โมเดลภาษาความหมาย
Note
ดูแท็บ ข้อความและรูปภาพ สําหรับรายละเอียดเพิ่มเติม!
เนื่องจากสถานะของศิลปะสําหรับ NLP มีขั้นสูง ความสามารถในการฝึกแบบจําลองที่ห่อหุ้มความสัมพันธ์เชิงความหมายระหว่างโทเค็นได้นําไปสู่การเกิดขึ้นของแบบจําลองภาษาการเรียนรู้เชิงลึกที่มีประสิทธิภาพ หัวใจของแบบจําลองเหล่านี้คือการเข้ารหัสโทเค็นภาษาเป็นเวกเตอร์ (อาร์เรย์หลายค่าของตัวเลข) ที่เรียกว่า การฝัง
วิธีการสร้างแบบจําลองข้อความที่ใช้เวกเตอร์นี้กลายเป็นเรื่องปกติในเทคนิคต่างๆ เช่น Word2Vec และ GloVe ซึ่งโทเค็นข้อความจะแสดงเป็นเวกเตอร์หนาแน่นที่มีหลายมิติ ในระหว่างการฝึกโมเดล ค่ามิติจะถูกกําหนดให้สะท้อนถึงลักษณะความหมายของแต่ละโทเค็นตามการใช้งานในข้อความการฝึกอบรม ความสัมพันธ์ทางคณิตศาสตร์ระหว่างเวกเตอร์สามารถนําไปใช้ประโยชน์เพื่อทํางานวิเคราะห์ข้อความทั่วไปได้อย่างมีประสิทธิภาพมากกว่าเทคนิคทางสถิติล้วนๆ ที่เก่ากว่า ความก้าวหน้าล่าสุดในแนวทางนี้คือการใช้เทคนิค ที่เรียกว่าความสนใจ เพื่อพิจารณาโทเค็นแต่ละตัวในบริบท และคํานวณอิทธิพลของโทเค็นรอบตัว การฝังตาม บริบท ที่เกิดขึ้น เช่น ที่พบในตระกูลโมเดล GPT เป็นพื้นฐานของ Generative AI ที่ทันสมัย
การแสดงข้อความเป็นเวกเตอร์
เวกเตอร์แสดงจุดในพื้นที่หลายมิติ ซึ่งกําหนดโดยพิกัดตามหลายแกน เวกเตอร์แต่ละตัวอธิบายทิศทางและระยะทางจากจุดกําเนิด โทเค็นที่คล้ายคลึงกันทางความหมายควรส่งผลให้เวกเตอร์มีทิศทางที่คล้ายคลึงกัน – กล่าวอีกนัยหนึ่งคือพวกเขาชี้ไปในทิศทางที่คล้ายคลึงกัน
ตัวอย่างเช่น พิจารณาการฝังสามมิติต่อไปนี้สําหรับคําทั่วไปบางคํา:
| คำ | เวกเตอร์ |
|---|---|
dog |
[0.8, 0.6, 0.1] |
puppy |
[0.9, 0.7, 0.4] |
cat |
[0.7, 0.5, 0.2] |
kitten |
[0.8, 0.6, 0.5] |
young |
[0.1, 0.1, 0.3] |
ball |
[0.3, 0.9, 0.1] |
tree |
[0.2, 0.1, 0.9] |
เราสามารถเห็นภาพเวกเตอร์เหล่านี้ในพื้นที่สามมิติดังที่แสดงไว้ที่นี่:

เวกเตอร์สําหรับ "dog" และ "cat" คล้ายกัน (สัตว์เลี้ยงทั้งคู่) เช่นเดียวกับ "puppy" และ "kitten" (สัตว์เล็กทั้งสอง) คํา "tree"ว่า , "young", และ ball" มีการวางแนวเวกเตอร์ที่แตกต่างกันอย่างชัดเจน ซึ่งสะท้อนถึงความหมายที่แตกต่างกัน
ลักษณะความหมายที่เข้ารหัสในเวกเตอร์ทําให้สามารถใช้การดําเนินการตามเวกเตอร์ที่เปรียบเทียบคําและเปิดใช้งานการเปรียบเทียบเชิงวิเคราะห์ได้
การค้นหาคําที่เกี่ยวข้อง
เนื่องจากการวางแนวของเวกเตอร์ถูกกําหนดโดยค่ามิติคําที่มีความหมายคล้ายกันจึงมีแนวโน้มที่จะมีการวางแนวที่คล้ายคลึงกัน ซึ่งหมายความว่าคุณสามารถใช้การคํานวณ เช่น ความคล้ายคลึงกันของโคไซน์ ระหว่างเวกเตอร์เพื่อทําการเปรียบเทียบที่มีความหมาย
ตัวอย่างเช่น ในการกําหนด "คี่ออก" ระหว่าง "dog", "cat", และ "tree"คุณสามารถคํานวณความคล้ายคลึงกันของโคไซน์ระหว่างคู่ของเวกเตอร์ได้ ความคล้ายคลึงกันของโคไซน์คํานวณได้ดังนี้:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
โดยที่ผลคูณดอทและ||A||ขนาดของเวกเตอร์ A อยู่ที่ไหนA · B
การคํานวณความคล้ายคลึงกันระหว่างสามคํา:
dog[0.8, 0.6, 0.1] และcat[0.7, 0.5, 0.2]:- ผลิตภัณฑ์จุด: (0.8 × 0.7) + (0.6 × 0.5) + (0.1 × 0.2) = 0.56 + 0.30 + 0.02 = 0.88
- ขนาดของ
dog: √(0.8² + 0.6² + 0.1²) = √(0.64 + 0.36 + 0.01) = √1.01 ≈ 1.005 - ขนาดของ
cat: √(0.7² + 0.5² + 0.2²) = √(0.49 + 0.25 + 0.04) = √0.78 ≈ 0.883 - ความคล้ายคลึงกันของโคไซน์: 0.88 / (1.005 × 0.883) ≈ 0.992 (ความคล้ายคลึงกันสูง)
dog[0.8, 0.6, 0.1] และtree[0.2, 0.1, 0.9]:- ผลิตภัณฑ์จุด: (0.8 × 0.2) + (0.6 × 0.1) + (0.1 × 0.9) = 0.16 + 0.06 + 0.09 = 0.31
- ขนาดของ
tree: √(0.2² + 0.1² + 0.9²) = √(0.04 + 0.01 + 0.81) = √0.86 ≈ 0.927 - ความคล้ายคลึงกันของโคไซน์: 0.31 / (1.005 × 0.927) ≈ 0.333 (ความคล้ายคลึงกันต่ํา)
cat[0.7, 0.5, 0.2] และtree[0.2, 0.1, 0.9]:- ผลิตภัณฑ์จุด: (0.7 × 0.2) + (0.5 × 0.1) + (0.2 × 0.9) = 0.14 + 0.05 + 0.18 = 0.37
- ความคล้ายคลึงกันของโคไซน์: 0.37 / (0.883 × 0.927) ≈ 0.452 (ความคล้ายคลึงกันต่ํา)
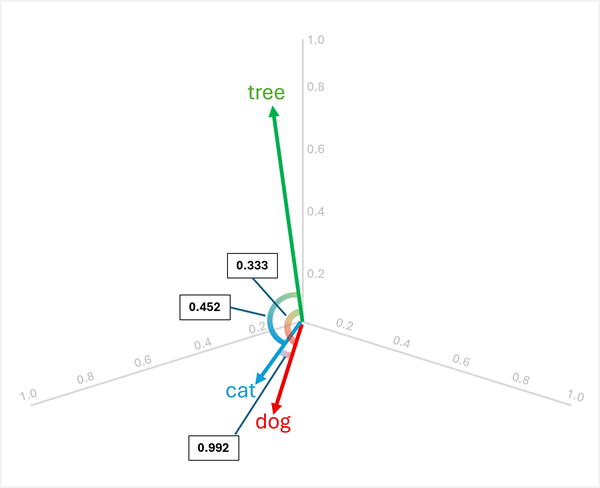
ผลการวิจัยแสดงให้เห็นว่า "dog" มีความ "cat" คล้ายคลึงกันอย่างมาก (0.992) ในขณะที่ "tree" มีความคล้ายคลึงกันต่ํากว่าทั้ง "dog" (0.333) และ "cat" (0.452) ดังนั้นจึง tree เป็นสิ่งที่แปลกอย่างชัดเจน
การแปลเวกเตอร์ผ่านการบวกและการลบ
คุณสามารถเพิ่มหรือลบเวกเตอร์เพื่อสร้างผลลัพธ์แบบเวกเตอร์ใหม่ ซึ่งสามารถใช้เพื่อค้นหาโทเค็นที่มีเวกเตอร์ที่ตรงกัน เทคนิคนี้ช่วยให้ตรรกะตามเลขคณิตที่ใช้งานง่ายสามารถกําหนดคําศัพท์ที่เหมาะสมตามความสัมพันธ์ทางภาษาศาสตร์
ตัวอย่างเช่น การใช้เวกเตอร์จากก่อนหน้านี้:
-
dog+young= [0.8, 0.6, 0.1] + [0.1, 0.1, 0.3] = [0.9, 0.7, 0.4] =puppy -
cat+young= [0.7, 0.5, 0.2] + [0.1, 0.1, 0.3] = [0.8, 0.6, 0.5] =kitten
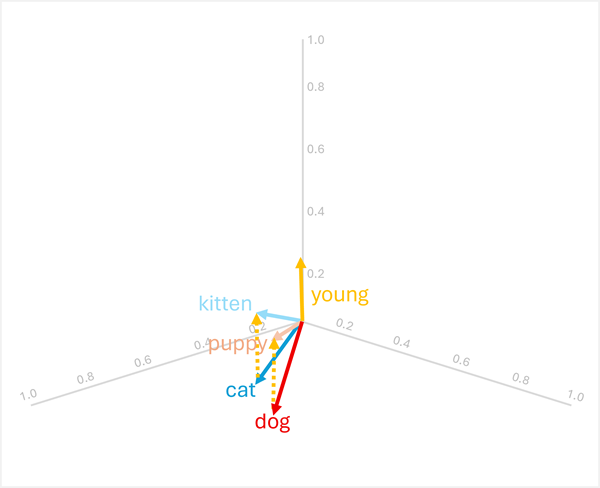
การดําเนินการเหล่านี้ทํางานเนื่องจากเวกเตอร์สําหรับ "young" เข้ารหัสการเปลี่ยนแปลงความหมายจากสัตว์ที่โตเต็มวัยเป็นสัตว์อายุน้อย
Note
ในทางปฏิบัติเลขคณิตเวกเตอร์ไม่ค่อยให้การจับคู่ที่ตรงกันทุกประการ คุณจะค้นหาคําที่มีเวกเตอร์ ใกล้เคียงที่สุด (คล้ายกันมากที่สุด) กับผลลัพธ์แทน
เลขคณิตทํางานในทางกลับกันเช่นกัน:
-
puppy-young= [0.9, 0.7, 0.4] - [0.1, 0.1, 0.3] = [0.8, 0.6, 0.1] =dog -
kitten-young= [0.8, 0.6, 0.5] - [0.1, 0.1, 0.3] = [0.7, 0.5, 0.2] =cat
การให้เหตุผลเชิงเปรียบเทียบ
เลขคณิตเวกเตอร์ยังสามารถตอบคําถามเปรียบเทียบเช่น "puppy เป็น dog เป็น kitten? "
ในการแก้ปัญหานี้ให้คํานวณ: kitten - puppy + dog
- [0.8, 0.6, 0.5] - [0.9, 0.7, 0.4] + [0.8, 0.6, 0.1]
- = [-0.1, -0.1, 0.1] + [0.8, 0.6, 0.1]
- = [0.7, 0.5, 0.2]
- =
cat
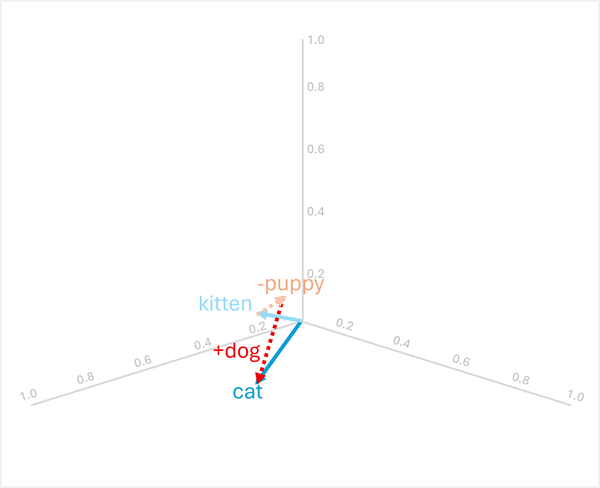
ตัวอย่างเหล่านี้แสดงให้เห็นว่าการดําเนินการเวกเตอร์สามารถจับความสัมพันธ์ทางภาษาและเปิดใช้งานการให้เหตุผลเกี่ยวกับรูปแบบความหมายได้อย่างไร
การใช้แบบจําลองความหมายสําหรับการวิเคราะห์ข้อความ
โมเดลความหมายตามเวกเตอร์ให้ความสามารถที่มีประสิทธิภาพสําหรับงานวิเคราะห์ข้อความทั่วไปมากมาย
การสรุปข้อความ
การฝังความหมายช่วยให้สามารถสรุปแบบ แยกได้โดย การระบุประโยคด้วยเวกเตอร์ที่เป็นตัวแทนของเอกสารโดยรวมมากที่สุด ด้วยการเข้ารหัสแต่ละประโยคเป็นเวกเตอร์ (มักจะโดยการหาค่าเฉลี่ยหรือการรวมการฝังคําที่เป็นส่วนประกอบ) คุณจะสามารถคํานวณได้ว่าประโยคใดเป็นศูนย์กลางของความหมายของเอกสารมากที่สุด ประโยคกลางเหล่านี้สามารถแยกออกมาเพื่อสร้างบทสรุปที่รวบรวมประเด็นสําคัญ
การแยกคําหลัก
ความคล้ายคลึงกันของเวกเตอร์สามารถระบุคําศัพท์ที่สําคัญที่สุดในเอกสารได้โดยการเปรียบเทียบการฝังแต่ละคํากับการแสดงความหมายโดยรวมของเอกสาร คําที่มีเวกเตอร์คล้ายกับเวกเตอร์เอกสารมากที่สุด หรือเป็นศูนย์กลางที่สุดเมื่อพิจารณาเวกเตอร์คําทั้งหมดในเอกสาร น่าจะเป็นคําสําคัญที่แสดงถึงหัวข้อหลัก
การจดจําเอนทิตีที่มีชื่อ
โมเดลความหมายสามารถปรับแต่งได้อย่างละเอียดเพื่อจดจําเอนทิตีที่มีชื่อ (บุคคล องค์กร สถานที่ ฯลฯ) โดยการเรียนรู้การแสดงเวกเตอร์ที่จัดกลุ่มประเภทเอนทิตีที่คล้ายคลึงกันเข้าด้วยกัน ในระหว่างการอนุมาน โมเดลจะตรวจสอบการฝังโทเค็นแต่ละรายการและบริบทของโทเค็นเพื่อพิจารณาว่าเป็นตัวแทนของเอนทิตีที่มีชื่อหรือไม่ และถ้าเป็นเช่นนั้น จะเป็นชนิดใด
การจําแนกข้อความ
สําหรับงานต่างๆ เช่น การวิเคราะห์ความคิดเห็นหรือการจัดหมวดหมู่หัวข้อ เอกสารสามารถแสดงเป็นเวกเตอร์รวม (เช่น ค่าเฉลี่ยของการฝังคําทั้งหมดในเอกสาร) เวกเตอร์เอกสารเหล่านี้สามารถใช้เป็นคุณสมบัติสําหรับตัวแยกประเภทการเรียนรู้ของเครื่อง หรือเปรียบเทียบโดยตรงกับเวกเตอร์ต้นแบบของคลาสเพื่อกําหนดหมวดหมู่ เนื่องจากเอกสารที่คล้ายคลึงกันทางความหมายมีการวางแนวเวกเตอร์ที่คล้ายคลึงกันวิธีการนี้จึงจัดกลุ่มเนื้อหาที่เกี่ยวข้องและแยกแยะหมวดหมู่ต่างๆ ได้อย่างมีประสิทธิภาพ