unattached.
This portion of the experiment now looks something like this:
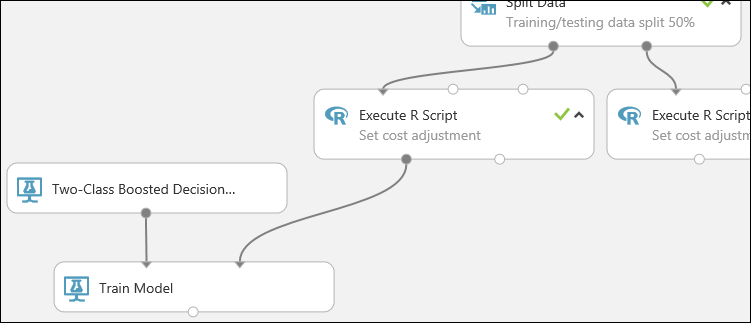
Now you need to tell the Train Model module that you want the model to predict the Credit Risk value.
Select the Train Model module. In the Properties pane, click Launch column selector.
In the Select a single column dialog, type "credit risk" in the search field under Available Columns, select "Credit risk" below, and click the right arrow button (>) to move "Credit risk" to Selected Columns.
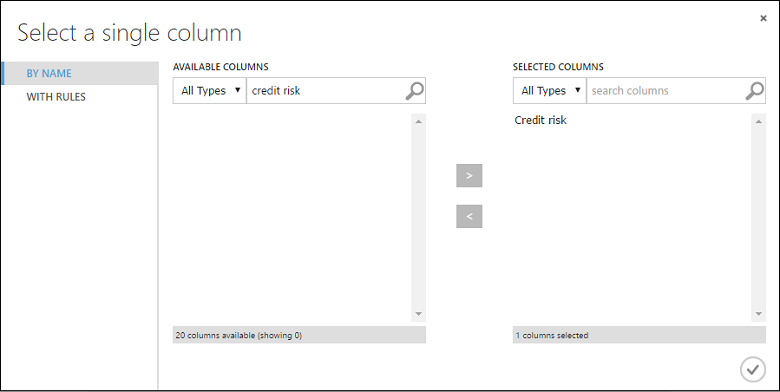
Click the OK check mark.
Two-Class Support Vector Machine
Next, you set up the SVM model.
First, a little explanation about SVM. Boosted decision trees work well with features of any type. However, since the SVM module generates a linear classifier, the model that it generates has the best test error when all numeric features have the same scale. To convert all numeric features to the same scale, you use a "Tanh" transformation (with the Normalize Data module). This transforms our numbers into the [0,1] range. The SVM module converts string features to categorical features and then to binary 0/1 features, so you don't need to manually transform string features. Also, you don't want to transform the Credit Risk column (column 21) - it's numeric, but it's the value we're training the model to predict, so you need to leave it alone.
To set up the SVM model, do the following:
Find the Two-Class Support Vector Machine module in the module palette and drag it onto the canvas.
Right-click the Train Model module, select Copy, and then right-click the canvas and select Paste. The copy of the Train Model module has the same column selection as the original.
Connect the output of the Two-Class Support Vector Machine module to the left input port of the second Train Model module.
Find the Normalize Data module and drag it onto the canvas.
Connect the left output of the left Execute R Script module to the input of this module (notice that the output port of a module may be connected to more than one other module).
Connect the left output port of the Normalize Data module to the right input port of the second Train Model module.
This portion of our experiment should now look something like this:
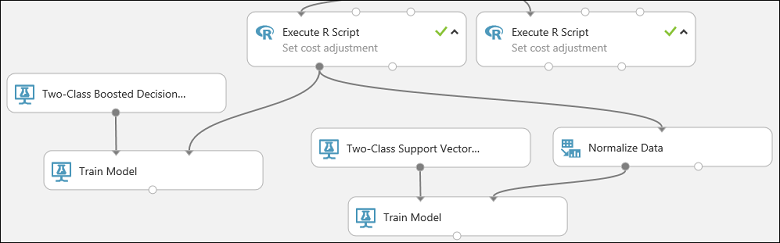
Now configure the Normalize Data module:
Click to select the Normalize Data module. In the Properties pane, select Tanh for the Transformation method parameter.
Click Launch column selector, select "No columns" for Begin With, select Include in the first dropdown, select column type in the second dropdown, and select Numeric in the third dropdown. This specifies that all the numeric columns (and only numeric) are transformed.
Click the plus sign (+) to the right of this row - this creates a row of dropdowns. Select Exclude in the first dropdown, select column names in the second dropdown, and enter "Credit risk" in the text field. This specifies that the Credit Risk column should be ignored (you need to do this because this column is numeric and so would be transformed if you didn't exclude it).
Click the OK check mark.
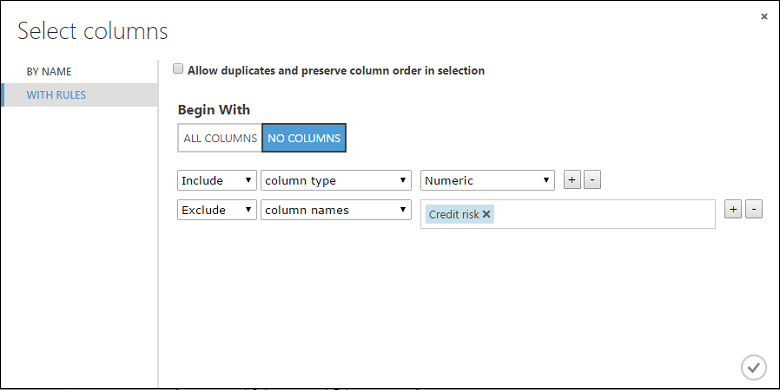
The Normalize Data module is now set to perform a Tanh transformation on all numeric columns except for the Credit Risk column.
Score and evaluate the models
you use the testing data that was separated out by the Split Data module to score our trained models. you can then compare the results of the two models to see which generated better results.
Add the Score Model modules
Find the Score Model module and drag it onto the canvas.
Connect the Train Model module that's connected to the Two-Class Boosted Decision Tree module to the left input port of the Score Model module.
Connect the right Execute R Script module (our testing data) to the right input port of the Score Model module.
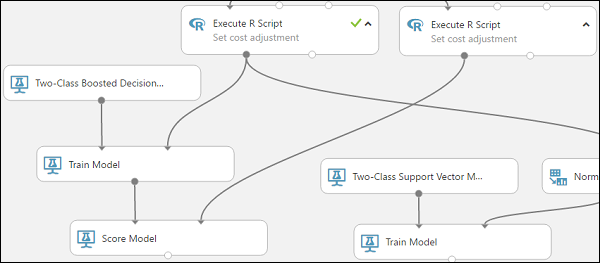
The Score Model module can now take the credit information from the testing data, run it through the model, and compare the predictions the model generates with the actual credit risk column in the testing data.
Copy and paste the Score Model module to create a second copy.
Connect the output of the SVM model (that is, the output port of the Train Model module that's connected to the Two-Class Support Vector Machine module) to the input port of the second Score Model module.
For the SVM model, you have to do the same transformation to the test data as you did to the training data. So copy and paste the Normalize Data module to create a second copy and connect it to the right Execute R Script module.
Connect the left output of the second Normalize Data module to the right input port of the second Score Model module.
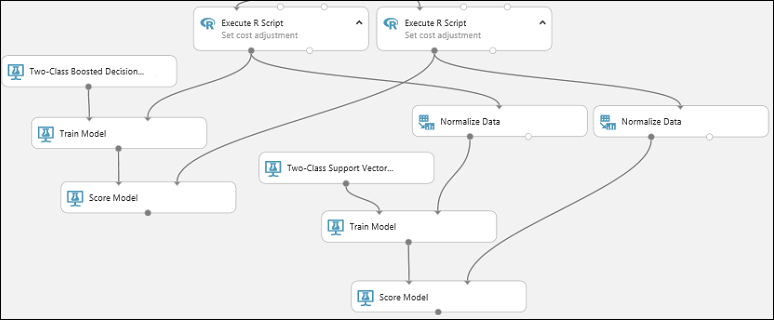
Add the Evaluate Model module
To evaluate the two scoring results and compare them, you use an Evaluate Model module.
Find the Evaluate Model module and drag it onto the canvas.
Connect the output port of the Score Model module associated with the boosted decision tree model to the left input port of the Evaluate Model module.
Connect the other Score Model module to the right input port.
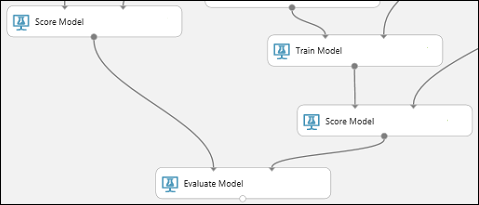
Run the experiment and check the results
To run the experiment, click the RUN button below the canvas. It may take a few minutes. A spinning indicator on each module shows that it's running, and then a green check mark shows when the module is finished. When all the modules have a check mark, the experiment has finished running.
The experiment should now look something like this:
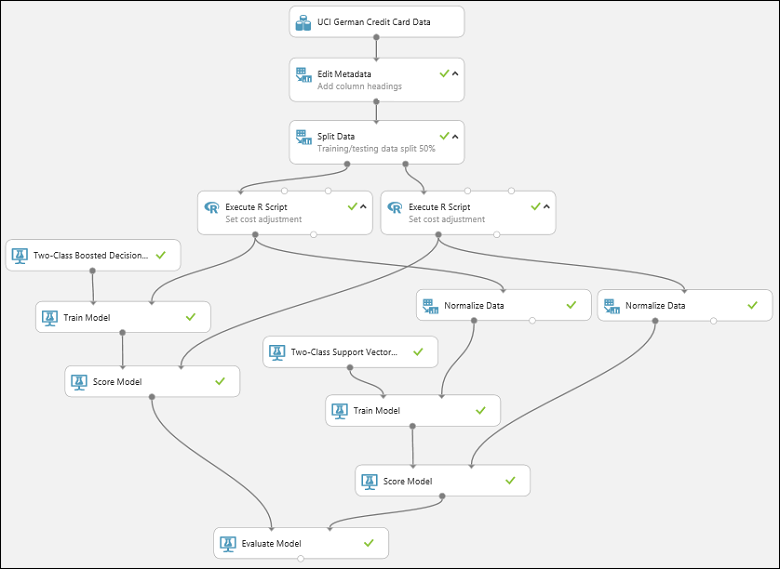
To check the results, click the output port of the Evaluate Model module and select Visualize.
The Evaluate Model module produces a pair of curves and metrics that allow you to compare the results of the two scored models. You can view the results as Receiver Operator Characteristic (ROC) curves, Precision/Recall curves, or Lift curves. Additional data displayed includes a confusion matrix, cumulative values for the area under the curve (AUC), and other metrics. You can change the threshold value by moving the slider left or right and see how it affects the set of metrics.
To the right of the graph, click Scored dataset or Scored dataset to compare to highlight the associated curve and to display the associated metrics below. In the legend for the curves, "Scored dataset" corresponds to the left input port of the Evaluate Model module - in our case, this is the boosted decision tree model. "Scored dataset to compare" corresponds to the right input port - the SVM model in our case. When you click one of these labels, the curve for that model is highlighted and the corresponding metrics are displayed, as shown in the following graphic.
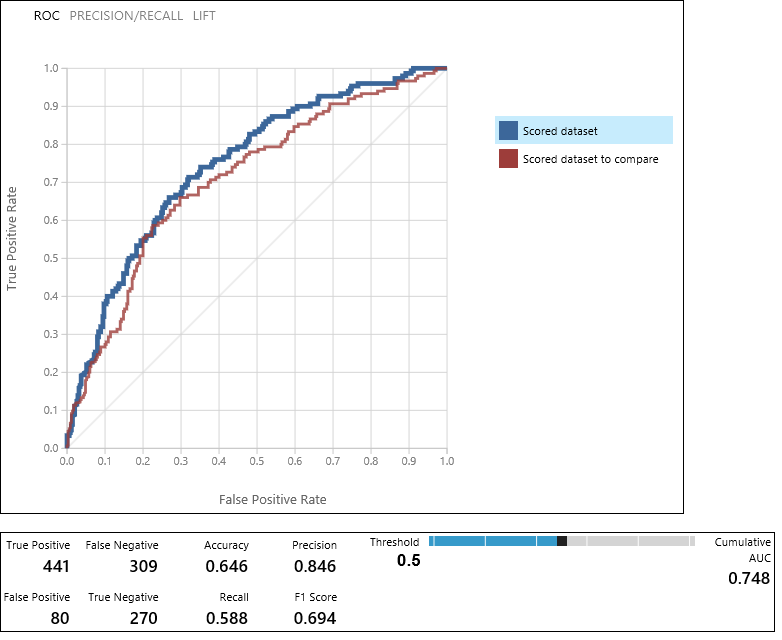
By examining these values, you can decide which model is closest to giving you the results you're looking for. You can go back and iterate on your experiment by changing parameter values in the different models.
The science and art of interpreting these results and tuning the model performance is outside the scope of this tutorial. For additional help, you might read the following articles:
- How to evaluate model performance in Machine Learning Studio (classic)
- Choose parameters to optimize your algorithms in Machine Learning Studio (classic)
- Interpret model results in Machine Learning Studio (classic)
Tip
Each time you run the experiment a record of that iteration is kept in the Run History. You can view these iterations, and return to any of them, by clicking VIEW RUN HISTORY below the canvas. You can also click Prior Run in the Properties pane to return to the iteration immediately preceding the one you have open.
You can make a copy of any iteration of your experiment by clicking SAVE AS below the canvas. Use the experiment's Summary and Description properties to keep a record of what you've tried in your experiment iterations.
For more information, see Manage experiment iterations in Machine Learning Studio (classic).
Clean up resources
If you no longer need the resources you created using this article, delete them to avoid incurring any charges. Learn how in the article, Export and delete in-product user data.
Next steps
In this tutorial, you completed these steps:
- Create an experiment
- Train multiple models
- Score and evaluate the models
You're now ready to deploy models for this data.