หม้อแปลงวิชันและโมเดลหลายรูปแบบ
หมายเหตุ
ดูแท็บ ข้อความและรูปภาพ สําหรับรายละเอียดเพิ่มเติม!
CNN เป็นหัวใจสำคัญของโซลูชันด้านคอมพิวเตอร์วิทัศน์มานานหลายปีแล้ว แม้ว่าโดยทั่วไปแล้วจะมีการใช้เพื่อแก้ไขปัญหาด้านการจัดประเภทรูปภาพตามที่อธิบายไว้ก่อนหน้านี้ แต่ก็ยังคงถือเป็นพื้นฐานสำหรับโมเดลคอมพิวเตอร์วิทัศน์ที่ซับซ้อนมากขึ้นอีกด้วย ตัวอย่างเช่น โมเดลการตรวจหาวัตถุจะรวมเลเยอร์การแยกคุณลักษณะของ CNN เข้ากับการระบุพื้นที่ที่สนใจในรูปภาพ เพื่อค้นหาวัตถุหลายคลาสในรูปภาพเดียวกัน ความก้าวหน้ามากมายในคอมพิวเตอร์วิทัศน์ในช่วงหลายทศวรรษที่ผ่านมาได้รับแรงหนุนจากการปรับปรุงโมเดลที่ใช้ CNN
อย่างไรก็ตาม ในอีกสาขาวิชาด้าน AI อย่างการประมวลผลภาษาธรรมชาติ (NLP) ซึ่งเป็นสถาปัตยกรรมเครือข่ายประสาทเทียมอีกประเภทหนึ่งที่เรียกว่าตัวแปลงได้สนับสนุนการพัฒนาโมเดลที่ซับซ้อนสำหรับภาษา
การสร้างแบบจําลองความหมายสําหรับภาษา - Transformers
ตัวแปลงทำงานโดยการประมวลผลข้อมูลปริมาณมหาศาล และการเข้ารหัสโทเค็นภาษา (แทนแต่ละคำหรือวลี) เป็นการฝังแบบเวกเตอร์ (อาร์เรย์ของค่าที่เป็นตัวเลข) เทคนิคที่เรียกว่า ความสนใจ ใช้เพื่อกําหนดค่าการฝังที่สะท้อนถึงแง่มุมต่างๆ ของวิธีการใช้โทเค็นแต่ละโทเค็นในบริบทของโทเค็นอื่นๆ คุณสามารถคิดว่าการฝังเป็นเวกเตอร์ในพื้นที่หลายมิติ ซึ่งแต่ละมิติจะฝังแอตทริบิวต์ทางภาษาของโทเค็นตามบริบทในข้อความการฝึกอบรม โทเค็นที่ใช้กันทั่วไปในบริบทที่คล้ายคลึงกันจะกําหนดเวกเตอร์ที่สอดคล้องกันอย่างใกล้ชิดมากกว่าคําที่ไม่เกี่ยวข้อง
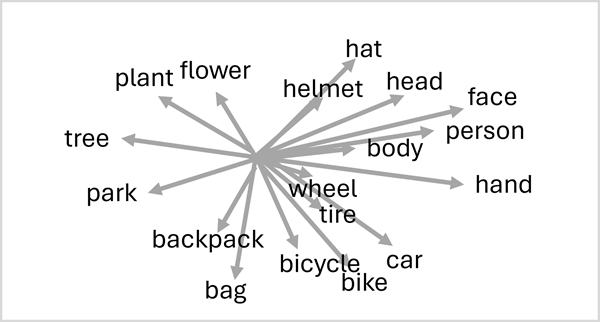
โทเค็นที่มีความหมายคล้ายกันมีการเข้ารหัสในทิศทางที่คล้ายกัน การสร้างแบบจําลองภาษาเชิงความหมายที่ทําให้สามารถสร้างโซลูชัน NLP ที่มีความซับซ้อนสําหรับการวิเคราะห์ข้อความ การแปล การสร้างภาษา และงานอื่น ๆ
หมายเหตุ
ในความเป็นจริงแล้ว ตัวเข้ารหัสในเครือข่ายตัวแปลงจะสร้างเวกเตอร์ที่มีมิติมากขึ้น โดยกำหนดความสัมพันธ์เชิงความหมายที่ซับซ้อนระหว่างโทเค็นตามการคำนวณด้วยพีชคณิตเชิงเส้น คณิตศาสตร์ที่เกี่ยวข้องมีความซับซ้อน เช่นเดียวกับสถาปัตยกรรมของโมเดลตัวแปลง เป้าหมายของเรา ณ จุดนี้คือเพียงเพื่อสร้างความเข้าใจเชิงมโนทัศน์ถึงวิธีการที่การเข้ารหัสสร้างโมเดลที่สรุปความสัมพันธ์ระหว่างเอนทิตี
แบบจําลองความหมายสําหรับรูปภาพ - Vision transformers
ความสำเร็จของตัวแปลงในฐานะวิธีการสร้างโมเดลภาษาทำให้นักวิจัยด้าน AI ต้องพิจารณาว่าแนวทางเดียวกันนี้จะมีประสิทธิภาพกับข้อมูลรูปภาพหรือไม่ ผลที่ได้คือการพัฒนาแบบจําลอง หม้อแปลงภาพ (ViT) ซึ่งโมเดลได้รับการฝึกฝนโดยใช้ภาพจํานวนมาก แทนที่จะเข้ารหัสโทเค็นแบบข้อความ หม้อแปลงจะแยก แพตช์ ของค่าพิกเซลออกจากรูปภาพ และสร้างเวกเตอร์เชิงเส้นจากค่าพิกเซล

เทคนิค ความสนใจ แบบเดียวกับที่ใช้ในโมเดลภาษาเพื่อฝังความสัมพันธ์ตามบริบทระหว่างโทเค็น ถูกใช้เพื่อกําหนดความสัมพันธ์ตามบริบทระหว่างแพตช์ ข้อแตกต่างที่สําคัญคือแทนที่จะเข้ารหัสลักษณะทางภาษาลงในเวกเตอร์การฝังค่าที่ฝังจะขึ้นอยู่กับคุณลักษณะทางภาพ เช่น สี รูปร่าง คอนทราสต์ พื้นผิว และอื่นๆ ผลลัพธ์ที่ได้คือชุดของเวกเตอร์การฝังที่สร้าง "แผนที่" หลายมิติของคุณลักษณะภาพตามที่เห็นได้ทั่วไปในภาพการฝึกอบรม
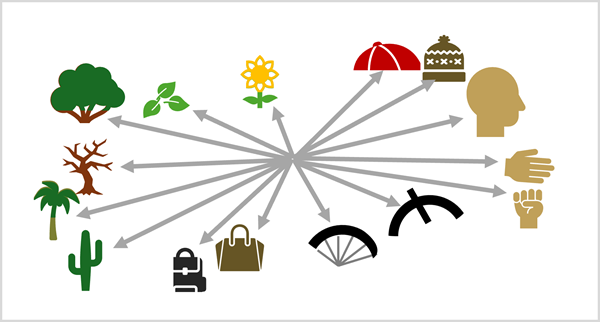
เช่นเดียวกับโมเดลภาษา การฝังส่งผลให้คุณลักษณะภาพที่ใช้ในบริบทที่คล้ายคลึงกันถูกกําหนดทิศทางเวกเตอร์ที่คล้ายคลึงกัน ตัวอย่างเช่น ลักษณะการมองเห็นที่พบได้ทั่วไปใน หมวก อาจเกี่ยวข้องกับบริบทของคุณลักษณะทางภาพที่พบได้ทั่วไปใน ศีรษะ เพราะสองสิ่งมักจะเห็นด้วยกัน นางแบบไม่เข้าใจว่า "หมวก" หรือ "ศีรษะ" คืออะไร แต่สามารถอนุมานความสัมพันธ์ทางความหมายระหว่างลักษณะทางสายตาได้
นําทุกอย่างมารวมกัน - โมเดลมัลติโมดอล
ตัวแปลงภาษาสร้างการฝังที่กําหนดคําศัพท์ทางภาษาที่เข้ารหัสความสัมพันธ์ทางความหมายระหว่างคํา หม้อแปลงวิชันจะสร้างคําศัพท์ภาพที่ทําเช่นเดียวกันกับคุณสมบัติภาพ เมื่อข้อมูลการฝึกอบรมมีรูปภาพพร้อมคําอธิบายข้อความที่เกี่ยวข้องเราสามารถรวมตัวเข้ารหัสจากหม้อแปลงทั้งสองนี้ในแบบจําลอง หลายรูปแบบ และใช้เทคนิคที่เรียกว่า cross-model attention เพื่อกําหนดการแสดงเชิงพื้นที่แบบรวมของการฝังเช่นนี้
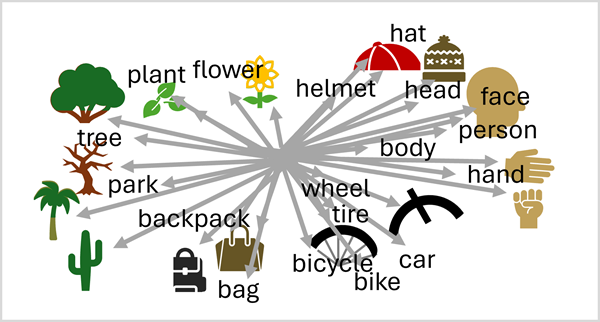
การผสมผสานระหว่างการฝังภาษาและการมองเห็นนี้ช่วยให้โมเดลสามารถแยกแยะความสัมพันธ์ทางความหมายระหว่างภาษาและคุณลักษณะของภาพ ความสามารถนี้จะช่วยให้โมเดลสามารถคาดการณ์คําอธิบายที่ซับซ้อนสําหรับรูปภาพที่ไม่เคยเห็นมาก่อน โดยการจดจําคุณลักษณะของภาพและค้นหาพื้นที่เวกเตอร์ที่ใช้ร่วมกันสําหรับภาษาที่เกี่ยวข้อง

คนในสวนสาธารณะพร้อมหมวกและกระเป๋าเป้สะพายหลัง