โมเดลภาษาขนาดใหญ่ (LLM) ของ GitHub Copilot
GitHub Copilot ขับเคลื่อนโดยโมเดลภาษาขนาดใหญ่ (LLM) เพื่อช่วยในการเขียนโค้ดอย่างราบรื่น ในหน่วยนี้ เราจะเน้นไปที่การทำความเข้าใจการผสานรวมและผลกระทบของ LLM ใน GitHub Copilot มาทบทวนหัวข้อต่อไปนี้กัน:
- LLM คืออะไร
- บทบาทของ LLM ใน GitHub Copilot และการสร้างพร้อมท์
- การปรับแต่ง LLM
- การปรับแต่ง LoRA
LLM คืออะไร
โมเดลภาษาขนาดใหญ่ (LLM) คือโมเดลปัญญาประดิษฐ์ที่ได้รับการออกแบบและฝึกมาให้เข้าใจ สร้าง และจัดการภาษาของมนุษย์ โมเดลเหล่านี้ได้รับการออกแบบมาให้มีศักยภาพในการจัดการงานต่างๆ ที่เกี่ยวข้องกับข้อความได้หลากหลาย โดยอาศัยข้อมูลข้อความจำนวนมากที่ได้รับการฝึกมา ต่อไปนี้เป็นประเด็นหลักบางประการที่ต้องเข้าใจเกี่ยวกับ LLM:
ปริมาณของข้อมูลการฝึก
LLM จะต้องเรียนรู้เนื้อหาจำนวนมากจากแหล่งต่างๆ ความรู้ดังกล่าวจะช่วยให้เข้าใจภาษา บริบท และความซับซ้อนต่างๆ ที่เกี่ยวข้องกับรูปแบบการสื่อสารต่างๆ อย่างมาก
ความเข้าใจตามบริบท
โดดเด่นในด้านการสร้างข้อความที่มีความเกี่ยวข้องกับบริบทและสอดคล้องกัน ความสามารถในการเข้าใจบริบททำให้สามารถนำเสนอข้อมูลที่มีประโยชน์ได้ ไม่ว่าจะเป็นการเรียบเรียงประโยคหรือย่อหน้าให้สมบูรณ์ หรือแม้กระทั่งการสร้างเอกสารทั้งหมดที่เหมาะสมกับบริบท
การรวมการเรียนรู้ของเครื่องและ AI
LLM มีพื้นฐานมาจากหลักการเรียนรู้ของเครื่องและปัญญาประดิษฐ์ โดยเป็นเครือข่ายประสาทที่มีพารามิเตอร์นับล้านหรือแม้แต่พันล้านรายการที่ได้รับการปรับแต่งอย่างละเอียดในระหว่างกระบวนการฝึกเพื่อทำความเข้าใจและคาดการณ์ข้อความอย่างมีประสิทธิภาพ
ความอเนกประสงค์
โมเดลเหล่านี้ไม่ได้จำกัดอยู่ที่ประเภทข้อความหรือภาษาใดภาษาหนึ่งเท่านั้น โดยสามารถกำหนดและปรับแต่งให้เหมาะกับงานเฉพาะได้ ทำให้มีความอเนกประสงค์สูงและใช้ได้กับโดเมนและภาษาต่างๆ
บทบาทของ LLM ใน GitHub Copilot และการสร้างพร้อมท์
GitHub Copilot ใช้ LLM เพื่อให้คำแนะนำโค้ดตามบริบท LLM ไม่เพียงพิจารณาไฟล์ปัจจุบันเท่านั้น แต่ยังรวมถึงไฟล์และแท็บอื่นๆ ที่เปิดอยู่ใน IDE เพื่อสร้างการเติมโค้ดที่แม่นยำและเกี่ยวข้อง แนวทางแบบไดนามิกนี้ช่วยให้มั่นใจได้ว่าจะได้รับคำแนะนำที่เหมาะสม ซึ่งจะช่วยปรับปรุงประสิทธิภาพการทำงานของคุณ
การปรับแต่ง LLM
การปรับแต่งเป็นกระบวนการสำคัญที่ช่วยให้เราปรับแต่งโมเดลภาษาขนาดใหญ่ (LLM) ที่ผ่านการฝึกล่วงหน้าสำหรับงานหรือโดเมนเฉพาะได้ ซึ่งเกี่ยวข้องกับการฝึกโมเดลบนชุดข้อมูลเฉพาะงานที่มีขนาดเล็กกว่า ซึ่งเรียกว่าชุดข้อมูลเป้าหมาย ในขณะที่ใช้ความรู้และพารามิเตอร์ที่ได้รับจากชุดข้อมูลขนาดใหญ่ที่ผ่านการฝึกล่วงหน้า ซึ่งเรียกว่าโมเดลต้นทาง
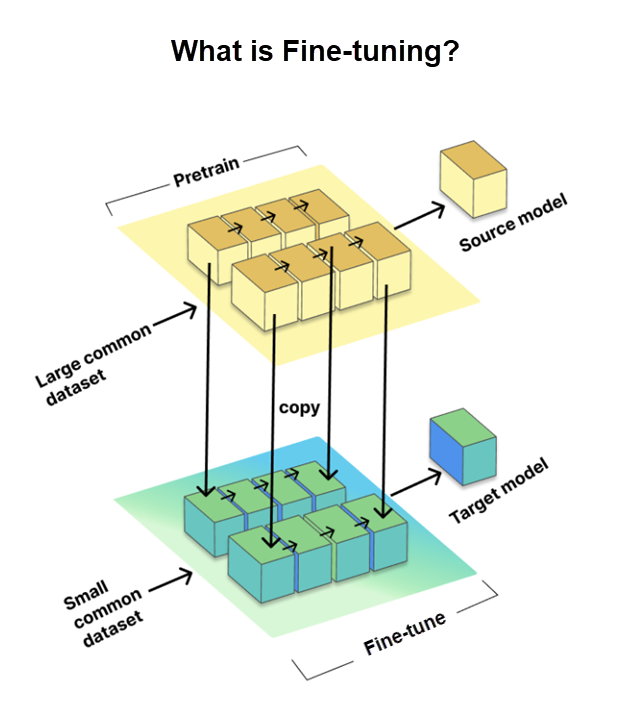
การปรับแต่งถือเป็นสิ่งจำเป็นเพื่อปรับ LLM ให้เหมาะกับงานเฉพาะ เพื่อเพิ่มประสิทธิภาพการทำงาน อย่างไรก็ตาม GitHub ได้ก้าวไปอีกขั้นโดยการใช้วิธีปรับแต่ง LoRA ซึ่งเราจะมาพูดถึงในหัวข้อต่อไป
การปรับแต่ง LoRA
การปรับแต่งอย่างสมบูรณ์แบบดั้งเดิมหมายถึงการฝึกส่วนต่างๆ ของเครือข่ายประสาท ซึ่งอาจช้าและต้องใช้ทรัพยากรอย่างมาก แต่การปรับแต่ง LoRA (Low-Rank Adaptation) เป็นทางเลือกที่ชาญฉลาด ใช้เพื่อทำให้โมเดลภาษาขนาดใหญ่ (LLM) ที่ผ่านการฝึกล่วงหน้าทำงานได้ดีขึ้นสำหรับงานเฉพาะ โดยไม่ต้องทำการฝึกใหม่ทั้งหมด
ต่อไปนี้คือวิธีการทำงานของ LoRA:
- LoRA จะเพิ่มชิ้นส่วนฝึกได้ที่มีขนาดเล็กลงในแต่ละเลเยอร์ของโมเดลที่ผ่านการฝึกล่วงหน้า แทนที่จะเปลี่ยนแปลงทุกอย่าง
- โมเดลต้นฉบับยังคงเหมือนเดิมซึ่งช่วยประหยัดเวลาและทรัพยากร
ข้อดีเกี่ยวกับ LoRA:
- ดีกว่าวิธีการปรับแต่งอื่นๆ เช่น อะแดปเตอร์และการปรับแต่งคำนำหน้า
- เหมือนการได้รับผลลัพธ์ที่ยอดเยี่ยมโดยมีส่วนที่ต้องลงมือทำน้อยลง
พูดง่ายๆ ก็คือ การปรับแต่ง LoRA คือการทำงานที่ชาญฉลาดขึ้น ไม่ใช่ทำงานหนักขึ้น เพื่อให้ LLM ดีขึ้นสำหรับข้อกำหนดการเขียนโค้ดเฉพาะของคุณเมื่อใช้ Copilot