Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede Apache Spark MLlib kullanarak Azure açık veri kümesinde basit tahmine dayalı analizler yapabilen bir makine öğrenmesi uygulaması oluşturmayı öğreneceksiniz. Spark, yerleşik makine öğrenmesi kitaplıkları sağlar. Bu örnek lojistik regresyon aracılığıyla sınıflandırmayı kullanır.
SparkML ve MLlib, aşağıdakiler için uygun yardımcı programlar da dahil olmak üzere makine öğrenmesi görevleri için yararlı olan birçok yardımcı program sağlayan temel Spark kitaplıklarıdır:
- Sınıflandırma
- Gerileme
- Kümeleme
- Konu modelleme
- Tekil değer ayrıştırma (SVD) ve asıl bileşen analizi (PCA)
- Hipotez testi ve örnek istatistikleri hesaplama
Sınıflandırmayı ve lojistik regresyonu anlama
Popüler bir makine öğrenmesi görevi olan sınıflandırma, giriş verilerini kategorilere ayırma işlemidir. Sağladığınız giriş verilerine etiket atamayı öğrenmek bir sınıflandırma algoritmasının işidir. Örneğin, hisse senedi bilgilerini girdi olarak kabul eden ve hisseyi iki kategoriye ayıran bir makine öğrenmesi algoritması düşünebilirsiniz: satmanız gereken hisse senetleri ve tutmanız gereken hisse senetleri.
Lojistik regresyon , sınıflandırma için kullanabileceğiniz bir algoritmadır. Spark'ın lojistik regresyon API'si ikili sınıflandırma veya giriş verilerini iki gruptan birinde sınıflandırmak için kullanışlıdır. Lojistik regresyon hakkında daha fazla bilgi için bkz. Vikipedi.
Özetle, lojistik regresyon işlemi, giriş vektörünün bir gruba veya diğerine ait olma olasılığını tahmin etmek için kullanabileceğiniz bir lojistik işlev oluşturur.
NYC taksi verileriyle ilgili tahmine dayalı analiz örneği
Bu örnekte Spark'ı kullanarak New York'tan gelen taksi yolculuğu ipucu verileriyle ilgili tahmine dayalı analizler gerçekleştirebilirsiniz. Veriler Azure Açık Veri Kümeleri aracılığıyla kullanılabilir. Veri kümesinin bu alt kümesi her yolculuk, başlangıç ve bitiş saati ve konumları, maliyet ve diğer ilginç öznitelikler hakkında bilgiler de dahil olmak üzere sarı taksi yolculukları hakkında bilgi içerir.
Önemli
Bu verileri depolama konumundan çekmek için ek ücretler olabilir.
Aşağıdaki adımlarda, belirli bir seyahatin ipucu içerip içermediğini tahmin etmek için bir model geliştirebilirsiniz.
Apache Spark makine öğrenmesi modeli oluşturma
PySpark çekirdeğini kullanarak bir not defteri oluşturun. Yönergeler için bkz . Not defteri oluşturma.
Bu uygulama için gereken türleri içeri aktarın. Aşağıdaki kodu kopyalayıp boş bir hücreye yapıştırın ve shift+Enter tuşlarına basın. Ya da kodun solundaki mavi yürütme simgesini kullanarak hücreyi çalıştırın.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorPySpark çekirdeği nedeniyle açıkça bağlam oluşturmanız gerekmez. spark bağlamı, ilk kod hücresini çalıştırdığınızda sizin için otomatik olarak oluşturulur.
Giriş DataFrame'ini oluşturma
Ham veriler Parquet biçiminde olduğundan Spark bağlamını kullanarak dosyayı doğrudan DataFrame olarak belleğe çekebilirsiniz. Aşağıdaki adımlardaki kod varsayılan seçenekleri kullansa da, gerekirse veri türlerinin ve diğer şema özniteliklerinin eşlemini zorlamak mümkündür.
Kodu yeni bir hücreye yapıştırarak Spark DataFrame oluşturmak için aşağıdaki satırları çalıştırın. Bu adım, Açık Veri Kümeleri API'sini kullanarak verileri alır. Bu verilerin tümünün çekilmesi yaklaşık 1,5 milyar satır oluşturur.
Sunucusuz Apache Spark havuzunuzun boyutuna bağlı olarak ham veriler çok büyük olabilir veya üzerinde çalışmak çok fazla zaman alabilir. Bu verileri daha küçük bir ölçekte filtreleyebilirsiniz. Aşağıdaki kod örneği,
start_dateveend_datekullanarak tek bir aylık veri döndüren bir filtre uygular.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Basit filtrelemenin dezavantajı, istatistiksel açıdan verilere sapma getirebileceğidir. Bir diğer yaklaşım da Spark'ta yerleşik olarak bulunan örneklemeyi kullanmaktır.
Aşağıdaki kod, önceki koddan sonra uygulanmışsa veri kümesini yaklaşık 2.000 satıra indirir. Basit filtre yerine veya basit filtreyle birlikte bu örnekleme adımını kullanabilirsiniz.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)Artık okunan verileri görmek için verilere bakabilirsiniz. Normalde veri kümesinin boyutuna bağlı olarak tam küme yerine bir alt kümeyle verileri gözden geçirmek daha iyidir.
Aşağıdaki kod, verileri görüntülemek için iki yol sunar. İlk yol temeldir. İkinci yol, verileri grafiksel olarak görselleştirme özelliğiyle birlikte çok daha zengin bir kılavuz deneyimi sağlar.
#sampled_taxi_df.show(5) display(sampled_taxi_df)Oluşturulan veri kümesinin boyutuna ve not defterini birçok kez denemeniz veya çalıştırmanız gerektiğinden, veri kümesini çalışma alanında yerel olarak önbelleğe almak isteyebilirsiniz. Açık önbelleğe alma işlemini gerçekleştirmenin üç yolu vardır:
- DataFrame'i yerel olarak dosya olarak kaydedin.
- DataFrame'i geçici bir tablo veya görünüm olarak kaydedin.
- DataFrame'i kalıcı bir tablo olarak kaydedin.
Bu yaklaşımlardan ilk ikisi aşağıdaki kod örneklerinde yer alır.
Geçici bir tablo veya görünüm oluşturmak verilere farklı erişim yolları sağlar, ancak yalnızca Spark örneği oturumu boyunca sürer.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
Verileri hazırlama
Ham biçimindeki veriler genellikle doğrudan bir modele geçirmek için uygun değildir. Modelin kullanabildiği bir duruma getirmek için veriler üzerinde bir dizi eylem gerçekleştirmeniz gerekir.
Aşağıdaki kodda dört işlem sınıfı gerçekleştirirsiniz:
- Filtre uygulama yoluyla aykırı değerlerin veya yanlış değerlerin kaldırılması.
- Gerekli olmayan sütunların kaldırılması.
- Modelin daha etkili çalışmasını sağlamak için ham verilerden türetilen yeni sütunların oluşturulması. Bu işleme bazen özellik kazandırma denir.
- Etiketleme. İkili sınıflandırmayı (belirli bir yolculukta ipucu olacak mı yoksa olmayacak mı) yaptığınız için, ipucu miktarını 0 veya 1 değerine dönüştürmeniz gerekir.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
Ardından son özellikleri eklemek için verilerin üzerinden ikinci bir geçiş yaparsınız.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
Lojistik regresyon modeli oluşturma
Son görev etiketlenmiş verileri lojistik regresyon aracılığıyla çözümlenebilen bir biçime dönüştürmektir. Lojistik regresyon algoritmasına giriş, etiket/özellik vektör çiftlerinden oluşmalıdır; burada özellik vektörü giriş noktasını temsil eden bir sayı vektörüdür.
Bu nedenle, kategorik sütunları sayılara dönüştürmeniz gerekir. Özellikle, trafficTimeBins ve weekdayString sütunlarını tamsayı biçimine dönüştürmeniz gerekir. Dönüştürmeyi gerçekleştirmek için birden çok yaklaşım vardır. Aşağıdaki örnek yaygın olan yaklaşımını benimser OneHotEncoder .
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
Bu eylem, modeli eğitmek için tüm sütunların doğru biçimde olduğu yeni bir DataFrame'e neden olur.
Lojistik regresyon modelini eğitme
İlk görev, veri kümesini bir eğitim kümesine ve bir test veya doğrulama kümesine bölmektir. Burada bölme rastgeledir. Modeli etkileyip etkilemediklerini görmek için farklı bölme ayarlarıyla denemeler yapın.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
artık iki DataFrame olduğuna göre, sonraki görev model formülünü oluşturmak ve eğitim DataFrame'inde çalıştırmaktır. Ardından test DataFrame'ine karşı doğrulama yapabilirsiniz. Farklı birleşimlerin etkisini görmek için model formülünün farklı sürümleriyle denemeler yapın.
Uyarı
Modeli kaydetmek için Depolama Blobu Veri Katkıda Bulunanı rolünü Azure SQL Veritabanı sunucusu kaynak kapsamına atayın. Ayrıntılı adımlar için bkz. Azure portalı kullanarak Azure rolleri atama. Bu adımı yalnızca sahip ayrıcalıklarına sahip üyeler gerçekleştirebilir.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
Bu hücrenin çıkışı:
Area under ROC = 0.9779470729751403
Tahminin görsel gösterimini oluşturma
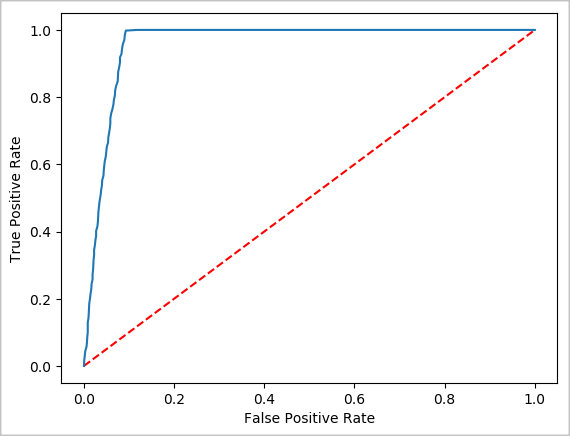
Artık bu testin sonuçları hakkında düşünmenize yardımcı olacak son bir görselleştirme oluşturabilirsiniz. ROC eğrisi, sonucu gözden geçirmenin bir yoludur.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Spark örneğini kapatma
Uygulamayı çalıştırmayı bitirdikten sonra, sekmeyi kapatarak kaynakları serbest bırakmak için not defterini kapatın. İsterseniz not defterinin altındaki durum panelinde Oturumu Sonlandır'ı da seçebilirsiniz.
Ayrıca bkz.
Sonraki adımlar
Uyarı
Resmi Apache Spark belgelerinden bazıları, Azure Synapse Analytics'te Apache Spark'ta bulunmayan Spark konsolunu kullanmaya dayanır. Bunun yerine not defterini veya IntelliJ deneyimlerini kullanın.