การรู้จําเสียง
Tip
ดูแท็บ ข้อความและรูปภาพ สําหรับรายละเอียดเพิ่มเติม!
การรู้จําเสียง หรือที่มักเรียกว่า การแปลงคําพูดเป็นข้อความ (STT) เป็นความสามารถของ AI ที่ช่วยให้แอปและตัวแทนสามารถตอบสนองต่อการป้อนข้อมูลด้วยเสียงพูดได้ การรู้จําเสียงจะนําคําพูดมาแปลงเป็นข้อมูล ซึ่งมักจะเป็นข้อความ ซอฟต์แวร์แปลงคําพูดเป็นข้อความมักใช้หลายรุ่น ได้แก่:
- โมเดล อะคูสติก ที่แปลงเสียงเป็นหน่วยเสียง (การแสดงเสียงเฉพาะ)
- โมเดล ภาษา ที่แมปหน่วยเสียงกับคํา
คําว่า AI ที่รับรู้เสียงพูดจะถูกแปลงเป็นข้อความ คุณสามารถใช้ข้อความเพื่อวัตถุประสงค์ต่างๆ เช่น การให้คําบรรยาย การสร้างการถอดเสียงการโทร การเขียนตามคําบอกโน้ตโดยอัตโนมัติ และอื่นๆ อีกมากมาย
Azure Speech - คําพูดเป็นข้อความ
Azure Speech มี API การแปลงคําพูดเป็นข้อความ ที่คุณสามารถใช้เพื่อประมวลผลการป้อนข้อมูลด้วยเสียงจากไมโครโฟนหรือไฟล์เสียง
Note
API (Application Programming Interface) คือชุดของกฎและปลายทางที่ช่วยให้แอปพลิเคชันซอฟต์แวร์หนึ่งสามารถสื่อสารและใช้ฟังก์ชันหรือข้อมูลของแอปพลิเคชันอื่นได้
Microsoft Foundry เป็นแพลตฟอร์มของ Microsoft ที่ช่วยให้นักพัฒนาสร้าง ทดสอบ และปรับใช้แอปพลิเคชันและเอเจนต์ AI โดยการรวบรวมโมเดล เครื่องมือ ข้อมูล และบริการไว้ในที่เดียว
ในพอร์ทัล Microsoft Foundry ใหม่ เราสามารถสํารวจความสามารถในการแปลงคําพูดเป็นข้อความของ Azure Speech ได้ใน Playground ของ Foundry หากต้องการไปที่ Playground ให้ไปที่หน้า Build จากนั้นไปที่ Models จากนั้นไปที่แท็บ AI Services ในแท็บ คุณจะพบบริการ AI ที่พร้อมใช้งานสําหรับการทดสอบ รวมถึง Azure Speech - Speech to Text
ใน Playground คุณสามารถอัปโหลดไฟล์เสียงหรือบันทึกการพูดของตัวเองได้ Azure Speech ถอดเสียงสิ่งที่พูด ทําให้คุณรู้สึกว่าแอปพลิเคชันของคุณจะตอบสนองต่ออินพุตเสียงอย่างไร

สนามเด็กเล่นในพอร์ทัล Foundry เป็นสถานที่ที่ยอดเยี่ยมในการทดลองกับ Azure Speech แต่หากต้องการใช้การแปลงคําพูดเป็นข้อความในแอปพลิเคชันเราจําเป็นต้องเขียนโค้ดบางอย่าง
การใช้ SDK การแปลงคําพูดเป็นข้อความของ Azure
Azure Speech – Speech-to-Text SDK เป็นไลบรารีไคลเอ็นต์ที่ช่วยให้แอปพลิเคชันแปลงเสียงพูดเป็นข้อความเขียน SDK การแปลงคําพูดเป็นข้อความได้รับการออกแบบมาเพื่อให้การเพิ่มการรู้จําเสียงลงในแอปพลิเคชันได้ง่าย
Note
ไลบรารีไคลเอ็นต์คือชุดโค้ดสําเร็จรูปที่นักพัฒนาสามารถใช้ในแอปพลิเคชันของตนเพื่อพูดคุยกับบริการหรือ API ได้อย่างง่ายดาย
SDK ช่วยให้แอปพลิเคชันของคุณทําสิ่งต่อไปนี้ได้
- จับภาพหรือส่งเสียงจากไมโครโฟน ไฟล์เสียง หรือสตรีมเสียง
- ส่งเสียงนั้นไปยัง Azure Speech อย่างปลอดภัย
- รับข้อความที่ถอดเสียงแบบเกือบเรียลไทม์หรือหลังจากการประมวลผลเสร็จสิ้น
SDK จัดการเครือข่าย การรับรองความถูกต้อง การสตรีมเสียง และการแยกวิเคราะห์การตอบสนอง เพื่อให้นักพัฒนาสามารถมุ่งเน้นไปที่ตรรกะของแอปพลิเคชันได้
การพัฒนาแอปพลิเคชัน
โดยทั่วไปแล้ว SDK การแปลงคําพูดเป็นข้อความจะใช้ในไคลเอ็นต์หรือเลเยอร์บริการของแอปพลิเคชัน SDK ทําหน้าที่เป็นสะพานเชื่อมระหว่างรหัสแอปพลิเคชันของคุณและบริการ Azure Speech
เมื่อต้องการใช้ Azure Speech Python SDK คุณต้องมี Python เวอร์ชันที่เข้ากันได้และ Azure Speech Python SDK ติดตั้งอยู่
Python SDK สามารถติดตั้งใน เทอร์มินัล Visual Studio Code ได้โดยใช้:
pip install azure-cognitiveservices-speech
Note
โค้ดแอปพลิเคชันเขียนในตัว แก้ไขโค้ด เช่น Visual Studio Code เทอร์มินัลของตัวแก้ไขโค้ดคือหน้าต่างบรรทัดคําสั่งในตัวในตัวแก้ไข ซึ่งคุณสามารถเรียกใช้คําสั่งได้โดยไม่ต้องออกจากสภาพแวดล้อมการพัฒนาของคุณ
เมื่อต้องการใช้ Azure Speech คุณยังต้องสร้างทรัพยากร Foundry ด้วย ตําแหน่งข้อมูลและคีย์ทรัพยากร Foundry ใช้ในโค้ดของคุณเพื่อรับรองความถูกต้องของการเชื่อมต่อของคุณ
หลังจากที่คุณติดตั้ง Python SDK และสร้างทรัพยากร Foundry แล้ว คุณสามารถสร้างและเรียกใช้โปรแกรมของคุณได้ พิจารณารหัส Python ต่อไปนี้ เมื่อคุณเรียกใช้:
- แอปของคุณเริ่มต้น Speech SDK: ให้จุดสิ้นสุดและการรับรองความถูกต้อง (คีย์หรือ Microsoft Entra ID)
- บันทึกหรือโหลดเสียง: อินพุตไมโครโฟนหรือเสียง file/สตรีม
- เสียงถูกส่งไปยัง Azure Speech: SDK สตรีมหรืออัปโหลดเสียงอย่างปลอดภัย
- การรู้จําเสียงทํางานในระบบคลาวด์: โมเดลเสียงพูดของ Azure วิเคราะห์เสียง
- ผลลัพธ์ของข้อความจะถูกส่งคืน: แอปของคุณได้รับข้อความที่รู้จักและข้อมูลเมตาที่ไม่บังคับ
import azure.cognitiveservices.speech as speechsdk
# Set up the speech config using resource endpoint
endpoint_url = "ENDPOINT"
speech_key = "FOUNDRY_KEY"
speech_config = speechsdk.SpeechConfig(
subscription=speech_key,
endpoint=endpoint_url
)
# Create a recognizer with microphone input
audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True)
speech_recognizer = speechsdk.SpeechRecognizer(
speech_config=speech_config,
audio_config=audio_config
)
# Event handlers
def recognized_handler(evt):
print(f"Recognized: {evt.result.text}")
def recognizing_handler(evt):
print(f"Recognizing: {evt.result.text}")
# Connect event handlers
speech_recognizer.recognized.connect(recognized_handler)
speech_recognizer.recognizing.connect(recognizing_handler)
# Start continuous recognition
speech_recognizer.start_continuous_recognition()
print("Say something...")
# Keep the program running
input("Press Enter to stop...")
speech_recognizer.stop_continuous_recognition()
ตัวอย่างแอปไคลเอ็นต์
ตัวอย่างเช่น สมมติว่าคุณต้องการพัฒนาแอปขนาดเล็กที่ถอดเสียงข้อความเสียงโดยอัตโนมัติ ในตัวแก้ไขโค้ด เรามีไฟล์เสียงหนึ่งไฟล์และไฟล์ Python หนึ่งไฟล์ ซึ่งมีโค้ดแอปพลิเคชัน
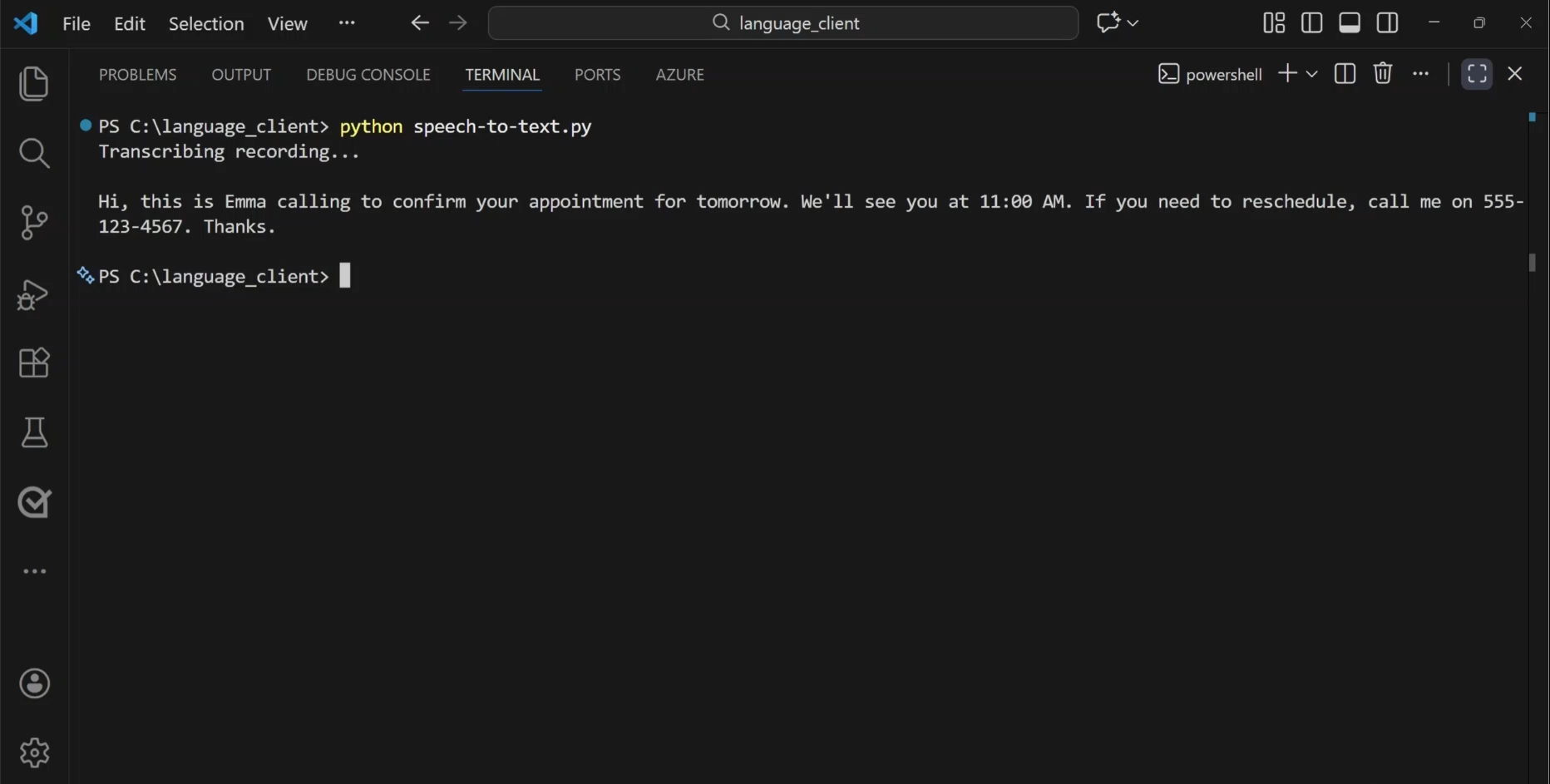
สมมติว่าคุณมีไฟล์เสียงที่มีการบันทึกข้อความเสียง หากต้องการถอดเสียงข้อความ ให้เริ่มต้นด้วยการระบุปลายทางและคีย์ และแหล่งเสียงที่คุณต้องการถอดเสียง จากนั้นใช้ SpeechRecognizer วัตถุเพื่อทําการถอดความก่อนที่จะแสดงผลลัพธ์

เมื่อคุณเรียกใช้โค้ด คุณจะเห็นข้อความการถอดเสียง
ตัวเลือกการประมวลผลเสียง
คุณสามารถใช้ API การแปลงคําพูดเป็นข้อความของ Azure Speech เพื่อทําการถอดเสียงแบบเรียลไทม์หรือเป็นชุดในรูปแบบข้อความ แหล่งเสียงสําหรับการถอดเสียงสามารถเป็นสตรีมเสียงแบบเรียลไทม์จากไมโครโฟนหรือไฟล์เสียงได้
การถอดเสียงแบบเรียลไทม์: การแปลงเสียงพูดเป็นข้อความแบบเรียลไทม์ช่วยให้คุณสามารถถอดเสียงสตรีมเสียงเป็นข้อความได้ คุณสามารถใช้การถอดเสียงแบบเรียลไทม์สําหรับการนําเสนอ การสาธิต หรือสถานการณ์อื่น ๆ ที่บุคคลนั้นพูดได้
แอปพลิเคชันของคุณต้องรอรับฟังเสียงจากไมโครโฟน หรือแหล่งสัญญาณเสียงเข้าอื่น ๆ เช่น ไฟล์เสียง รหัสแอปพลิเคชันของคุณจะสตรีมเสียงไปยังบริการ ซึ่งส่งกลับข้อความอธิบาย
การถอดเสียงเป็นชุด: สถานการณ์การเปลี่ยนคําพูดเป็นข้อความไม่ใช่ทุกสถานการณ์แบบเรียลไทม์ คุณอาจมีการบันทึกเสียงที่จัดเก็บไว้ในการแชร์ไฟล์ เซิร์ฟเวอร์ระยะไกล หรือแม้กระทั่งบนที่เก็บข้อมูล Azure คุณสามารถชี้ไปยังไฟล์เสียงด้วย URI ลายเซ็นสําหรับการเข้าถึงที่ใช้ร่วมกัน (SAS) และได้รับผลลัพธ์การถอดข้อความแบบอะซิงโครนัส
ควรรันการถอดข้อความชุดงานแบบอะซิงโครนัสเนื่องจากมีการจัดกําหนดการชุดงานโดยใช้ความพยายามอย่างดีที่สุด โดยปกติงานจะเริ่มดําเนินการภายในไม่กี่นาทีของคําขอ แต่ไม่มีการประเมินสําหรับเมื่องานเปลี่ยนเป็นสถานะกําลังทํางาน
การรู้จําเสียงใน Azure Speech เป็นวิธีที่ยอดเยี่ยมในการสร้างโซลูชันที่ถอดเสียงเสียงที่บันทึกไว้หรือคําบรรยายเสียงพูดโดยอัตโนมัติ เรียนรู้วิธีรวมการสังเคราะห์เสียงพูดเข้ากับแอปพลิเคชัน