จัดเก็บเวกเตอร์ในฐานข้อมูล Azure สําหรับ PostgreSQL
โปรดทราบว่าคุณจําเป็นต้องฝังเวกเตอร์ที่จัดเก็บไว้ในฐานข้อมูลเวกเตอร์เพื่อเรียกใช้การค้นหาเชิงความหมาย ฐานข้อมูล Azure สําหรับเซิร์ฟเวอร์ที่ยืดหยุ่น PostgreSQL สามารถใช้เป็น ฐานข้อมูลเวกเตอร์ ที่มี vector ส่วนขยาย
ข้อมูลเบื้องต้น pgvector
ส่วนขยายแบบโอเพนซอร์สpgvectorมีที่เก็บข้อมูลเวกเตอร์ การทําคิวรี่ความคล้ายคลึงกัน และการดําเนินการเวกเตอร์อื่น ๆ สําหรับ PostgreSQL เมื่อเปิดใช้งานคุณสามารถสร้าง vector คอลัมน์เพื่อจัดเก็บการฝัง (หรือเวกเตอร์อื่น ๆ) ควบคู่กับคอลัมน์อื่น ๆ
/* Enable the extension. */
CREATE EXTENSION vector;
/* Create a table containing a 3d vector. */
CREATE TABLE documents (id bigserial PRIMARY KEY, embedding vector(3));
/* Create some sample data. */
INSERT INTO documents (embedding) VALUES
('[1,2,3]'),
('[2,1,3]'),
('[4,5,6]');
คุณสามารถเพิ่มคอลัมน์เวกเตอร์ไปยังตารางที่มีอยู่:
ALTER TABLE documents ADD COLUMN embedding vector(3);
เมื่อคุณมีข้อมูลเวกเตอร์บางอย่าง คุณสามารถดูข้อมูลนั้นควบคู่ไปกับข้อมูลตารางปกติ:
# SELECT * FROM documents;
id | embedding
----+-----------
1 | [1,2,3]
2 | [2,1,3]
3 | [4,5,6]
ส่วนขยาย vector รองรับหลายภาษา เช่น .NET, Python, Java และอื่นๆ อีกมากมาย ดู พื้นที่เก็บ GitHub ของพวกเขาสําหรับเพิ่มเติม
หากต้องการแทรกเอกสารด้วยเวกเตอร์ [1, 2, 3] โดยใช้ Npgsql ใน C# ให้เรียกใช้โค้ดดังนี้:
var sql = "INSERT INTO documents (embedding) VALUES ($1)";
await using (var cmd = new NpgsqlCommand(sql, conn))
{
var embedding = new Vector(new float[] { 1, 2, 3 });
cmd.Parameters.AddWithValue(embedding);
await cmd.ExecuteNonQueryAsync();
}
แทรกและอัปเดตเวกเตอร์
เมื่อตารางมีคอลัมน์เวกเตอร์สามารถเพิ่มแถวด้วยค่าเวกเตอร์ตามที่ระบุไว้ก่อนหน้านี้
INSERT INTO documents (embedding) VALUES ('[1,2,3]');
คุณยังสามารถโหลดเวกเตอร์จํานวนมากโดยใช้คําสั่ง COPY (ดู ตัวอย่างที่สมบูรณ์ ใน Python):
COPY documents (embedding) FROM STDIN WITH (FORMAT BINARY);
คอลัมน์เวกเตอร์สามารถอัปเดตได้เช่นคอลัมน์มาตรฐาน:
UPDATE documents SET embedding = '[1,1,1]' where id = 1;
ดําเนินการค้นหาระยะทางของโคไซน์
ส่วนขยายvectorให้ตัวv1 <=> v2ดําเนินการในการคํานวณระยะห่างของโคไซน์ระหว่างเวกv1เตอร์และv2 ผลลัพธ์คือตัวเลขระหว่าง 0 และ 2 โดยที่ 0 หมายถึง "ความเหมือนกันทางความหมาย" (ไม่มีระยะห่าง) และสอง หมายถึง "ตรงกันข้ามกับความหมาย" (ระยะทางสูงสุด)
คุณสามารถดูคําว่า ระยะโคไซน์ และความคล้ายคลึงกัน จําได้ว่าความคล้ายคลึงกันของโคไซน์อยู่ระหว่าง -1 ถึง 1 โดยที่ -1 หมายถึง "ตรงกันข้ามทางความหมาย" และ 1 หมายถึง "เหมือนกันทางความหมาย" ดังนั้น similarity = 1 - distance.
Upshot คือคิวรีที่เรียงลําดับตามระยะห่างจากน้อยไปหามากจะส่งกลับผลลัพธ์ที่ห่างไกลน้อยที่สุด (คล้ายกันมากที่สุด) ก่อน ในขณะที่คิวรีที่เรียงลําดับตามความคล้ายคลึงกันจากมากไปหาน้อยจะส่งกลับผลลัพธ์ที่คล้ายกันมากที่สุด (น้อยที่สุดจากระยะไกล) ก่อน
นี่คือเวกเตอร์บางตัวและระยะทางและความคล้ายคลึงกันเพื่อแสดงให้เห็นแนวคิด คุณสามารถคํานวณการคํานวณนี้ได้ด้วยตนเองโดยการเรียกใช้บางอย่างเช่น:
SELECT '[1,1]' <=> '[-1,-1]';
พิจารณาเวกเตอร์เหล่านี้:
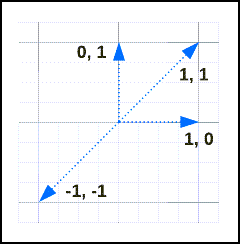
ความคล้ายคลึงและระยะทางของพวกเขาคือ:
| v1 | V2 | ระยะทาง | ความคล้ายคลึง |
|---|---|---|---|
[1, 1] |
[1, 1] |
0 | 1 |
[1, 1] |
[-1, -1] |
2 | -1 |
[1, 0] |
[0, 1] |
1 | 0 |
เมื่อต้องการรับเอกสารตามลําดับของความใกล้เคียงเวกเตอร์ [2, 3, 4]ให้เรียกใช้คิวรีนี้:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance;
ผลลัพธ์:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535
1 | [1,2,3] | 0.007416666029069763
2 | [2,1,3] | 0.05704583272761632
เอกสารที่มี id=3 จะคล้ายกับคิวรีมากที่สุด ตามด้วย id=1และสุดท้ายโดยid=2
เพิ่มส่วนLIMIT Nคําสั่งลงในSELECTคิวรีเพื่อส่งคืนเอกสารที่คล้ายกันมากที่สุดN ตัวอย่างเช่น เพื่อรับเอกสารที่คล้ายกันมากที่สุด:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance
LIMIT 1;
ผลลัพธ์:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535