StorSimple 8100 and 8600 migration to Azure File Sync
The StorSimple 8000 series includes either the 8100 or the 8600 physical, on-premises appliances and their cloud service components. StorSimple 8010 and 8020 virtual appliances are also covered in this migration guide. It's possible to migrate the data from either of these appliances to Azure file shares with optional Azure File Sync. Azure File Sync is the default and strategic long-term Azure service that replaces the StorSimple on-premises functionality. This article provides the necessary background knowledge and migration steps for a successful migration to Azure File Sync.
Note
The StorSimple Service (including the StorSimple Device Manager for 8000 and 1200 series and StorSimple Data Manager) has reached the end of support. The end of support for StorSimple was published in 2019 on the Microsoft LifeCycle Policy and Azure Communications pages. Additional notifications were sent via email and posted on the Azure portal and in the StorSimple overview. Contact Microsoft Support for additional details.

This video provides an overview of:
- Azure Files
- Azure File Sync
- Comparison of StorSimple & Azure Files
- StorSimple Data Manager migration tool and process overview
Phase 1: Prepare for migration
This section contains the steps you should take at the beginning of your migration from StorSimple volumes to Azure file shares.

This video covers:
- Selecting storage tier
- Selecting storage redundancy options
- Selecting direct-share-access vs. Azure File Sync
- StorSimple Service Data Encryption Key and Serial Number
- StorSimple Volume Backup migration
- Mapping StorSimple volumes and shares to Azure file shares
- Grouping shares inside Azure file shares
- Mapping considerations
- Migration planning worksheet
- Namespace mapping spreadsheet
Inventory
When you begin planning your migration, first identify all the StorSimple appliances and volumes you need to migrate. Afterwards, you can decide on the best migration path.
- StorSimple physical appliances (8000 series) use this migration guide.
- StorSimple virtual appliances (1200 series) use a different migration guide.
Migration cost summary
Migrations to Azure file shares from StorSimple volumes via migration jobs in a StorSimple Data Manager resource are free of charge. Other costs might be incurred during and after a migration:
- Network egress: Your StorSimple files live in a storage account within a specific Azure region. If you provision the Azure file shares you migrate into a storage account in the same Azure region, no egress costs occur. However, if you move your files to a storage account in a different region as part of this migration, egress costs will apply.
- Azure file share transactions: When files are copied into an Azure file share (as part of a migration or outside of one), transaction costs apply as files and metadata are being written. As a best practice, start your Azure file share on the transaction optimized tier during the migration. Switch to your desired tier after the migration is finished. The phases described in this article call this out at the appropriate point.
- Change an Azure file share tier: Changing the tier of an Azure file share costs transactions. In most cases, it is more cost efficient to follow the advice from the previous point.
- Storage cost: When this migration starts copying files into an Azure file share, storage is consumed and billed. Migrated backups become Azure file share snapshots. File share snapshots only consume storage capacity for the differences they contain.
- StorSimple: Until you deprovision the StorSimple devices and storage accounts, StorSimple cost for storage, backups, and appliances will continue to occur.
Direct-share-access vs. Azure File Sync
Azure file shares open up a new world of opportunities for structuring your file services deployment. An Azure file share is an SMB share in the cloud that you can set up to have users access directly over the SMB protocol with the familiar Kerberos authentication and existing NTFS permissions (file and folder ACLs) working natively. Learn more about identity-based access to Azure file shares.
An alternative to direct access is Azure File Sync. Azure File Sync is a direct analog for StorSimple's ability to cache frequently used files on-premises.
Azure File Sync is a Microsoft cloud service, based on two main components:
- File synchronization and cloud tiering to create a performance access cache on any Windows Server.
- File shares as native storage in Azure that can be accessed over multiple protocols like SMB and file REST.
Azure file shares retain important file fidelity aspects like attributes, permissions, and timestamps. With Azure file shares, there's no longer a need for an application or service to interpret the files and folders stored in the cloud. You can access them natively over familiar protocols and clients. Azure file shares allow you to store general-purpose file server data and application data in the cloud.
This article focuses on the migration steps. If you want to learn more about Azure File Sync before migrating, see the following articles:
StorSimple service data encryption key
When you first set up your StorSimple appliance, it generated a service data encryption key and instructed you to securely store the key. This key is used to encrypt all data in the associated Azure storage account where the StorSimple appliance stores your files.
The service data encryption key is necessary for a successful migration. Retrieve this key from your records, one for each of the appliances in your inventory.
If you can't find the keys in your records, you can generate a new key from the appliance. Each appliance has a unique encryption key.
Change the service data encryption key
Service data encryption keys are used to encrypt confidential customer data, such as storage account credentials, that are sent from your StorSimple Manager service to the StorSimple device. You will need to change these keys periodically if your IT organization has a key rotation policy on the storage devices. The key change process can be slightly different depending on whether there is a single device or multiple devices managed by the StorSimple Manager service. For more information, go to StorSimple security and data protection.
Changing the service data encryption key is a 3-step process:
- Using Windows PowerShell scripts for Azure Resource Manager, authorize a device to change the service data encryption key.
- Using Windows PowerShell for StorSimple, initiate the service data encryption key change.
- If you have more than one StorSimple device, update the service data encryption key on the other devices.
Step 1: Use Windows PowerShell script to Authorize a device to change the service data encryption key
Typically, the device administrator will request that the service administrator authorize a device to change service data encryption keys. The service administrator will then authorize the device to change the key.
This step is performed using the Azure Resource Manager based script. The service administrator can select a device that is eligible to be authorized. The device is then authorized to start the service data encryption key change process.
For more information about using the script, go to Authorize-ServiceEncryptionRollover.ps1
Which devices can be authorized to change service data encryption keys?
A device must meet the following criteria before it can be authorized to initiate service data encryption key changes:
- The device must be online to be eligible for service data encryption key change authorization.
- You can authorize the same device again after 30 minutes if the key change has not been initiated.
- You can authorize a different device, provided that the key change has not been initiated by the previously authorized device. After the new device has been authorized, the old device cannot initiate the change.
- You cannot authorize a device while the rollover of the service data encryption key is in progress.
- You can authorize a device when some of the devices registered with the service have rolled over the encryption while others have not.
Step 2: Use Windows PowerShell for StorSimple to initiate the service data encryption key change
This step is performed in the Windows PowerShell for StorSimple interface on the authorized StorSimple device.
Note
No operations can be performed in the Azure portal of your StorSimple Manager service until the key rollover is completed.
If you are using the device serial console to connect to the Windows PowerShell interface, perform the following steps.
To initiate the service data encryption key change
Select option 1 to log on with full access.
At the command prompt, type:
Invoke-HcsmServiceDataEncryptionKeyChangeAfter the cmdlet has successfully completed, you will get a new service data encryption key. Copy and save this key for use in step 3 of this process. This key will be used to update all the remaining devices registered with the StorSimple Manager service.
Note
This process must be initiated within four hours of authorizing a StorSimple device.
This new key is then sent to the service to be pushed to all the devices that are registered with the service. An alert will then appear on the service dashboard. The service will disable all the operations on the registered devices, and the device administrator will then need to update the service data encryption key on the other devices. However, the I/Os (hosts sending data to the cloud) will not be disrupted.
If you have a single device registered to your service, the rollover process is now complete and you can skip the next step. If you have multiple devices registered to your service, proceed to step 3.
Step 3: Update the service data encryption key on other StorSimple devices
These steps must be performed in the Windows PowerShell interface of your StorSimple device if you have multiple devices registered to your StorSimple Manager service. The key that you obtained in Step 2 must be used to update all the remaining StorSimple device registered with the StorSimple Manager service.
Perform the following steps to update the service data encryption on your device.
To update the service data encryption key on physical devices
- Use Windows PowerShell for StorSimple to connect to the console. Select option 1 to log on with full access.
- At the command prompt, type:
Invoke-HcsmServiceDataEncryptionKeyChange – ServiceDataEncryptionKey - Provide the service data encryption key that you obtained in Step 2: Use Windows PowerShell for StorSimple to initiate the service data encryption key change.
To update the service data encryption key on all the 8010/8020 cloud appliances
- Download and setup Update-CloudApplianceServiceEncryptionKey.ps1 PowerShell script.
- Open PowerShell and at the command prompt, type:
Update-CloudApplianceServiceEncryptionKey.ps1 -SubscriptionId [subscription] -TenantId [tenantid] -ResourceGroupName [resource group] -ManagerName [device manager]
This script will ensure that service data encryption key is set on all the 8010/8020 cloud appliances under the device manager.
Caution
When you're deciding how to connect to your StorSimple appliance, consider the following:
- Connecting through an HTTPS session is the most secure and recommended option.
- Connecting directly to the device serial console is secure, but connecting to the serial console over network switches isn't.
- HTTP session connections are an option but are not encrypted. They're not recommended unless they're used within in a closed, trusted network.
Known limitations
The StorSimple Data Manager and Azure file shares have a few limitations you should consider before you begin, as they can prevent a migration:
- Only NTFS volumes from your StorSimple appliance are supported. ReFS volumes aren't supported.
- Any volume placed on Windows Server Dynamic Disks isn't supported.
- The service doesn't work with volumes that are BitLocker encrypted or have Data Deduplication enabled.
- Corrupted StorSimple backups can't be migrated.
- Special networking options, such as firewalls or private endpoint-only communication, can't be enabled on either the source storage account where StorSimple backups are stored, nor on the target storage account that holds your Azure file shares.
File fidelity
If none of the limitations in Known limitations prevent a migration, there are still limitations on what can be stored in Azure file shares.
File fidelity refers to the multitude of attributes, timestamps, and data that compose a file. In a migration, file fidelity is a measure of how well the information on the source (StorSimple volume) can be translated (migrated) to the target Azure file share.
Azure Files supports a subset of the NTFS file properties. Windows ACLs, common metadata, and some timestamps are migrated.
The following items won't prevent a migration but will cause per-item issues during a migration:
- Timestamps: File change time won't be set. It's currently read-only over the REST protocol. Last access timestamp on a file won't be moved, as it isn't a supported attribute on files stored in an Azure file share.
- Alternative Data Streams can't be stored in Azure file shares. Files holding Alternate Data Streams will be copied, but Alternate Data Streams are stripped from the file in the process.
- Symbolic links, hard links, junctions, and reparse points are skipped during a migration. The migration copy logs list each skipped item and a reason.
- EFS encrypted files fail to copy. Copy logs show the item failed to copy with "Access is denied".
- Corrupt files are skipped. The copy logs might list different errors for each item that is corrupt on the StorSimple disk: "The request failed due to a fatal device hardware error" or "The file or directory is corrupted or unreadable" or "The access control list (ACL) structure is invalid".
- Individual files larger than 4 TiB are skipped.
- File path lengths must be equal to or fewer than 2048 characters. Files and folders with longer paths are skipped.
- Reparse points are skipped. Any Microsoft Data Deduplication / SIS reparse points or those of third parties can't be resolved by the migration engine and will prevent a migration of the affected files and folders.
The troubleshooting section at the end of this article has more details for item level and migration job level error codes and where possible, their mitigation options.
StorSimple volume backups
StorSimple offers differential backups on the volume level. Azure file shares also have this ability, called share snapshots.
Your migration jobs can only move backups, never data from the live volume. Therefore the most recent backup is closest to the live data and thus should always be part of the list of backups to be moved in a migration.
Decide if you need to move any older backups during your migration. It's a best practice to keep this list as small as possible so your migration jobs complete faster.
To identify critical backups that must be migrated, make a checklist of your backup policies. For example:
- The most recent backup.
- One backup a month for 12 months.
- One backup a year for three years.
When you create your migration jobs, you can use this list to identify the exact StorSimple volume backups that must be migrated to satisfy your requirements.
It's best to suspend all StorSimple backup retention policies before you select a backup for migration. Migrating your backups can take several days or weeks. StorSimple offers backup retention policies that delete backups. Backups you've selected for this migration might get deleted before they've had a chance to be migrated.
Caution
Selecting more than 50 StorSimple volume backups isn't supported.
Map your existing StorSimple volumes to Azure file shares
In this step, you'll determine how many Azure file shares you need. A single Windows Server instance (or cluster) can sync up to 30 Azure file shares.
You might have more folders on your volumes that you currently share out locally as SMB shares to your users and apps. The easiest way to picture this scenario is to envision an on-premises share that maps 1:1 to an Azure file share. If you have a small enough number of shares, below 30 for a single Windows Server instance, we recommend a 1:1 mapping.
If you have more than 30 shares, mapping an on-premises share 1:1 to an Azure file share is often unnecessary. Consider the following options.
Share grouping
For example, if your human resources (HR) department has 15 shares, you might consider storing all the HR data in a single Azure file share. Storing multiple on-premises shares in one Azure file share doesn't prevent you from creating the usual 15 SMB shares on your local Windows Server instance. It only means that you organize the root folders of these 15 shares as subfolders under a common folder. You then sync this common folder to an Azure file share. That way, only a single Azure file share in the cloud is needed for this group of on-premises shares.
Volume sync
Azure File Sync supports syncing the root of a volume to an Azure file share. If you sync the volume root, all subfolders and files will go to the same Azure file share.
Syncing the root of the volume isn't always the best option. There are benefits to syncing multiple locations. For example, doing so helps keep the number of items lower per sync scope. We test Azure file shares and Azure File Sync with 100 million items (files and folders) per share. But a best practice is to try to keep the number below 20 million or 30 million in a single share. Setting up Azure File Sync with a lower number of items isn't beneficial only for file sync. A lower number of items also benefits scenarios like these:
- Initial scan of the cloud content can complete faster, which in turn decreases the wait for the namespace to appear on a server enabled for Azure File Sync.
- Cloud-side restore from an Azure file share snapshot will be faster.
- Disaster recovery of an on-premises server can speed up significantly.
- Changes made directly in an Azure file share (outside of sync) can be detected and synced faster.
Tip
If you don't know how many files and folders you have, check out the TreeSize tool from JAM Software GmbH.
A structured approach to a deployment map
Before you deploy cloud storage in a later step, it's important to create a map between on-premises folders and Azure file shares. This mapping will inform how many and which Azure File Sync sync group resources you'll provision. A sync group ties the Azure file share and the folder on your server together and establishes a sync connection.
To decide how many Azure file shares you need, review the following limits and best practices. Doing so will help you optimize your map.
A server on which the Azure File Sync agent is installed can sync with up to 30 Azure file shares.
An Azure file share is deployed in a storage account. That arrangement makes the storage account a scale target for performance numbers like IOPS and throughput.
Pay attention to a storage account's IOPS limitations when deploying Azure file shares. Ideally, you should map file shares 1:1 with storage accounts. However, this might not always be possible due to various limits and restrictions, both from your organization and from Azure. When it's not possible to have only one file share deployed in one storage account, consider which shares will be highly active and which shares will be less active to ensure that the hottest file shares don't get put in the same storage account together.
If you plan to lift an app to Azure that will use the Azure file share natively, you might need more performance from your Azure file share. If this type of use is a possibility, even in the future, it's best to create a single standard Azure file share in its own storage account.
There's a limit of 250 storage accounts per subscription per Azure region.
Tip
Given this information, it often becomes necessary to group multiple top-level folders on your volumes into a new common root directory. You then sync this new root directory, and all the folders you grouped into it, to a single Azure file share. This technique allows you to stay within the limit of 30 Azure file share syncs per server.
This grouping under a common root doesn't affect access to your data. Your ACLs stay as they are. You only need to adjust any share paths (like SMB or NFS shares) you might have on the local server folders that you now changed into a common root. Nothing else changes.
Important
The most important scale vector for Azure File Sync is the number of items (files and folders) that need to be synced. Review the Azure File Sync scale targets for more details.
It's a best practice to keep the number of items per sync scope low. That's an important factor to consider in your mapping of folders to Azure file shares. Azure File Sync is tested with 100 million items (files and folders) per share. But it's often best to keep the number of items below 20 million or 30 million in a single share. Split your namespace into multiple shares if you start to exceed these numbers. You can continue to group multiple on-premises shares into the same Azure file share if you stay roughly below these numbers. This practice will provide you with room to grow.
It's possible that, in your situation, a set of folders can logically sync to the same Azure file share (by using the new common root folder approach mentioned earlier). But it might still be better to regroup folders so they sync to two instead of one Azure file share. You can use this approach to keep the number of files and folders per file share balanced across the server. You can also split your on-premises shares and sync across more on-premises servers, adding the ability to sync with 30 more Azure file shares per extra server.
Common file sync scenarios and considerations
| # | Sync scenario | Supported | Considerations (or limitations) | Solution (or workaround) |
|---|---|---|---|---|
| 1 | File server with multiple disks/volumes and multiple shares to same target Azure file share (consolidation) | No | A target Azure file share (cloud endpoint) only supports syncing with one sync group. A sync group only supports one server endpoint per registered server. |
1) Start with syncing one disk (its root volume) to target Azure file share. Starting with largest disk/volume will help with storage requirements on-premises. Configure cloud tiering to tier all data to cloud, thereby freeing up space on the file server disk. Move data from other volumes/shares into the current volume which is syncing. Continue the steps one by one until all data is tiered up to cloud/migrated. 2) Target one root volume (disk) at a time. Use cloud tiering to tier all data to target Azure file share. Remove server endpoint from sync group, re-create the endpoint with the next root volume/disk, sync, and repeat the process. Note: Agent re-install might be required. 3) Recommend using multiple target Azure file shares (same or different storage account based on performance requirements) |
| 2 | File server with single volume and multiple shares to same target Azure file share (consolidation) | Yes | Can't have multiple server endpoints per registered server syncing to same target Azure file share (same as above) | Sync root of the volume holding multiple shares or top-level folders. Refer to Share grouping concept and Volume sync for more information. |
| 3 | File server with multiple shares and/or volumes to multiple Azure file shares under single storage account (1:1 share mapping) | Yes | A single Windows Server instance (or cluster) can sync up to 30 Azure file shares. A storage account is a scale target for performance. IOPS and throughput get shared across file shares. Keep number of items per sync group within 100 million items (files and folders) per share. Ideally it's best to stay below 20 or 30 million per share. |
1) Use multiple sync groups (number of sync groups = number of Azure file shares to sync to). 2) Only 30 shares can be synced in this scenario at a time. If you have more than 30 shares on that file server, use Share grouping concept and Volume sync to reduce the number of root or top-level folders at source. 3) Use additional File Sync servers on-premises and split/move data to these servers to work around limitations on the source Windows server. |
| 4 | File server with multiple shares and/or volumes to multiple Azure file shares under different storage account (1:1 share mapping) | Yes | A single Windows Server instance (or cluster) can sync up to 30 Azure file shares (same or different storage account). Keep number of items per sync group within 100 million items (files and folders) per share. Ideally it's best to stay below 20 or 30 million per share. |
Same approach as above |
| 5 | Multiple file servers with single (root volume or share) to same target Azure file share (consolidation) | No | A sync group can't use cloud endpoint (Azure file share) already configured in another sync group. Although a sync group can have server endpoints on different file servers, the files can't be distinct. |
Follow guidance in Scenario # 1 above with additional consideration of targeting one file server at a time. |
Create a mapping table

Use the previous information to determine how many Azure file shares you need and which parts of your existing data will end up in which Azure file share.
Create a table that records your thoughts so you can refer to it when you need to. Staying organized is important because it can be easy to lose details of your mapping plan when you're provisioning many Azure resources at once. Download the following Excel file to use as a template to help create your mapping.

|
Download a namespace-mapping template. |
Number of storage accounts
Your migration will likely benefit from deploying multiple storage accounts that each hold a smaller number of Azure file shares.
If your file shares are highly active (utilized by many users or applications), two Azure file shares might reach the performance limit of your storage account. Because of this, it's often better migrate to multiple storage accounts, each with their own individual file shares, and typically no more than two or three shares per storage account. A best practice is to deploy storage accounts with one file share each. You can pool multiple Azure file shares into the same storage account, if you have archival shares in them.
These considerations apply more to direct cloud access (through an Azure VM or service) than to Azure File Sync. If you plan to exclusively use Azure File Sync on these shares, grouping several into a single Azure storage account is fine. In the future, you might want to lift and shift an app into the cloud that would then directly access a file share, as this scenario would benefit from having higher IOPS and throughput. Or you could start using a service in Azure that would also benefit from having higher IOPS and throughput.
After making a list of your shares, map each share to the storage account where it will reside. Decide on an Azure region, and ensure each storage account and Azure File Sync resource matches the region you selected.
Important
Don't configure network and firewall settings for the storage accounts now. Making these configurations at this point would make a migration impossible. Configure these Azure storage settings after the migration is complete.
Storage account settings
There are many configurations you can make on a storage account. Use the following checklist to confirm your storage account configurations. You can change the networking configuration after your migration is complete.
- Firewall and virtual networks: Disabled - don't configure any IP restrictions or limit storage account access to a specific virtual network. The public endpoint of the storage account is used during the migration. All IP addresses from Azure VMs must be allowed. It's best to configure any firewall rules on the storage account after the migration. Configure both your source and target storage accounts this way.
- Private Endpoints: Supported - You can enable private endpoints, but the public endpoint is used for the migration and must remain available. This applies to both your source and target storage accounts.
Phase 1 summary
At the end of Phase 1:
- You have a good overview of your StorSimple devices and volumes.
- The Data Manager service is ready to access your StorSimple volumes in the cloud because you've retrieved your service data encryption key for each StorSimple device.
- You have a plan for which volumes and backups (if any beyond the most recent) need to be migrated.
- You know how to map your volumes to the appropriate number of Azure file shares and storage accounts.
Phase 2: Deploy Azure storage and migration resources
This section discusses considerations around deploying the different resource types that are needed in Azure. Some will hold your data post migration, and some are needed solely for the migration. Don't start deploying resources until you've finalized your deployment plan. It's difficult, sometimes impossible, to change certain aspects of your Azure resources after they've been deployed.

This video covers deployment of:
- Storage accounts
- Subscription(s) and resource groups
- Storage accounts
- Types and name(s)
- Performance and share size
- Location and replication types
- Azure file shares
- StorSimple Data Manager Service
Deploy storage accounts
You'll likely need to deploy several Azure storage accounts. Each one will hold a smaller number of Azure file shares, as per your deployment plan. Go to the Azure portal to deploy your planned storage accounts. Consider adhering to the following basic settings for any new storage account.
Important
Don't configure network and firewall settings for your storage accounts before or during your migration. Making those configurations at this point would make a migration impossible. The public endpoint must be accessible on source and target storage accounts. Limiting to specific IP ranges or virtual networks isn't supported. You can change the storage account networking configurations after the migration is complete.
Subscription
You can use the same subscription you used for your StorSimple deployment, or you can use a different one. The only limitation is that your subscription must be in the same Microsoft Entra tenant as the StorSimple subscription. Consider moving the StorSimple subscription to the appropriate tenant before you start a migration. You can only move the entire subscription, as individual StorSimple resources can't be moved to a different tenant or subscription.
Resource group
Resource groups in Azure assist with organization of resources and admin management permissions. Find out more.
Storage account name
The name of your storage account will become part of a URL used to access your file share, and has certain character limitations. In your naming convention, consider that storage account names must be unique in the world, allow only lowercase letters and numbers, require between 3 to 24 characters, and don't allow special characters like hyphens or underscores. See Azure storage resource naming rules.
Location
The Azure region of a storage account is important. If you use Azure File Sync, all your storage accounts must be in the same region as your Storage Sync Service resource. The Azure region you pick should be close or central to your local servers and users. After you deploy your resource, you can't change its region.
You can pick a different region from where your StorSimple data (storage account) currently resides, however, if you do, egress charges will apply during the migration. Data will leave the StorSimple region and enter your new storage account region. No bandwidth charges apply if you stay within the same Azure region.
Performance
You have the option to pick premium storage (SSD) for Azure file shares or standard storage. Standard storage includes several tiers for a file share. Standard storage is the right option for most customers migrating from StorSimple.
- Choose premium storage if you need the performance of a premium Azure file share.
- Choose standard storage for general-purpose file server workloads, which includes hot data and archive data. Also choose standard storage if the only workload on the share in the cloud will be Azure File Sync.
- For premium file shares, choose File shares in the create storage account wizard.
Replication
There are several replication settings available. Only choose from the following two options:
- Locally redundant storage (LRS).
- Zone redundant storage (ZRS), which isn't available in all Azure regions.
Note
Geo redundant storage (GRS) and geo-zone redundant storage aren't supported.
Azure file shares
After creating your storage accounts, go to the File share section of the storage account(s) and deploy the appropriate number of Azure file shares as per your migration plan from Phase 1. Consider adhering to the following basic settings for your new file shares in Azure.

Name
Lowercase letters, numbers, and hyphens are supported.
Quota
Quota here is comparable to an SMB hard quota on a Windows Server instance. The best practice is to not set a quota here because your migration and other services will fail when the quota is reached.
Tiers
Select Transaction optimized for your new file share. During the migration, many transactions will occur. It's more cost efficient to change your tier later to the tier best suited to your workload.
StorSimple Data Manager
The Azure resource that holds your migration jobs is called a StorSimple Data Manager. Select New resource, and search for it. Then select Create.
This temporary resource is used for orchestration. You deprovision it after your migration completes. Make sure to deploy it in the same subscription, resource group, and region as your StorSimple storage account.
Azure File Sync
With Azure File Sync, you can add on-premises caching of the most frequently accessed files. Similar to the caching abilities of StorSimple, the Azure File Sync cloud tiering feature offers local-access latency in combination with improved control over the available cache capacity on the Windows Server instance and multi-site sync. If having an on-premises cache is your goal, then in your local network, prepare a Windows Server VM (physical servers and failover clusters are also supported) with sufficient direct-attached storage capacity.
Important
Don't set up Azure File Sync yet. Deploying Azure File Sync shouldn't start before Phase 4 of a migration.
Phase 2 summary
At the end of Phase 2, you'll have deployed your storage accounts and all Azure file shares across them. You'll also have a StorSimple Data Manager resource. You'll use the latter in Phase 3 when you configure your migration jobs.
Phase 3: Create and run a migration job
This section describes how to set up a migration job and map the directories on a StorSimple volume that should be copied into the target Azure file share you select.

This video covers:
- Creating a migration job
- Summary
- Source
- Selecting volume backups to migrate
- Target
- Directory mapping
- Semantic rules
- Running a migration Job
- Run job definition
- Viewing the state of the job
- Running jobs in parallel
- Interpreting the log files
To get started, go to your StorSimple Data Manager, find Job definitions on the menu, and select + Job definition. The correct target storage type is the default: Azure file share.

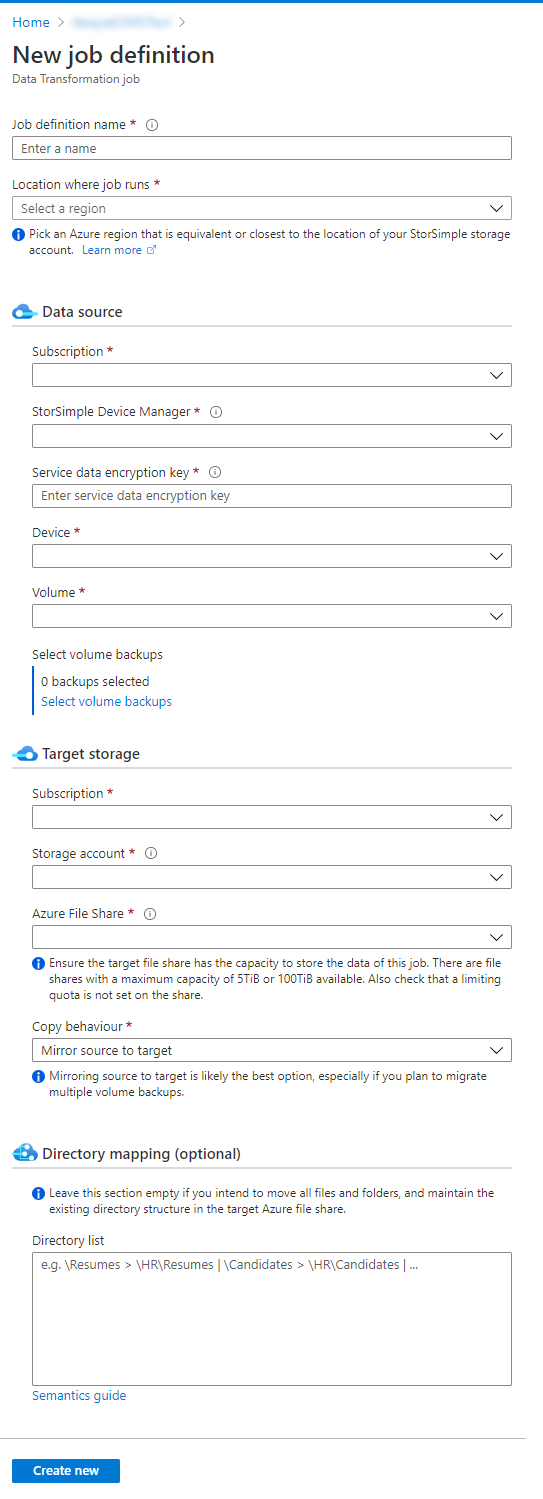
Job definition name
This name should indicate the set of files you're moving. Giving it a similar name as your Azure file share is a good practice.
Location where the job runs
When selecting a region, you must select the same region as your StorSimple storage account or, if that isn't available, then a region close to it.
Source
Source subscriptionSelect the subscription in which you store your StorSimple Device Manager resource.
StorSimple resource
Select your StorSimple Device Manager your appliance is registered with.
Service data encryption key
Check this prior section in this article in case you can't locate the key in your records.
Device
Select your StorSimple device that holds the volume where you want to migrate.
Volume
Select the source volume. Later you'll decide if you want to migrate the whole volume or subdirectories into the target Azure file share.
Volume backups
You can select Select volume backups to choose specific backups to move as part of this job. An upcoming, dedicated section in this article covers the process in detail.
Target
Select the subscription, storage account, and Azure file share as the target of this migration job.Directory mapping
A dedicated section in this article, discusses all relevant details.Selecting volume backups to migrate
There are important aspects around choosing backups that need to be migrated:
- Your migration jobs can only move backups, not live volume data. So the most recent backup is closest to the live data and should always be on the list of backups moved in a migration. When you open the Backup selection dialog, it's selected by default.
- Make sure your latest backup is recent to keep the delta to the live share as small as possible. It could be worth manually triggering and completing another volume backup before creating a migration job. A small delta to the live share improves your migration experience. If this delta can be zero, meaning that no more changes to the StorSimple volume happened after the newest backup was taken in your list, then the user cut-over will be drastically simplified and sped up.
- Backups must be played back into the Azure file share from oldest to newest. An older backup can't be "sorted into" the list of backups on the Azure file share after running a migration job. Therefore you must ensure that your list of backups is complete before you create a job.
- This list of backups in a job can't be modified once the job is created, even if the job never ran.
- In order to select backups, the StorSimple volume you want to migrate must be online.

To select backups of your StorSimple volume for your migration job, select the Select volume backups on the job creation form.

When the backup selection blade opens, it's separated into two lists. In the first list, all available backups are displayed. You can expand and narrow the result set by filtering for a specific time range. (see next section)
A selected backup will display as grayed-out and is added to a second list on the lower half of the blade. The second list displays all the backups selected for migration. A backup selected in error can also be removed again.
Caution
You must select all backups you wish to migrate. You can't add older backups later. You can't modify the job to change your selection once the job is created.

By default, the list is filtered to show the StorSimple volume backups within the past seven days. The most recent backup is selected by default, even if it didn't occur in the past seven days. For older backups, use the time range filter at the top of the blade. You can either select from an existing filter or set a custom time range to filter for only the backups taken during this period.
Caution
Selecting more than 50 StorSimple volume backups isn't supported. Jobs with a large number of backups may fail. Make sure your backup retention policies don't delete a selected backup before it got a chance to be migrated!
Directory mapping
Directory mapping is optional for your migration job. If you leave the section empty, all the files and folders on the root of your StorSimple volume will be moved into the root of your target Azure file share. In most cases, storing an entire volume's content in an Azure file share isn't the best approach. It's often better to split a volume's content across multiple file shares in Azure. If you haven't made a plan already, see Map your StorSimple volume to Azure file shares first.
As part of your migration plan, you might have decided that the folders on a StorSimple volume need to be split across multiple Azure file shares. If that's the case, you can accomplish that split by:
- Defining multiple jobs to migrate the folders on one volume. Each will have the same StorSimple volume source but a different Azure file share as the target.
- Specifying precisely which folders from the StorSimple volume need to be migrated into the specified file share by using the Directory-mapping section of the job creation form and following the specific mapping semantics.
Important
The paths and mapping expressions in this form can't be validated when the form is submitted. If mappings are specified incorrectly, a job might either fail completely or produce an undesirable result. In that case, it's usually best to delete the Azure file share, re-create it, and then fix the mapping statements in a new migration job for the share. Running a new job with fixed mapping statements can fix omitted folders and bring them into the existing share. However, only folders that were omitted because of path misspellings can be addressed this way.
Semantic elements
A mapping is expressed from left to right: [\source path] > [\target path].
| Semantic character | Meaning |
|---|---|
| \ | Root level indicator. |
| > | [Source] and [target-mapping] operator. |
| | or RETURN (new line) | Separator of two folder-mapping instructions. Alternatively, you can omit this character and select Enter to get the next mapping expression on its own line. |
Examples
Moves the content of folder User data to the root of the target file share:
\User data > \
Moves the entire volume content into a new path on the target file share:
\ > \Apps\HR tracker
Moves the source folder content into a new path on the target file share:
\HR resumes-Backup > \Backups\HR\resumes
Sorts multiple source locations into a new directory structure:
\HR\Candidate Tracker\v1.0 > \Apps\Candidate tracker
\HR\Candidates\Resumes > \HR\Candidates\New
\Archive\HR\Old Resumes > \HR\Candidates\Archived
Semantic rules
- Always specify folder paths relative to the root level.
- Begin each folder path with a root level indicator "\".
- Don't include drive letters.
- When specifying multiple paths, source or target paths can't overlap:
Invalid source path overlap example:
\folder\1 > \folder
\folder\1\2 > \folder2
Invalid target path overlap example:
\folder > \
\folder2 > \ - Source folders that don't exist are ignored.
- Folder structures that don't exist on the target are created.
- Like Windows, folder names are case insensitive but case preserving.
Note
Contents of the \System Volume Information folder and the $Recycle.Bin on your StorSimple volume won't be copied by the migration job.
Run a migration job
Your migration jobs are listed under Job definitions in the Data Manager resource you've deployed to a resource group. From the list of job definitions, select the job you want to run.
In the job blade that opens, you can see your job's current status and a list of backups you've selected. The list of backups is sorted by oldest to newest and will be migrated to your Azure file share in this order.

Initially, the migration job will have the status: Never ran.
When you're ready, start the migration job. Select the image for a version with higher resolution.
When a backup is successfully migrated, an automatic Azure file share snapshot will be taken. The original backup date of your StorSimple backup is placed in the Comments section of the Azure file share snapshot. Utilizing this field allows you to see when the data was originally backed up as compared to the time the file share snapshot was taken.
Caution
Backups must be processed from oldest to newest. Once a migration job is created, you can't change the list of selected StorSimple volume backups. Don't start the job if the list of Backups is incorrect or incomplete. Delete the job and make a new one with the correct backups selected. For each selected backup, check your retention schedules. Backups might get deleted by one or more of your retention policies before they got a chance to be migrated!
Per-item errors
The migration jobs have two columns in the list of backups that list any issues that might have occurred during the copy:
- Copy errors
This column lists files or folders that should have been copied but weren't. These errors are often recoverable. When a backup lists item issues in this column, review the copy logs. If you need to migrate these files, select Retry backup. This option becomes available once the backup finishes processing. The Managing a migration job section explains your options in more detail. - Unsupported files
This column lists files or folders that can't be migrated. Azure Storage has limitations in file names, path lengths, and file types that currently or logically can't be stored in an Azure file share. A migration job won't pause for these kinds of errors. Retrying migration of the backup won't change the result. When a backup lists item issues in this column, review the copy logs and take note. If such issues arise in your last backup and you found in the copy log that the failure was due to a file name, path length, or other issue you have influence over, you might want to remedy the issue in the live StorSimple volume, take a StorSimple volume backup, and create a new migration job with just that backup. You can then migrate this remedied namespace and it will become the most recent / live version of the Azure file share. This is a manual and time consuming process. Review the copy logs carefully and evaluate if it's worth it.
These copy logs are *.csv files listing namespace items succeeded and items that failed to get copied. The errors are further split into the previously discussed categories. From the log file location, you can find logs for failed files by searching for "failed". The result should be a set of logs for files that failed to copy. Sort these logs by size. There might be extra logs produced at 17 bytes in size. They are empty and can be ignored. With a sort, you can focus on the logs with content.
The same process applies for log files recording successful copies.
Manage a migration job
Migration jobs have the following states:
- Never ran
A new job that has been defined but never run. - Waiting
A job in this state is waiting for resources to be provisioned in the migration service. It will automatically switch to a different state when ready. - Failed
A failed job hit a fatal error that prevents it from processing more backups. A job isn't expected to enter this state. A support request is the best course of action. - Canceled / Canceling
Either and entire migration job or individual backups within the job can be canceled. Canceled backups won't be processed, as a canceled migration job will stop processing backups. Expect that canceling a job will take a long time. This doesn't prevent you from creating a new job. The best course of action is to let a job fully arrive in the Canceled state. You can either ignore failed / canceled jobs or delete them later. You won't have to delete jobs before you can delete the Data Manager resource at the end of your StorSimple migration.

Running
A running job is currently processing a backup. Refer to the table on the bottom half of the blade to see which backup is currently being processed and which ones might have been migrated already.
Already migrated backups have a column with a link to a copy log. If a backup reports any errors, you should review its copy log.

Paused
A migration job is paused when there is a decision needed. This condition enables two command buttons on the top of the blade:
Choose Retry backup when the backup shows files that were supposed to move but didn't (Copy error column).
Choose Skip backup when the backup is missing (was deleted by policy since you created the migration job) or when the backup is corrupt. You can find detailed error information in the blade that opens when you click on the failed backup.
When you skip or retry the current backup, the migration service will create a new snapshot in your target Azure file share. You might want to delete the previous one later, as it's likely incomplete.

Complete and Complete with warnings
A migration job is listed as Complete when all backups in the job have been successfully processed.
Complete with warnings is a state that occurs when:
- A backup ran into a recoverable issue. This backup is marked as partial success or failed.
- You decided to continue on the paused job by skipping the backup with said issues. (You chose Skip backup instead of Retry backup)
Run jobs in parallel
You will likely have multiple StorSimple volumes, each with their own shares that must be migrated to an Azure file share. It's important that you understand how much you can do in parallel. There are limitations that aren't enforced in the user experience and will either degrade or inhibit a complete migration if jobs are executed at the same time.
There are no limits in defining migration jobs. You can define the same StorSimple source volume, the same Azure file share, across the same or different StorSimple appliances. However, running them has limitations:
- Only one migration job with the same StorSimple source volume can run at the same time.
- Only one migration job with the same target Azure file share can run at the same time.
- Before starting the next job, ensure that any of the previous jobs are in the
copy stageand show progress of moving files for at least 30 minutes. - You can run up to four migration jobs in parallel per StorSimple device manager, as long as you abide by the previous rules.
When you attempt to start a migration job, the previous rules are checked. If there are jobs running, you might not be able to start a new job. You'll receive an alert that lists the name of currently running job(s) that must finish before you can start the new job.
Tip
It's a good idea to regularly check your migration jobs in the Job definition tab of your Data Manager resource to see if any of them have paused and need your input to complete.
Phase 3 summary
At the end of Phase 3, you'll have run at least one of your migration jobs from StorSimple volumes into Azure file share(s). With your run, you will have migrated your specified backups into Azure file share snapshots. You can now focus on either setting up Azure File Sync for the share (once migration jobs for a share have completed) or direct-share-access for your information workers and apps to the Azure file share.
Phase 4: Access your Azure file shares
There are two main strategies for accessing your Azure file shares:
- Azure File Sync: Deploy Azure File Sync to an on-premises Windows Server instance. Azure File Sync has all the advantages of a local cache, just like StorSimple.
- Direct-share-access: Deploy direct-share-access. Use this strategy if your access scenario for a given Azure file share won't benefit from local caching, or if you no longer have an ability to host an on-premises Windows Server instance. Here, your users and apps will continue to access SMB shares over the SMB protocol. These shares are no longer on an on-premises server but directly in the cloud.
You should have already decided which option is best for you in Phase 1 of this guide.
The remainder of this section focuses on deployment instructions.

This video covers:
- Approaches to access Azure file shares
- Azure File Sync
- Direct-share-access
- Deploying Azure File Sync
- Deploy the Azure File Sync cloud resource
- Deploy an on-premises Windows Server instance
- Preparing the Windows Server instance for Azure File Sync
- Configuring Azure File Sync on the Windows Server instance
- Monitoring initial sync
- Testing Azure File Sync
- Creating the SMB shares
Deploy Azure File Sync
It's time to deploy a part of Azure File Sync.
- Create the Azure File Sync cloud resource.
- Deploy the Azure File Sync agent on your on-premises server.
- Register the server with the cloud resource.
Don't create any sync groups yet. Setting up sync with an Azure file share should only occur after your migration jobs to an Azure file share have completed. If you start using Azure File Sync before your migration completes, it will make your migration unnecessarily difficult because you won't be able to easily tell when it was time to initiate a cut-over.
Deploy the Azure File Sync cloud resource
To complete this step, you need your Azure subscription credentials.
The core resource to configure for Azure File Sync is called a Storage Sync Service. We recommend that you deploy only one for all servers that are syncing the same set of files now or in the future. Create multiple Storage Sync Services only if you have distinct sets of servers that must never exchange data. For example, you might have servers that must never sync the same Azure file share. Otherwise, using a single Storage Sync Service is the best practice.
Choose an Azure region for your Storage Sync Service that's close to your location. All other cloud resources must be deployed in the same region. To simplify management, create a new resource group in your subscription that houses sync and storage resources.
For more information, see the section about deploying the Storage Sync Service in the article about deploying Azure File Sync. Follow only this section of the article. There will be links to other sections of the article in later steps.
Tip
If you want to change the Azure region your data resides in after the migration is finished, deploy the Storage Sync Service in the same region as the target storage accounts for this migration.
Deploy an on-premises Windows Server instance
- Create Windows Server 2019 (at a minimum 2012R2) as a virtual machine or physical server. A Windows Server failover cluster is also supported. Don't reuse the server fronting the StorSimple 8100 or 8600.
- Provision or add direct-attached storage. Network-attached storage isn't supported.
It's best practice to give your new Windows Server instance an equal or larger amount of storage than your StorSimple 8100 or 8600 appliance has locally available for caching. You'll use the Windows Server instance the same way you used the StorSimple appliance. If it has the same amount of storage as the appliance, the caching experience should be similar, if not the same. You can add or remove storage from your Windows Server instance at will. This capability enables you to scale your local volume size and the amount of local storage available for caching.
Prepare the Windows Server instance for file sync
In this section, you install the Azure File Sync agent on your Windows Server instance.
The deployment guide explains that you need to turn off Internet Explorer Enhanced Security Configuration. This security measure isn't applicable with Azure File Sync. Turning it off allows you to authenticate to Azure without any problems.
Open PowerShell. Install the required PowerShell modules by using the following commands. Be sure to install the full module and the NuGet provider when you're prompted to do so.
Install-Module -Name Az -AllowClobber
Install-Module -Name Az.StorageSync
If you have any problems reaching the internet from your server, now is the time to solve them. Azure File Sync uses any available network connection to the internet. Requiring a proxy server to reach the internet is also supported. You can either configure a machine-wide proxy now or, during agent installation, specify a proxy that only Azure File Sync will use.
If configuring a proxy means you need to open your firewalls for the server, that approach might be acceptable to you. At the end of the server installation, after you've completed server registration, a network connectivity report will show you the exact endpoint URLs in Azure that Azure File Sync needs to communicate with for the region you've selected. The report also tells you why communication is needed. You can use the report to lock down the firewalls around the server to specific URLs.
You can also take a more conservative approach in which you don't open the firewalls wide. You can instead limit the server to communicate with higher-level DNS namespaces. For more information, see Azure File Sync proxy and firewall settings. Follow your own networking best practices.
At the end of the server installation wizard, a server registration wizard will open. Register the server to your Storage Sync Service's Azure resource from earlier.
These steps are described in more detail in the deployment guide, which includes the PowerShell modules that you should install first: Azure File Sync agent installation.
Use the latest agent. You can download it from the Microsoft Download Center: Azure File Sync Agent.
After a successful installation and server registration, you can confirm that you've successfully completed this step. Go to the Storage Sync Service resource in the Azure portal. In the left menu, go to Registered servers. You'll see your server listed there.
Configure Azure File Sync on the Windows Server instance
Your registered on-premises Windows Server instance must be ready and connected to the internet for this process.
Important
Your StorSimple migration of files and folders into the Azure file share must be complete before you proceed. Make sure there are no more changes done to the file share.
This step ties together all the resources and folders you've set up on your Windows Server instance during the previous steps.
- Sign in to the Azure portal.
- Locate your Storage Sync Service resource.
- Create a new sync group within the Storage Sync Service resource for each Azure file share. In Azure File Sync terminology, the Azure file share will become a cloud endpoint in the sync topology that you're describing with the creation of a sync group. When you create the sync group, give it a familiar name so that you recognize which set of files syncs there. Make sure you reference the Azure file share with a matching name.
- After you create the sync group, a row for it will appear in the list of sync groups. Select the name (a link) to display the contents of the sync group. You'll see your Azure file share under Cloud endpoints.
- Locate the Add Server Endpoint button. The folder on the local server that you've provisioned will become the path for this server endpoint.
Important
Be sure to turn on cloud tiering. Cloud tiering is the Azure File Sync feature that allows the local server to have less storage capacity than is stored in the cloud, yet have the full namespace available. Locally interesting data is also cached locally for fast performance. Another reason to turn on cloud tiering at this step is that we don't want to sync file content at this stage. Only the namespace should be moving at this time.
Deploy direct-share-access
This video is a guide and demo for how to securely expose Azure file shares directly to information workers and apps in five simple steps.
The video references dedicated documentation for the following topics. Note that Azure Active Directory is now Microsoft Entra ID. For more info, see New name for Azure AD.
Phase 4 summary
At the end of this phase, you've created and run multiple migration jobs in your StorSimple Data Manager. Those jobs have migrated your files and folders and their backups to Azure file shares. You've also deployed Azure File Sync or prepared your network and storage accounts for direct-share-access.
Phase 5: User cut-over
In this phase, you'll complete your migration:
- Plan your downtime.
- Catch up with any changes your users and apps produced on the StorSimple side while the migration jobs in Phase 3 have been running.
- Fail over your users to the new Windows Server instance with Azure File Sync or to the Azure file shares via direct-share-access.

This video covers:
- Steps to take before your workload cut-over
- Executing your cut-over
- Post cut-over steps
Plan your downtime
This migration approach requires some downtime for your users and apps. The goal is to keep downtime to a minimum. The following considerations can help:
- Keep your StorSimple volumes available while running your migration jobs.
- When you've finished running your data migration jobs for a share, it's time to remove user access (at least write access) from the StorSimple volumes or shares. A final RoboCopy will catch up your Azure file share. Then you can cut over your users. Where you run RoboCopy depends on whether you chose to use Azure File Sync or direct-share-access. The upcoming section covers that subject.
- After you've completed the RoboCopy catch-up, you're ready to expose the new location to your users by either the Azure file share directly or an SMB share on a Windows Server instance with Azure File Sync. Often a DFS-N deployment will help accomplish a cut-over quickly and efficiently. It will keep your existing share addresses consistent and repoint to a new location that contains your migrated files and folders.
For archival data, it's a fully viable approach to take downtime on your StorSimple volume (or subfolder), take one more StorSimple volume backup, migrate, and then open up the migration destination for access by users and apps. This will spare you the need for a catch-up RoboCopy. However, this approach comes at the cost of a prolonged downtime window that might stretch to several days or longer depending on the number of files and backups you need to migrate. This is likely only an option for archival workloads that can do without write access for prolonged periods of time.
Determine when your namespace has fully synced to your server
When you use Azure File Sync for an Azure file share, it's important to determine that your entire namespace has finished downloading to the server before you start any local RoboCopy. The time it takes to download your namespace depends on the number of items in your Azure file share. There are two methods for determining whether your namespace has fully arrived on the server.
Azure portal
You can use the Azure portal to see when your namespace has fully arrived.
- Sign in to the Azure portal, and go to your sync group. Check the sync status of your sync group and server endpoint.
- The interesting direction is download. If the server endpoint is newly provisioned, it will show Initial sync, which indicates the namespace is still coming down. After that state changes to anything but Initial sync, your namespace will be fully populated on the server.
You can now proceed with a local RoboCopy.
Windows Server Event Viewer
You can also use the Event Viewer on your Windows Server instance to tell when the namespace has fully arrived.
- Open the Event Viewer, and go to Applications and Services.
- Go to and open Microsoft\FileSync\Agent\Telemetry.
- Look for the most recent event 9102, which corresponds to a completed sync session.
- Select Details, and confirm that you're looking at an event where the SyncDirection value is Download.
- For the time where your namespace has completed download to the server, there will be a single event with Scenario, the value FullGhostedSync, and HResult = 0.
- If you miss that event, you can also look for other 9102 events with SyncDirection = Download and Scenario = "RegularSync". Finding one of these events also indicates that the namespace has finished downloading and sync progressed to regular sync sessions, whether there's anything to sync or not at this time.
A final RoboCopy
At this point, there are differences between your on-premises Windows Server instance and the StorSimple 8100 or 8600 appliance.
- You need to catch up with the changes that users or apps produced on the StorSimple side while the migration was ongoing.
- For cases where you use Azure File Sync: The StorSimple appliance has a populated cache versus the Windows Server instance with just a namespace with no file content stored locally at this time. The final RoboCopy can help jump-start your local Azure File Sync cache by pulling over locally cached file content as much as is available and can fit on the Azure File Sync server.
- Some files might have been left behind by the migration job because of invalid characters. If so, copy them to the Azure File Sync-enabled Windows Server instance. Later, you can adjust them so that they will sync. If you don't use Azure File Sync for a particular share, you're better off renaming the files with invalid characters on the StorSimple volume. Then run the RoboCopy directly against the Azure file share.
Warning
Robocopy in Windows Server 2019 experienced an issue that caused files tiered by Azure File Sync on the target server to be recopied from the source and re-uploaded to Azure when using the /MIR function. We recommend running Robocopy on a Windows Server other than 2019, such as Windows Server 2016.
Warning
You must not start the RoboCopy before the server has the namespace for an Azure file share downloaded fully. For more information, see Determine when your namespace has fully downloaded to your server.
You only want to copy files that were changed after the migration job last ran and files that haven't moved through these jobs before. You can solve the problem as to why they didn't move later on the server, after the migration is complete. For more information, see Azure File Sync troubleshooting.
RoboCopy has several parameters. The following example showcases a finished command and a list of reasons for choosing these parameters.
robocopy <SourcePath> <Dest.Path> /MT:20 /R:2 /W:1 /B /MIR /IT /COPY:DATSO /DCOPY:DAT /NP /NFL /NDL /XD "System Volume Information" /UNILOG:<FilePathAndName>
| Switch | Meaning |
|---|---|
/MT:n |
Allows Robocopy to run multithreaded. Default for n is 8. The maximum is 128 threads. While a high thread count helps saturate the available bandwidth, it doesn't mean your migration will always be faster with more threads. Tests with Azure Files indicate between 8 and 20 shows balanced performance for an initial copy run. Subsequent /MIR runs are progressively affected by available compute vs available network bandwidth. For subsequent runs, match your thread count value more closely to your processor core count and thread count per core. Consider whether cores need to be reserved for other tasks that a production server might have. Tests with Azure Files have shown that up to 64 threads produce a good performance, but only if your processors can keep them alive at the same time. |
/R:n |
Maximum retry count for a file that fails to copy on first attempt. Robocopy will try n times before the file permanently fails to copy in the run. You can optimize the performance of your run: Choose a value of two or three if you believe timeout issues caused failures in the past. This may be more common over WAN links. Choose no retry or a value of one if you believe the file failed to copy because it was actively in use. Trying again a few seconds later may not be enough time for the in-use state of the file to change. Users or apps holding the file open may need hours more time. In this case, accepting the file wasn't copied and catching it in one of your planned, subsequent Robocopy runs, may succeed in eventually copying the file successfully. That helps the current run to finish faster without being prolonged by many retries that ultimately end up in a majority of copy failures due to files still open past the retry timeout. |
/W:n |
Specifies the time Robocopy waits before attempting to copy a file that didn't successfully copy during a previous attempt. n is the number of seconds to wait between retries. /W:n is often used together with /R:n. |
/B |
Runs Robocopy in the same mode that a backup application would use. This switch allows Robocopy to move files that the current user doesn't have permissions for. The backup switch depends on running the Robocopy command in an administrator elevated console or PowerShell window. If you use Robocopy for Azure Files, make sure you mount the Azure file share using the storage account access key vs. a domain identity. If you don't, the error messages might not intuitively lead you to a resolution of the problem. |
/MIR |
(Mirror source to target.) Allows Robocopy to copy only deltas between source and target. Empty subdirectories will be copied. Items (files or folders) that have changed or don't exist on the target will be copied. Items that exist on the target but not on the source will be purged (deleted) from the target. When you use this switch, match the source and target folder structures exactly. Matching means copying from the correct source and folder level to the matching folder level on the target. Only then can a "catch up" copy be successful. When source and target are mismatched, using /MIR will lead to large-scale deletions and recopies. |
/IT |
Ensures fidelity is preserved in certain mirror scenarios. For example, if a file experiences an ACL change and an attribute update between two Robocopy runs, it's marked hidden. Without /IT, the ACL change might be missed by Robocopy and not transferred to the target location. |
/COPY:[copyflags] |
The fidelity of the file copy. Default: /COPY:DAT. Copy flags: D= Data, A= Attributes, T= Timestamps, S= Security = NTFS ACLs, O= Owner information, U= Auditing information. Auditing information can't be stored in an Azure file share. |
/DCOPY:[copyflags] |
Fidelity for the copy of directories. Default: /DCOPY:DA. Copy flags: D= Data, A= Attributes, T= Timestamps. |
/NP |
Specifies that the progress of the copy for each file and folder won't be displayed. Displaying the progress significantly lowers copy performance. |
/NFL |
Specifies that file names aren't logged. Improves copy performance. |
/NDL |
Specifies that directory names aren't logged. Improves copy performance. |
/XD |
Specifies directories to be excluded. When running Robocopy on the root of a volume, consider excluding the hidden System Volume Information folder. If used as designed, all information in there is specific to the exact volume on this exact system and can be rebuilt on-demand. Copying this information won't be helpful in the cloud or when the data is ever copied back to another Windows volume. Leaving this content behind should not be considered data loss. |
/UNILOG:<file name> |
Writes status to the log file as Unicode. (Overwrites the existing log.) |
/L |
Only for a test run Files are to be listed only. They won't be copied, not deleted, and not time stamped. Often used with /TEE for console output. Flags from the sample script, like /NP, /NFL, and /NDL, might need to be removed to achieve you properly documented test results. |
/LFSM |
Only for targets with tiered storage. Not supported when the destination is a remote SMB share. Specifies that Robocopy operates in "low free space mode." This switch is useful only for targets with tiered storage that might run out of local capacity before Robocopy finishes. It was added specifically for use with a target enabled for Azure File Sync cloud tiering. It can be used independently of Azure File Sync. In this mode, Robocopy will pause whenever a file copy would cause the destination volume's free space to go below a "floor" value. This value can be specified by the /LFSM:n form of the flag. The parameter n is specified in base 2: nKB, nMB, or nGB. If /LFSM is specified with no explicit floor value, the floor is set to 10 percent of the destination volume's size. Low free space mode isn't compatible with /MT, /EFSRAW, or /ZB. Support for /B was added in Windows Server 2022. Please see section Windows Server 2022 and RoboCopy LFSM below for more information including detail about a related bug and workaround. |
/Z |
Use cautiously Copies files in restart mode. This switch is recommended only in an unstable network environment. It significantly reduces copy performance because of extra logging. |
/ZB |
Use cautiously Uses restart mode. If access is denied, this option uses backup mode. This option significantly reduces copy performance because of checkpointing. |
Important
We recommend using a Windows Server 2022. When using a Windows Server 2019, ensure at the latest patch level or at least OS update KB5005103 is installed. It contains important fixes for certain Robocopy scenarios.
When you configure source and target locations of the RoboCopy command, make sure you review the structure of the source and target to ensure they match. If you used the directory-mapping feature of the migration job, your root-directory structure might be different than the structure of your StorSimple volume. If that's the case, you might need multiple RoboCopy jobs, one for each subdirectory. If you unsure if the command will perform as expected, you can use the /L parameter, which will simulate the command without actually making any changes.
This RoboCopy command uses /MIR, so it won't move files that are the same (tiered files, for instance). But if you get the source and target path wrong, /MIR also purges directory structures on your Windows Server instance or Azure file share that aren't present on the StorSimple source path. They must match exactly for the RoboCopy job to reach its intended goal of updating your migrated content with the latest changes made while the migration is ongoing.
Consult the RoboCopy log file to see if files have been left behind. If issues exist, fix them, and rerun the RoboCopy command. Don't deprovision any StorSimple resources before you fix outstanding issues for files or folders you care about.
If you don't use Azure File Sync to cache the particular Azure file share in question but instead opted for direct-share-access:
- Mount your Azure file share as a network drive to a local Windows machine.
- Perform the RoboCopy between your StorSimple and the mounted Azure file share. If files don't copy, fix up their names on the StorSimple side to remove invalid characters. Then retry RoboCopy. The previously listed RoboCopy command can be run multiple times without causing unnecessary recall to StorSimple.
Troubleshoot and optimize
Speed and success rate of a given RoboCopy run will depend on several factors:
- IOPS on the source and target storage
- the available network bandwidth between source and target
- the ability to quickly process files and folders in a namespace
- the number of changes between RoboCopy runs
- the size and number of files you need to copy
IOPS and bandwidth considerations
In this category, you need to consider abilities of the source storage, the target storage, and the network connecting them. The maximum possible throughput is determined by the slowest of these three components. Make sure your network infrastructure is configured to support optimal transfer speeds to its best abilities.
Caution
While copying as fast as possible is often most desireable, consider the utilization of your local network and NAS appliance for other, often business-critical tasks.
Copying as fast as possible might not be desirable when there's a risk that the migration could monopolize available resources.
- Consider when it's best in your environment to run migrations: during the day, off-hours, or during weekends.
- Also consider networking QoS on a Windows Server to throttle the RoboCopy speed.
- Avoid unnecessary work for the migration tools.
RoboCopy can insert inter-packet delays by specifying the /IPG:n switch where n is measured in milliseconds between RoboCopy packets. Using this switch can help avoid monopolization of resources on both IO constrained devices, and crowded network links.
/IPG:n can't be used for precise network throttling to a certain Mbps. Use Windows Server Network QoS instead. RoboCopy entirely relies on the SMB protocol for all networking needs. Using SMB is the reason why RoboCopy can't influence the network throughput itself, but it can slow down its use.
A similar line of thought applies to the IOPS observed on the NAS. The cluster size on the NAS volume, packet sizes, and an array of other factors influence the observed IOPS. Introducing inter-packet delay is often the easiest way to control the load on the NAS. Test multiple values, for instance from about 20 milliseconds (n=20) to multiples of that number. Once you introduce a delay, you can evaluate if your other apps can now work as expected. This optimization strategy will allow you to find the optimal RoboCopy speed in your environment.
Processing speed
RoboCopy will traverse the namespace it's pointed to and evaluate each file and folder for copy. Every file will be evaluated during an initial copy and during catch-up copies. For example, repeated runs of RoboCopy /MIR against the same source and target storage locations. These repeated runs are useful to minimize downtime for users and apps, and to improve the overall success rate of files migrated.
We often default to considering bandwidth as the most limiting factor in a migration - and that can be true. But the ability to enumerate a namespace can influence the total time to copy even more for larger namespaces with smaller files. Consider that copying 1 TiB of small files will take considerably longer than copying 1 TiB of fewer but larger files, assuming that all other variables remain the same. Therefore, you may experience slow transfer if you're migrating a large number of small files. This is an expected behavior.
The cause for this difference is the processing power needed to walk through a namespace. RoboCopy supports multi-threaded copies through the /MT:n parameter where n stands for the number of threads to be used. So when provisioning a machine specifically for RoboCopy, consider the number of processor cores and their relationship to the thread count they provide. Most common are two threads per core. The core and thread count of a machine is an important data point to decide what multi-thread values /MT:n you should specify. Also consider how many RoboCopy jobs you plan to run in parallel on a given machine.
More threads will copy our 1-TiB example of small files considerably faster than fewer threads. At the same time, the extra resource investment on our 1 TiB of larger files may not yield proportional benefits. A high thread count will attempt to copy more of the large files over the network simultaneously. This extra network activity increases the probability of getting constrained by throughput or storage IOPS.
During a first RoboCopy into an empty target or a differential run with lots of changed files, you are likely constrained by your network throughput. Start with a high thread count for an initial run. A high thread count, even beyond your currently available threads on the machine, helps saturate the available network bandwidth. Subsequent /MIR runs are progressively impacted by processing items. Fewer changes in a differential run mean less transport of data over the network. Your speed is now more dependent on your ability to process namespace items than to move them over the network link. For subsequent runs, match your thread count value to your processor core count and thread count per core. Consider if cores need to be reserved for other tasks a production server may have.
Tip
Rule of thumb: The first RoboCopy run, that will move a lot of data of a higher-latency network, benefits from over-provisioning the thread count (/MT:n). Subsequent runs will copy fewer differences and you are more likely to shift from network throughput constrained to compute constrained. Under these circumstances, it is often better to match the RoboCopy thread count to the actually available threads on the machine. Over-provisioning in that scenario can lead to more context shifts in the processor, possibly slowing down your copy.
Avoid unnecessary work
Avoid large-scale changes in your namespace. For example, moving files between directories, changing properties at a large scale, or changing permissions (NTFS ACLs). Especially ACL changes can have a high impact because they often have a cascading change effect on files lower in the folder hierarchy. Consequences can be:
- extended RoboCopy job run time because each file and folder affected by an ACL change needing to be updated
- reusing data moved earlier may need to be recopied. For instance, more data will need to be copied when folder structures change after files had already been copied earlier. A RoboCopy job can't "play back" a namespace change. The next job must purge the files previously transported to the old folder structure and upload the files in the new folder structure again.
Another important aspect is to use the RoboCopy tool effectively. With the recommended RoboCopy script, you'll create and save a log file for errors. Copy errors can occur - that is normal. These errors often make it necessary to run multiple rounds of a copy tool like RoboCopy. An initial run, say from a NAS to DataBox or a server to an Azure file share. And one or more extra runs with the /MIR switch to catch and retry files that didn't get copied.
You should be prepared to run multiple rounds of RoboCopy against a given namespace scope. Successive runs will finish faster as they have less to copy but are constrained increasingly by the speed of processing the namespace. When you run multiple rounds, you can speed up each round by not having RoboCopy try unreasonably hard to copy everything in a given run. These RoboCopy switches can make a significant difference:
/R:nn = how often you retry to copy a failed file and/W:nn = how many seconds to wait between retries
/R:5 /W:5 is a reasonable setting that you can adjust to your liking. In this example, a failed file will be retried five times, with five-second wait time between retries. If the file still fails to copy, the next RoboCopy job will try again. Often files that failed because they are in use or because of timeout issues might eventually be copied successfully this way.
Windows Server 2022 and RoboCopy LFSM
The RoboCopy switch /LFSM can be used to avoid a RoboCopy job failing with a volume full error. RoboCopy will pause whenever a file copy would cause the destination volume's free space to go below a "floor" value.
Use RoboCopy with Windows Server 2022. Only this version of RoboCopy contains important bug fixes and features that make the switch compatible with additional flags needed in most migrations. For example, compatibility with the /B flag.
/B runs RoboCopy in the same mode that a backup application would use. This switch allows RoboCopy to move files that the current user doesn't have permissions for.
Normally, RoboCopy can be run on the Source, Destination or a third machine.
Important
If you intend to use /LFSM, RoboCopy must be run on the Windows Server 2022 target Azure File Sync server.
Note also that with /LFSM you must also use a local path for the destination, not a UNC path. For example as a destination path you should use E:\Foldername rather than a UNC path like \\ServerName\FolderName.
Caution
The currently available version of RoboCopy on Windows Server 2022 has a bug that causes the pauses to count against the per file error count. Apply the following workaround.
The recommended /R:2 /W:1 flags increase the probability that a file is failed due to an /LFSM induced pause. In this example, a file that wasn't copied after 3 pauses because /LFSM caused the pause, will incorrectly make RoboCopy fail the file. The workaround for this is to use higher values for /R:n and /W:n. A good example is /R:10 /W:1800 (10 retries of 30 minutes each). This should give the Azure File Sync tiering algorithm time to create space on the destination volume.
This bug has been fixed but the fix is not yet publicly available. Check this paragraph for updates on the availability of the fix and how to deploy it.
User cut-over
If you use Azure File Sync, you likely need to create the SMB shares on that Azure File Sync-enabled Windows Server instance that match the shares you had on the StorSimple volumes. You can front-load this step and do it earlier to not lose time here. But you must ensure that before this point, nobody has access to cause changes to the Windows Server instance.
If you have a DFS-N deployment, you can point the DFN-Namespaces to the new server folder locations. If you don't have a DFS-N deployment, and you fronted your 8100 or 8600 appliance locally with a Windows Server instance, you can take that server off the domain. Then domain-join your new Azure File Sync-enabled Windows Server instance. During that process, give the server the same server name and share names as the old server so that cut-over remains transparent for your users, group policy, and scripts.
Learn more about DFS-N.
Phase 6: Deprovision
When you deprovision a resource, you lose access to the configuration of that resource and its data. Deprovisioning can't be undone. Don't proceed until you've confirmed that:
- Your migration is complete.
- There are no dependencies whatsoever on the StorSimple files, folders, or volume backups that you're about to deprovision.
Before you begin, it's a best practice to observe your new Azure File Sync deployment in production for a while. That time gives you the opportunity to fix any problems you might encounter. After you've observed your Azure File Sync deployment for at least a few days, you can begin to deprovision resources in this order:
- Deprovision your StorSimple Data Manager resource via the Azure portal. All of your DTS jobs will be deleted with it. You won't be able to easily retrieve the copy logs. If they're important for your records, retrieve them before you deprovision.
- Make sure that your StorSimple physical appliances have been migrated, and then unregister them. If you aren't sure that they've been migrated, don't proceed. If you deprovision these resources while they're still necessary, you won't be able to recover the data or their configuration.
Optionally you can first deprovision the StorSimple volume resource, which will clean up the data on the appliance. This process can take several days and won't forensically zero out the data on the appliance. If this is important to you, handle disk zeroing separately from the resource deprovisioning and according to your policies. - If there are no more registered devices left in a StorSimple Device Manager, you can proceed to remove that Device Manager resource itself.
- It's now time to delete the StorSimple storage account in Azure. Again, stop and confirm your migration is complete and that nothing and no one depends on this data before you proceed.
- Unplug the StorSimple physical appliance from your data center.
- If you own the StorSimple appliance, you're free to PC Recycle it. If your device is leased, inform the lessor and return the device as appropriate.
Your migration is complete.
Note
Still have questions or encountered any issues?
We're here to help:

Troubleshooting
When using the StorSimple Data Manager migration service, either an entire migration job or individual files may fail for various reasons. The file fidelity section has more details on supported / unsupported scenarios. The following tables list error codes, error details, and where possible, mitigation options.
Job level errors
| Phase | Error | Details / Mitigation |
|---|---|---|
| Backup | Could not find a backup for the parameters specified | The backup selected for the job run is not found at the time of "Estimation" or "Copy". Ensure that the backup is still present in the StorSimple backup catalog. Sometimes automatic backup retention policies delete backups between selecting them for migration and actually running the migration job for this backup. Consider disabling any backup retention schedules before starting a migration. |
| Estimation Configure compute |
Installation of encryption keys failed | Your Service Data Encryption Key is incorrect. Review the encryption key section in this article for more details and help retrieving the correct key. |
| Batch error | It's possible that starting up all the internal infrastructure required to perform a migration runs into an issue. Multiple other services are involved in this process. These problems generally resolve themselves when you attempt to run the job again. | |
| StorSimple Manager encountered an internal error. Wait for a few minutes and then try the operation again. If the issue persists, contact Microsoft Support. (Error code: 1074161829) | This generic error has multiple causes, but one possibility encountered is that the StorSimple device manager reached the limit of 50 appliances. Check if the most recently run jobs in the device manager have suddenly started to fail with this error, which would suggest this is the problem. The mitigation for this particular issue is to remove any offline StorSimple 8001 appliances created and used by the Data Manager Service. You can file a support ticket or delete them manually in the portal. Make sure to only delete offline 8001 series appliances. | |
| Estimating Files | Clone volume job failed | This error most likely indicates that you specified a backup that was somehow corrupted. The migration service can't mount or read it. You can try out the backup manually or open a support ticket. |
| Cannot proceed as volume is in non-NTFS format | Only NTFS volumes, non dedupe enabled, can be used by the migration service. If you have a differently formatted volume, like ReFS or a third-party format, the migration service won't be able to migrate this volume. See the Known limitations section. | |
| Contact support. No suitable partition found on the disk | The StorSimple disk that is supposed to have the volume specified for migration doesn't appear to have a partition for said volume. That is unusual and can indicate a corruption or management mis-alignment. Your only option to further investigate this issue is to file a support ticket. | |
| Timed out | The estimation phase failing with a timeout is typically an issue with either the StorSimple appliance, or the source Volume Backup being slow and sometimes even corrupt. If re-running the backup doesn't work, then filing a support ticket is your best course of action. | |
| Could not find file <path> Could not find a part of the path |
The job definition allows you to provide a source sub-path. This error is shown when that path does not exist. For instance: \Share1 > \Share\Share1 In this example you've specified \Share1 as a sub-path in the source, mapping to another sub-path in the target. However, the source path does not exist (was misspelled?). Note: Windows is case preserving but not case dependent. Meaning specifying \Share1 and \share1 is equivalent. Also: Target paths that don't exist will be automatically created. |
|
| This request is not authorized to perform this operation | This error shows when the source StorSimple storage account or the target storage account with the Azure file share has a firewall setting enabled. You must allow traffic over the public endpoint and not restrict it with further firewall rules. Otherwise the Data Transformation Service will be unable to access either storage account, even if you authorized it. Disable any firewall rules and re-run the job. | |
| Copying Files | The account being accessed does not support HTTP | Disable internet routing on the target storage account or use the Microsoft routing endpoint. |
| The specified share is full | If the target is a premium Azure file share, ensure that you've provisioned sufficient capacity for the share. Temporary over-provisioning is a common practice. |
Item level errors
During the copy phase of a migration job run, individual namespace items (files and folders) can encounter errors. The following table lists the most common errors and suggests mitigation options when possible.
| Phase | Error | Mitigation |
|---|---|---|
| Copy | -2146233088 The server is busy. |
Rerun the job if there are too many failures. If there are only very few errors, you can try running the job again, but often a manual copy of the failed items can be faster. Then resume the migration by skipping to processing the next backup. |
| -2146233088 Operation could not be completed within the specified time. |
Rerun the job if there are too many failures. If there are only very few errors, you can try running the job again, but often a manual copy of the failed items can be faster. Then resume the migration by skipping to processing the next backup. | |
| Upload timed out or copy not started | Rerun the job if there are too many failures. If there are only very few errors, you can try running the job again, but often a manual copy of the failed items can be faster. Then resume the migration by skipping to processing the next backup. | |
| -2146233029 The operation was canceled. |
Rerun the job if there are too many failures. If there are only very few errors, you can try running the job again, but often a manual copy of the failed items can be faster. Then resume the migration by skipping to processing the next backup. | |
| 1920 The file cannot be accessed by the system. |
This is a common error when the migration engine encounters a reparse point, link, or junction. They are not supported. These types of files can't be copied. Review the Known limitations section and the File fidelity section in this article. | |
| -2147024891 Access is denied |
This is an error for files that are encrypted in a way that they can't be accessed on the disk. Files that can be read from disk but simply have encrypted content are not affected and can be copied. Your only option is to copy them manually. You can find such items by mounting the affected volume and running the following command: get-childitem <path> [-Recurse] -Force -ErrorAction SilentlyContinue | Where-Object {$_.Attributes -ge "Encrypted"} | format-list fullname, attributes |
|
| Not a valid Win32 FileTime. Parameter name: fileTime | In this case, the file can be accessed but can't be evaluated for copy because a timestamp the migration engine depends on is either corrupted or was written by an application in an incorrect format. There is not much you can do, because you can't change the timestamp in the backup. If retaining this file is important, perhaps on the latest version (last backup containing this file) you manually copy the file, fix the timestamp, and then move it to the target Azure file share. This option doesn't scale very well but is an option for high-value files where you want to have at least one version retained in your target. | |
| -2146232798 Safe handle has been closed |
Often a transient error. Rerun the job if there are too many failures. If there are only very few errors, you can try running the job again, but often a manual copy of the failed items can be faster. Then resume the migration by skipping to processing the next backup. | |
| -2147024413 Fatal device hardware error |
This is a rare error and not actually reported for a physical device, but rather the 8001 series virtualized appliances used by the migration service. The appliance ran into an issue. Files with this error won't stop the migration from proceeding to the next backup. That makes it hard for you to perform a manual copy or retry the backup that contains files with this error. If the files left behind are very important or there is a large number of files, you may need to start the migration of all backups again. Open a support ticket for further investigation. | |
| Delete (Mirror purging) |
The specified directory is not empty. | This error occurs when the migration mode is set to mirror and the process that removes items from the Azure file share ran into an issue that prevented it from deleting items. Deletion happens only in the live share, not from previous snapshots. The deletion is necessary because the affected files are not in the current backup and thus must be removed from the live share before the next snapshot. There are two options: Option 1: mount the target Azure file share and delete the files with this error manually. Option 2: you can ignore these errors and continue processing the next backup with an expectation that the target isn't identical to source and has some extra items that weren't in the original StorSimple backup. |
| Bad request | This error indicates that the source file has certain characteristics that couldn't be copied to the Azure file share. Most notably there could be invisible control characters in a file name or 1 byte of a double byte character in the file name or file path. You can use the copy logs to get path names, copy the files to a temporary location, rename the paths to remove the unsupported characters, and then robocopy again to the Azure file share. You can then resume the migration by skipping to the next backup to be processed. |
Next steps
- Understand the flexibility of cloud tiering policies.
- Enable Azure Backup on your Azure file shares to schedule snapshots and define backup retention schedules.
- If you see in the Azure portal that some files are permanently not syncing, review the Troubleshooting guide for steps to resolve these issues.