Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
ŞUNLARA UYGULANIR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
İpucu
Microsoft Fabric'daki
Azure Data Factory ve Synapse işlem hatlarındaki eşleme veri akışları, büyük ölçekte veri dönüştürmeleri tasarlamak ve çalıştırmak için kod içermeyen bir arabirim sağlar. Veri akışlarını eşleme hakkında bilginiz yoksa bkz. Mapping Data Flow Overview. Bu makalede, performans karşılaştırmalarınızı karşılayacak şekilde veri akışlarınızı ayarlamanın ve iyileştirmenin çeşitli yolları vurgulanır.
Veri akışlarıyla verileri dönüştüren bazı örnek zamanlamaları görmek için aşağıdaki videoyu izleyin.
Veri akışı performansını izleme
Hata ayıklama modunu kullanarak dönüştürme mantığınızı doğruladıktan sonra, veri akışınızı bir işlem hattında etkinlik olarak uçtan uca çalıştırın. Veri akışları, veri akışı yürütme etkinliği kullanılarak işlem hattında çalışır hale getirilir. Veri akışı etkinliği, dönüştürme mantığının ayrıntılı yürütme planını ve performans profilini görüntüleyen diğer etkinliklerle karşılaştırıldığında benzersiz bir izleme deneyimine sahiptir. Bir veri akışının ayrıntılı izleme bilgilerini görüntülemek için işlem hattının etkinlik çalıştırma çıkışındaki gözlük simgesini seçin. Daha fazla bilgi için Veri akışlarını eşleme izlemesine bakın.

Veri akışı performansını izlerken dikkat edilmesi gereken dört olası performans sorunu vardır:
- Küme başlangıç zamanı
- Kaynaktan okuma
- Dönüştürme süresi
- Havuza yazma
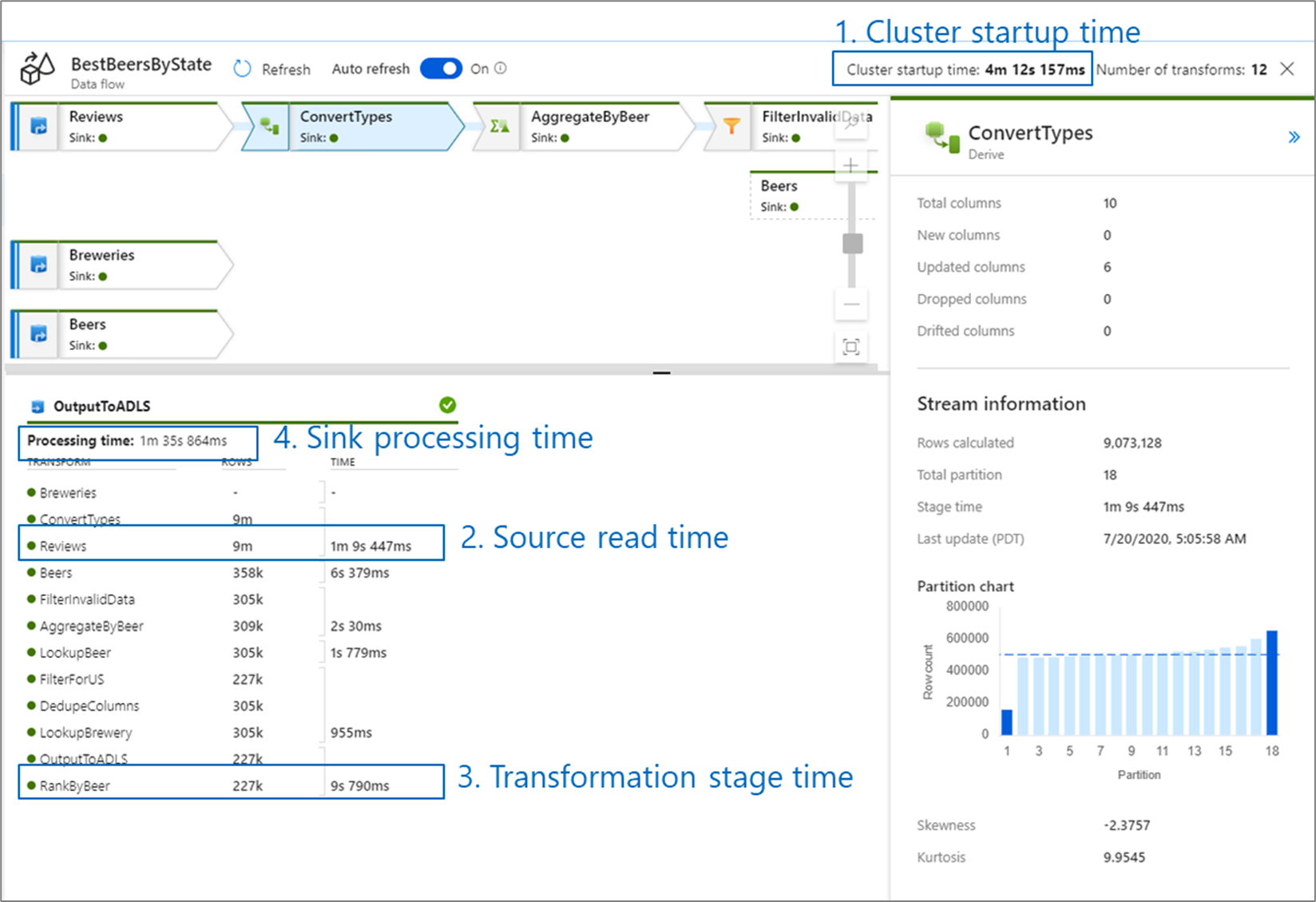
Küme başlangıç zamanı, Apache Spark kümesinin başlatılması için gereken süredir. Bu değer, izleme ekranının sağ üst köşesinde bulunur. Veri akışları, her iş için izole edilmiş bir kümenin kullanıldığı just-in-time modeliyle çalışır. Bu başlangıç süresi genellikle 3-5 dakika sürer. Sıralı işler için, yaşam süresi parametresi etkinleştirilerek başlatma zamanı azaltılabilir. Daha fazla bilgi için Integration Runtime performance içindeki Time to live bölümüne bakın.
Veri akışları, iş mantığınızı mümkün olduğunca hızlı gerçekleştirmek için 'aşamalarda' yeniden sıralayan ve çalıştıran bir Spark optimizasyon aracı kullanır. Veri akışınızın yazdığı her havuz için izleme çıkışı, her dönüştürme aşamasının süresini ve havuza veri yazma süresini listeler. En uzun süre muhtemelen veri akışınızın darboğazıdır. En uzun zamanı alan dönüşüm aşaması bir kaynak içeriyorsa, okuma sürenizi daha da optimize etmeyi düşünebilirsiniz. Dönüştürme işlemi uzun sürüyorsa tümleştirme çalışma zamanınızın boyutunu yeniden bölümlemeniz veya artırmanız gerekebilir. Çıkış işleme süresi uzunsa, veritabanınızı yükseltmeniz veya tek bir dosyaya çıkış yapmadığınızı doğrulamanız gerekebilir.
Veri akışınızın performans sorununu belirledikten sonra performansı geliştirmek için aşağıdaki iyileştirme stratejilerini kullanın.
Veri akışı mantığını test etme
Kullanıcı arabiriminden veri akışları tasarlarken ve test ederken, hata ayıklama modu canlı bir Spark kümesine karşı etkileşimli olarak test etmenizi sağlar. Bu sayede bir kümenin ısınmasını beklemeden verilerin önizlemesini görebilir ve veri akışlarınızı yürütebilirsiniz. Daha fazla bilgi için Hata Ayıklama Modu'na bakın.
İyileştirme sekmesi
İyileştir sekmesi, Spark kümesinin bölümleme düzenini yapılandırmak için ayarları içerir. Bu sekme, veri akışının her dönüşümünde bulunur ve dönüştürme tamamlandıktan sonra verileri yeniden bölümleyip bölümlemeyeceğini belirtir. Bölümlemenin ayarlanması, verilerinizin işlem düğümleri arasında dağılımı ve genel veri akışı performansınızda hem olumlu hem de olumsuz etkileri olabilecek veri yerelliği iyileştirmeleri üzerinde denetim sağlar.
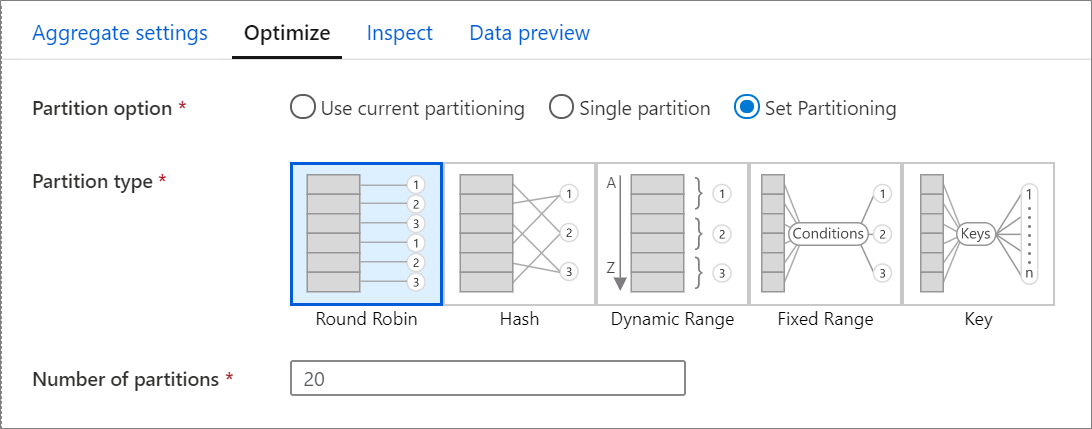
Varsayılan olarak, Geçerli bölümlemeyi kullan seçilidir, bu da hizmetin dönüştürmenin geçerli çıkış bölümlemesini tutmasını belirtir. Verilerin yeniden bölümlenmesi zaman aldığından, çoğu senaryoda Geçerli bölümlemenin kullanılması önerilir. Verilerinizi yeniden bölümlendirmek isteyebileceğiniz senaryolar, verilerinizi önemli ölçüde dengesizleştiren toplama ve birleştirmelerden sonra veya SQL veritabanında kaynak bölümlemeyi kullandığınız durumları içerir.
Herhangi bir dönüştürmede bölümlemesi değiştirmek için İyileştir sekmesini seçin ve Bölümlemesi Ayarla radyo düğmesini seçin. Bölümleme için size bir dizi seçenek sunulur. Bölümlemenin en iyi yöntemi veri birimlerinize, aday anahtarlarınıza, null değerlerinize ve kardinalitenize göre farklılık gösterir.
Önemli
Tek bölüm, tüm dağıtılmış verileri tek bir bölümde birleştirir. Bu, tüm aşağı akış dönüşümlerini ve yazmalarını da önemli ölçüde etkileyen çok yavaş bir işlemdir. Bu seçeneği kullanmak için açık bir iş nedeni olmadığı sürece bu seçenek kesinlikle önerilmez.
Aşağıdaki bölümleme seçenekleri her dönüştürmede kullanılabilir:
Döngüsel sıralama
"Round robin, verileri bölümlere eşit olarak dağıtır." "Sağlam ve akıllı bir bölümleme stratejisini uygulamak için iyi anahtar adaylarınız olmadığında, döngüsel geçiş yöntemini kullanın." Fiziksel bölüm sayısını ayarlayabilirsiniz.
Hash
Hizmet, benzer değerlere sahip satırların aynı bölüme düşmesi için eşit büyüklükte bölümler oluşturmak amacıyla sütunların karmasını üretir. Hash seçeneğini kullandığınızda, olası bölüm sapması için test edin. Fiziksel bölüm sayısını ayarlayabilirsiniz.
Dinamik aralık
Dinamik aralık, sağladığınız sütunları veya ifadeleri temel alan Spark dinamik aralıklarını kullanır. Fiziksel bölüm sayısını ayarlayabilirsiniz.
Sabit aralık
Bölümlenmiş veri sütunlarınızdaki değerler için sabit bir aralık sağlayan bir ifade oluşturun. Bölüm dengesizliklerini önlemek için bu seçeneği kullanmadan önce verilerinizi iyi anlamanız gerekir. İfade için girdiğiniz değerler bölüm işlevinin bir parçası olarak kullanılır. Fiziksel bölüm sayısını ayarlayabilirsiniz.
Anahtar
Verilerinizin kardinalitesini iyi kavradıysanız anahtar bölümleme iyi bir strateji olabilir. Anahtar bölümleme, sütununuzda her benzersiz değer için bölümler oluşturur. Sayı verilerdeki benzersiz değerlere dayandığından bölüm sayısını ayarlayamazsınız.
İpucu
Bölümleme düzenini el ile ayarlamak verileri yeniden düzenler ve Spark iyileştiricisinin avantajlarını dengeleyebilir. En iyi yöntem, gerekli olmadıkça bölümlemesi el ile ayarlamamaktır.
Log seviyesi
Veri akışı etkinliklerinizin her bir işlem hattı yürütmesinin tüm ayrıntılı telemetri günlüklerini tamamen kaydetmesini gerektirmiyorsanız, günlüğe kaydetme seviyenizi "Temel" veya "Yok" olarak ayarlayabilirsiniz. Veri akışlarınızı "Ayrıntılı" modda çalıştırırken (varsayılan), veri dönüştürme sırasında hizmetin her bölüm düzeyinde etkinliği tam olarak günlüğe kaydetmesini istiyorsunuz. Bu pahalı bir işlem olabileceğinden, yalnızca sorun giderme sırasında ayrıntılı bir şekilde etkinleştirilmesi genel veri akışınızı ve işlem hattı performansınızı iyileştirebilir. "Temel" modu yalnızca dönüştürme sürelerini günlüğe kaydederken "Yok" yalnızca sürelerin özetini sağlar.

İlgili içerik
- Kaynakları iyileştirme
- Lavaboları optimize etme
- Dönüştürmeleri iyileştirme
- İşlem hatlarında veri akışlarını kullanma
Performansla ilgili diğer Data Flow makalelere bakın: