กําหนดสถาปัตยกรรม ส่วนประกอบ และฟังก์ชันการทํางานของการทําซ้ําข้อมูล
องค์กรและธุรกิจส่วนใหญ่ รวมถึง Contoso ต้องจัดการกับการประมวลผลและจัดเก็บข้อมูลในปริมาณที่เพิ่มขึ้น แม้ว่าจะมีโซลูชันที่ช่วยให้คุณสามารถถ่ายถ่ายข้อมูลและเก็บถาวรข้อมูลไปยังระบบคลาวด์ได้ แต่ในหลายกรณี จําเป็นต้องบํารุงรักษาในศูนย์ข้อมูลภายในองค์กร การจัดการที่มีประสิทธิภาพในการจัดเก็บข้อมูลดังกล่าวต้องใช้เครื่องมือที่เหมาะสม เมื่อใช้ Windows Server คุณมีตัวเลือกในการใช้เพื่อการทําซ้ําข้อมูลเพื่อวัตถุประสงค์นี้
การทําซ้ําข้อมูลคืออะไร
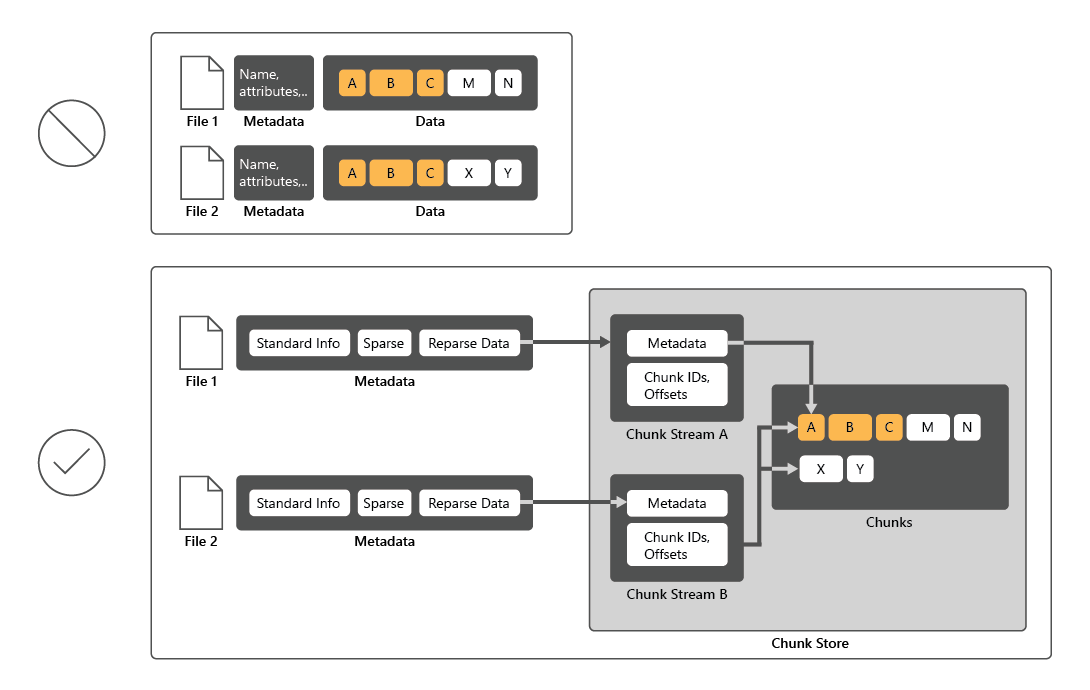
Data Deduplication คือบริการบทบาทของ Windows Server ที่ระบุและลบการทําซ้ําภายในข้อมูลโดยไม่ลดความสมบูรณ์ของข้อมูล ซึ่งบรรลุเป้าหมายในการจัดเก็บข้อมูลเพิ่มเติมและใช้เนื้อที่ดิสก์จริงน้อยลง
เพื่อลดการใช้งานดิสก์ Data Deduplication จะสแกนไฟล์ แล้วแบ่งไฟล์เหล่านั้นออกเป็นกลุ่ม และเก็บสําเนาของแต่ละกลุ่มเพียงหนึ่งชุดเท่านั้น หลังจากทําซ้ํา ไฟล์จะไม่ถูกจัดเก็บเป็นสตรีมข้อมูลอิสระอีกต่อไป แต่ Data Deduplication จะแทนที่ไฟล์ด้วย stubs ที่ชี้ไปยังบล็อกข้อมูลที่จัดเก็บไว้ในที่เก็บกลุ่มทั่วไป กระบวนการในการเข้าถึงข้อมูลซ้ําซ้อนนั้นโปร่งใสสําหรับผู้ใช้และแอป
ในหลายกรณี การทําซ้ําข้อมูลจะเพิ่มประสิทธิภาพโดยรวมของดิสก์ เนื่องจากหลายไฟล์สามารถแชร์หนึ่งกลุ่มที่แคชไว้ในหน่วยความจําได้ ด้วยวิธีนี้ อาจเป็นไปได้ที่จะดึงข้อมูลจากไฟล์เหล่านี้โดยการดําเนินการอ่านน้อยลงซึ่งชดเชยผลกระทบต่อประสิทธิภาพการทํางานเล็ก ๆ เมื่ออ่านไฟล์ที่ซ้ําซ้อน การทําซ้ําข้อมูลไม่มีผลกระทบต่อประสิทธิภาพการทํางานของการเขียนดิสก์เนื่องจากนําไปใช้กับข้อมูลที่อยู่ในดิสก์อยู่แล้ว
คอมโพเนนต์ของการทําสําเนาข้อมูลคืออะไร
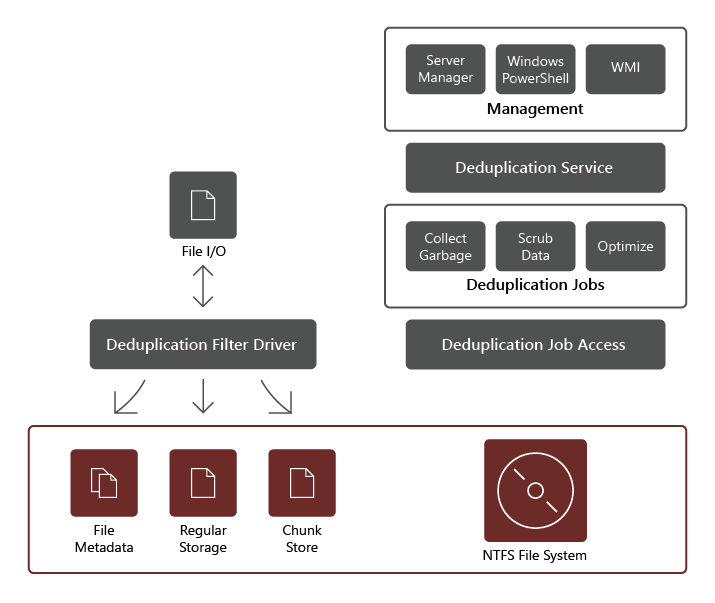
บริการบทบาท Deduplication Data ประกอบด้วยคอมโพเนนต์ต่อไปนี้:
- โปรแกรมควบคุมตัวกรอง คอมโพเนนต์นี้จะเปลี่ยนเส้นทางการร้องขอการอ่านไปยังกลุ่มที่เป็นส่วนหนึ่งของแฟ้มที่ร้องขอ มีฟิลเตอร์ไดรเวอร์หนึ่งตัวสําหรับทุกวอลุ่ม
- บริการ Deduplication คอมโพเนนต์นี้จะจัดการงานต่อไปนี้:
- การทําซ้ําและการบีบอัด งานเหล่านี้ประมวลผลไฟล์ตามนโยบายการทําซ้ําข้อมูลสําหรับไดรฟ์ข้อมูล หลังจากการปรับไฟล์ให้เหมาะสมเริ่มต้น หากมีการปรับเปลี่ยนไฟล์แล้วและตรงตามค่าเกณฑ์ของนโยบายการทําซ้ําสําหรับการปรับให้เหมาะสม ไฟล์จะถูกปรับให้เหมาะสมอีกครั้ง
- การเก็บขยะ กระบวนการงานนี้จะลบหรือปรับเปลี่ยนข้อมูลบนไดรฟ์ข้อมูลเพื่อให้กลุ่มข้อมูลใด ๆ ที่ไม่ถูกอ้างอิงถูกล้างและทําให้พื้นที่ว่างในดิสก์ถูกล้าง ตามค่าเริ่มต้นคอลเลกชันขยะจะทํางานทุกสัปดาห์ อย่างไรก็ตามคุณอาจพิจารณาการเรียกหลังจากลบไฟล์จํานวนมาก
- การขัดถู งานนี้อาศัยคุณลักษณะความยืดหยุ่นดังกล่าว เช่น การตรวจสอบความถูกต้องของ checksum และการตรวจสอบความสอดคล้องของเมตาดาต้า เพื่อระบุและเมื่อใดก็ตามที่เป็นไปได้ ให้แก้ไขปัญหาความสมบูรณ์ของข้อมูลโดยอัตโนมัติ
หมายเหตุ
เนื่องจากความสามารถในการตรวจสอบเพิ่มเติม การทําสําเนาสามารถตรวจจับและรายงานสัญญาณเริ่มต้นของข้อมูลเสียหายได้
- ยกเลิกการปิดใช้ งานนี้จะย้อนกลับการทําซ้ําบนแฟ้มที่ได้รับการปรับให้เหมาะสมทั้งหมดบนไดรฟ์ข้อมูล บางสถานการณ์ทั่วไปสําหรับการใช้งานประเภทนี้ประกอบด้วยการแก้ไขปัญหาเกี่ยวกับข้อมูลที่ซ้ําซ้อนหรือการย้ายข้อมูลไปยังระบบอื่นที่ไม่รองรับการทําซ้ําข้อมูล
หมายเหตุ
ก่อนที่คุณจะเริ่มงานนี้ คุณควรใช้ cmdlet ของ Disable-DedupVolume Windows PowerShell เพื่อปิดใช้งานกิจกรรมการทําซ้ําข้อมูลเพิ่มเติมในหนึ่งหรือหลายวอลุ่ม
หมายเหตุ
หลังจากปิดใช้งานการทําซ้ําข้อมูล ปริมาณยังคงอยู่ในสถานะทําซ้ํา และข้อมูล deduplicated ที่มีอยู่ยังคงสามารถเข้าถึงได้ อย่างไรก็ตาม เซิร์ฟเวอร์หยุดเรียกใช้งานการปรับให้เหมาะสมสําหรับไดรฟ์ข้อมูล และจะไม่ทําซ้ําข้อมูลใหม่ หลังจากนั้น คุณสามารถใช้งานยกเลิกการเลือกเพื่อยกเลิกข้อมูลซ้ําซ้อนที่มีอยู่ในไดรฟ์ข้อมูล ในตอนท้ายของงานยกเลิกการปรับให้เหมาะสมสําเร็จ เมตาดาต้า deduplication ทั้งหมดจะถูกลบออกจากปริมาณ
สําคัญ
เมื่อใช้งานที่ไม่ได้ปรับให้เหมาะสมตรวจสอบให้แน่ใจว่าไดรฟ์ข้อมูลที่โฮสต์ข้อมูลนี้มีพื้นที่ว่างเพียงพอเพราะไฟล์ที่ทําซ้ําทั้งหมดจะกลับไปเป็นขนาดเดิม
ขอบเขตของการทําซ้ําข้อมูล
ข้อมูล Deduplication ประมวลผลข้อมูลทั้งหมดบนไดรฟ์ข้อมูลที่เลือก โดยมีข้อยกเว้นบางอย่าง รวมถึง:
- ไฟล์ที่ไม่ตรงตามนโยบายการทําซ้ําที่คุณกําหนดค่า
- ไฟล์ในโฟลเดอร์ที่คุณแยกออกอย่างชัดเจนจากขอบเขตการทําซ้ํา
- แฟ้มสถานะของระบบ
- สตรีมข้อมูลสํารอง
- ไฟล์ที่เข้ารหัสลับ
- ไฟล์ที่มีแอตทริบิวต์เพิ่มเติม
- ไฟล์ที่มีขนาดเล็กกว่า 32 KB
หมายเหตุ
ตั้งแต่ Windows Server 2019 ระบบไฟล์ที่ยืดหยุ่น (ReFS) สนับสนุนการทําซ้ําข้อมูลสําหรับปริมาณสูงสุด 64 เทราไบต์ (TB) ในขนาดและไฟล์ที่มีขนาดสูงสุด 4 TB นอกจากนี้ยังอาศัยที่เก็บขนาดตัวแปรที่รวมถึงการบีบอัดเพิ่มเติมเพื่อเพิ่มการประหยัดพื้นที่ดิสก์ในขณะที่สถาปัตยกรรมหลังการประมวลผลแบบหลายเธรดทําให้ประสิทธิภาพการทํางานต่ําที่สุด