สร้างบริการระบบคลาวด์ที่ทนต่อข้อบกพร่อง
- 13 นาที
ศูนย์ข้อมูลและการจัดการบริการคลาวด์ส่วนใหญ่เกี่ยวข้องกับการออกแบบและการรักษาบริการที่เชื่อถือได้ตามชิ้นส่วนที่ไม่น่าเชื่อถือ รูปภาพต่อไปนี้แสดงส่วนของการฝึกอบรมสําหรับพนักงานใหม่ และควรมีแนวคิดเกี่ยวกับความล้มเหลวจํานวนมาก (และชนิด) ที่ประสบเป็นประจําในศูนย์ข้อมูลขนาดใหญ่

รูปที่ 2: ปัญหาความน่าเชื่อถือดังที่แสดงในงานนําเสนอการฝึกอบรม
ความล้มเหลวในระบบเกิดขึ้นเนื่องจากสถานะที่ไม่ถูกต้องที่เกิดจากระบบเนื่องจากข้อบกพร่อง โดยทั่วไประบบจะพัฒนาข้อบกพร่องของหนึ่งในประเภทต่อไปนี้:
- ข้อบกพร่องชั่วคราว: ข้อผิดพลาดชั่วคราวในระบบที่แก้ไขด้วยตนเองตามเวลา
- ข้อบกพร่องถาวร: ข้อบกพร่องที่ไม่สามารถกู้คืนจากและโดยทั่วไปต้องการเปลี่ยนทรัพยากร
- ข้อบกพร่องเป็นระยะ ๆ: ข้อบกพร่องที่เกิดขึ้นเป็นระยะ ๆ ในระบบ
ข้อบกพร่องอาจส่งผลกระทบต่อความพร้อมใช้งานของระบบโดยการนําบริการหรือประสิทธิภาพของฟังก์ชันการทํางานของระบบมาใช้ ระบบที่ทนต่อข้อบกพร่องมีความสามารถในการทํางานได้แม้ในกรณีที่ระบบล้มเหลว บนคลาวด์ ระบบที่ทนต่อข้อบกพร่องมักจะคิดว่าเป็นระบบที่ให้บริการในลักษณะที่สอดคล้องกันโดยมีเวลาหยุดทํางานต่ํากว่าข้อตกลงระดับบริการ (SLA)
ทําไมความคลาดเคลื่อนของความผิดพลาดจึงสําคัญ?
ความล้มเหลวในระบบที่สําคัญสําหรับภารกิจขนาดใหญ่อาจส่งผลให้เกิดความเสียหายทางการเงินที่สําคัญแก่ทุกฝ่ายที่เกี่ยวข้อง ลักษณะของระบบการประมวลผลแบบคลาวด์คือพวกเขามีสถาปัตยกรรมแบบชั้น ดังนั้น ข้อบกพร่องในหนึ่งเลเยอร์ของทรัพยากรระบบคลาวด์สามารถทริกเกอร์ความล้มเหลวในเลเยอร์อื่น ๆ ด้านบน หรือซ่อนการเข้าถึงเลเยอร์ด้านล่าง
ตัวอย่างเช่น ข้อบกพร่องในคอมโพเนนต์ฮาร์ดแวร์ของระบบอาจส่งผลต่อการดําเนินการทั่วไปของแอปพลิเคชัน SaaS (ซอฟต์แวร์ที่เป็นบริการ) ที่ทํางานบนเครื่องเสมือนโดยใช้ทรัพยากรที่ผิดพลาด ข้อบกพร่องในระบบที่เลเยอร์ใด ๆ มีความสัมพันธ์โดยตรงกับ SLA ระหว่างผู้ให้บริการในแต่ละระดับ
หน่วยวัดเชิงรุก
ผู้ให้บริการใช้มาตรการหลายอย่างเพื่อออกแบบระบบในลักษณะเฉพาะเพื่อหลีกเลี่ยงปัญหาที่ทราบหรือความล้มเหลวที่คาดการณ์ได้
การทําโปรไฟล์และการทดสอบ
การโหลดและการทดสอบปัญหาทรัพยากรบนคลาวด์เพื่อทําความเข้าใจสาเหตุที่เป็นไปได้ของความล้มเหลวเป็นสิ่งสําคัญเพื่อให้แน่ใจว่าบริการพร้อมใช้งาน การทําโปรไฟล์เมตริกเหล่านี้ช่วยในการออกแบบระบบที่สามารถรับภาระที่คาดไว้ได้สําเร็จโดยไม่มีลักษณะการทํางานที่ไม่สามารถคาดเดาได้
การเตรียมใช้งานเกิน
การเตรียมใช้งานเกินคือแนวทางปฏิบัติของการปรับใช้ทรัพยากรในปริมาณที่มีขนาดใหญ่กว่าการใช้ทรัพยากรที่คาดการณ์ทั่วไปในเวลาที่กําหนด ในสถานการณ์ที่ความต้องการที่แน่นอนของระบบไม่สามารถคาดการณ์ได้ ทรัพยากรที่จัดเตรียมไว้มากเกินไปอาจเป็นกลยุทธ์ที่ยอมรับได้เพื่อจัดการกับการเพิ่มขึ้นอย่างรวดเร็วทันทีทันใดที่ไม่คาดคิดในการโหลด
พิจารณาเป็นตัวอย่างแพลตฟอร์มอีคอมเมิร์ซที่มีโหลดที่สอดคล้องกันโดยเฉลี่ยบนเซิร์ฟเวอร์ตลอดทั้งปี แต่ในช่วงวันหยุดความคาดหวังคือรูปแบบโหลดจะดีดขึ้นอย่างรวดเร็ว ในช่วงเวลาสูงสุดเหล่านี้ขอแนะนําให้จัดหาทรัพยากรเพิ่มเติมตามข้อมูลในอดีตสําหรับการใช้งานสูงสุด การจราจรที่เพิ่มขึ้นอย่างรวดเร็วมักเป็นเรื่องยากที่จะรองรับได้ในระยะเวลาอันสั้น ดังที่อภิปรายในส่วนต่อ ๆ ไป มีค่าใช้จ่ายที่เกี่ยวข้องกับการปรับมาตราส่วนแบบไดนามิกซึ่งเกี่ยวข้องกับขั้นตอนที่ใช้เวลานานในการตรวจหาการเปลี่ยนแปลงในรูปแบบโหลดและการจัดหาทรัพยากรเพิ่มเติมเพื่อรองรับการโหลดใหม่ ทั้งสองขั้นตอนเหล่านั้นจะต้องใช้เวลา เวลานี้ล่าช้าในการปรับปรุงอาจเพียงพอที่จะครอบงําและเมื่อเกิดความผิดพลาดที่แย่ที่สุดระบบหรือลดคุณภาพของบริการได้ดีที่สุด
การเตรียมใช้งานมากเกินไปยังเป็นกลยุทธ์ที่ใช้ในการป้องกัน DoS (ปฏิเสธของบริการ) หรือการโจมตี DDoS (กระจาย DoS) ซึ่งเป็นเมื่อผู้โจมตีสร้างคําขอที่ออกแบบมาเพื่อครอบงําระบบโดยการขว้างปริมาณการใช้งานจํานวนมากที่มันพยายามทําให้ระบบล้มเหลว การโจมตีจะใช้เวลาสักครู่ในการตรวจหาระบบและใช้มาตรการแก้ไขเสมอ ในขณะที่กําลังทําการวิเคราะห์รูปแบบคําขอดังกล่าว ระบบกําลังถูกโจมตีอยู่แล้วและจําเป็นต้องสามารถรองรับปริมาณการใช้งานที่เพิ่มขึ้นจนกว่าจะสามารถใช้กลยุทธ์การลดความเสี่ยงได้
แบบ จำลอง
คอมโพเนนต์ระบบที่สําคัญสามารถทําซ้ําได้โดยใช้คอมโพเนนต์ฮาร์ดแวร์และซอฟต์แวร์เพิ่มเติมเพื่อจัดการความล้มเหลวในส่วนของระบบโดยไม่แสดงความล้มเหลวของระบบโดยที่ระบบทั้งหมดล้มเหลว การจําลองแบบมีกลยุทธ์พื้นฐานสองอย่าง:
- การจําลองแบบที่ใช้งานอยู่ ซึ่งทรัพยากรที่จําลองแบบแล้วทั้งหมดยังทํางานอยู่พร้อมๆ กัน และตอบสนองและประมวลผลคําขอทั้งหมด ซึ่งหมายความว่าสําหรับคําขอของไคลเอ็นต์ใด ๆ ทรัพยากรทั้งหมดได้รับคําขอเดียวกัน ทรัพยากรทั้งหมดจะตอบสนองต่อคําขอเดียวกัน และลําดับของคําขอรักษาสถานะทั่วทั้งทรัพยากรทั้งหมด
- การจําลองแบบพาสซีฟ ซึ่งมีเฉพาะคําขอกระบวนการหน่วยหลักและหน่วยรองเท่านั้นที่จะรักษาสถานะและเข้าควบคุมเมื่อหน่วยหลักล้มเหลว ไคลเอ็นต์จะอยู่ในการติดต่อกับทรัพยากรหลัก เท่านั้น ซึ่งจะถ่ายทอดการเปลี่ยนแปลงสถานะไปยังทรัพยากรรองทั้งหมด ข้อเสียของการจําลองแบบพาสซีฟคืออาจมีคําขอทิ้งหรือ QoS ที่ลดลงในการเปลี่ยนจากอินสแตนซ์หลักเป็นอินสแตนซ์รอง
นอกจากนี้ยังมีกลยุทธ์แบบไฮบริดที่เรียกว่า กึ่งที่ใช้งาน ซึ่งคล้ายกับกลยุทธ์ที่ใช้งานอยู่มาก ความแตกต่างคือมีเพียงผลลัพธ์ของทรัพยากรหลักเท่านั้นที่จะแสดงไปยังไคลเอ็นต์ เอาต์พุตของทรัพยากรรองถูกระงับและบันทึก และพร้อมที่จะสลับใหม่ทันทีที่เกิดความล้มเหลวของทรัพยากรหลัก รูปภาพต่อไปนี้แสดงความแตกต่างระหว่างกลยุทธ์การจําลองแบบ
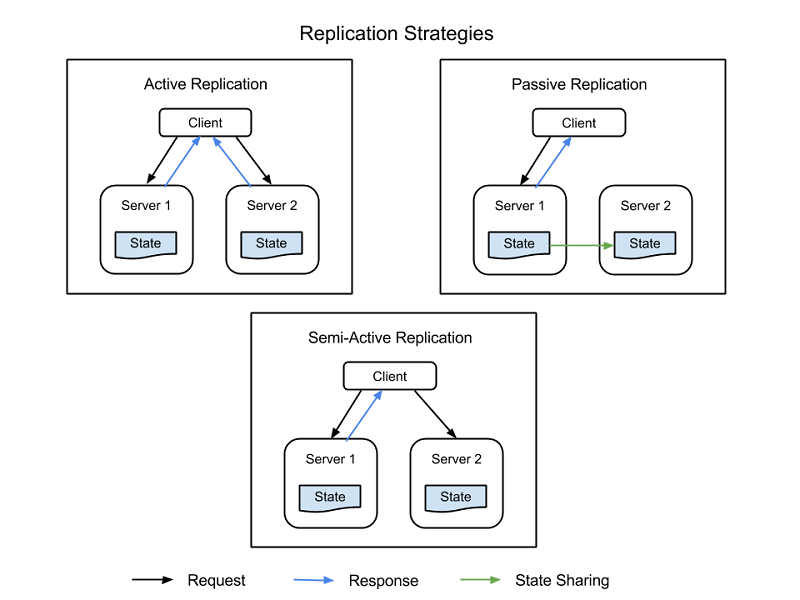
รูปที่ 3: กลยุทธ์การจําลองแบบ
ปัจจัยสําคัญที่ควรพิจารณาในการจําลองแบบคือจํานวนของทรัพยากรรองที่จะใช้ แม้ว่าสิ่งนี้จะแตกต่างจากแอปพลิเคชันไปยังแอปพลิเคชันตามความสําคัญของระบบ แต่การจําลองแบบเป็นทางการ 3 ระดับ:
- N+1: โดยทั่วไปแล้วหมายความว่า สําหรับแอปพลิเคชันที่จําเป็นต้องมีโหนด N เพื่อให้ทํางานได้อย่างถูกต้อง ทรัพยากรเพิ่มเติมหนึ่งรายการถูกเตรียมใช้งานเป็นระบบที่ปลอดภัยต่อความล้มเหลว
- 2N: ในระดับนี้ จะมีโหนดพิเศษหนึ่งโหนดสําหรับแต่ละโหนดที่จําเป็นสําหรับฟังก์ชันปกติถูกเตรียมใช้งานเป็นระบบความปลอดภัยแบบ fail-safe
- 2N + 1: ในระดับนี้ อีกโหนดหนึ่งต้องการโหนดพิเศษสําหรับแต่ละโหนดที่จําเป็นสําหรับฟังก์ชันปกติและโหนดโดยรวมอีกหนึ่งโหนดถูกเตรียมใช้งานเป็นความปลอดภัยแบบ fail-safe
เปิดใช้งานหน่วยวัดใหม่
นอกเหนือจากการวัดผลเชิงทํานายแล้ว ระบบยังสามารถใช้มาตรการตอบสนองและจัดการกับความล้มเหลวเมื่อเกิด:
การตรวจสอบและการตรวจสอบ
ทรัพยากรทั้งหมดได้รับการตรวจสอบอย่างต่อเนื่องเพื่อตรวจสอบพฤติกรรมที่ไม่สามารถคาดเดาได้หรือการสูญเสียทรัพยากร ยึดตามข้อมูลการตรวจสอบ กลยุทธ์การกู้คืนหรือการกําหนดค่าใหม่ถูกออกแบบมาเพื่อรีสตาร์ตทรัพยากรหรือนําทรัพยากรใหม่มาใช้ การตรวจสอบสามารถช่วยในการระบุข้อบกพร่องในระบบได้ ความผิดพลาดที่ทําให้บริการไม่สามารถใช้งานได้เรียกว่าความผิดพลาดและที่ทําให้เกิดปัญหาผิดปกติ/ไม่ถูกต้องในระบบเรียกว่าข้อบกพร่องไบแซนไทน์
มีกลยุทธ์การตรวจสอบหลายอย่างที่ใช้ในการตรวจสอบข้อผิดพลาดภายในระบบ สองกลวิธีเหล่านี้คือ:
- Ping-echo: บริการการตรวจสอบจะถามแต่ละทรัพยากรสําหรับรัฐ และจะได้รับหน้าต่างเวลาในการตอบสนอง
- Heartbeat: แต่ละอินสแตนซ์ส่งสถานะไปยังบริการตรวจสอบอย่างสม่ําเสมอโดยไม่มีทริกเกอร์ใด ๆ
การตรวจสอบข้อบกพร่องของไบแซนไทน์มักขึ้นอยู่กับคุณสมบัติของบริการที่มีให้ ระบบการตรวจสอบสามารถตรวจสอบเมตริกพื้นฐาน เช่น เวลาแฝง การใช้งาน CPU และการใช้หน่วยความจํา และตรวจสอบค่าที่คาดไว้เพื่อดูว่าคุณภาพของบริการลดลงหรือไม่ นอกจากนี้ บันทึกการควบคุมเฉพาะแอปพลิเคชันมักจะเก็บไว้ในจุดดําเนินการบริการที่สําคัญแต่ละจุดและวิเคราะห์เป็นระยะ ๆ เพื่อดูว่าบริการทํางานอย่างถูกต้องตลอดเวลา (หรือไม่ว่าจะมีความล้มเหลวของฉีดในระบบ)
จุดตรวจสอบและรีสตาร์ท
แบบจําลองการเขียนโปรแกรมหลายรูปแบบในคลาวด์ใช้กลยุทธ์จุดตรวจสอบซึ่งสถานะจะถูกบันทึกไว้ในหลายขั้นตอนของการดําเนินการเพื่อให้สามารถกู้คืนไปยังจุดตรวจสอบที่บันทึกไว้ล่าสุด ในแอปพลิเคชันการวิเคราะห์ข้อมูล มักจะมีงานกระจายแบบขนานที่ทํางานนานที่ทํางานบนเทราไบต์ของชุดข้อมูลเพื่อดึงข้อมูล เนื่องจากงานเหล่านี้ถูกดําเนินการในหลายกลุ่มการดําเนินการขนาดเล็ก แต่ละขั้นตอนในการดําเนินการของโปรแกรมสามารถบันทึกสถานะโดยรวมของการดําเนินการเป็นจุดตรวจสอบ ณ จุดที่ล้มเหลวซึ่งโหนดแต่ละโหนดไม่สามารถทํางานให้เสร็จสมบูรณ์ได้การดําเนินการสามารถรีสตาร์ทจากจุดตรวจสอบก่อนหน้า ความท้าทายที่ใหญ่ที่สุดในขณะที่ระบุจุดตรวจสอบที่ถูกต้องเพื่อย้อนกลับไปคือเมื่อกระบวนการขนานกําลังแชร์ข้อมูล ความล้มเหลวในกระบวนการหนึ่งอาจทําให้เกิดการย้อนกลับแบบเรียงซ้อนในกระบวนการอื่น เนื่องจากจุดตรวจสอบที่ทําในกระบวนการนั้นอาจเป็นผลมาจากข้อบกพร่องในข้อมูลที่ใช้ร่วมกันโดยกระบวนการล้มเหลว คุณจะได้เรียนรู้เพิ่มเติมเกี่ยวกับความคลาดเคลื่อนของข้อบกพร่องสําหรับแบบจําลองการเขียนโปรแกรมในโมดูลถัดไป
กรณีศึกษาในการทดสอบความยืดหยุ่น
บริการระบบคลาวด์จะต้องสร้างขึ้นด้วยความอดทนซ้ําและความบกพร่องในใจเนื่องจากไม่มีองค์ประกอบเดียวของระบบแบบกระจายขนาดใหญ่ที่สามารถรับประกันความพร้อมใช้งาน% 100 รายการหรือช่วงเวลาพร้อมใช้งาน
ความล้มเหลวทั้งหมด (รวมถึงความล้มเหลวของการขึ้นต่อกันในโหนดแร็ค ศูนย์ข้อมูล หรือการปรับใช้ซ้ําซ้อนตามภูมิภาค) จะต้องได้รับการจัดการอย่างนุ่มนวลโดยไม่กระทบต่อระบบทั้งหมด การทดสอบความสามารถของระบบในการจัดการความล้มเหลวที่รุนแรงเป็นสิ่งสําคัญ เนื่องจากบางครั้งเวลาหยุดทํางานหรือการลดประสิทธิภาพของบริการอาจก่อให้เกิดความเสียหายหลายร้อยพันดอลลาร์หากไม่ใช่ล้านดอลลาร์ในการสูญเสียรายได้
การทดสอบความล้มเหลวด้วยปริมาณการใช้งานจริงจะต้องทําเป็นประจําเพื่อให้ระบบแข็งตัวและสามารถรับมือได้เมื่อเกิดเหตุขัดข้องที่ไม่ได้วางแผนไว้ มีระบบต่าง ๆ ที่สร้างขึ้นเพื่อทดสอบความยืดหยุ่น หนึ่งชุดการทดสอบดังกล่าว Simian Army สร้างขึ้นโดย Netflix
Simian Army ประกอบด้วยบริการต่าง ๆ (เรียกว่าลิง ) ในระบบคลาวด์เพื่อสร้างความล้มเหลวหลายประเภท ตรวจจับสภาพผิดปกติ และทดสอบความสามารถของระบบเพื่อเอาชีวิตรอด เป้าหมายคือการรักษาระบบคลาวด์ให้ปลอดภัยและพร้อมใช้งานสูง ลิงที่พบในกองทัพไซเมียนบางส่วนคือ:
- ลิง Chaos: เครื่องมือที่สุ่มเลือกอินสแตนซ์การผลิตและปิดใช้งานเพื่อให้แน่ใจว่าระบบคลาวด์มีความล้มเหลวประเภททั่วไปโดยไม่มีผลกระทบใด ๆ กับลูกค้า Netflix อธิบายว่า Chaos Monkey เป็น "แนวคิดในการปล่อยลิงป่าด้วยอาวุธในศูนย์ข้อมูล (หรือภูมิภาคคลาวด์) เพื่อยิงตัวอย่างแบบสุ่มและเคี้ยวผ่านสายเคเบิล - ทั้งหมดในขณะที่เรายังคงให้บริการลูกค้าของเราโดยไม่หยุดชะงัก" การทดสอบด้วยการตรวจสอบโดยละเอียดนี้สามารถเปิดเผยความอ่อนแอได้หลายรูปแบบในระบบและกลยุทธ์การกู้คืนอัตโนมัติสามารถสร้างขึ้นตามผลลัพธ์
- ลิงเวลาแฝง: บริการที่ทําให้เกิดความล่าช้าระหว่างการสื่อสาร RESTful ของลูกค้าและเซิร์ฟเวอร์ที่แตกต่างกันจําลองการลดประสิทธิภาพของบริการและการหยุดทํางาน
- Doctor Monkey: บริการที่ค้นหาอินสแตนซ์ที่มีลักษณะการทํางานที่ใช้งานได้ไม่เหมาะสม (เช่น การโหลด CPU) และลบออกจากบริการ ซึ่งช่วยให้เจ้าของบริการทราบเหตุผลของปัญหาและในที่สุดจะยุติอินสแตนซ์
- Chaos gorilla: บริการที่สามารถจําลองการสูญเสียโซนความพร้อมใช้งานทั้งหมดของ AWS ได้ การดําเนินการนี้จะใช้เพื่อทดสอบว่าบริการจะปรับฟังก์ชันการทํางานระหว่างโซนที่เหลือให้โดยอัตโนมัติโดยไม่มีผลกระทบที่ผู้ใช้มองเห็นได้ หรือการดําเนินการด้วยตนเอง