การเรียนรู้เชิงลึก
หมายเหตุ
ดูแท็บ ข้อความและรูปภาพ สําหรับรายละเอียดเพิ่มเติม!
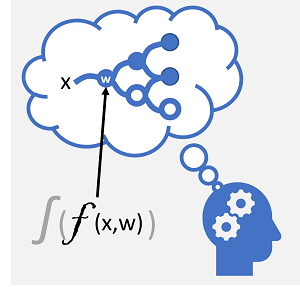
การเรียนรู้เชิงลึก เป็นรูปแบบขั้นสูงของการเรียนรู้ของเครื่องที่พยายามเลียนแบบวิธีที่สมองมนุษย์เรียนรู้ กุญแจสําคัญในการเรียนรู้เชิงลึกคือการสร้าง เครือข่ายประสาท เทียมที่จําลองกิจกรรมทางเคมีไฟฟ้าในเซลล์ประสาทชีวภาพโดยใช้ฟังก์ชั่นทางคณิตศาสตร์ดังที่แสดงไว้ที่นี่
| เครือข่ายประสาทชีวภาพ | เครือข่ายประสาทเทียม |
|---|---|

|
|
| เซลล์ประสาททำงานเมื่อได้รับการกระตุ้นทางเคมีไฟฟ้า เมื่อถูกไล่ออกสัญญาณจะถูกส่งผ่านไปยังเซลล์ประสาทที่เชื่อมต่อ | เซลล์ประสาทแต่ละอันเป็นฟังก์ชันที่ทํางานเกี่ยวกับค่าอินพุต (x) และ น้ําหนัก (w) ฟังก์ชันนี้รวมอยู่ในฟังก์ชันการเปิดใช้งานที่กำหนดว่าจะส่งผลลัพธ์ต่อไปหรือไม่ |
เครือข่ายประสาทเทียมสร้างขึ้นจากเซลล์ประสาทหลาย ชั้น - โดยพื้นฐานแล้วจะกําหนดฟังก์ชั่นที่ซ้อนกันลึก สถาปัตยกรรมนี้เป็นเหตุผลที่จะเรียกว่า เทคนิคการเรียนรู้เชิงลึก และแบบจําลองที่ผลิตโดยมักจะเรียกว่า เครือข่ายประสาทลึก (DNNs) คุณสามารถใช้เครือข่ายประสาทลึกสําหรับปัญหาการเรียนรู้ของเครื่องหลายชนิด รวมถึงการถดถอยและการจําแนกประเภทตลอดจนแบบจําลองพิเศษเพิ่มเติมสําหรับการประมวลผลภาษาธรรมชาติและวิสัยทัศน์คอมพิวเตอร์
เช่นเดียวกับเทคนิคการเรียนรู้ของเครื่องอื่น ๆ ที่กล่าวถึงในโมดูลนี้ การเรียนรู้เชิงลึกเกี่ยวข้องกับการปรับข้อมูลการฝึกให้เหมาะกับฟังก์ชันที่สามารถคาดการณ์ป้ายชื่อ (y) ตามค่าของคุณลักษณะอย่างน้อยหนึ่งอย่าง (x) ฟังก์ชัน (f(x)) เป็นชั้นนอกของฟังก์ชันที่ซ้อนกันซึ่งแต่ละเลเยอร์ของเครือข่ายประสาทห่อหุ้มฟังก์ชันที่ทํางานบน x และค่าน้ําหนัก (w) ที่เกี่ยวข้อง อัลกอริทึมที่ใช้ในการฝึกแบบจําลองเกี่ยวข้องกับการป้อนค่าคุณลักษณะ (x) อย่างต่อเนื่องในข้อมูลการฝึกไปข้างหน้าผ่านเลเยอร์เพื่อคํานวณค่าเอาต์พุตสําหรับ ŷ การตรวจสอบความถูกต้องของแบบจําลองเพื่อประเมินว่าค่า ŷ ที่คํานวณมาจากค่า y ที่รู้จักหรือไม่ (ซึ่งกําหนดระดับของข้อผิดพลาดหรือ การสูญเสียในแบบจําลอง) และจากนั้นแก้ไขน้ําหนัก (w) เพื่อลดการสูญเสีย แบบจําลองที่ได้รับการฝึกนั้นมีค่าน้ําหนักสุดท้ายที่ส่งผลให้เกิดการคาดการณ์ที่ถูกต้องที่สุด
ตัวอย่าง - การใช้การเรียนรู้เชิงลึกสําหรับการจัดประเภท
เพื่อให้เข้าใจวิธีการทํางานของรูปแบบเครือข่ายประสาทอย่างลึกซึ้ง เรามาสํารวจตัวอย่างที่ใช้เครือข่ายประสาทเพื่อกําหนดแบบจําลองการจําแนกประเภทสําหรับสายพันธุ์นกเพนกวิน
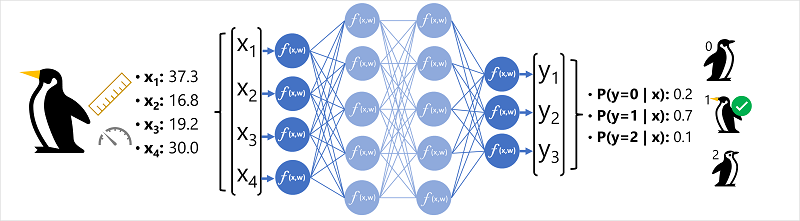
ข้อมูลคุณลักษณะ (x) ประกอบด้วยการวัดบางอย่างของนกเพนกวิน โดยเฉพาะการวัดคือ:
- ความยาวของปากนกเพนกวิน
- ความลึกของจะงอยปากนกเพนกวิน
- ความยาวของครีบนกเพนกวิน
- น้ําหนักของนกเพนกวิน
ในกรณีนี้ x เป็นเวกเตอร์ของสี่ค่าหรือทางคณิตศาสตร์ x=[x1,x2,x3,x4]
ป้ายชื่อที่เราพยายามทํานาย (y) คือสายพันธุ์ของนกเพนกวินและอาจมีสามชนิดที่เป็นไปได้ซึ่งอาจเป็น:
- Adelie
- เกนทู
- ชินสเตรป
นี่คือตัวอย่างของปัญหาการจัดประเภทซึ่งแบบจําลองการเรียนรู้ของเครื่องจะต้องคาดการณ์คลาสที่น่าจะเป็นไปได้มากที่สุดที่เป็นส่วนสังเกตการณ์ แบบจําลองการจัดประเภททําสิ่งนี้โดยการคาดการณ์ป้ายชื่อที่ประกอบด้วยความน่าจะเป็นสําหรับแต่ละคลาส กล่าวอีกนัยหนึ่ง y คือเวกเตอร์ของค่าความน่าจะเป็นสามค่า หนึ่งคลาสสําหรับแต่ละคลาสที่เป็นไปได้: [P(y=0|x), P(y=1|x), P(y=2|x)]
กระบวนการสําหรับการอนุมานคลาสนกเพนกวินที่คาดการณ์ไว้โดยใช้เครือข่ายนี้คือ:
- เวกเตอร์คุณลักษณะสําหรับการสังเกตนกเพนกวินถูกป้อนลงในชั้นอินพุตของเครือข่ายประสาทซึ่งประกอบด้วยเซลล์ประสาทสําหรับแต่ละค่า x ในตัวอย่างนี้ x เวกเตอร์ต่อไปนี้ถูกใช้เป็นข้อมูลป้อนเข้า: [37.3, 16.8, 19.2, 30.0]
- ฟังก์ชันสําหรับชั้นแรกของเซลล์ประสาทแต่ละชั้นคํานวณผลรวมถ่วงน้ําหนักโดยการรวมค่า x และ น้ําหนักและ ส่งผ่านไปยังฟังก์ชันการเปิดใช้งานที่กําหนดว่าเป็นไปตามเกณฑ์ที่จะส่งผ่านไปยังเลเยอร์ถัดไปหรือไม่
- เซลล์ประสาทแต่ละรายการในเลเยอร์เชื่อมต่อกับเซลล์ประสาททั้งหมดในชั้นถัดไป (บางครั้งสถาปัตยกรรมเรียกว่า เครือข่ายที่เชื่อมต่ออย่างสมบูรณ์) ดังนั้นผลลัพธ์ของแต่ละชั้นจะถูกป้อนไปข้างหน้าผ่านทางเครือข่ายจนกว่าจะถึงชั้นเอาต์พุต
- ชั้นเอาต์พุตสร้างเวกเตอร์ของค่า ในกรณีนี้ การใช้ softmax หรือฟังก์ชันที่คล้ายกันเพื่อคํานวณการแจกแจงความน่าจะเป็นสําหรับนกเพนกวินทั้งสามชั้นที่เป็นไปได้ ในตัวอย่างนี้ เวกเตอร์ผลลัพธ์คือ: [0.2, 0.7, 0.1]
- องค์ประกอบของเวกเตอร์แสดงถึงความน่าจะเป็นสําหรับคลาส 0, 1 และ 2 ค่าที่สองคือค่าสูงสุดดังนั้นแบบจําลองทํานายว่าสายพันธุ์ของนกเพนกวินเป็น 1 (เกนทู)
เครือข่ายประสาทเรียนรู้อย่างไร
น้ําหนักในเครือข่ายประสาทเป็นศูนย์กลางสําหรับวิธีการคํานวณค่าที่คาดการณ์สําหรับป้ายชื่อ ในระหว่างกระบวนการฝึกอบรม แบบจําลองจะ เรียนรู้ น้ําหนักที่จะส่งผลให้เกิดการคาดการณ์ที่ถูกต้องที่สุด เรามาสํารวจกระบวนการฝึกอบรมในรายละเอียดเพิ่มเติมเล็กน้อยเพื่อทําความเข้าใจว่าการเรียนรู้นี้เกิดขึ้นได้อย่างไร
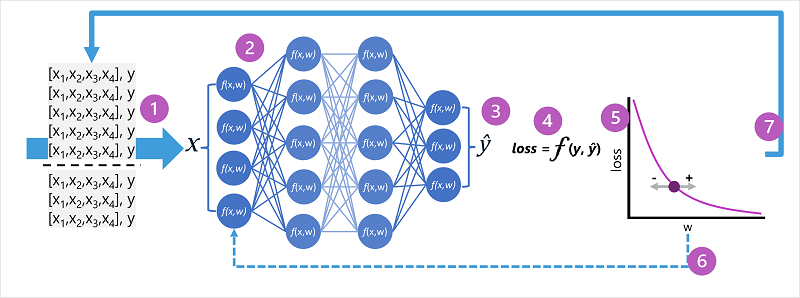
- ชุดข้อมูลการฝึกอบรมและการตรวจสอบความถูกต้องถูกกําหนดและคุณลักษณะการฝึกอบรมจะถูกป้อนลงในเลเยอร์อินพุต
- เซลล์ประสาทในแต่ละชั้นของเครือข่ายใช้น้ําหนักของพวกเขา (ซึ่งในขั้นต้นจะถูกกําหนดแบบสุ่ม) และให้ข้อมูลผ่านเครือข่าย
- ชั้นเอาต์พุตสร้างเวกเตอร์ที่ประกอบด้วยค่าที่คํานวณสําหรับ ŷ ตัวอย่างเช่น ผลลัพธ์สําหรับการคาดการณ์คลาสนกเพนกวินอาจเป็น [0.3 0.1. 0.6]
- ฟังก์ชัน Loss ใช้เพื่อเปรียบเทียบค่า ŷ ที่ทํานายกับค่า y ที่รู้จักและรวมความแตกต่าง (ซึ่งเรียกว่าการสูญเสีย) ตัวอย่างเช่น ถ้าคลาสที่ทราบสําหรับกรณีที่ส่งกลับผลลัพธ์ในขั้นตอนก่อนหน้าคือ Chinstrap ค่า y ควรเป็น [0.0, 0.0, 1.0] ความแตกต่างอย่างแน่นอนระหว่างสิ่งนี้และ ŷ เวกเตอร์คือ [0.3, 0.1, 0.4] ในความเป็นจริง ฟังก์ชัน Loss จะคํานวณค่าความแปรปรวนรวมสําหรับหลายกรณี และสรุปเป็นค่า การสูญเสีย เดียว
- เนื่องจากเครือข่ายทั้งหมดเป็นฟังก์ชั่นที่ซ้อนกันขนาดใหญ่ฟังก์ชั่นการเพิ่มประสิทธิภาพสามารถใช้ calculus ที่แตกต่างกันในการประเมินอิทธิพลของน้ําหนักแต่ละรายการในเครือข่ายในการสูญเสียและกําหนดวิธีการปรับปรุง (ขึ้นหรือลง) เพื่อลดจํานวนการสูญเสียโดยรวม เทคนิคการปรับให้เหมาะสมเฉพาะอาจแตกต่างกัน แต่โดยปกติแล้วจะเกี่ยวข้องกับวิธีการไล่ ระดับความชัน ที่ซึ่งน้ำหนักแต่ละตัวจะเพิ่มขึ้นหรือลดลงเพื่อให้การสูญเสียลดลง
- การเปลี่ยนแปลงของน้ําหนักจะถูก ส่งกลับ ไปยังเลเยอร์ในเครือข่ายแทนที่ค่าที่ใช้ก่อนหน้านี้
- กระบวนการนี้จะถูกทำซ้ำในหลายรอบการฝึก (เรียกว่า epochs) จนกว่าค่าความสูญเสียจะลดลงและแบบจำลองสามารถทำนายได้อย่างถูกต้องตามที่ยอมรับได้
หมายเหตุ
ในขณะที่เป็นการง่ายที่จะคิดถึงแต่ละกรณีในข้อมูลการฝึกที่ส่งผ่านเครือข่ายทีละครั้งในความเป็นจริงข้อมูลจะถูกรวมเป็นเมทริกซ์และประมวลผลโดยใช้การคํานวณพีชคณิตเชิงเส้น ด้วยเหตุนี้การฝึกอบรมเครือข่ายประสาทจะทํางานได้ดีที่สุดในคอมพิวเตอร์ที่มีหน่วยประมวลผลแบบกราฟิก (GPUs) ที่ปรับให้เหมาะสมสําหรับการจัดการเวกเตอร์และเมทริกซ์