การแยกและการทําแผนที่ภาคสนาม
Note
ดูแท็บ ข้อความและรูปภาพ สําหรับรายละเอียดเพิ่มเติม!
การแยกฟิลด์เป็นกระบวนการในการนําเอาต์พุตข้อความจาก OCR และแมปค่าข้อความแต่ละค่าไปยังฟิลด์ข้อมูลที่มีป้ายกํากับเฉพาะซึ่งสอดคล้องกับข้อมูลทางธุรกิจที่มีความหมาย แม้ว่า OCR จะบอกคุณว่ามีข้อความ ใด บ้างในเอกสาร แต่การแยกฟิลด์จะบอกคุณ ว่าข้อความนั้นหมายถึงอะไร และอยู่ใน ระบบ ธุรกิจของคุณที่ใด
ไปป์ไลน์การสกัดภาคสนาม
การแยกภาคสนามเป็นไปตามไปป์ไลน์ที่เป็นระบบที่แปลงเอาต์พุต OCR เป็นข้อมูลที่มีโครงสร้าง
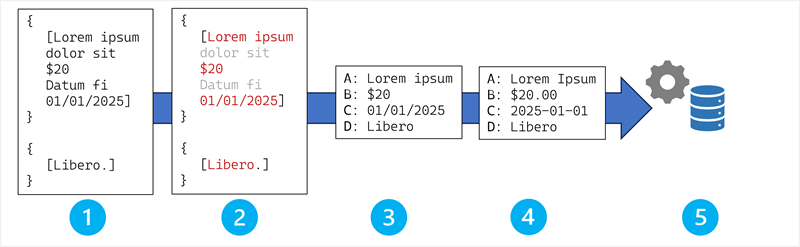
ขั้นตอนในกระบวนการสกัดภาคสนามคือ:
- การนําเข้าเอาต์พุต OCR
- การตรวจจับภาคสนามและการระบุผู้สมัคร
- การแม็ปฟิลด์และการเชื่อมโยง
- การทําให้เป็นมาตรฐานและมาตรฐานของข้อมูล
- การผสานรวมกับกระบวนการและระบบทางธุรกิจ
มาสํารวจขั้นตอนเหล่านี้โดยละเอียดกัน
ขั้นตอนที่ 1: การนําเข้าเอาต์พุต OCR
กระบวนการเริ่มต้นด้วยเอาต์พุตที่มีโครงสร้างจากไปป์ไลน์ OCR ซึ่งอาจรวมถึง:
- เนื้อหาข้อความดิบ: อักขระและคําจริงที่ดึงออกมาจากเอกสาร
- ข้อมูลเมตาของตําแหน่ง: พิกัดกล่องขอบเขต ตําแหน่งของหน้า และการอ่านข้อมูลคําสั่งซื้อ
- คะแนนความเชื่อมั่น: ระดับความเชื่อมั่นของกลไกจัดการ OCR สําหรับแต่ละองค์ประกอบข้อความ
- ข้อมูลเค้าโครง: โครงสร้างเอกสาร ตัวแบ่งบรรทัด ขอบเขตย่อหน้า
Note
ซึ่งแตกต่างจากการประมวลผลข้อความธรรมดาการแยกฟิลด์ขึ้นอยู่กับ ตําแหน่ง ที่ปรากฏของข้อความในเอกสารไม่ใช่แค่สิ่งที่พูด ตําแหน่งของ "12345" อาจช่วยระบุว่าเป็นหมายเลขใบแจ้งหนี้ รหัสลูกค้า หรือหมายเลขโทรศัพท์
ขั้นตอนที่ 2: การตรวจหาภาคสนามและการระบุผู้สมัคร
ขั้นตอนนี้ระบุค่าฟิลด์ที่เป็นไปได้ในเอาต์พุต OCR มีหลายวิธีที่สามารถใช้ได้แยกกันหรือใช้ร่วมกันเพื่อกําหนดฟิลด์ที่เป็นไปได้ในผลลัพธ์ OCR
การตรวจจับตามเทมเพลต
เทมเพลตสําหรับการตรวจหาฟิลด์อาศัยการจับคู่รูปแบบตามกฎ การระบุภาคสนามสามารถทําได้โดยใช้เทคนิคต่างๆเช่น:
- เค้าโครงเอกสารที่กําหนดไว้ล่วงหน้าพร้อมตําแหน่งฟิลด์ที่รู้จักและคําสําคัญ anchor
- ค้นหาคู่ป้ายกํากับ-ค่า เช่น "Invoice Number:", "Date:", "Total:"
- นิพจน์ทั่วไปและอัลกอริทึมการจับคู่สตริง
ข้อดี ของวิธีการตามเทมเพลต ได้แก่ ความแม่นยําสูงสําหรับประเภทเอกสารที่รู้จัก การประมวลผลที่รวดเร็ว และผลลัพธ์ที่อธิบายได้
ข้อจํากัด ของวิธีการรวมถึงข้อกําหนดสําหรับการสร้างเทมเพลตด้วยตนเอง และความซับซ้อนที่เกิดจากรูปแบบโครงร่างหรือความไม่สอดคล้องกันของการตั้งชื่อฟิลด์
การตรวจจับตามแมชชีนเลิร์นนิ่ง
แทนที่จะใช้ตรรกะแบบฮาร์ดโค้ดเพื่อแยกฟิลด์ตามชื่อและตําแหน่งที่รู้จัก คุณสามารถใช้คลังข้อมูลของเอกสารตัวอย่างเพื่อฝึกโมเดลแมชชีนเลิร์นนิงที่แยกฟิลด์ตามความสัมพันธ์ที่เรียนรู้ โดยเฉพาะอย่างยิ่งโมเดลที่ใช้หม้อแปลงไฟฟ้านั้นเก่งในการใช้ตัวชี้นําตามบริบทเพื่อระบุรูปแบบ และมักเป็นพื้นฐานของโซลูชันการตรวจจับภาคสนาม
แนวทางการฝึกอบรมสําหรับโมเดลแมชชีนเลิร์นนิงการตรวจจับภาคสนาม ได้แก่ :
- การเรียนรู้ภายใต้การดูแล: ได้รับการฝึกอบรมเกี่ยวกับชุดข้อมูลที่มีป้ายกํากับพร้อมตําแหน่งฟิลด์ที่รู้จัก
- การเรียนรู้ด้วยตนเอง: ได้รับการฝึกอบรมล่วงหน้าเกี่ยวกับคลังข้อมูลเอกสารขนาดใหญ่เพื่อทําความเข้าใจรูปแบบเค้าโครง
- การเรียนรู้แบบหลายรูปแบบ: รวมคุณลักษณะข้อความ ภาพ และตําแหน่ง
-
สถาปัตยกรรมแบบจําลองขั้นสูง เช่น:
- โครงข่ายประสาทเทียมกราฟ (GNN) ที่จําลองความสัมพันธ์เชิงพื้นที่ระหว่างองค์ประกอบข้อความเป็นการเชื่อมต่อกราฟ
- กลไกความสนใจ ที่มุ่งเน้นไปที่ขอบเขตเอกสารที่เกี่ยวข้องเมื่อคาดการณ์ค่าเขตข้อมูล
- โมเดลลําดับต่อลําดับ ที่แปลงลําดับข้อความที่ไม่มีโครงสร้างเป็นการกําหนดฟิลด์ที่มีโครงสร้าง
Generative AI สําหรับการแยกตามสคีมา
ความก้าวหน้าล่าสุดในโมเดลภาษาขนาดใหญ่ (LLM) ได้นําไปสู่การเกิดขึ้นของเทคนิคการตรวจจับภาคสนามที่ใช้ AI เชิงกําเนิด ซึ่งช่วยให้การตรวจจับภาคสนามมีประสิทธิภาพและประสิทธิผลมากขึ้นผ่าน:
- การแยกตามพร้อมท์ที่คุณให้ LLM ด้วยข้อความเอกสารและข้อกําหนด Schema และจับคู่ข้อความกับเขตข้อมูลใน Schema
- การเรียนรู้เพียงไม่กี่ช็อต ซึ่งคุณสามารถฝึกโมเดลด้วยตัวอย่างน้อยที่สุดเพื่อแยกฟิลด์ที่กําหนดเอง
- การให้เหตุผลแบบห่วงโซ่ความคิด ที่แนะนําโมเดลผ่านตรรกะการระบุฟิลด์ทีละขั้นตอน
ขั้นตอนที่ 3: การแม็ปและการเชื่อมโยงฟิลด์
หลังจากระบุค่าผู้สมัครแล้ว จะต้องแม็ปกับฟิลด์ Schema เฉพาะ:
เทคนิคการจับคู่คีย์-ค่า
ในหลายกรณี ฟิลด์ข้อมูลในเอกสารหรือฟอร์มเป็นค่าที่ไม่ต่อเนื่องที่สามารถแม็ปกับคีย์ ตัวอย่างเช่น ชื่อผู้จัดจําหน่าย วันที่ และยอดเงินรวมในใบเสร็จรับเงินหรือใบแจ้งหนี้ เทคนิคทั่วไปที่ใช้สําหรับการจับคู่คีย์-ค่า ได้แก่
การวิเคราะห์ความใกล้ชิด:
- การจัดกลุ่มเชิงพื้นที่: จัดกลุ่มองค์ประกอบข้อความใกล้เคียงโดยใช้อัลกอริทึมระยะทาง
- การวิเคราะห์ลําดับการอ่าน: ทําตามโฟลว์ข้อความธรรมชาติเพื่อเชื่อมโยงป้ายชื่อกับค่า
- ความสัมพันธ์ทางเรขาคณิต: ใช้รูปแบบการจัดตําแหน่ง การเยื้อง และการวางตําแหน่ง
การจดจํารูปแบบภาษาศาสตร์:
- การรับรู้เอนทิตีที่มีชื่อ (NER): ระบุชนิดเอนทิตีเฉพาะ (วันที่ ยอดเงิน ชื่อ)
- การติดแท็กส่วนของคําพูด: ทําความเข้าใจความสัมพันธ์ทางไวยากรณ์ระหว่างป้ายกํากับและค่า
- การแยกวิเคราะห์การพึ่งพา: วิเคราะห์ความสัมพันธ์ทางวากยสัมพันธ์ในข้อความ
การประมวลผลเนื้อหาแบบตารางและเนื้อหาที่มีโครงสร้าง
เอกสารบางฉบับมีโครงสร้างข้อความที่ซับซ้อนมากขึ้น เช่น ตาราง ตัวอย่างเช่น ใบเสร็จรับเงินหรือใบแจ้งหนี้อาจรวมตารางของสินค้าในรายการที่มีคอลัมน์สําหรับชื่อสินค้า ราคา และปริมาณที่ซื้อ
การมีอยู่ของตารางสามารถกําหนดได้โดยใช้เทคนิคหลายอย่าง ได้แก่ :
- สถาปัตยกรรมโครงข่ายประสาทเทียมแบบ convolutional (CNN) เฉพาะสําหรับการจดจําโครงสร้างตาราง
- วิธีการตรวจจับวัตถุที่ปรับให้เข้ากับการระบุเซลล์ตาราง
- วิธีการแยกวิเคราะห์ตามกราฟที่สร้างแบบจําลองโครงสร้างตารางเป็นความสัมพันธ์ของกราฟระหว่างเซลล์
เมื่อต้องการแมปค่าในเซลล์ในตารางกับเขตข้อมูล โซลูชันการแยกเขตข้อมูลอาจใช้เทคนิคต่อไปนี้อย่างน้อยหนึ่งอย่าง:
- การเชื่อมโยงแถวและคอลัมน์ เพื่อแมปเซลล์ตารางกับสคีมาฟิลด์เฉพาะ
- การตรวจหาส่วนหัวเพื่อระบุส่วนหัวของคอลัมน์เพื่อทําความเข้าใจความหมายของฟิลด์
- การประมวลผลแบบลําดับชั้น เพื่อจัดการโครงสร้างตารางที่ซ้อนกันและผลรวมย่อย
การให้คะแนนและความเชื่อมั่นและการตรวจสอบความถูกต้อง
ความแม่นยําในการแยกภาคสนามขึ้นอยู่กับหลายปัจจัย และอัลกอริทึมและโมเดลที่ใช้ในการนําโซลูชันไปใช้อาจมีข้อผิดพลาดในการระบุผิดพลาดหรือการตีความค่า เพื่อพิจารณาเรื่องนี้จึงใช้เทคนิคต่างๆเพื่อประเมินความถูกต้องของค่าฟิลด์ที่คาดการณ์ไว้ รวมถึง:
- ความเชื่อมั่น OCR: สืบทอดคะแนนความเชื่อมั่นจากการรู้จําข้อความพื้นฐาน
- ความเชื่อมั่นในการจับคู่รูปแบบ: การให้คะแนนตามการแยกข้อมูลที่ตรงกับรูปแบบที่คาดไว้
- การตรวจสอบบริบท: การตรวจสอบว่าค่าฟิลด์นั้นสมเหตุสมผลในบริบทของเอกสาร
- การตรวจสอบความถูกต้องข้ามฟิลด์: การตรวจสอบความสัมพันธ์ระหว่างฟิลด์ที่แยกออกมา (ตัวอย่างเช่น การยืนยันว่าผลรวมย่อยของรายการเฉพาะรายการเป็นผลรวมของใบแจ้งหนี้โดยรวม)
ขั้นตอนที่ 4: การทําให้เป็นมาตรฐานและมาตรฐานของข้อมูล
โดยทั่วไปค่าดิบที่แยกออกมาจะถูกแปลงเป็นรูปแบบที่สอดคล้องกัน (ตัวอย่างเช่น เพื่อให้แน่ใจว่าวันที่ที่แยกทั้งหมดจะแสดงในรูปแบบวันที่เดียวกัน) และตรวจสอบความถูกต้อง
จัดรูปแบบมาตรฐาน
ตัวอย่างของการกําหนดมาตรฐานรูปแบบที่สามารถนําไปใช้ได้ ได้แก่ :
การทําให้เป็นมาตรฐานวันที่:
- การตรวจจับรูปแบบ: ระบุรูปแบบวันที่ต่างๆ (MM/DD/YYYY, DD-MM-YYYY เป็นต้น)
- อัลกอริทึมการแยกวิเคราะห์: แปลงเป็นรูปแบบ ISO มาตรฐาน
- การแก้ไขความคลุมเครือ: จัดการกรณีที่รูปแบบวันที่ไม่ชัดเจน
การประมวลผลสกุลเงินและตัวเลข:
- การจดจําสัญลักษณ์: จัดการสัญลักษณ์สกุลเงินต่างๆ และตัวคั่นหลักพัน
- การทําให้เป็นมาตรฐานของทศนิยม: กําหนดมาตรฐานการแสดงจุดทศนิยมในตําแหน่งที่ตั้ง
- การแปลงหน่วย: แปลงระหว่างหน่วยการวัดต่างๆ ตามต้องการ
การกําหนดมาตรฐานข้อความ:
- การทําให้เป็นมาตรฐานของตัวพิมพ์ใหญ่: ใช้กฎการใช้ตัวพิมพ์ใหญ่ที่สอดคล้องกัน
- มาตรฐานการเข้ารหัส: จัดการการเข้ารหัสอักขระและอักขระพิเศษที่แตกต่างกัน
- การขยายตัวย่อ: แปลงตัวย่อทั่วไปเป็นรูปแบบเต็ม
การตรวจสอบความถูกต้องของข้อมูลและการประกันคุณภาพ
กระบวนการสร้างมาตรฐานยังช่วยให้สามารถตรวจสอบความถูกต้องเพิ่มเติมของค่าที่แยกออกมาผ่านเทคนิคต่างๆ เช่น:
การตรวจสอบตามกฎ:
- การตรวจสอบรูปแบบ: ตรวจสอบว่าค่าที่แยกออกมาตรงกับรูปแบบที่คาดไว้ (หมายเลขโทรศัพท์ ที่อยู่อีเมล)
- การตรวจสอบช่วง: ตรวจสอบให้แน่ใจว่าค่าตัวเลขอยู่ในขอบเขตที่เหมาะสม
- การตรวจสอบฟิลด์ที่จําเป็น: ยืนยันว่ามีฟิลด์บังคับทั้งหมดอยู่
การตรวจสอบความถูกต้องทางสถิติ:
- การตรวจหาค่าผิดปกติ: ระบุค่าที่สูงหรือต่ําผิดปกติที่อาจบ่งบอกถึงข้อผิดพลาดในการแยกข้อมูล
- การวิเคราะห์การแจกแจง: เปรียบเทียบค่าที่แยกออกมากับรูปแบบในอดีต
- การตรวจสอบความถูกต้องข้ามเอกสาร: ตรวจสอบความสอดคล้องของเอกสารที่เกี่ยวข้อง
ขั้นตอนที่ 5: การผสานรวมกับกระบวนการและระบบทางธุรกิจ
ขั้นตอนสุดท้ายของกระบวนการมักจะเกี่ยวข้องกับการรวมค่าฟิลด์ที่แยกออกมาเข้ากับกระบวนการทางธุรกิจหรือระบบ:
การแม็ป Schema
ฟิลด์ที่แยกออกมาอาจต้องได้รับการแปลงหรือจัดรูปแบบใหม่เพิ่มเติมเพื่อให้สอดคล้องกับสคีมาของแอปพลิเคชันที่ใช้สําหรับการนําเข้าข้อมูลไปยังระบบดาวน์สตรีม เช่น:
- สคีมาฐานข้อมูล: แมปฟิลด์ที่แยกออกมากับคอลัมน์และตารางฐานข้อมูลเฉพาะ
- เพย์โหลด API: จัดรูปแบบข้อมูลสําหรับการใช้ REST API โดยระบบดาวน์สตรีม
- คิวข้อความ: เตรียมข้อความที่มีโครงสร้างสําหรับการประมวลผลแบบอะซิงโครนัส
กระบวนการแม็ป Schema อาจเกี่ยวข้องกับการแปลง เช่น:
- การเปลี่ยนชื่อฟิลด์: แมปชื่อฟิลด์ที่แยกออกมากับข้อตกลงของระบบเป้าหมาย
- การแปลงประเภทข้อมูล: ตรวจสอบว่าค่าตรงกับประเภทข้อมูลที่คาดไว้ในระบบเป้าหมาย
- ตรรกะแบบมีเงื่อนไข: ใช้กฎทางธุรกิจสําหรับการแปลงฟิลด์และการได้มา
เมตริกคุณภาพและการรายงาน
งานทั่วไปอีกอย่างหนึ่งหลังจากกระบวนการแยกเสร็จสิ้นคือการประเมินและรายงานคุณภาพของข้อมูลที่แยกออกมา รายงานสามารถมีข้อมูลเช่น:
- คะแนนความเชื่อมั่นระดับฟิลด์: คะแนนความเชื่อมั่นแต่ละรายการสําหรับแต่ละฟิลด์ที่แยกออกมา
- การประเมินคุณภาพระดับเอกสาร: เมตริกความสําเร็จในการสกัดโดยรวม
- การจัดหมวดหมู่ข้อผิดพลาด: จําแนกความล้มเหลวในการแยกตามประเภทและสาเหตุ