เครือข่ายประสาทปฏิวัติ
หมายเหตุ
ดูแท็บ ข้อความและรูปภาพ สําหรับรายละเอียดเพิ่มเติม!
ความสามารถในการใช้ฟิลเตอร์เพื่อนำเอฟเฟ็กต์ไปใช้กับรูปภาพมีประโยชน์ในงานประมวลผลรูปภาพ เช่นเดียวกับที่คุณอาจใช้ด้วยซอฟต์แวร์ตัดต่อรูปภาพ อย่างไรก็ตาม เป้าหมายของคอมพิวเตอร์วิทัศน์มักจะเป็นการดึงความหมายหรือข้อมูลเชิงลึกที่ดำเนินการได้เป็นอย่างน้อยจากรูปภาพ ซึ่งต้องมีการสร้างโมเดลการเรียนรู้ของเครื่องที่ได้รับการฝึกให้จดจำคุณลักษณะตามรูปภาพที่มีอยู่จำนวนมาก
เคล็ดลับ
บทเรียนนี้จะถือว่าคุณคุ้นเคยกับหลักการพื้นฐานเกี่ยวกับการเรียนรู้ของเครื่อง และคุณมีความรู้เชิงมโนทัศน์เกี่ยวกับการเรียนรู้เชิงลึกด้วยโครงข่ายประสาทเทียมแล้ว ถ้าคุณยังใหม่กับการเรียนรู้ของเครื่อง ให้พิจารณาดําเนินการ บทนําสู่มอดูลการเรียนรู้ของเครื่อง ใน Microsoft Learn ให้เสร็จสมบูรณ์
หนึ่งในสถาปัตยกรรมโมเดลการเรียนรู้ของเครื่องที่ใช้กันมากที่สุดสำหรับคอมพิวเตอร์วิทัศน์คือโครงข่ายประสาทเทียมแบบสังวัตนาการ (CNN) ซึ่งเป็นสถาปัตยกรรมการเรียนรู้เชิงลึกประเภทหนึ่ง CNN ใช้ตัวกรองเพื่อแยกการแมปคุณลักษณะที่เป็นตัวเลขจากรูปภาพ จากนั้นจึงป้อนค่าของคุณลักษณะลงในโมเดลการเรียนรู้เชิงลึกเพื่อสร้างการคาดคะเนป้ายกำกับ ตัวอย่างเช่น ในสถานการณ์ของการจัดประเภทรูปภาพ ป้ายกำกับจะแสดงถึงหัวข้อหลักของรูปภาพ (หรืออีกนัยหนึ่งคือ รูปภาพนี้คืออะไร) คุณอาจฝึกโมเดล CNN ด้วยรูปภาพผลไม้ประเภทต่างๆ (เช่น แอปเปิ้ล กล้วย และส้ม) เพื่อให้ป้ายกำกับที่มีการคาดคะเนไว้คือประเภทของผลไม้ในรูปภาพที่กำหนด
ในระหว่างกระบวนการฝึกสำหรับ CNN จะมีการกำหนดเคอร์เนลในขั้นต้นโดยใช้ค่าน้ำหนักถ่วงที่สร้างขึ้นแบบสุ่ม จากนั้น เมื่อกระบวนการฝึกดำเนินต่อไป การคาดคะเนโมเดลจะได้รับการประเมินโดยเทียบกับค่าป้ายกำกับที่ทราบ และน้ำหนักถ่วงตัวกรองจะได้รับการปรับเพื่อปรับปรุงความแม่นยำ ในท้ายที่สุดแล้ว โมเดลการจัดประเภทรูปภาพผลไม้ที่ได้รับการฝึกจะใช้น้ำหนักถ่วงตัวกรองที่จะแยกคุณลักษณะที่ดีที่สุดที่ช่วยระบุผลไม้ประเภทต่างๆ ได้ดีที่สุด
ไดอะแกรมต่อไปนี้แสดงวิธีการทำงานของ CNN สำหรับโมเดลการจัดประเภทรูปภาพ:
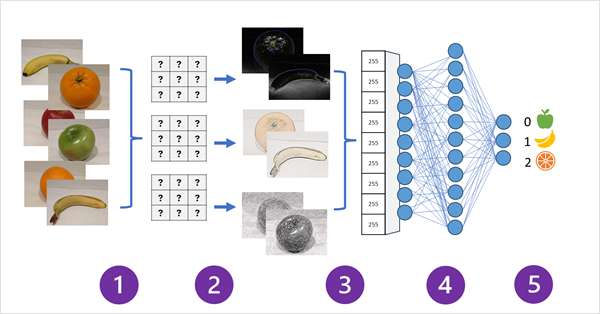
- ระบบจะป้อนรูปภาพที่มีป้ายกำกับที่รู้จัก (ตัวอย่างเช่น 0: แอปเปิ้ล, 1: กล้วย หรือ 2: ส้ม) เข้าสู่เครือข่ายเพื่อฝึกโมเดล
- มีการใช้ตัวกรองตั้งแต่หนึ่งชั้นขึ้นไปเพื่อแยกคุณลักษณะจากแต่ละรูปภาพในขณะที่มีการป้อนผ่านเครือข่าย เคอร์เนลตัวกรองเริ่มต้นด้วยน้ำหนักถ่วงที่ได้รับการกำหนดแบบสุ่ม และสร้างอาร์เรย์ของค่าที่เป็นตัวเลขที่เรียกว่าการแมปคุณลักษณะ เลเยอร์เพิ่มเติมอาจ "พูล" หรือ "ลดขนาด" แมปคุณลักษณะเพื่อสร้างอาร์เรย์ขนาดเล็กที่เน้นคุณลักษณะภาพหลักที่ดึงออกมาโดยตัวกรอง
- การแมปคุณลักษณะจะได้รับการแปรสภาพเป็นอาร์เรย์ค่าของคุณลักษณะในมิติเดียว
- ระบบจะป้อนค่าของคุณลักษณะเข้าสู่โครงข่ายประสาทเทียมที่เชื่อมต่อกันอย่างสมบูรณ์
- ชั้นกระแสข้อมูลของโครงข่ายประสาทเทียมใช้ Softmax หรือฟังก์ชันที่คล้ายคลึงกันเพื่อสร้างผลลัพธ์ที่มีค่าความน่าจะเป็นสำหรับแต่ละคลาสที่เป็นไปได้ ตัวอย่างเช่น [0.2, 0.5, 0.3]
ในระหว่างการฝึก ความน่าจะเป็นของกระแสข้อมูลจะได้รับการเปรียบเทียบกับป้ายกำกับคลาสปัจจุบัน - ตัวอย่างเช่น รูปภาพของกล้วย (คลาส 1) ควรมีค่า [0.0, 1.0, 0.0] ระบบจะนำความแตกต่างระหว่างคะแนนของคลาสที่คาดคะเนไว้และคะแนนจริงมาใช้ในการคำนวณการสูญเสียในโมเดล และน้ำหนักถ่วงในโครงข่ายประสาทเทียมที่เชื่อมต่อกันอย่างสมบูรณ์และเคอร์เนลตัวกรองในชั้นข้อมูลการแยกคุณลักษณะได้รับการแก้ไขเพื่อลดการสูญเสีย
กระบวนการฝึกจะดำเนินการซ้ำในหลายรอบจนกว่าจะได้เรียนรู้ถึงชุดน้ำหนักถ่วงที่เหมาะสมที่สุด จากนั้น จะมีการบันทึกน้ำหนักถ่วง และสามารถใช้โมเดลเพื่อคาดคะเนป้ายกำกับสำหรับรูปภาพใหม่ที่ยังไม่ทราบป้ายกำกับได้
หมายเหตุ
โดยทั่วไปแล้ว สถาปัตยกรรมของ CNN จะรวมชั้นข้อมูลตัวกรองแบบสังวัตนาการหลายชั้นและชั้นข้อมูลเพิ่มเติมเพื่อลดขนาดของการแมปคุณลักษณะ จำกัดค่าที่แยกออกมา และจัดการค่าของคุณลักษณะ ชั้นข้อมูลเหล่านี้จะถูกละเว้นไว้ในตัวอย่างที่เรียบง่ายนี้เพื่อมุ่งเน้นไปยังแนวคิดหลัก นั่นคือการใช้ตัวกรองเพื่อแยกคุณลักษณะที่เป็นตัวเลขจากรูปภาพ ซึ่งจะมีการใช้ในโครงข่ายประสาทเทียมเพื่อคาดคะเนป้ายกำกับรูปภาพ