วิธีจัดการกับเวลาแฝงหาง
- 13 นาที
เราได้กล่าวถึงเทคนิคการปรับให้เหมาะสมหลายเทคนิคที่ใช้ในระบบคลาวด์เพื่อลดเวลาแฝงแล้ว หน่วยวัดที่เราศึกษาบางส่วนรวมถึงการปรับมาตราส่วนทรัพยากรในแนวนอนหรือแนวตั้ง และใช้ตัวปรับสมดุลโหลดเพื่อกําหนดเส้นทางคําขอไปยังทรัพยากรที่พร้อมใช้งานที่ใกล้ที่สุด หน้านี้ระบุได้ลึกซึ้งมากขึ้นว่าทําไมในศูนย์ข้อมูลขนาดใหญ่หรือแอปพลิเคชันระบบคลาวด์ สิ่งสําคัญคือการลดเวลาแฝงสําหรับคําขอทั้งหมดและไม่เพียงแต่ปรับให้เหมาะสมสําหรับกรณีทั่วไปเท่านั้น เราจะศึกษาว่าแม้แต่ค่าผิดปกติของเวลาแฝงสูงไม่กี่ค่าสามารถลดประสิทธิภาพที่สังเกตได้ของระบบขนาดใหญ่อย่างมีนัยสําคัญได้อย่างไร หน้านี้ยังครอบคลุมเทคนิคต่าง ๆ ในการสร้างบริการที่มีการตอบสนองเวลาแฝงต่ําที่สามารถคาดการณ์ได้ แม้ว่าแต่ละคอมโพเนนต์ไม่รับประกันสิ่งนี้ นี่เป็นปัญหาที่สําคัญอย่างยิ่งสําหรับแอปพลิเคชันแบบโต้ตอบที่มีเวลาแฝงที่ต้องการสําหรับการโต้ตอบต่ํากว่า 100 มิลลิวินาที
เวลาแฝงหางคืออะไร
แอปพลิเคชันระบบคลาวด์ส่วนใหญ่เป็นระบบแบบกระจายขนาดใหญ่ที่มักจะพึ่งพาการทํางานแบบขนานเพื่อลดเวลาแฝง เทคนิคทั่วไปคือการกระจายคําขอที่ได้รับที่โหนดราก (ตัวอย่างเช่น เว็บเซิร์ฟเวอร์ front-end) ไปยังโหนดปลายสุด (เซิร์ฟเวอร์คํานวณส่วนหลัง) จํานวนมาก การปรับปรุงประสิทธิภาพการทํางานนั้นขับเคลื่อนโดยความขนานของการคํานวณแบบกระจาย และยังต้องหลีกเลี่ยงค่าใช้จ่ายในการย้ายข้อมูลราคาแพงมากอีกด้วย เราเพียงแค่ย้ายการคํานวณไปยังตําแหน่งที่จัดเก็บข้อมูล แน่นอนว่าโหนดใบไม้แต่ละโหนดพร้อมกันดําเนินการในหลายร้อยหรือหลายพันคําขอแบบขนาน
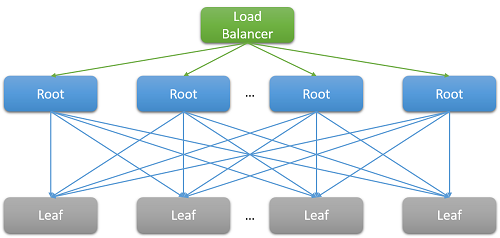
รูปที่ 7: เวลาแฝงเนื่องจาก แบบแนวกว้าง
ลองพิจารณาตัวอย่างการค้นหาภาพยนตร์ใน Netflix เมื่อผู้ใช้เริ่มพิมพ์ในกล่องค้นหา การดําเนินการนี้จะสร้างเหตุการณ์แบบขนานหลายรายการจากเว็บเซิร์ฟเวอร์ราก อย่างน้อยที่สุด เหตุการณ์เหล่านี้ประกอบด้วยคําขอต่อไปนี้:
- ในการเติมข้อความอัตโนมัติ เพื่อคาดการณ์การค้นหาโดยยึดตามแนวโน้มในอดีตและโปรไฟล์ของผู้ใช้
- ไปยังกลไกการแก้ไข ซึ่งพบข้อผิดพลาดในคิวรีที่พิมพ์ตามแบบจําลองภาษาที่ปรับเปลี่ยนอย่างต่อเนื่อง
- ผลการค้นหาแต่ละรายการคําองค์ประกอบของคิวรีแบบหลายคําซึ่งจะต้องรวมตามอันดับและความเกี่ยวข้องของภาพยนตร์
- การประมวลผลหลังและการกรองผลลัพธ์เพิ่มเติมเพื่อให้ตรงตามการกําหนดลักษณะ "การค้นหาที่ปลอดภัย" ของผู้ใช้
ตัวอย่างดังกล่าวเป็นเรื่องธรรมดามาก คําขอ Facebook เดียวเป็นที่รู้จักกันในการติดต่อเซิร์ฟเวอร์ memcached หลายพันในขณะที่การค้นหา Bing เดียวมักจะติดต่อผ่านเซิร์ฟเวอร์ดัชนีหมื่นรายการ
เห็นได้ชัดว่าความจําเป็นสําหรับมาตราส่วนได้นําไปสู่พัดลมขนาดใหญ่ที่ด้านหลังส่วนท้ายสําหรับแต่ละคําขอที่ให้บริการโดยส่วนหน้า สําหรับบริการที่คาดว่าจะเป็น "ตอบสนอง" เพื่อรักษาฐานผู้ใช้ไว้ วิทยาการศึกษาสํานึกแสดงให้เห็นว่าจะตอบสนองภายใน 100 มิลลิวินาที เนื่องจากจํานวนเซิร์ฟเวอร์ที่ต้องใช้ในการแก้ไขคิวรีเพิ่มขึ้น เวลาโดยรวมมักขึ้นอยู่กับการตอบสนองที่แย่ที่สุดจากโหนดใบไม้ไปยังโหนดราก สมมติว่าโหนดปลายสุดทั้งหมดต้องดําเนินการเสร็จสิ้นก่อนจึงจะสามารถส่งกลับผลลัพธ์ได้ เวลาแฝงโดยรวมต้องมากกว่าเวลาแฝงขององค์ประกอบที่ช้าที่สุดชิ้นเดียวเสมอ
เช่นเดียวกับกระบวนการ stochastic ส่วนใหญ่เวลาตอบสนองของโหนดใบเดียวสามารถแสดงเป็นการกระจายได้ ประสบการณ์หลายทศวรรษแสดงให้เห็นว่าในกรณีทั่วไป ส่วนใหญ่ (>99%) คําขอของระบบคลาวด์ที่กําหนดค่าไว้อย่างดีจะดําเนินการได้อย่างรวดเร็ว แต่บ่อยครั้งมีค่าผิดปกติน้อยมากในระบบที่ทํางานช้ามาก
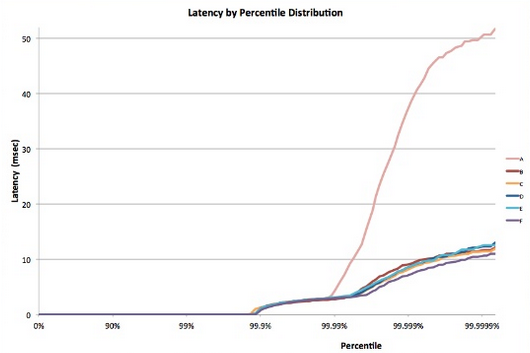
รูปที่ 8: ตัวอย่างเวลาแฝงหาง5
พิจารณาระบบที่โหนดใบไม้ทั้งหมดมีเวลาตอบสนองเฉลี่ย 1 มิลลิวินาที แต่มีความน่าจะเป็น 1% ว่าเวลาการตอบสนองมากกว่า 1,000 มิลลิวินาที (หนึ่งวินาที) ถ้าแต่ละคิวรีจัดการโดยโหนดปลายสุดเดียว ความน่าจะเป็นของคิวรีที่ใช้เวลานานกว่าหนึ่งวินาทีจะเป็น 1%ด้วยเช่นกัน อย่างไรก็ตาม ในขณะที่เราเพิ่มจํานวนโหนดเป็น 100 ความน่าจะเป็นที่คิวรีจะเสร็จสิ้นภายในหนึ่งวินาทีลดลงถึง 36.6%ซึ่งหมายความว่ามีโอกาส 63.4% ที่ระยะเวลาคิวรีจะถูกกําหนดโดยหาง (ต่ําสุด 1%) ของการกระจายความล่าช้า
$(.99^{100})$
หากเราจําลองสิ่งนี้สําหรับหลายกรณี เราเห็นว่าเมื่อจํานวนเซิร์ฟเวอร์เพิ่มขึ้น ผลกระทบของคิวรีที่ช้าช้าเพียงครั้งเดียวจะเด่นชัดกว่า (สังเกตว่ากราฟด้านล่างเพิ่มขึ้นเล็กน้อย) นอกจากนี้ความน่าจะเป็นของค่าผิดปกติเหล่านี้ลดลงจาก 1% ถึง 0.01%ระบบต่ํากว่าอย่างมาก
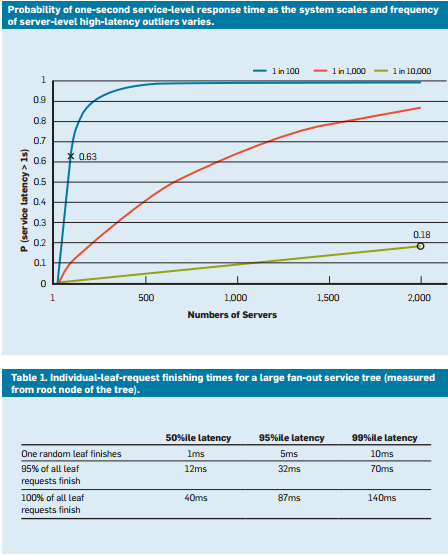
รูปที่ 9: การศึกษาล่าสุดเกี่ยวกับความน่าจะเป็นของเวลาตอบสนองที่แสดงเปอร์เซ็นไทล์ที่ 50, 95 และ 99 สําหรับเวลาแฝงของคําขอ4
เหมือนกับที่เราออกแบบแอปพลิเคชันของเราเพื่อแสดงความผิดพลาดที่ทนต่อปัญหาความน่าเชื่อถือของทรัพยากร ควรจะชัดเจนในตอนนี้ว่าทําไมแอปพลิเคชันจึงเป็นสิ่งสําคัญที่จะต้อง "ปรับให้เหมาะสมกับความอดทน" เพื่อให้สามารถทําเช่นนี้ได้ เราต้องเข้าใจแหล่งข้อมูลของความแปรปรวนด้านประสิทธิภาพที่ยาวนานเหล่านี้และระบุการลดปัญหาที่เป็นไปได้และการแก้ไขปัญหาชั่วคราวที่ไม่ได้ดําเนินการ
ความแปรปรวนในระบบคลาวด์: แหล่งข้อมูลและการลด
เพื่อแก้ไขความแปรปรวนของเวลาตอบสนองที่นําไปสู่ปัญหาเวลาแฝงของหางนี้ เราต้องทําความเข้าใจแหล่งข้อมูลของความแปรปรวนของประสิทธิภาพการทํางาน1
- การใช้ทรัพยากรที่ใช้ร่วมกัน: VM ต่าง ๆ มากมาย (และแอปพลิเคชันภายใน VM) ที่รวมกลุ่มทรัพยากรการคํานวณที่ใช้ร่วมกัน ในบางกรณีอาจเป็นไปได้ว่าข้อนี้จะทําให้เวลาแฝงต่ําสําหรับคําขอบางอย่าง สําหรับงานที่สําคัญ อาจเหมาะสมที่จะใช้อินสแตนซ์เฉพาะและเรียกใช้เกณฑ์มาตรฐานเป็นระยะ ๆ เมื่อไม่ได้ใช้งานเพื่อให้แน่ใจว่ามีการทํางานอย่างถูกต้อง
- daemons พื้นหลังและการบํารุงรักษา: เราได้พูดไปแล้วเกี่ยวกับความจําเป็นสําหรับกระบวนการพื้นหลังในการสร้างจุดตรวจสอบสร้างการสํารองข้อมูลบันทึกการอัปเดตเก็บขยะและจัดการการล้างข้อมูล อย่างไรก็ตาม สิ่งเหล่านี้สามารถลดประสิทธิภาพของระบบขณะดําเนินการได้ สิ่งสําคัญคือต้องซิงโครไนซ์การหยุดชะงักเนื่องจากเธรดการบํารุงรักษาเพื่อลดผลกระทบต่อการไหลของการจราจร สิ่งนี้จะทําให้การเปลี่ยนแปลงทั้งหมดเกิดขึ้นในหน้าต่างสั้น ๆ ที่รู้จักกันดีแทนที่จะสุ่มตลอดอายุการใช้งานของแอปพลิเคชัน
- การจัดคิว: แหล่งทั่วไปอีกแหล่งหนึ่งของความแปรปรวนคือความจํานวนของรูปแบบการมาถึงการจราจร1 ความแปรปรวนนี้อาจเปลี่ยนแปลงได้หากระบบปฏิบัติการใช้อัลกอริทึมการจัดกําหนดการอื่นที่ไม่ใช่ FIFO ระบบ Linux มักจะกําหนดเวลาเธรดจากลําดับเพื่อปรับปริมาณงานโดยรวมให้เหมาะสมและเพิ่มการใช้งานเซิร์ฟเวอร์ให้สูงสุด การศึกษาพบว่าการใช้ FIFO ในการตั้งเวลาของ FIFO ในระบบปฏิบัติการจะลดเวลาแฝงหางด้วยต้นทุนของการลดอัตราความเร็วโดยรวมของระบบ
- Incast ทั้งหมด : รูปแบบที่แสดงในรูปที่ 8 ข้างต้นเรียกว่าการสื่อสารแบบทั้งหมดต่อทั้งหมด เนื่องจากการสื่อสารเครือข่ายส่วนใหญ่ผ่าน TCP ทําให้มีการร้องขอและการตอบสนองพร้อมกันหลายพันรายการระหว่างเว็บเซิร์ฟเวอร์ front-end และโหนดการประมวลผลส่วนหลังทั้งหมด นี่คือรูปแบบที่ราบสูงมากของการสื่อสารและมักจะนําไปสู่ความล้มเหลวจากความแออัดที่รู้จักกัน TCP ในการยุบตัวชนิดพิเศษ1, 2 การตอบสนองอย่างฉับพลันอย่างมากจากเซิร์ฟเวอร์นับพันทําให้ชุดข้อมูลที่ขาดและส่งซ้ําจํานวนมาก ส่งผลให้มีเครือข่ายการตรวจสอบปริมาณการใช้งานสําหรับแพ็คเก็ตที่มีขนาดเล็กมาก ศูนย์ข้อมูลขนาดใหญ่และแอปพลิเคชันระบบคลาวด์มักจําเป็นต้องใช้โปรแกรมควบคุมเครือข่ายแบบกําหนดเองเพื่อปรับหน้าต่างรับ TCP และตัวจับเวลาการส่งข้อมูลใหม่แบบไดนามิก เราเตอร์อาจได้รับการกําหนดค่าให้ปล่อยปริมาณการใช้งานที่เกินอัตราที่กําหนดและลดขนาดของการส่ง
- การจัดการพลังงานและอุณหภูมิ : สุดท้ายแล้ว ความแปรปรวนคือผลพลอยได้ของเทคนิคการลดต้นทุนอื่น ๆ เช่น การใช้สถานะที่ไม่ได้ใช้งานหรือการลดความถี่ของ CPU ตัวประมวลผลมักจะใช้ระยะเวลาที่ไม่ใช่เล็กน้อยในการปรับมาตราส่วนขึ้นจากสถานะไม่ได้ใช้งาน การปิดการปรับค่าใช้จ่ายให้เหมาะสมนั้นนําไปสู่การใช้งานด้านพลังงานและค่าใช้จ่ายที่สูงขึ้น แต่ลดความแปรปรวน นี่เป็นปัญหาน้อยกว่าในระบบคลาวด์สาธารณะ เนื่องจากแบบจําลองการกําหนดราคาจะไม่ค่อยพิจารณาเมตริกการใช้งานภายในของแหล่งข้อมูลของลูกค้า
การทดลองบางอย่างพบว่าความแปรปรวนของระบบดังกล่าวแย่กว่ามากในระบบคลาวด์สาธารณะ3 มักเกิดจากการแยกประสิทธิภาพการทํางานที่ไม่สมบูรณ์ของทรัพยากรเสมือนและตัวประมวลผลที่ใช้ร่วมกัน การดําเนินการนี้จะเพิ่มมากขึ้นหากมีการดําเนินการงานที่ไวต่อเวลาแฝงจํานวนมากบนโหนดจริงเดียวกันกับงานที่มี CPU สูง
การใช้ชีวิตอย่างหลากหลาย: โซลูชันด้านวิศวกรรม
แหล่งข้อมูลหลายแหล่งของความแปรปรวนข้างต้นไม่มีวิธีแก้ปัญหาที่ไม่ดี ดังนั้นแทนที่จะพยายามแก้ไขแหล่งข้อมูลทั้งหมดที่พองหางแฝงแอปพลิเคชันระบบคลาวด์ต้องออกแบบมาเพื่อให้ทนต่อความเหมาะสม แน่นอนนี้คล้ายกับวิธีที่เราออกแบบแอปพลิเคชันที่จะทนต่อข้อบกพร่องเนื่องจากเราไม่สามารถหวังว่าจะแก้ไขข้อผิดพลาดที่เป็นไปได้ทั้งหมด เทคนิคทั่วไปบางอย่างเพื่อจัดการกับความแปรปรวนนี้คือ:
- ผลลัพธ์ "ดีเพียงพอ": บ่อยครั้งที่ระบบกําลังรอรับผลลัพธ์จากโหนดนับพัน ความสําคัญของผลลัพธ์เดี่ยวอาจถือว่าค่อนข้างต่ํา ดังนั้นแอปพลิเคชันจํานวนมากอาจเลือกที่จะตอบกลับผู้ใช้ที่มีผลลัพธ์ที่มาถึงภายในหน้าต่างเวลาแฝงที่สั้นและละทิ้งส่วนที่เหลือ
- Canaries: อีกทางเลือกหนึ่งที่มักจะใช้สําหรับเส้นทางโค้ดที่หายากคือการทดสอบคําขอบนโหนดปลายนิ้วขนาดเล็กเพื่อทดสอบว่าทําให้เกิดความล้มเหลวหรือความล้มเหลวที่อาจส่งผลกระทบต่อระบบทั้งหมดหรือไม่ คิวรีแบบพัดลมออกแบบเต็มจะถูกสร้างขึ้นเฉพาะเมื่อ canary ไม่ทําให้เกิดความล้มเหลว นี่คือคล้ายกับการส่งนกกระวาน (นก) เข้าไปในเหมืองถ่านหินเพื่อทดสอบว่าปลอดภัยสําหรับมนุษย์หรือไม่
- การตรวจสอบความน่าจะเป็นและการตรวจสอบสุขภาพที่เกิดจากเวลาแฝง: แน่นอนว่าคําขอของระบบจํานวนมากเป็นเรื่องธรรมดาเกินกว่าที่จะทดสอบโดยใช้นกขนาดใหญ่ คําขอดังกล่าวมีแนวโน้มที่จะมีหางยาวหากโหนดใบหนึ่งทํางานได้ไม่ดี เพื่อแก้ไขปัญหานี้ ระบบต้องตรวจสอบสุขภาพและเวลาแฝงของแต่ละโหนดปลายสุดเป็นระยะ และไม่กําหนดเส้นทางการร้องขอไปยังโหนดที่แสดงประสิทธิภาพการทํางานต่ํา (เนื่องจากการบํารุงรักษาหรือความล้มเหลว)
- ต่างกัน QoS: สามารถสร้างคลาสบริการแยกต่างหากสําหรับคําขอแบบโต้ตอบ เพื่อให้พวกเขาสามารถลําดับความสําคัญในคิวใดก็ได้ แอปพลิเคชันที่สูญเสียเวลาแฝงสามารถทนต่อเวลารอที่นานขึ้นสําหรับการดําเนินการของพวกเขา
- request hedging: นี่คือโซลูชันง่ายๆ เพื่อลดผลกระทบของความแปรปรวน โดยการส่งต่อคําขอเดียวกันไปยังหลายแบบจําลอง และใช้การตอบสนองที่มาถึงก่อน แน่นอนว่า สิ่งนี้สามารถเพิ่มเป็นสองเท่า หรือสามเท่าของทรัพยากรที่จําเป็น เพื่อลดจํานวนคําขอที่มีความเสี่ยง คําขอที่สองอาจถูกส่งเฉพาะเมื่อรอการตอบสนองครั้งแรกที่มากกว่าเปอร์เซ็นไทล์ที่ 95 ของเวลาแฝงที่คาดไว้สําหรับคําขอนั้น ซึ่งทําให้ภาระส่วนเกินจะอยู่ที่ประมาณ 5%เท่านั้น แต่ลดเวลาแฝงลงอย่างมาก (ในกรณีทั่วไปที่แสดงในรูปที่ 9 ซึ่งเวลาแฝงที่ 95 ต่ํากว่าเวลาแฝงที่ 99th-เปอร์เซ็นไทล์มาก)
- การดําเนินการแบบเก็งกําไรและการจําลองแบบเลือก: งานบนโหนดที่ไม่ว่างโดยเฉพาะอย่างยิ่งสามารถเปิดใช้งานได้อย่างแน่นอนบนโหนดปลายสุดอื่น ๆ ซึ่งจะมีผลโดยเฉพาะอย่างยิ่งหากความล้มเหลวในโหนดเฉพาะทําให้เกิดการโอเวอร์โหลด
- โซลูชันที่ใช้ UX: สุดท้าย ความล่าช้าสามารถซ่อนได้อย่างชาญฉลาดจากผู้ใช้ผ่านส่วนติดต่อผู้ใช้ที่ออกแบบมาอย่างดีซึ่งช่วยลดความรู้สึกของการหน่วงเวลาที่ผู้ใช้มีประสบการณ์ เทคนิคการทําเช่นนี้อาจรวมถึงการใช้ภาพเคลื่อนไหว ที่แสดงผลลัพธ์ในช่วงแรก หรือมีส่วนร่วมกับผู้ใช้โดยการส่งข้อความที่เกี่ยวข้อง
การใช้เทคนิคเหล่านี้สามารถปรับปรุงประสบการณ์ของผู้ใช้ปลายทางของแอปพลิเคชันระบบคลาวด์อย่างมีนัยสําคัญเพื่อแก้ปัญหาที่แปลกประหลาดของหางยาว
อ้าง อิง
- Li, J., Sharma, N. K., Ports, D. R., & Gribble, S. D. (2014) เรื่องท้าย: ฮาร์ดแวร์ OS และแหล่ง Application-Level ของ Tail Latency จากการดําเนินการของ ACM Symposium ในการประมวลผลแบบคลาวด์ ACM
- Wu, Haitao และ Feng, Zhenqian และ Guo, Chuanxiong และ Zhang, Yongguang (2013) ICTCP: การควบคุมความแออัดของอินคาสต์สําหรับ TCP ใน Data-Center เครือข่าย, ธุรกรรม IEEE/ACM บนเครือข่าย (TON), กด IEEE
- Xu, Yunjing และ Musgrave, Zachary และ Noble, Brian และ Bailey, Michael (2013) Bobtail: หลีกเลี่ยงหางยาวในระบบคลาวด์การประชุม USENIX ครั้งที่ 10 เกี่ยวกับการออกแบบและการใช้งานระบบเครือข่ายการเชื่อมโยง USENIX
- Dean, Jeffrey และ Barroso, Luiz André (2013) หางที่มาตราส่วน การสื่อสารของ ACM, ACM
- Tene, Gil (2014) [ทําความเข้าใจเวลาแฝง - บทเรียนหลักและเครื่องมือบางอย่าง](https://www.infoq.com/presentations/latency-lessons-tools/, คิวคอน ลอนดอน