การจัดประเภทแบบไบนารี
หมายเหตุ
ดูแท็บ ข้อความและรูปภาพ สําหรับรายละเอียดเพิ่มเติม!
การจัดประเภท เช่น การถดถอย เป็นเทคนิคการเรียนรู้ของเครื่อง แบบมีผู้ควบคุม การตรวจสอบและการประเมินแบบจําลองจึงเป็นไปในขั้นตอนเดียวกัน แทนที่จะคํานวณค่าตัวเลขเช่นแบบจําลองการถดถอย อัลกอริทึมที่ใช้ในการฝึกแบบจําลองการจัดประเภทคํานวณค่า ความน่าจะเป็น สําหรับการมอบหมายคลาสและเมตริกการประเมินที่ใช้ในการประเมินประสิทธิภาพของแบบจําลองเปรียบเทียบคลาสที่คาดการณ์ไว้กับระดับชั้นจริง
อัลกอริทึมการจัดประเภทไบนารีใช้เพื่อฝึกแบบจําลองที่คาดการณ์หนึ่งในสองป้ายชื่อที่เป็นไปได้สําหรับคลาสเดียว โดยพื้นฐานแล้วการคาดการณ์ว่าเป็นจริงหรือเท็จ ในสถานการณ์จริงส่วนใหญ่ การสังเกตการณ์ข้อมูลที่ใช้เพื่อฝึกและตรวจสอบความถูกต้องของแบบจําลองประกอบด้วยค่าคุณลักษณะ (x) หลายค่าและค่า y ที่เป็น 1 หรือ 0
ตัวอย่าง - การจัดประเภทไบนารี
เมื่อต้องการทําความเข้าใจวิธีการทํางานของการจัดประเภทไบนารี มาดูตัวอย่างที่เรียบง่ายที่ใช้คุณลักษณะเดียว (x) เพื่อคาดการณ์ว่าป้ายชื่อ y เป็น 1 หรือ 0 ในตัวอย่างนี้เราจะใช้ระดับน้ําตาลในเลือดของผู้ป่วยเพื่อคาดการณ์ว่าผู้ป่วยเป็นโรคเบาหวานหรือไม่ นี่คือข้อมูลที่เราจะฝึกแบบจําลอง:

|

|
|---|---|
| น้ําตาลกลูโคสในเลือด (x) | เป็นเบาหวาน? (y) |
| 67 | 0 |
| 103 | 1 |
| 114 | 1 |
| 72 | 0 |
| 116 | 1 |
| 65 | 0 |
การฝึกแบบจําลองการจัดประเภทแบบไบนารี
ในการฝึกแบบจําลอง เราจะใช้อัลกอริทึมเพื่อให้พอดีกับข้อมูลการฝึกกับฟังก์ชันที่คํานวณ ความน่าจะ เป็นของป้ายชื่อระดับชั้น เป็นจริง (กล่าวอีกนัยหนึ่งว่าผู้ป่วยเป็นโรคเบาหวาน) ความน่าจะเป็นจะถูกวัดเป็นค่าระหว่าง 0.0 และ 1.0 ดังนั้นความน่าจะเป็น ทั้งหมด สําหรับคลาสที่เป็นไปได้ ทั้งหมด คือ 1.0 ตัวอย่างเช่นหากความน่าจะเป็นของผู้ป่วยที่มีโรคเบาหวานคือ 0.7 ความน่าจะเป็นที่สอดคล้องกันคือ 0.3 ที่ผู้ป่วยไม่ใช่ โรคเบาหวาน
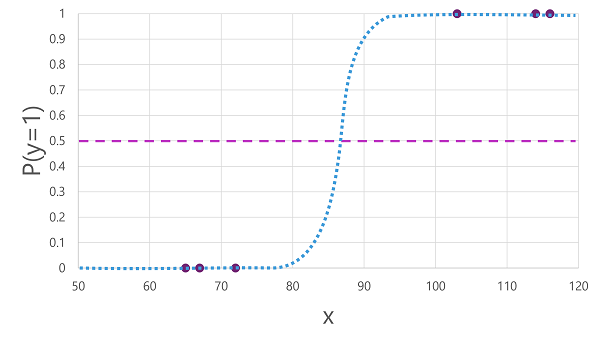
มีอัลกอริทึมจํานวนมากที่สามารถใช้สําหรับการจําแนกประเภทไบนารี เช่น การถดถอยโลจิสติกส์ ซึ่งได้รับฟังก์ชัน sigmoid (รูป S) ที่มีค่าระหว่าง 0.0 และ 1.0 ดังนี้:
หมายเหตุ
แม้จะชื่อเป็นเช่นนี้ แต่ในการเรียนรู้ของเครื่อง การถดถอยโลจิสติกส์จะใช้สำหรับการจัดประเภท ไม่ใช่การถดถอย จุดสําคัญคือลักษณะ ลอจิสติกส์ ของฟังก์ชันที่ผลิตซึ่งอธิบายเส้นโค้งรูป S ระหว่างค่าที่ต่ํากว่าและสูงสุด (0.0 และ 1.0 เมื่อใช้สําหรับการจําแนกประเภทไบนารี)
ฟังก์ชันที่สร้างขึ้นโดยอัลกอริทึมจะอธิบายความน่าจะเป็นของ y เป็น true (y=1) สําหรับค่าที่กําหนดของ x ในทางคณิตศาสตร์ คุณสามารถแสดงฟังก์ชันดังนี้:
f(x) = P(y=1 | x)
สําหรับการสังเกตสามข้อในข้อมูลการฝึก เราทราบว่า yเป็นความจริงอย่างแน่นอน ดังนั้นความน่าจะเป็นสําหรับการสังเกตการณ์เหล่านั้นที่ y=1 คือ 1.0 และสําหรับทั้งสาม เราทราบว่า y เป็นเท็จอย่างแน่นอน ดังนั้นความน่าจะเป็นที่ y=1 คือ 0.0 เส้นโค้งรูปตัว S จะอธิบายการแจกแจงความน่าจะเป็น เพื่อให้การลงจุดค่าของ x บนเส้นระบุความน่าจะเป็นที่สอดคล้องกันที่ y คือ 1
แผนภาพยังมีเส้นแนวนอนเพื่อระบุ ค่าเกณฑ์ ที่แบบจําลองที่ยึดตามฟังก์ชันนี้จะทํานาย true (1) หรือ false (0) ค่าเกณฑ์อยู่ที่จุดกลางสําหรับ y (P(y) = 0.5) สําหรับค่าใด ๆ ที่จุดนี้หรือสูงกว่า แบบจําลองจะคาดการณ์ ว่า true (1) ในขณะที่สําหรับค่าใด ๆ ที่ต่ํากว่าจุดนี้จะคาดการณ์ เท็จ (0) ตัวอย่างเช่น สําหรับผู้ป่วยที่มีระดับน้ําตาลในเลือด 90 ฟังก์ชันจะส่งผลให้มีค่าความน่าจะเป็น 0.9 เนื่องจาก 0.9 สูงกว่าค่าเกณฑ์ 0.5 แบบจําลองจะคาดการณ์ ว่าเป็นจริง (1) หรืออีกนัยหนึ่งผู้ป่วยคาดว่าจะมีโรคเบาหวาน
การประเมินแบบจําลองการจัดประเภทไบนารี
เช่นเดียวกับการถดถอยเมื่อฝึกแบบจําลองการจัดประเภทไบนารีคุณจะเก็บชุดย่อยแบบสุ่มของข้อมูลที่จะตรวจสอบแบบจําลองที่ได้รับการฝึก สมมติว่าเราเก็บข้อมูลต่อไปนี้เพื่อตรวจสอบตัวจําแนกประเภทโรคเบาหวานของเรา:
| น้ําตาลกลูโคสในเลือด (x) | เป็นเบาหวาน? (y) |
|---|---|
| 66 | 0 |
| 107 | 1 |
| 112 | 1 |
| 71 | 0 |
| 87 | 1 |
| 89 | 1 |
การใช้ฟังก์ชันลอจิสติกส์ที่เราสร้างขึ้นก่อนหน้านี้กับค่า x ส่งผลให้เกิดแผนภูมิต่อไปนี้
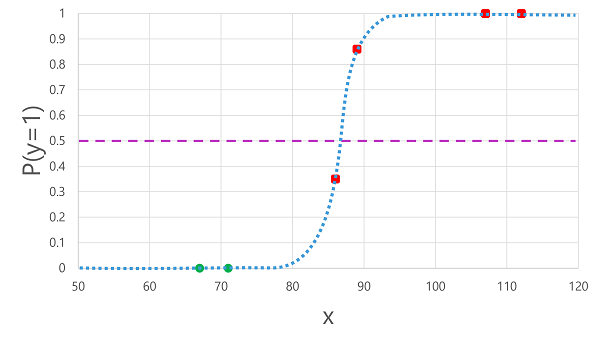
แบบจําลองจะสร้างป้ายชื่อที่คาดการณ์ไว้ 1 หรือ 0 สําหรับการสังเกตการณ์แต่ละรายการ โดยขึ้นอยู่กับว่าความน่าจะเป็นที่คํานวณโดยฟังก์ชันอยู่เหนือหรือต่ํากว่าค่าเกณฑ์ จากนั้นเราสามารถเปรียบเทียบป้ายชื่อระดับชั้น ที่ทํานาย (ŷ) กับป้ายชื่อระดับชั้น จริง (y) ดังที่แสดงไว้ที่นี่:
| น้ําตาลกลูโคสในเลือด (x) | การวินิจฉัยโรคเบาหวานที่แน่ชัด (y) | การวินิจฉัยโรคเบาหวานที่คาดการณ์ได้ (ŷ) |
|---|---|---|
| 66 | 0 | 0 |
| 107 | 1 | 1 |
| 112 | 1 | 1 |
| 71 | 0 | 0 |
| 87 | 1 | 0 |
| 89 | 1 | 1 |
เมตริกการประเมินการจัดประเภทไบนารี
ขั้นตอนแรกในการคํานวณเมตริกการประเมินผลสําหรับแบบจําลองการจัดประเภทแบบไบนารีมักจะสร้างเมทริกซ์ของจํานวนการคาดการณ์ที่ถูกต้องและไม่ถูกต้องสําหรับแต่ละป้ายชื่อคลาสที่เป็นไปได้:
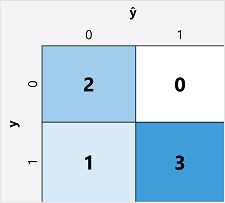
การแสดงภาพนี้เรียกว่า เมทริกซ์ความสับสน และแสดงผลรวมการคาดการณ์ที่:
- ŷ=0 และ y=0: ผลลบจริง (TN)
- ŷ=1 และ y=0: ผลบวกเท็จ (FP)
- ŷ=0 และ y=1: ผลลบเท็จ (FN)
- ŷ=1 และ y=1: ผลบวกจริง (TP)
การจัดเรียงของเมทริกซ์ความสับสนคือการทํานายที่ถูกต้อง (จริง) จะแสดงในเส้นทแยงมุมจากบนซ้ายไปด้านล่างขวา บ่อยครั้งที่ความเข้มของสีถูกใช้เพื่อระบุจำนวนการคาดการณ์ในแต่ละเซลล์ เพียงแค่มองแวบเดียวที่แบบจำลองก็จะสามารถเห็นแนวโน้มในแนวทแยงมุมที่มีการแรเงาอย่างเข้มได้หากแบบจำลองนั้นสามารถคาดการณ์ได้ดี
ความถูกต้อง
เมตริกที่ง่ายที่สุดที่คุณสามารถคํานวณได้จากเมทริกซ์ความสับสนคือ ความแม่นยํา - สัดส่วนของการคาดการณ์ที่แบบจําลองได้รับถูกต้อง ความถูกต้องจะถูกคํานวณเป็น:
(TN + TP) ÷ (TN + FN + FP + TP)
ในกรณีของตัวอย่างโรคเบาหวานของเราการคํานวณคือ:
(2+3) ÷ (2+1+0+3)
= 5 ÷ 6
= 0.83
ดังนั้นตามข้อมูลตรวจสอบความถูกต้องแล้ว แบบจำลองการจัดประเภทโรคเบาหวานสร้างการคาดการณ์ที่ถูกต้องอยู่ที่ 83%
ในตอนแรก ความแม่นยําอาจดูเหมือนเป็นเมตริกที่ดีในการประเมินแบบจําลอง แต่ลองพิจารณาสิ่งนี้ สมมติว่า 11% ของประชากรเป็นโรคเบาหวาน คุณสามารถสร้างแบบจําลองที่ทํานาย 0 เสมอและจะทําให้มีความแม่นยํา 89%แม้ว่าจะไม่มีความพยายามจริงในการแยกความแตกต่างระหว่างผู้ป่วยโดยการประเมินคุณลักษณะของพวกเขา สิ่งที่เราต้องการคือความเข้าใจอย่างลึกซึ้งว่าแบบจําลองทํางานอย่างไรเมื่อทํานาย 1 สําหรับกรณีเชิงบวกและ 0 สําหรับกรณีเชิงลบ
การจดจำได้
การเรียกใช้ คือเมตริกที่วัดสัดส่วนของกรณีเชิงบวกที่แบบจําลองระบุอย่างถูกต้อง กล่าวอีกนัยหนึ่งเมื่อเทียบกับจํานวนผู้ป่วย ที่มี โรคเบาหวานแบบจําลองนี้ คาดการณ์ ว่าจะมีโรคเบาหวานจํานวนเท่าใด
สูตรสําหรับการเรียกใช้คือ:
÷ TP (TP+FN)
สําหรับตัวอย่างโรคเบาหวานของเรา:
3 ÷ (3+1)
= 3 ÷ 4
= 0.75
ดังนั้นแบบจำลองของเราระบุว่าผู้ป่วย 75% เปอร์เซ็นต์ที่มีโรคเบาหวานว่าเป็นโรคเบาหวานได้อย่างถูกต้อง
ความแม่นยำ
ความแม่นยำคือเมตริกที่คล้ายกันกับการจดจำได้ แต่จะวัดสัดส่วนของกรณีผลบวกที่คาดการณ์ไว้ ซึ่งป้ายกำกับจริงเป็นผลบวกจริง กล่าวอีกนัยหนึ่งสัดส่วนของผู้ป่วยที่คาดการณ์โดยแบบจําลองจะมีโรคเบาหวานจริง ๆ
สูตรสําหรับความแม่นยําคือ:
÷ TP (TP+FP)
สําหรับตัวอย่างโรคเบาหวานของเรา:
3 ÷ (3+0)
= 3 ÷ 3
= 1.0
ดังนั้น 100% ของผู้ป่วยที่ทํานายโดยแบบจําลองของเราจะมีโรคเบาหวานในความเป็นจริงมีโรคเบาหวาน
ค่า F1
F1-score เป็นเมตริกโดยรวมที่รวมการเรียกคืนและความแม่นยํา สูตรสําหรับคะแนน F1 คือ:
(2 x ค่าความแม่นยํา x ค่าความระลึก) ÷ (ความแม่นยํา + การเรียกใช้)
สําหรับตัวอย่างโรคเบาหวานของเรา:
(2 x 1.0 x 0.75) ÷ (1.0 + 0.75)
= 1.5 ÷ 1.75
= 0.86
พื้นที่ภายใต้เส้นโค้ง (AUC)
ชื่ออื่นสําหรับการเรียกใช้คืออัตราบวกจริง (TPR) และมีเมตริกที่เทียบเท่าที่เรียกว่าอัตราบวกเท็จ (FPR) ซึ่งคํานวณเป็น FP÷(FP + TN) เราทราบแล้วว่า TPR สําหรับแบบจําลองของเราเมื่อใช้ค่าเกณฑ์ 0.5 คือ 0.75 และเราสามารถใช้สูตรสําหรับ FPR เพื่อคํานวณค่า 0÷2 = 0 ได้
แน่นอนว่า หากเราต้องการเปลี่ยนแปลงค่าเกณฑ์ที่สูงกว่าที่แบบจําลองคาดการณ์ ว่าเป็นจริง (1) แบบจําลองจะส่งผลกระทบต่อจํานวนการคาดการณ์เชิงบวกและเชิงลบ และดังนั้นจึงเปลี่ยนเมตริก TPR และ FPR เมตริกเหล่านี้มักจะใช้เพื่อประเมินแบบจําลองโดยการลงจุดเส้นโค้ง ลักษณะตัวดําเนินการ ( ROC) ที่ได้รับซึ่งเปรียบเทียบ TPR และ FPR สําหรับค่าเกณฑ์ที่เป็นไปได้ทั้งหมดระหว่าง 0.0 และ 1.0:
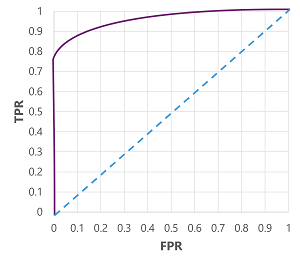
เส้นโค้ง ROC สําหรับแบบจําลองที่สมบูรณ์แบบจะตรงไปยังแกน TPR ทางด้านซ้ายแล้วข้ามแกน FPR ที่ด้านบน เนื่องจากพื้นที่การลงจุดสำหรับเส้นโค้งจะวัด 1x1 โดยพื้นที่ใต้เส้นโค้งที่สมบูรณ์แบบนี้จะเป็น 1.0 (ซึ่งหมายความว่าแบบจำลองถูกต้อง 100%) ในทางตรงกันข้าม เส้นทแยงมุมจากด้านล่างซ้ายไปด้านบนขวาแสดงผลลัพธ์ที่สามารถทําได้โดยการเดาป้ายชื่อไบนารีแบบสุ่ม การผลิตพื้นที่ภายใต้เส้นโค้งของ 0.5 กล่าวอีกนัยหนึ่ง เมื่อกำหนดป้ายชื่อคลาสสองป้าย คุณอาจคาดเดาได้อย่างถูกต้อง 50%
ในกรณีของโมเดลโรคเบาหวานของเรา เราได้ผลิตเส้นโค้งดังกล่าว และ พื้นที่ใต้เส้นโค้ง (AUC) คือ 0.875 เนื่องจาก AUC สูงกว่า 0.5 เราสามารถสรุปแบบจําลองได้ดีขึ้นในการคาดการณ์ว่าผู้ป่วยมีโรคเบาหวานมากกว่าการคาดเดาแบบสุ่มหรือไม่