Scans and ingestion in Microsoft Purview
This article provides an overview of the Scanning and Ingestion features in Microsoft Purview. These features connect your Microsoft Purview account to your sources to populate the data map and data catalog so you can begin exploring and managing your data through Microsoft Purview.
- Scanning captures metadata from data sources and brings it to Microsoft Purview.
- Ingestion processes metadata and stores it in the data catalog from both:
- Data source scans - scanned metadata is added to the Microsoft Purview Data Map.
- Lineage connections - transformation resources add metadata about their sources, outputs, and activities to the Microsoft Purview Data Map.
Scanning
After data sources are registered in your Microsoft Purview account, the next step is to scan the data sources. The scanning process establishes a connection to the data source and captures technical metadata like names, file size, columns, and so on. It also extracts schema for structured data sources, applies classifications on schemas, and applies sensitivity labels if your Microsoft Purview Data Map is connected to a Microsoft Purview compliance portal. The scanning process can be triggered to run immediately or can be scheduled to run on a periodic basis to keep your Microsoft Purview account up to date.
For each scan, there are customizations you can apply so that you're only scanning information you need, rather than the whole source.
Choose an authentication method for your scans
Microsoft Purview is secure by default. No passwords or secrets are stored directly in Microsoft Purview, so you’ll need to choose an authentication method for your sources. There are several possible ways to authenticate your Microsoft Purview account, but not all methods are supported for each data source.
- Managed Identity
- Service Principal
- SQL Authentication
- Windows Authentication
- Role ARN
- Delegated Authentication
- Consumer Key
- Account Key or Basic Authentication
Whenever possible, a Managed Identity is the preferred authentication method because it eliminates the need for storing and managing credentials for individual data sources. This can greatly reduce the time you and your team spend setting up and troubleshooting authentication for scans. When you enable a managed identity for your Microsoft Purview account, an identity is created in Microsoft Entra ID and is tied to the lifecycle of your account.
Scope your scan
When scanning a source, you have a choice to scan the entire data source or choose only specific entities (folders/tables) to scan. Available options depend on the source you're scanning, and can be defined for both one-time and scheduled scans.
For example, when creating and running a scan for an Azure SQL Database, you can choose which tables to scan, or select the entire database.
For each entity (folder/table), there will be three selection states: fully selected, partially selected and not selected. In the example below, if you select “Department 1” on the folder hierarchy, “Department 1” is considered as fully selected. The parent entities for “Department 1” like “Company” and “example” are considered as partially selected as there are other entities under the same parent not having been selected, for example “Department 2”. Different icons will be used on UI for entities with different selection states.
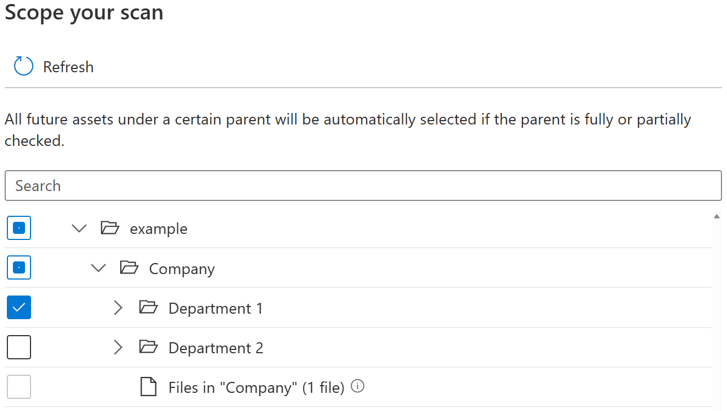
After you run the scan it’s likely that there will be new assets added in the source system. By default the future assets under a certain parent will be automatically selected if the parent is fully or partially selected when you run the scan again. In the example above, after you select “Department 1” and run the scan, any new assets under folder “Department 1” or under “Company” and “example” will be included when you run the scan again.
A toggle button is introduced for users to control the automatic inclusion for new assets under partially selected parent. By default the toggle will be turned off and the automatic inclusion behavior for partially selected parent is disabled. In the same example with the toggle turned off, any new assets under partially selected parents like “Company” and “example” won't be included when you run the scan again, only new assets under “Department 1” will be included in future scan.
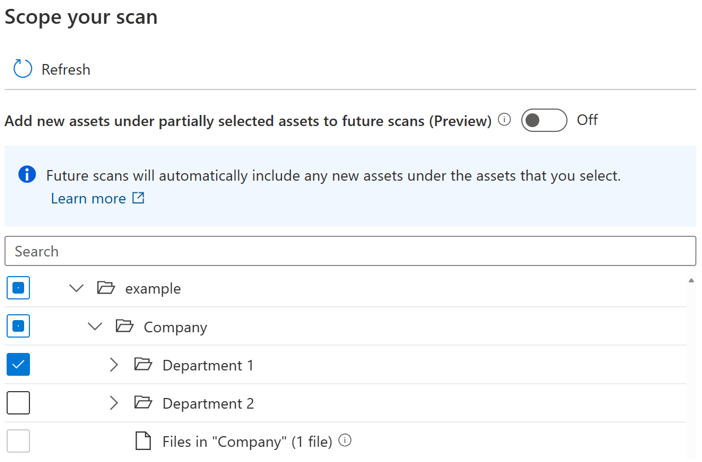
If the toggle button is turned on, the new assets under a certain parent will be automatically selected if the parent is fully or partially selected when you run the scan again. The inclusion behavior will be the same as before the toggle button is introduced.
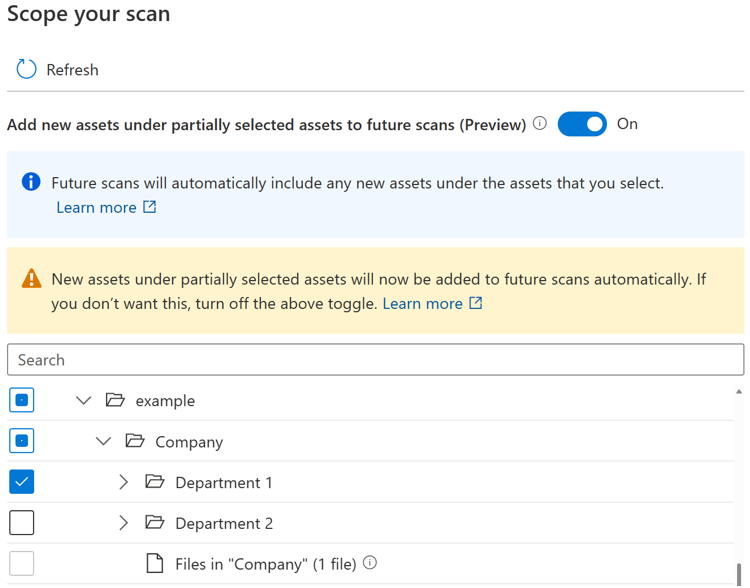
Note
- The availability of the toggle button will depend on the data source type. Currently it's available in public preview for sources including Azure Blob Storage, Azure Data Lake Storage Gen 1, Azure Data Lake Storage Gen 2, Azure Files and Azure Dedicated SQL pool (formerly SQL DW).
- For any scans created or scheduled before the toggle button is introduced, the toggle state is set as on and can’t be changed. For any scans created or scheduled after the toggle button is introduced, the toggle state can’t be changed after the scan is saved. You need to create a new scan to change the toggle state.
- When the toggle button is turned off, for sources of storage type like Azure Data Lake Storage Gen 2 it may take up to 4 hours before the browse by source type experience becomes fully available after your scan job is completed.
Known limitations
When the toggle button is turned off:
- The file entities under a partially selected parent won't be scanned.
- If all existing entities under a parent are explicitly selected, the parent will be considered as fully selected and any new assets under the parent will be included when you run the scan again.
Customize scan level
In Microsoft Purview Data Map terminology, there are three different levels of scanning based on the metadata scope and functionalities:
- L1 scan: Extracts basic information and metadata like file name, size, and fully qualified name
- L2 scan: Extracts schema for structured file types and database tables
- L3 scan: Extracts schema where applicable and subjects the sampled file to the system and custom classification rules
When you set up a new scan or edit an existing scan, you can customize the scan level for scanning data sources which have already supported the scan level configuration.
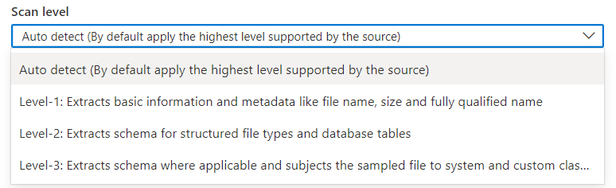
By default, the “Auto detect” will be selected which means Microsoft Purview will apply the highest scan level available for this data source. Take Azure SQL Database as an example, the “Auto detect” will be resolved as “Level-3” when the scan is executed as the data source has already supported classification in Microsoft Purview. The scan level in the scan run detail will show the actual level applied.
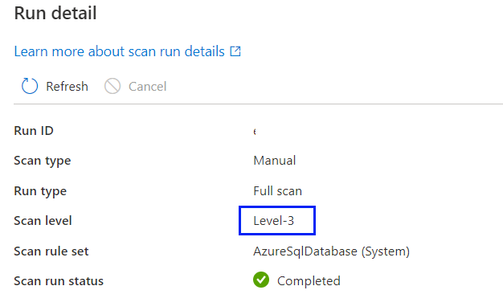
For all scan runs in the scan history which were completed before customizing scan level as a new feature is introduced, by default the scan level will be set and displayed as “Auto detect”.
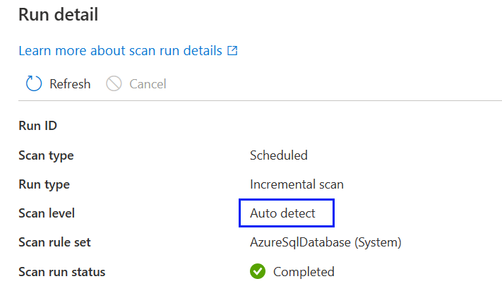
- When a higher scan level becomes available for a data source, the saved or scheduled scans that have scan level set to “Auto detect” will automatically apply the new scan level. For example, if classification as a new feature is enabled for a given data source, all existing scans on this data source will apply classification automatically.
- The scan level setting will show in the scan monitoring interface for each scan run.
- If “Level-1” is selected, scanning will only return basic technical metadata like asset name, asset size, modified timestamp etc. based on the existing metadata availability of a specific data source. For Azure SQL Database, asset entities like tables will be created in Microsoft Purview Data Map but without table schema extraction. (Note: users can still see the table schema via live view if they have necessary permissions in the source system).
- If “Level-2” is selected, scanning will return table schemas as well as basic technical metadata, but data sampling and classification won't be performed. For Azure SQL Database, table asset entities will have table schema captured without classification information.)
- If “Level-3” is selected, scanning will perform the data sampling and classification. This is a standard configuration for Azure SQL Database scanning before scan level as a new feature is introduced.
- If a scheduled scan is set to a lower scan level and later modified to a higher scan level, the next scan run will automatically perform a full scan and all existing data assets from the data source will be updated with metadata introduced by a higher scan level setting. For example, when a scheduled scan set with “Level-2” on an Azure SQL Database is changed to “Level-3”, the next scan run will be a full scan and all existing Azure SQL Database table/view assets will be updated with classification information, and all scans thereafter will resume as incremental scans set with “Level-3”.
- If a scheduled scan is set to a higher scan level and later modified to a lower scan level, the next scan run will continue to perform an incremental scan and all new data assets from the data source will only have metadata introduced by a lower scan level setting. For example, when a scheduled scan set with “Level-3” on an Azure SQL Database is changed to “Level-2”, the next scan run will be an incremental scan and all new Azure SQL Database table/view assets added in Microsoft Purview Data Map will have no classification information. All existing data assets will still keep the classification information generated from the previous scan set with “Level-3”.
Note
- Customizing scan level is currently available for the following data sources: Azure SQL Database, Azure SQL Managed Instance, Azure Cosmos DB for NoSQL, Azure Database for PostgreSQL, Azure Database for MySQL, Azure Data Lake Storage Gen2, Azure Blob Storage, Azure Files, Azure Synapse Analytics, Azure Dedicated SQL pool (formerly SQL DW), Azure Data Explorer, Dataverse, Azure Multiple (Azure Subscription), Azure Multiple (Azure Resource Group), Snowflake, Azure Databricks Unity Catalog
- Currently the feature is only available on Azure IR and Managed VNet IR v2.
Scan rule set
A scan rule set determines the kinds of information a scan will look for when it's running against one of your sources. Available rules depend on the kind of source you're scanning, but include things like the file types you should scan, and the kinds of classifications you need.
There are system scan rule sets already available for many data source types, but you can also create your own scan rule sets to tailor your scans to your organization.
Schedule your scan
Microsoft Purview gives you a choice of scanning daily, weekly or monthly at a specific time you choose. Learn more about the supported schedule options. Daily or weekly scans may be appropriate for data sources with structures that are actively under development or frequently change. Monthly scanning is more appropriate for data sources that change infrequently. Best practice is to work with the administrator of the source you want to scan to identify a time when compute demands on the source are low.
How scans detect deleted assets
A Microsoft Purview catalog is only aware of the state of a data store when it runs a scan. For the catalog to know if a file, table, or container was deleted, it compares the last scan output against the current scan output. For example, suppose that the last time you scanned an Azure Data Lake Storage Gen2 account, it included a folder named folder1. When the same account is scanned again, folder1 is missing. Therefore, the catalog assumes the folder has been deleted.
Tip
Because of how deleted files are detected, multiple successful scans might be needed to detect and resolve deleted assets. If your data catalog isn't registering deletions for a scoped scan, try multiple full scans to resolve the issue.
Detecting deleted files
The logic for detecting missing files works for multiple scans by the same user and by different users. For example, suppose a user runs a one-time scan on a Data Lake Storage Gen2 data store on folders A, B, and C. Later, a different user in the same account runs a different one-time scan on folders C, D, and E of the same data store. Because folder C was scanned twice, the catalog checks it for possible deletions. Folders A, B, D, and E, however, were scanned only once, and the catalog won't check them for deleted assets.
To keep deleted files out of your catalog, it's important to run regular scans. The scan interval is important, because the catalog can't detect deleted assets until another scan is run. So, if you run scans once a month on a particular store, the catalog can't detect any deleted data assets in that store until you run the next scan a month later.
When you enumerate large data stores like Data Lake Storage Gen2, there are multiple ways (including enumeration errors and dropped events) to miss information. A particular scan might miss that a file was created or deleted. So, unless the catalog is certain a file was deleted, it won't delete it from the catalog. This strategy means there can be errors when a file that doesn't exist in the scanned data store still exists in the catalog. In some cases, a data store might need to be scanned two or three times before it catches certain deleted assets.
Note
- Assets that are marked for deletion are deleted after a successful scan. Deleted assets might continue to be visible in your catalog for some time before they are processed and removed.
- Currently, source deletion detection is not supported for the following sources: Azure Databricks, Amazon Redshift, Cassandra, Dataverse, Db2, Erwin, Google BigQuery, Hive Metastore, Looker, MongoDB, MySQL, Oracle, PostgreSQL, Power BI, Qlik Sense, Salesforce, SAP BW, SAP ECC, SAP HANA, SAP S/4HANA, Snowflake, Tableau, and Teradata. When object is deleted from the data source, the subsequent scan won't automatically remove the corresponding asset in Microsoft Purview.
Ingestion
Ingestion is the process responsible for populating the data map with metadata gathered through its various processes.
Ingestion from scans
The technical metadata or classifications identified by the scanning process are then sent to ingestion. Ingestion analyses the input from scan, applies resource set patterns, populates available lineage information, and then loads the data map automatically. Assets/schemas can be discovered or curated only after ingestion is complete. So, if your scan is completed but you haven't seen your assets in the data map or catalog, you'll need to wait for the ingestion process to finish.
Ingestion from lineage connections
Resources like Azure Data Factory and Azure Synapse can be connected to Microsoft Purview to bring data source and lineage information into your Microsoft Purview Data Map. For example, when a copy pipeline runs in an Azure Data Factory that has been connected to Microsoft Purview, metadata about the input sources, the activity, and the output sources are ingested in Microsoft Purview and the information is added to the data map.
If a data source has already been added to the data map through a scan, lineage information about the activity will be added to the existing source. If the data source hasn't yet been added to the data map, the lineage ingestion process will add it to the root collection with its lineage information.
For more information about the available lineage connections, see the lineage user guide.
Next steps
For more information, or for specific instructions for scanning sources, follow the links below.
- To understand resource sets, see our resource sets article.
- How to govern an Azure SQL Database
- Lineage in Microsoft Purview