การรู้จําตัวอักษรด้วยแสง (OCR)
หมายเหตุ
ดูแท็บ ข้อความและรูปภาพ สําหรับรายละเอียดเพิ่มเติม!
การรู้จําอักขระด้วยแสง (OCR) เป็นเทคโนโลยีที่แปลงข้อความภาพในรูปภาพโดยอัตโนมัติ ไม่ว่าจะจากเอกสารที่สแกน ภาพถ่าย หรือไฟล์ดิจิทัล ให้เป็นข้อมูลข้อความที่แก้ไขและค้นหาได้ แทนที่จะถอดเสียงข้อมูลด้วยตนเอง OCR ช่วยให้สามารถดึงข้อมูลอัตโนมัติจาก:
- ใบแจ้งหนี้และใบเสร็จรับเงินที่สแกน
- ภาพถ่ายดิจิทัลของเอกสาร
- ไฟล์ PDF ที่มีรูปภาพของข้อความ
- ภาพหน้าจอและเนื้อหาที่บันทึกไว้
- แบบฟอร์มและบันทึกย่อที่เขียนด้วยลายมือ
ไปป์ไลน์ OCR: กระบวนการทีละขั้นตอน
ไปป์ไลน์ OCR ประกอบด้วยห้าขั้นตอนสําคัญที่ทํางานร่วมกันเพื่อแปลงข้อมูลภาพเป็นข้อมูลข้อความ
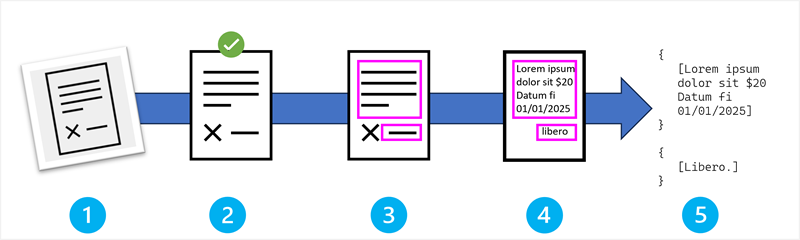
ขั้นตอนในกระบวนการ OCR คือ:
- การรับภาพและการป้อนข้อมูล
- การประมวลผลล่วงหน้าและการปรับปรุงภาพ
- การตรวจจับขอบเขตข้อความ
- การจดจําอักขระและการจําแนกประเภท
- การสร้างผลลัพธ์และการประมวลผลภายหลัง
ลองตรวจสอบแต่ละขั้นตอนในเชิงลึกมากขึ้น
ขั้นตอนที่ 1: การรับและการป้อนภาพ
ไปป์ไลน์เริ่มต้นเมื่อรูปภาพที่มีข้อความเข้าสู่ระบบ นี่อาจเป็น:
- ภาพถ่ายที่ถ่ายด้วยกล้องสมาร์ทโฟน
- เอกสารที่สแกนจากเครื่องสแกนเอกสารแบบแท่นหรือเอกสาร
- เฟรมที่แยกจากสตรีมวิดีโอ
- หน้า PDF ที่แสดงเป็นรูปภาพ
เคล็ดลับ
คุณภาพของภาพในขั้นตอนนี้ส่งผลกระทบอย่างมากต่อความแม่นยําขั้นสุดท้ายของการแยกข้อความ
ขั้นตอนที่ 2: การประมวลผลล่วงหน้าและการปรับปรุงภาพ
ก่อนเริ่มการตรวจจับข้อความ จะใช้เทคนิคต่อไปนี้เพื่อเพิ่มประสิทธิภาพรูปภาพเพื่อความแม่นยําในการจดจําที่ดีขึ้น:
การลดสัญญาณรบกวนจะขจัดสิ่งประดิษฐ์ทางภาพ จุดฝุ่น และความไม่สมบูรณ์ของการสแกนที่อาจรบกวนการตรวจจับข้อความ เทคนิคเฉพาะที่ใช้ในการลดสัญญาณรบกวน ได้แก่:
- อัลกอริธึมการกรองและการประมวลผลภาพ: ฟิลเตอร์เกาส์เซียน ฟิลเตอร์มัธยฐาน และการดําเนินการทางสัณฐานวิทยา
- โมเดลแมชชีนเลิร์นนิง: การลดเสียงรบกวนของตัวเข้ารหัสอัตโนมัติและโครงข่ายประสาทเทียมแบบบิดเบี้ยว (CNN) ที่ได้รับการฝึกอบรมโดยเฉพาะสําหรับการล้างข้อมูลรูปภาพเอกสาร
การปรับความคมชัด ช่วยเพิ่มความแตกต่างระหว่างข้อความและพื้นหลังเพื่อทําให้อักขระมีความชัดเจนมากขึ้น อีกครั้งมีหลายวิธีที่เป็นไปได้:
- วิธีการแบบคลาสสิก: การปรับสมดุลฮิสโตแกรม เกณฑ์การปรับตัว และการแก้ไขแกมมา
- แมชชีนเลิร์นนิง: โมเดลการเรียนรู้เชิงลึกที่เรียนรู้พารามิเตอร์การเพิ่มประสิทธิภาพที่เหมาะสมที่สุดสําหรับเอกสารประเภทต่างๆ
การแก้ไขความเอียง จะตรวจจับและแก้ไขการหมุนเอกสาร เพื่อให้มั่นใจว่าบรรทัดข้อความอยู่ในแนวนอนอย่างเหมาะสม เทคนิคการแก้ไขความเอียง ได้แก่ :
- เทคนิคทางคณิตศาสตร์: การแปลง Hough สําหรับการตรวจจับเส้น โปรไฟล์การฉายภาพ และการวิเคราะห์ส่วนประกอบที่เชื่อมต่อ
- แบบจําลองโครงข่ายประสาทเทียม: CNN การถดถอยที่คาดการณ์มุมการหมุนโดยตรงจากคุณสมบัติของภาพ
การเพิ่มประสิทธิภาพความละเอียด จะปรับความละเอียดของภาพให้อยู่ในระดับที่เหมาะสมที่สุดสําหรับอัลกอริธึมการจดจําอักขระ คุณสามารถปรับความละเอียดของภาพให้เหมาะสมได้ด้วย:
- วิธีการแก้ไข: อัลกอริธึมการสุ่มตัวอย่างแบบ Bicubic, bilinear และ Lanczos
- โมเดลความละเอียดสูง: เครือข่ายปฏิปักษ์เชิงกําเนิด (GAN) และเครือข่ายที่เหลือที่ยกระดับรูปภาพข้อความความละเอียดต่ําอย่างชาญฉลาด
ขั้นตอนที่ 3: การตรวจหาขอบเขตข้อความ
ระบบจะวิเคราะห์รูปภาพที่ประมวลผลล่วงหน้าเพื่อระบุพื้นที่ที่มีข้อความโดยใช้เทคนิคต่อไปนี้:
การวิเคราะห์เค้าโครง จะแยกความแตกต่างระหว่างขอบเขตข้อความ รูปภาพ กราฟิก และพื้นที่สีขาว เทคนิคในการวิเคราะห์เค้าโครง ได้แก่ :
- วิธีการแบบดั้งเดิม: การวิเคราะห์ส่วนประกอบที่เชื่อมต่อ การเข้ารหัสความยาวรัน และการแบ่งส่วนตามการฉายภาพ
- โมเดลการเรียนรู้เชิงลึก: เครือข่ายการแบ่งส่วนเชิงความหมาย เช่น U-Net, Mask R-CNN และโมเดลการวิเคราะห์เค้าโครงเอกสารเฉพาะทาง (เช่น LayoutLM หรือโมเดลที่ผ่านการฝึกอบรม PubLayNet)
การระบุบล็อกข้อความจะจัดกลุ่มอักขระแต่ละตัวเป็นคํา บรรทัด และย่อหน้าตามความสัมพันธ์เชิงพื้นที่ แนวทางทั่วไป ได้แก่ :
- วิธีการแบบคลาสสิก: การจัดกลุ่มตามระยะทาง การวิเคราะห์พื้นที่สีขาว และการดําเนินการทางสัณฐานวิทยา
- โครงข่ายประสาทเทียม: โครงข่ายประสาทเทียมกราฟและแบบจําลองหม้อแปลงที่เข้าใจโครงสร้างเอกสารเชิงพื้นที่
การกําหนดลําดับการอ่าน จะกําหนดลําดับที่ควรอ่านข้อความ (จากซ้ายไปขวา จากบนลงล่างสําหรับภาษาอังกฤษ) ลําดับที่ถูกต้องสามารถกําหนดได้โดย:
- ระบบตามกฎ: อัลกอริทึมทางเรขาคณิตโดยใช้พิกัดกล่องขอบเขตและฮิวริสติกเชิงพื้นที่
- โมเดลแมชชีนเลิร์นนิง: โมเดลการคาดการณ์ลําดับและแนวทางตามกราฟที่เรียนรู้รูปแบบการอ่านจากข้อมูลการฝึกอบรม
การจําแนกขอบเขตจะระบุขอบเขตข้อความประเภทต่างๆ (ส่วนหัว ข้อความเนื้อหา คําอธิบายภาพ ตาราง)
- ตัวแยกประเภทตามคุณลักษณะ: รองรับเครื่องเวกเตอร์ (SVM) โดยใช้คุณสมบัติที่สร้างขึ้นด้วยมือ เช่น ขนาดตัวอักษร ตําแหน่ง และการจัดรูปแบบ
- โมเดลการเรียนรู้เชิงลึก: โครงข่ายประสาทเทียมแบบ Convolutional และตัวแปลงวิชันที่ได้รับการฝึกฝนเกี่ยวกับชุดข้อมูลเอกสารที่มีป้ายกํากับ
ขั้นตอนที่ 4: การจดจําอักขระและการจําแนกประเภท
นี่คือหัวใจสําคัญของกระบวนการ OCR ที่มีการระบุอักขระแต่ละตัว:
การแยกคุณสมบัติ: วิเคราะห์รูปร่าง ขนาด และลักษณะเฉพาะของอักขระหรือสัญลักษณ์แต่ละตัว
- วิธีการแบบดั้งเดิม: คุณลักษณะทางสถิติ เช่น ช่วงเวลา ตัวอธิบายฟูริเยร์ และคุณลักษณะโครงสร้าง (ลูป จุดสิ้นสุด จุดตัด)
- แนวทางการเรียนรู้เชิงลึก: โครงข่ายประสาทเทียมแบบ Convolutional ที่เรียนรู้คุณลักษณะการเลือกปฏิบัติโดยอัตโนมัติจากข้อมูลพิกเซลดิบ
การจับคู่รูปแบบ: เปรียบเทียบคุณลักษณะที่แยกออกมากับโมเดลที่ผ่านการฝึกอบรมซึ่งจดจําแบบอักษร ขนาด และสไตล์การเขียนที่แตกต่างกัน
- การจับคู่เทมเพลต: การเปรียบเทียบโดยตรงกับเทมเพลตอักขระที่เก็บไว้โดยใช้เทคนิคความสัมพันธ์
- ตัวแยกประเภททางสถิติ: Hidden Markov Models (HMMs), Support Vector Machines และ k-nearest neighbors โดยใช้เวกเตอร์คุณลักษณะ
- โครงข่ายประสาทเทียม: เพอร์เซปตรอนหลายชั้น CNN และสถาปัตยกรรมพิเศษ เช่น LeNet สําหรับการจดจําตัวเลข
- การเรียนรู้เชิงลึกขั้นสูง: สถาปัตยกรรมเครือข่ายที่เหลือ (ResNet), DenseNet และ EfficientNet เพื่อการจําแนกอักขระที่มีประสิทธิภาพ
การวิเคราะห์บริบท: ใช้อักขระและคําโดยรอบเพื่อปรับปรุงความแม่นยําในการจดจําผ่านการค้นหาพจนานุกรมและแบบจําลองภาษา
- แบบจําลอง N-gram: แบบจําลองภาษาทางสถิติที่ทํานายลําดับอักขระตามการแจกแจงความน่าจะเป็น
- การแก้ไขตามพจนานุกรม: การค้นหาพจนานุกรมด้วยอัลกอริธึมระยะการแก้ไข (เช่น ระยะทาง Levenshtein) สําหรับการแก้ไขการสะกด
- โมเดลภาษาประสาท: LSTM และโมเดลที่ใช้หม้อแปลง (เช่น ตัวแปร BERT) ที่เข้าใจความสัมพันธ์ตามบริบท
- กลไกความสนใจ: โมเดลหม้อแปลงที่มุ่งเน้นไปที่ส่วนที่เกี่ยวข้องของอินพุตเมื่อทําการคาดการณ์อักขระ
การให้คะแนนความเชื่อมั่น: กําหนดคะแนนความน่าจะเป็นให้กับอักขระที่รู้จักแต่ละตัวโดยพิจารณาจากความแน่นอนของระบบเกี่ยวกับการระบุตัวตน
- แนวทางเบย์เซียน: แบบจําลองความน่าจะเป็นที่วัดความไม่แน่นอนในการคาดการณ์อักขระ
- เอาต์พุต Softmax: การเปิดใช้งานเลเยอร์สุดท้ายของโครงข่ายประสาทเทียมที่แปลงเป็นการแจกแจงความน่าจะเป็น
- วิธีการรวม: การรวมการคาดการณ์จากหลายแบบจําลองเพื่อปรับปรุงการประมาณความเชื่อมั่น
ขั้นตอนที่ 5: การสร้างผลลัพธ์และการประมวลผลภายหลัง
ขั้นตอนสุดท้ายจะแปลงผลการจดจําเป็นข้อมูลข้อความที่ใช้งานได้:
การรวบรวมข้อความ: รวบรวมการจดจําอักขระแต่ละตัวเป็นคําและประโยคที่สมบูรณ์
- การประกอบตามกฎ: อัลกอริทึมที่กําหนดซึ่งรวมการคาดการณ์อักขระโดยใช้ความใกล้ชิดเชิงพื้นที่และเกณฑ์ความเชื่อมั่น
- แบบจําลองลําดับ: เครือข่ายโครงข่ายประสาทเทียมที่เกิดซ้ํา (RNN) และเครือข่ายหน่วยความจํา Short-Term ยาว (LSTM) ที่สร้างแบบจําลองข้อความเป็นข้อมูลตามลําดับ
- โมเดลตามความสนใจ: สถาปัตยกรรมหม้อแปลงที่สามารถจัดการลําดับความยาวตัวแปรและเค้าโครงข้อความที่ซับซ้อน
การรักษารูปแบบ: รักษาโครงสร้างเอกสาร รวมถึงย่อหน้า ตัวแบ่งบรรทัด และระยะห่าง
- อัลกอริทึมทางเรขาคณิต: ระบบตามกฎโดยใช้พิกัดกล่องขอบเขตและการวิเคราะห์พื้นที่สีขาว
- โมเดลการทําความเข้าใจเค้าโครง: กราฟโครงข่ายประสาทเทียมและจัดทําเอกสารโมเดล AI ที่เรียนรู้ความสัมพันธ์เชิงโครงสร้าง
- หม้อแปลงหลายรูปแบบ: โมเดลเช่น LayoutLM ที่รวมข้อความและข้อมูลเค้าโครงเพื่อการรักษาโครงสร้าง
การแมปพิกัด: บันทึกตําแหน่งที่แน่นอนของแต่ละองค์ประกอบข้อความภายในรูปภาพต้นฉบับ
- การแปลงพิกัด: การทําแผนที่ทางคณิตศาสตร์ระหว่างพิกเซลรูปภาพและพิกัดเอกสาร
- การจัดทําดัชนีเชิงพื้นที่: โครงสร้างข้อมูล เช่น R-trees และ quad-trees สําหรับการสืบค้นเชิงพื้นที่ที่มีประสิทธิภาพ
- แบบจําลองการถดถอย: โครงข่ายประสาทเทียมที่ได้รับการฝึกฝนให้ทํานายพิกัดการวางตําแหน่งข้อความที่แม่นยํา
การตรวจสอบคุณภาพ: ใช้การตรวจสอบการสะกดและไวยากรณ์เพื่อระบุข้อผิดพลาดในการจดจําที่อาจเกิดขึ้น
- การตรวจสอบความถูกต้องตามพจนานุกรม: ค้นหารายการคําศัพท์ที่ครอบคลุมและคําศัพท์โดเมนเฉพาะ
- แบบจําลองภาษาทางสถิติ: แบบจําลอง N-gram และตัวแยกวิเคราะห์ความน่าจะเป็นสําหรับการตรวจสอบไวยากรณ์และบริบท
- โมเดลภาษาประสาท: โมเดลที่ได้รับการฝึกอบรมล่วงหน้า เช่น GPT หรือ BERT ได้รับการปรับแต่งอย่างละเอียดสําหรับการตรวจจับและแก้ไขข้อผิดพลาด OCR
- การตรวจสอบความถูกต้องของกลุ่ม: การรวมแนวทางการตรวจสอบความถูกต้องที่หลากหลายเพื่อปรับปรุงความแม่นยําในการตรวจจับข้อผิดพลาด