การถดถอย
Note
ดูแท็บ ข้อความและรูปภาพ สําหรับรายละเอียดเพิ่มเติม!
แบบจําลองการถดถอยได้รับการฝึกฝนเพื่อทํานายค่าป้ายชื่อตัวเลขตามข้อมูลการทดสอบการใช้งานที่มีทั้งคุณลักษณะและป้ายชื่อที่รู้จัก กระบวนการฝึกแบบจําลองการถดถอย (หรือแบบจำลองการเรียนรู้ของเครื่องที่มีการควบคุม) เกี่ยวข้องกับการทําซ้ำหลายครั้ง ซึ่งคุณใช้อัลกอริทึมที่เหมาะสม (โดยปกติจะมีการตั้งค่าพารามิเตอร์บางอย่าง) เพื่อแบบจําลอง ประเมินประสิทธิภาพการคาดการณ์ของแบบจําลอง และปรับแต่งแบบจําลองโดยทําซ้ำกระบวนการฝึกด้วยอัลกอริทึมและพารามิเตอร์ต่างๆ จนกว่าคุณจะได้ความแม่นยําในการคาดการณ์ในระดับที่ยอมรับได้
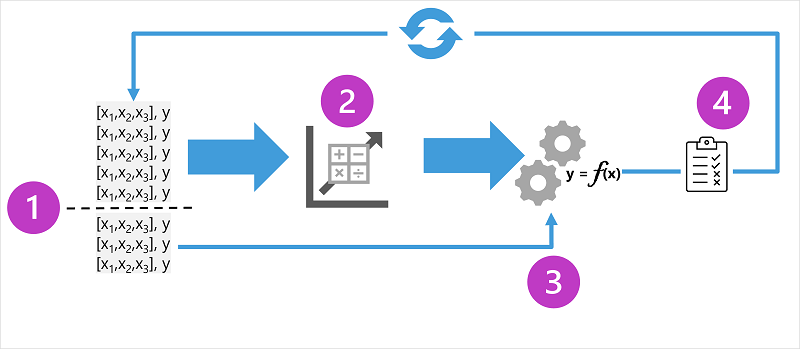 แผนภาพที่แสดงกระบวนการของการฝึกประเมินแบบจําลองที่มีการควบคุม
แผนภาพที่แสดงกระบวนการของการฝึกประเมินแบบจําลองที่มีการควบคุม
แผนภาพจะแสดงองค์ประกอบสําคัญสี่ประการของกระบวนการฝึกสําหรับแบบจําลองการเรียนรู้ของเครื่องที่มีการควบคุม:
- แยกข้อมูลการฝึก (สุ่ม) เพื่อสร้างชุดข้อมูลที่จะฝึกแบบจําลองในขณะที่เก็บชุดย่อยของข้อมูลที่คุณจะใช้เพื่อตรวจสอบแบบจําลองที่ได้รับการฝึก
- ใช้อัลกอริทึมเพื่อให้พอดีกับข้อมูลการฝึกกับแบบจําลอง ในกรณีของแบบจําลองการถดถอย ให้ใช้อัลกอริทึมการถดถอย เช่น การถดถอยเชิงเส้น
- ใช้ข้อมูลการตรวจสอบความถูกต้องที่คุณเก็บไว้เพื่อทดสอบแบบจําลองโดยการทํานายป้ายชื่อสําหรับคุณลักษณะ
- เปรียบเทียบป้ายชื่อ จริง ที่รู้จักในชุดข้อมูลการตรวจสอบความถูกต้องกับป้ายชื่อที่แบบจําลองคาดการณ์ไว้ จากนั้นรวมความแตกต่างระหว่าง ที่ทํานาย และ ค่าป้ายชื่อ จริงเพื่อคํานวณเมตริกที่ระบุว่าแบบจําลองคาดการณ์สําหรับข้อมูลการตรวจสอบความถูกต้องได้แม่นยําเพียงใด
หลังจากการฝึก ตรวจสอบ และประเมินการทําซ้ำแต่ละครั้ง คุณสามารถทําซ้ำกระบวนการด้วยอัลกอริทึมและพารามิเตอร์ต่างๆ ได้จนกว่าจะได้เมตริกการประเมินที่ยอมรับได้
ตัวอย่าง - การถดถอย
เรามาสํารวจการถดถอยด้วยตัวอย่างที่เรียบง่ายซึ่งเราจะฝึกแบบจําลองเพื่อคาดการณ์ป้ายชื่อตัวเลข (y) ตามค่าคุณลักษณะเดียว (x) สถานการณ์จริงส่วนใหญ่เกี่ยวข้องกับค่าคุณลักษณะหลายค่า ซึ่งเพิ่มความซับซ้อนบางอย่าง แต่หลักการนั้นเหมือนกัน
ตัวอย่างเช่น เรามาติดสถานการณ์การขายไอศกรีมที่เรากล่าวถึงก่อนหน้านี้กัน สําหรับคุณลักษณะของเรา เราจะพิจารณา อุณหภูมิ (สมมติว่าค่าคืออุณหภูมิสูงสุดในวันใดวันหนึ่ง) และป้ายชื่อที่เราต้องการฝึกแบบจําลองเพื่อคาดการณ์คือจํานวนไอศกรีมที่ขายได้ในวันนั้น เราจะเริ่มต้นด้วยข้อมูลในอดีตบางอย่างที่มีบันทึกอุณหภูมิรายวัน (x) และยอดขายไอศกรีม (y):
 แผนภาพของเทอร์โมมิเตอร์ แผนภาพของเทอร์โมมิเตอร์ |
 แผนผังของไอศกรีม แผนผังของไอศกรีม |
|---|---|
| อุณหภูมิ (x) | ยอดขายไอศกรีม (y) |
| 51 | 1 |
| 52 | 0 |
| 67 | 14 |
| 65 | 14 |
| 70 | 23 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 73 | 22 |
| 81 | 30 |
| 78 | 26 |
| 83 | 36 |
การฝึกแบบจําลองการถดถอย
เราจะเริ่มต้นโดยการแยกข้อมูลและใช้ชุดย่อยของข้อมูลนั้นเพื่อฝึกแบบจําลอง นี่คือชุดข้อมูลการฝึก:
| อุณหภูมิ (x) | ยอดขายไอศกรีม (y) |
|---|---|
| 51 | 1 |
| 65 | 14 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 81 | 30 |
เพื่อรับข้อมูลเชิงลึกว่า x และค่า y เหล่านี้อาจเกี่ยวข้องกันอย่างไร เราสามารถลงจุดเหล่านั้นเป็นพิกัดตามสองแกนดังนี้:
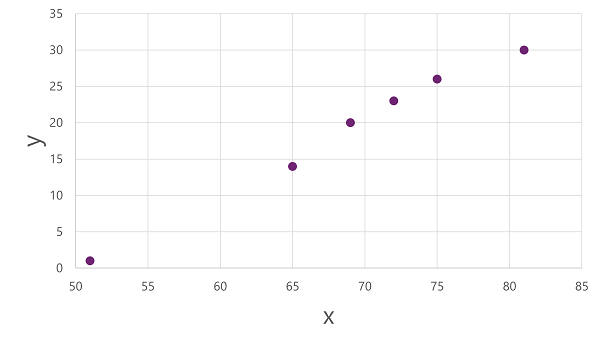 ไดอะแกรมของแผนภูมิกระจายที่แสดง x และ y
ไดอะแกรมของแผนภูมิกระจายที่แสดง x และ y
ในตอนนี้เราพร้อมที่จะใช้อัลกอริทึมกับข้อมูลการฝึกของเราและพอดีกับฟังก์ชันที่ใช้การดําเนินการกับ x เพื่อคํานวณ y อัลกอริทึมหนึ่งเช่นนั้น การถดถอยเชิงเส้นซึ่งทํางานโดยได้รับฟังก์ชันที่สร้างเส้นตรงผ่านจุดตัดของ x และค่า y ในขณะที่ลดระยะห่างเฉลี่ยระหว่างเส้นและจุดที่ลงจุดให้น้อยที่สุด เช่นนี้:
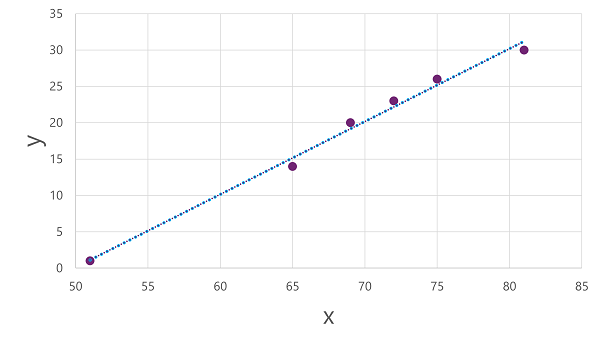 แผนภาพของแผนภูมิกระจายที่มีการเพิ่มเส้นการถดถอย
แผนภาพของแผนภูมิกระจายที่มีการเพิ่มเส้นการถดถอย
เส้นเป็นการแสดงภาพของฟังก์ชันที่ความลาดชันของเส้นอธิบายวิธีการคํานวณค่าของ y สําหรับค่าที่กําหนดของ x เส้นตรงนี้ตัดแกน x ที่ 50 ดังนั้นเมื่อ x เท่ากับ 50, y เท่ากับ 0 ตามที่คุณเห็นได้จากเครื่องหมายแกนในแผนภูมิ เเส้นจะลาดเอียงเพื่อให้ทุกๆ การเพิ่มขึ้นของ 5 ตามแกน x จะส่งผลให้เพิ่มขึ้น 5 ขึ้นไปตามแกน y ดังนั้น เมื่อ x เท่ากับ 55, y เท่ากับ 5 เมื่อ x เท่ากับ 60, y เท่ากับ 10 และเป็นเช่นนี้ไปเรื่อยๆ เมื่อต้องการคํานวณค่า y สําหรับค่า x ที่กําหนด ฟังก์ชันจะลบ 50 ด้วยค่าที่กําหนด กล่าวอีกนัยหนึ่ง ฟังก์ชันสามารถแสดงได้ดังนี้:
f(x) = x-50
คุณสามารถใช้ฟังก์ชันนี้เพื่อทํานายจํานวนไอศกรีมที่ขายได้ในแต่ละวันด้วยอุณหภูมิที่กําหนด ตัวอย่างเช่น สมมติว่าพยากรณ์อากาศบอกเราว่าพรุ่งนี้อุณหภูมิจะอยู่ที่ 77 องศา เราสามารถใช้แบบจําลองของเรามาคำนวณ 77-50 และคาดการณ์ว่าเราจะขายไอศกรีม 27 ถ้วยในวันพรุ่งนี้
แต่ว่าแบบจําลองของเรามีความแม่นยําเพียงใด
การประเมินแบบจําลองการถดถอย
เพื่อตรวจสอบแบบจําลองและประเมินว่าคาดการณ์ได้ดีเพียงใด เราเก็บข้อมูลบางอย่างไว้เพื่อให้เราทราบค่าป้ายชื่อ (y) นี่คือข้อมูลที่เราเก็บไว้:
| อุณหภูมิ (x) | ยอดขายไอศกรีม (y) |
|---|---|
| 52 | 0 |
| 67 | 14 |
| 70 | 23 |
| 73 | 22 |
| 78 | 26 |
| 83 | 36 |
เราสามารถใช้แบบจําลองเพื่อทํานายป้ายชื่อสําหรับข้อสังเกตแต่ละรายการในชุดข้อมูลนี้ตามค่าคุณลักษณะ (x) จากนั้นเปรียบเทียบป้ายชื่อที่คาดการณ์ (ŷ) กับค่าป้ายชื่อจริง (y) ที่รู้จัก
การใช้แบบจําลองที่เราฝึกไว้ก่อนหน้านี้ ซึ่งย่อส่วนฟังก์ชัน f(x) = x-50 ส่งผลให้เกิดการคาดการณ์ต่อไปนี้:
| อุณหภูมิ (x) | ยอดขายจริง (y) | ยอดขายที่คาดการณ์ไว้ (ŷ) |
|---|---|---|
| 52 | 0 | 2 |
| 67 | 14 | 17 |
| 70 | 23 | 20 |
| 73 | 22 | 23 |
| 78 | 26 | 28 |
| 83 | 36 | 33 |
เราสามารถลงจุดทั้ง คาดการณ์ และป้ายชื่อ จริง กับค่าคุณลักษณะดังนี้:
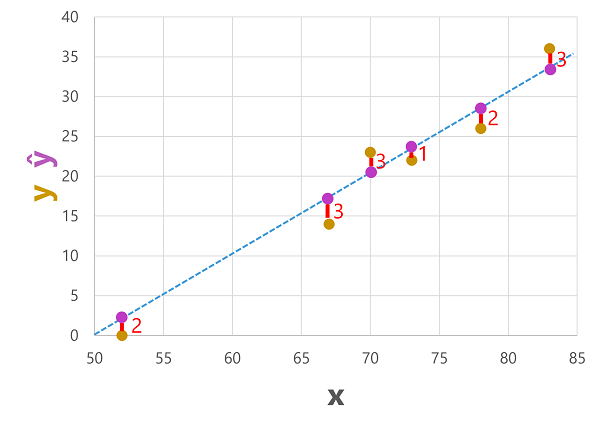 แผนภาพของแผนภูมิกระจายที่แสดงค่าที่ทํานายและค่าจริง
แผนภาพของแผนภูมิกระจายที่แสดงค่าที่ทํานายและค่าจริง
ป้ายชื่อที่ทำนายไว้จะถูกคำนวณโดยแบบจำลองเพื่อให้อยู่บนเส้นฟังก์ชัน แต่มีค่าความแปรปรวนบางส่วนระหว่างค่า ŷ ที่คำนวณโดยฟังก์ชันและค่า y จริงจากชุดข้อมูลการตรวจสอบ ซึ่งระบุไว้บนกราฟเป็นเส้นตรงระหว่างค่า ŷ และค่า y ที่แสดงให้เห็นว่าการทำนายนั้นแตกต่างจากค่าจริงมากเพียงใด
เมตริกการประเมินการถดถอย
คุณสามารถคํานวณเมตริกทั่วไปบางอย่างที่ใช้เพื่อประเมินแบบจําลองการถดถอยโดยยึดตามความแตกต่างระหว่างค่าที่คาดการณ์และค่าจริง
ข้อผิดพลาดแบบสัมบูรณ์ (MAE)
ค่าความแปรปรวนในตัวอย่างนี้บ่งบอกถึงจํานวนไอศกรีมที่คาดการณ์แต่ละอย่างไม่ถูกต้อง ไม่สําคัญว่าการคาดการณ์ มากกว่า หรือ น้อยกว่า ค่าจริง (ตัวอย่างเช่น -3 และ +3 แสดงถึงความแปรปรวน 3 ทั้งคู่) เมตริกนี้เรียกว่า ข้อผิดพลาดสัมบูรณ์ สําหรับแต่ละการคาดการณ์ และสามารถสรุปได้สําหรับการตรวจสอบความถูกต้องทั้งหมดที่กําหนดเป็น ข้อผิดพลาดแบบสัมบูรณ์ (MAE)
ในตัวอย่างไอศกรีม ค่าเฉลี่ย (เฉลี่ย) ของข้อผิดพลาดสัมบูรณ์ (2, 3, 3, 1, 2 และ 3) คือ 2.33
ข้อผิดพลาดสแควร์ (MSE)
เมตริกข้อผิดพลาดแบบสัมบูรณ์จะใช้ความขัดแย้งทั้งหมดระหว่างป้ายชื่อที่คาดการณ์และป้ายชื่อจริงในบัญชีเท่ากัน อย่างไรก็ตาม อาจเป็นที่น่าปรารถนาที่จะมีแบบจําลองที่ไม่ถูกต้องอย่างต่อเนื่องด้วยจํานวนเล็กน้อยที่ทําให้เกิดข้อผิดพลาดน้อยลง แต่มีข้อผิดพลาดที่ใหญ่กว่า วิธีหนึ่งในการสร้างเมตริกที่ "การขยาย" ข้อผิดพลาดใหญ่ขึ้นโดย ยกกำลังสอง ข้อผิดพลาดแต่ละรายการและคำนวณค่าเฉลี่ยของค่ายกกำลังสอง เมตริกนี้เรียกว่า ค่าความผิดพลาดกำลังสองเฉลี่ย (MSE)
ในตัวอย่างไอศกรีมของเรา ค่าเฉลี่ยของค่าสัมบูรณ์กำลังสอง (ซึ่งคือ 4, 9, 9, 1, 4 และ 9) คือ 6
รากที่สองของค่าเฉลี่ยข้อผิดพลาดกำลังสอง (RMSE)
ข้อผิดพลาดกำลังสองเฉลี่ยจะช่วยให้คำนึงถึงขนาดของข้อผิดพลาดได้ แต่เนื่องจาก กำลังสอง ค่าข้อผิดพลาด เมตริกที่ได้จึงไม่สามารถแสดงปริมาณที่วัดได้ด้วยป้ายชื่อได้อีกต่อไป กล่าวอีกนัยหนึ่งเราสามารถพูดได้ว่า MSE ของแบบจำลองของเราคือ 6 แต่ไม่ได้วัดความแม่นยำในแง่ของจำนวนไอศกรีมที่คาดการณ์ผิด 6 เป็นเพียงคะแนนตัวเลขที่บ่งชี้ระดับข้อผิดพลาดในการคาดการณ์การตรวจสอบความถูกต้อง
หากเราต้องการวัดข้อผิดพลาดในแง่ของจำนวนไอศกรีม เราจำเป็นต้องคำนวณ รากที่สอง ของ MSE ซึ่งจะได้ค่าเมตริกที่เรียกว่า ค่าผิดพลาดรากที่สองเฉลี่ย ซึ่งไม่น่าแปลกใจเลย ในกรณีนี้ √6 ซึ่งจะ 2.45 (ไอศกรีม)
ค่าสัมประสิทธิ์การกำหนด (R2)
เมตริกทั้งหมดจนถึงขณะนี้จะเปรียบเทียบความแตกต่างระหว่างค่าที่คาดการณ์กับค่าจริงเพื่อประเมินแบบจำลอง อย่างไรก็ตาม ในความเป็นจริงแล้ว มีความแตกต่างโดยสุ่มตามธรรมชาติในยอดขายไอศกรีมรายวันซึ่งแบบจำลองคำนึงถึง ในแบบจําลองการถดถอยเชิงเส้น อัลกอริทึมการฝึกมีพอดีกับเส้นตรงที่ลดค่าความแปรปรวนของค่าเฉลี่ยระหว่างฟังก์ชันและค่าป้ายชื่อที่รู้จัก ค่าสัมประสิทธิ์การกำหนด (มักเรียกกันว่า R2 หรือ R-Squared) เป็นตัวชี้วัดที่วัดสัดส่วนของความแปรปรวนในผลการตรวจสอบความถูกต้อง ซึ่งสามารถอธิบายได้ด้วยแบบจำลอง โดยตรงข้ามกับลักษณะผิดปกติบางประการของข้อมูลการตรวจสอบความถูกต้อง (ตัวอย่างเช่น วันที่มียอดขายไอศกรีมมากผิดปกติอย่างมากเนื่องจากมีเทศกาลในท้องถิ่น)
การคํานวณสําหรับ R2 จะซับซ้อนมากกว่าสําหรับเมตริกก่อนหน้า เปรียบเทียบผลรวมของความแตกต่างยกกำลังสองระหว่างป้ายชื่อที่คาดการณ์และป้ายชื่อจริงกับผลรวมของความแตกต่างยกกำลังสองระหว่างค่าป้ายชื่อจริงและค่าเฉลี่ยของค่าป้ายชื่อจริง ดังนี้:
R2 = 1- ∑(y-ŷ)2 ÷ ∑(y-ȳ)2
อย่ากังวลมากเกินไปหากดูซับซ้อน เนื่องจากเครื่องมือการเรียนรู้ของเครื่องส่วนใหญ่สามารถคำนวณหน่วยเมตริกให้คุณได้ จุดสำคัญคือผลลัพธ์จะเป็นค่าระหว่าง 0 ถึง 1 ที่อธิบายสัดส่วนความแปรปรวนที่อธิบายได้โดยแบบจำลอง กล่าวง่าย ๆ ยิ่งค่านี้ใกล้เคียงกับ 1 มากแบบจําลองก็จะยิ่งพอดีกับข้อมูลการตรวจสอบความถูกต้อง ในกรณีของแบบจําลองการถดถอยของไอศกรีม R2 ที่คํานวณจากข้อมูลการตรวจสอบความถูกต้องคือ 0.95
การฝึกแบบวนซ้ำ
เมตริกที่อธิบายไว้ข้างต้นมักใช้เพื่อประเมินแบบจําลองการถดถอย ในสถานการณ์โลกแห่งความเป็นจริงส่วนใหญ่ นักวิทยาศาสตร์ข้อมูลจะใช้กระบวนการแบบวนซ้ำเพื่อฝึกและประเมินแบบจำลองซ้ำๆ โดยมีการเปลี่ยนแปลงดังต่อไปนี้:
- การเลือกและการเตรียมคุณสมบัติ (การเลือกคุณสมบัติที่จะรวมไว้ในแบบจำลองและการคำนวณที่ใช้กับคุณสมบัติเหล่านั้นเพื่อช่วยให้แน่ใจว่าเหมาะสมมากขึ้น)
- การเลือกอัลกอริทึม (เราได้สำรวจการถดถอยเชิงเส้นในตัวอย่างก่อนหน้านี้ แต่ยังมีอัลกอริทึมการถดถอยอื่นๆ อีกมากมาย)
- พารามิเตอร์อัลกอริทึม (การตั้งค่าตัวเลขเพื่อควบคุมพฤติกรรมของอัลกอริทึม เรียกได้อย่างถูกต้องว่า ไฮเปอร์พารามิเตอร์ เพื่อแยกความแตกต่างจากพารามิเตอร์ x และ y)
หลังจากทำซ้ำหลายครั้ง จะเลือกแบบจำลองที่ให้ผลลัพธ์เป็นเมตริกการประเมินที่ดีที่สุดซึ่งยอมรับได้สำหรับสถานการณ์เฉพาะนั้นๆ