Belge Zekası özel modelleri
Önemli
- Document Intelligence genel önizleme sürümleri, etkin geliştirme aşamasında olan özelliklere erken erişim sağlar.
- Genel Kullanılabilirlik (GA) öncesinde kullanıcı geri bildirimlerine göre özellikler, yaklaşımlar ve süreçler değişebilir.
- Belge Zekası istemci kitaplıklarının genel önizleme sürümü varsayılan olarak REST API sürüm 2024-02-29-preview'dır.
- Genel önizleme sürümü 2024-02-29-preview şu anda yalnızca aşağıdaki Azure bölgelerinde kullanılabilir:
- Doğu ABD
- Batı ABD2
- Batı Avrupa
Bu içerik şunlar için geçerlidir:![]() v4.0 (önizleme) | Önceki sürümler:
v4.0 (önizleme) | Önceki sürümler:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Bu içerik:![]() v3.1 (GA) | En son sürüm:
v3.1 (GA) | En son sürüm:![]() v4.0 (önizleme) | Önceki sürümler:
v4.0 (önizleme) | Önceki sürümler:![]() v3.0
v3.0![]() v2.1 için geçerlidir
v2.1 için geçerlidir
Bu içerik:![]() v3.0 (GA) | En son sürümler:
v3.0 (GA) | En son sürümler:![]() v4.0 (önizleme)
v4.0 (önizleme)![]() v3.1 | Önceki sürüm:
v3.1 | Önceki sürüm:![]() v2.1 için geçerlidir
v2.1 için geçerlidir
Bu içerik:![]() v2.1 | En son sürüm:
v2.1 | En son sürüm:![]() v4.0 (önizleme) için geçerlidir
v4.0 (önizleme) için geçerlidir
Belge Zekası, belgeleri tanımlamak, formlardan ve belgelerden bilgileri algılamak ve ayıklamak ve ayıklanan verileri yapılandırılmış bir JSON çıkışına döndürmek için gelişmiş makine öğrenmesi teknolojisini kullanır. Belge Zekası ile belge çözümleme modellerini, önceden oluşturulmuş/önceden eğitilmiş veya eğitilmiş tek başına özel modellerinizi kullanabilirsiniz.
Özel modeller artık ayıklama modelini çağırmadan önce belge türünü tanımlamanız gereken senaryolar için özel sınıflandırma modelleri içerir. Sınıflandırıcı modelleri API'den 2023-07-31 (GA) başlayarak kullanılabilir. Sınıflandırma modeli, bir belge işleme çözümü oluşturmak üzere işletmenize özgü form ve belgelerden alanları analiz etmek ve ayıklamak için özel bir ayıklama modeliyle eşleştirilebilir. Tek başına özel ayıklama modelleri bir araya getirilerek oluşturulan modeller oluşturulabilir.
Özel belge modeli türleri
Özel belge modelleri, özel şablon veya özel form ve özel nöral veya özel belge modellerinden biri olmak üzere iki türden biri olabilir. Her iki model için etiketleme ve eğitim süreci aynıdır, ancak modeller aşağıdaki gibi farklılık gösterir:
Özel ayıklama modelleri
Özel ayıklama modeli oluşturmak için, bir belge veri kümesini ayıklanmasını istediğiniz değerlerle etiketleyip etiketlenmiş veri kümesinde modeli eğitin. Başlamak için aynı form veya belge türünün yalnızca beş örneğine ihtiyacınız vardır.
Özel sinir modeli
Önemli
Sürüm 4.0 — 2024-02-29-preview API'siyle başlayan özel sinir modelleri artık çakışan alanları ve tablo, satır ve hücre düzeyi güvenilirliğini destekliyor.
Özel sinirsel (özel belge) modeli, derin öğrenme modellerini ve büyük bir belge koleksiyonu üzerinde eğitilen temel modeli kullanır. Bu model daha sonra etiketli bir veri kümesiyle eğittiğinizde verilerinize ince ayarlar yapılır veya uyarlanır. Özel sinir modelleri, alanları ayıklamak için yapılandırılmış, yarı yapılandırılmış ve yapılandırılmamış belgeleri destekler. Özel sinir modelleri şu anda İngilizce belgeleri desteklemektedir. İki model türü arasında seçim yaparken işlev gereksinimlerinizi karşılayıp karşılamadığını belirlemek için bir sinir modeliyle başlayın. Özel belge modelleri hakkında daha fazla bilgi edinmek için bkz. sinir modelleri.
Özel şablon modeli
Özel şablon veya özel form modeli, etiketlenmiş verileri ayıklamak için tutarlı bir görsel şablonu kullanır. Belgelerinizin görsel yapısındaki farklar modelinizin doğruluğunu etkiler. Anketler veya uygulamalar gibi yapılandırılmış formlar, tutarlı görsel şablonların örnekleridir.
Eğitim kümeniz, biçimlendirme ve düzenin bir belge örneğinden diğerine statik ve sabit olduğu yapılandırılmış belgelerden oluşur. Özel şablon modelleri anahtar-değer çiftlerini, seçim işaretlerini, tabloları, imza alanlarını ve bölgeleri destekler. Şablon modelleri ve desteklenen dillerden herhangi birindeki belgeler üzerinde eğitilebilir. Daha fazla bilgi için bkz. özel şablon modelleri.
Belgelerinizin dili ve ayıklama senaryoları özel sinir modellerini destekliyorsa, daha yüksek doğruluk için şablon modelleri üzerinde özel sinir modelleri kullanmanızı öneririz.
İpucu
Eğitim belgelerinizin tutarlı bir görsel şablonu sunduğunu onaylamak için, kümedeki her formdan kullanıcı tarafından girilen tüm verileri kaldırın. Boş formlar görünümde aynıysa, tutarlı bir görsel şablonu temsil ederler.
Daha fazla bilgi için bkz. Özel modeller için doğruluğu ve güvenilirliği yorumlama ve geliştirme.
Giriş gereksinimleri
En iyi sonuçları elde için belge başına tek bir net fotoğraf veya yüksek kaliteli tarama sağlayın.
Desteklenen dosya biçimleri:
Model PDF Resim:
jpeg/jpg, png, bmp, tiff, heifMicrosoft Office:
Word (docx), Excel (xlsx), PowerPoint (pptx)Okundu ✔ ✔ ✔ Düzen ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview ve üzeri) Genel Belge ✔ ✔ Önceden oluşturulmuş ✔ ✔ Özel ayıklama ✔ ✔ Özel sınıflandırma ✔ ✔ ✔ ✱ Microsoft Office dosyaları şu anda diğer modeller veya sürümler için desteklenmiyor.
PDF ve TIFF için en fazla 2.000 sayfa işlenebilir (ücretsiz katman aboneliğiyle yalnızca ilk iki sayfa işlenir).
Belgeleri analiz etmek için dosya boyutu ücretli (S0) katman için 500 MB ve ücretsiz (F0) katmanı için 4 MB'tır.
Görüntü boyutları 50 x 50 piksel ile 10.000 piksel x 10.000 piksel arasında olmalıdır.
PDF’leriniz parola korumalıysa göndermeden önce kilidi kaldırmanız gerekir.
Ayıklanacak metnin en düşük yüksekliği 1024 x 768 piksel görüntü için 12 pikseldir. Bu boyut, inç başına 150 nokta olan yaklaşık
8nokta metnine karşılık gelir.Özel model eğitimi için eğitim verileri için en fazla sayfa sayısı özel şablon modeli için 500, özel sinir modeli için 50.000'dir.
Özel ayıklama modeli eğitimi için eğitim verilerinin toplam boyutu şablon modeli için 50 MB ve sinir modeli için 1G-MB'tır.
Özel sınıflandırma modeli eğitimi için eğitim verilerinin toplam boyutu en fazla 10.000 sayfadır
1GB.
Derleme modu
Özel model oluşturma işlemi, şablon ve sinir özel modelleri için destek ekler. REST API'nin ve istemci kitaplıklarının önceki sürümleri artık şablon modu olarak bilinen tek bir derleme modunu destekliyor.
Şablon modelleri yalnızca aynı temel sayfa yapısına (tekdüzen bir görsel görünüme) veya belge içindeki öğelerin aynı göreli konumuna sahip belgeleri kabul eder.
Sinir modelleri aynı bilgilere ancak farklı sayfa yapılarına sahip belgeleri destekler. Bu belgelere örnek olarak, aynı bilgileri paylaşan ancak şirketler arasında görünüm olarak farklılık gösteren Birleşik Devletler W2 formları verilebilir. Sinir modelleri şu anda yalnızca İngilizce metinleri destekler.
Bu tablo, GitHub'da derleme modu programlama dili SDK başvurularının ve kod örneklerinin bağlantılarını sağlar:
| Programlama dili | SDK başvurusu | Kod örneği |
|---|---|---|
| C#/.NET | DocumentBuildMode Yapısı | Sample_BuildCustomModelAsync.cs |
| Java | DocumentBuildMode Sınıfı | BuildModel.java |
| JavaScript | DocumentBuildMode türü | buildModel.js |
| Python | DocumentBuildMode Sabit Listesi | sample_build_model.py |
Model özelliklerini karşılaştırma
Aşağıdaki tabloda özel şablon ve özel nöral özellikler karşılaştırılarak yer alır:
| Özellik | Özel şablon (form) | Özel nöral (belge) |
|---|---|---|
| Belge yapısı | Şablon, form ve yapılandırılmış | Yapılandırılmış, yarı yapılandırılmış ve yapılandırılmamış |
| Eğitim süresi | 1 - 5 dakika | 20 dakika ile 1 saat arasında |
| Veri ayıklama | Anahtar-değer çiftleri, tablolar, seçim işaretleri, koordinatlar ve imzalar | Anahtar-değer çiftleri, seçim işaretleri ve tablolar |
| Çakışan alanlar | Desteklenmez | Desteklenir |
| Belge çeşitlemeleri | Her çeşitleme için bir model gerektirir | Tüm varyasyonlar için tek bir model kullanır |
| Dil desteği | Birden çok dil desteği | İngilizce, İspanyolca, Fransızca, Almanca, İtalyanca ve Felemenkçe dil desteği için önizleme desteğiyle |
Özel sınıflandırma modeli
Belge sınıflandırması, (v3.1 GA) API'siyle Belge Zekası 2023-07-31 tarafından desteklenen yeni bir senaryodur. Belge sınıflandırıcı API'si sınıflandırma ve bölme senaryolarını destekler. Uygulamanızın desteklediği farklı belge türlerini tanımlamak için bir sınıflandırma modeli eğitin. Sınıflandırma modelinin giriş dosyası birden çok belge içerebilir ve ilişkili bir sayfa aralığındaki her belgeyi sınıflandırır. Daha fazla bilgi edinmek için bkz. özel sınıflandırma modelleri.
Not
API sürümü belge sınıflandırmasıyla 2024-02-29-preview başlayarak artık sınıflandırma için Office belge türlerini destekliyor. Bu API sürümü, sınıflandırma modeli için artımlı eğitim de sağlar.
Özel model araçları
Document Intelligence v3.1 ve üzeri modeller aşağıdaki araçları, uygulamaları ve kitaplıkları, programları ve kitaplıkları destekler:
| Özellik | Kaynaklar | Model Kimliği |
|---|---|---|
| Özel model | • Document Intelligence Studio • REST API • C# SDK • Python SDK |
custom-model-id |
Document Intelligence v2.1 aşağıdaki araçları, uygulamaları ve kitaplıkları destekler:
Not
Özel model türleri özel sinir ve özel şablon , Belge Yönetim Bilgileri sürümü v3.1 ve v3.0 API'leriyle kullanılabilir.
| Özellik | Kaynaklar |
|---|---|
| Özel model | • Belge Zekası etiketleme aracı • REST API • İstemci kitaplığı SDK'sı • Belge Zekası Docker kapsayıcısı |
Özel model derleme
Özel modelleri kullanarak belirli veya benzersiz belgelerinizdeki verileri ayıklayın. Aşağıdaki kaynaklara ihtiyacınız vardır:
Azure aboneliği. Ücretsiz bir tane oluşturabilirsiniz.
Azure portalında bir Belge Zekası örneği. Hizmeti denemek için ücretsiz fiyatlandırma katmanını (
F0) kullanabilirsiniz. Kaynağınız dağıtıldıktan sonra anahtarınızı ve uç noktanızı almak için Kaynağa git'i seçin.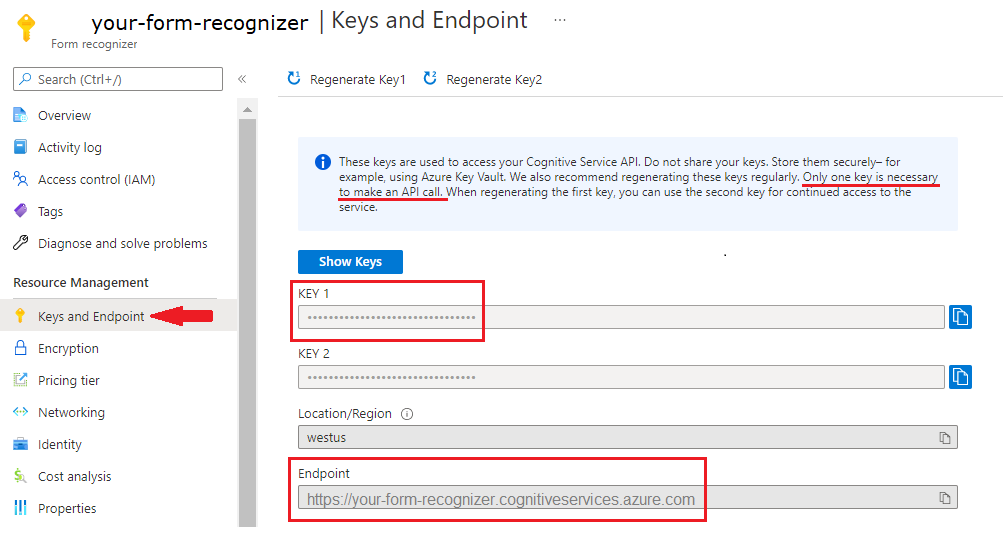
Örnek Etiketleme aracı
İpucu
- Gelişmiş bir deneyim ve gelişmiş model kalitesi için Document Intelligence v3.0 Studio'yu deneyin.
- v3.0 Studio, v2.1 etiketli verilerle eğitilen tüm modelleri destekler.
- v2.1'den v3.0'a geçiş hakkında ayrıntılı bilgi için API geçiş kılavuzuna başvurabilirsiniz.
- v3.0 sürümünü kullanmaya başlamak için REST API veya C#, Java, JavaScript veya Python SDK hızlı başlangıçlarımıza bakın.
Belge Zekası Örnek Etiketleme aracı, Belge Zekası ve Optik Karakter Tanıma (OCR) özelliklerinin en son özelliklerini test etmenizi sağlayan açık kaynak bir araçtır.
Özel model oluşturmaya ve kullanmaya başlamak için Örnek Etiketleme aracı hızlı başlangıcını deneyin.
Belge Makine Zekası Stüdyosu
Not
Document Intelligence Studio, v3.1 ve v3.0 API'leriyle kullanılabilir.
Document Intelligence Studio giriş sayfasında Özel ayıklama modelleri'ni seçin.
Projelerim'in altında Proje oluştur'u seçin.
Proje ayrıntıları alanlarını tamamlayın.
Eğitim veri kaynağınızı Bağlan için Depolama hesabınızı ve Blob kapsayıcınızı ekleyerek hizmet kaynağını yapılandırın.
Projenizi gözden geçirin ve oluşturun.
Özel modelinizi etiketlemek, derlemek ve test etmek için örnek belgelerinizi ekleyin.
İlk özel ayıklama modelinizi oluşturmaya yönelik ayrıntılı bir izlenecek yol için bkz. Özel ayıklama modeli oluşturma.
Özel model ayıklama özeti
Bu tablo desteklenen veri ayıklama alanlarını karşılaştırır:
| Model | Form alanları | Seçim işaretleri | Yapılandırılmış alanlar (Tablolar) | İmza | Bölge etiketleme | Çakışan alanlar |
|---|---|---|---|---|---|---|
| Özel şablon | ✔ | ✔ | ✔ | ✔ | ✔ | Yok |
| Özel nöral | ✔ | ✔ | ✔ | Yok | * | ✔ (2024-02-29-preview) |
Tablo simgeleri:
✔ —Desteklenir
**yok—Şu anda kullanılamıyor;
*-Modele bağlı olarak farklı davranır. Şablon modelleriyle yapay veriler eğitim zamanında oluşturulur. Sinir modellerinde, bölgede tanınan metinden çıkma seçilidir.
İpucu
İki model türü arasında seçim yaparken, işlevsel gereksinimlerinizi karşılıyorsa özel bir sinir modeliyle başlayın. Özel sinir modelleri hakkında daha fazla bilgi edinmek için bkz. özel sinir.
Özel model geliştirme seçenekleri
Aşağıdaki tabloda, ilişkili araçlar ve istemci kitaplıklarıyla kullanılabilen özellikler açıklanmaktadır. En iyi uygulama olarak, burada listelenen uyumlu araçları kullandığınızdan emin olun.
| Document type | REST API | SDK | Modelleri Etiketleme ve Test Et |
|---|---|---|---|
| Özel şablon v 4.0 v3.1 v3.0 | Belge Yönetim Bilgileri 3.1 | Belge Yönetim Bilgileri SDK'sı | Belge Makine Zekası Stüdyosu |
| Özel nöral v4.0 v3.1 v3.0 | Belge Yönetim Bilgileri 3.1 | Belge Yönetim Bilgileri SDK'sı | Belge Makine Zekası Stüdyosu |
| Özel form v2.1 | Belge Zekası 2.1 GA API'si | Belge Yönetim Bilgileri SDK'sı | Örnek etiketleme aracı |
Not
3.0 API'siyle eğitilen özel şablon modellerinde, OCR altyapısında yapılan iyileştirmelerden kaynaklanan 2.1 API üzerinde birkaç geliştirme yapılacaktır. 2.1 API'sini kullanarak özel şablon modelini eğitmek için kullanılan veri kümeleri, 3.0 API'sini kullanarak yeni bir modeli eğitmek için kullanılabilir.
En iyi sonuçları elde için belge başına tek bir net fotoğraf veya yüksek kaliteli tarama sağlayın.
Desteklenen dosya biçimleri JPEG/JPG, PNG, BMP, TIFF ve PDF'tir (metin eklenmiş veya taranmış). Metin eklenmiş PDF’ler, karakter ayıklama ve konum ile ilgili hata olasılığını azaltma açısından en iyi seçenektir.
PDF ve TIFF dosyaları için en fazla 2.000 sayfa işlenebilir. Ücretsiz katman aboneliğiyle yalnızca ilk iki sayfa işlenir.
Dosya boyutu ücretli (S0) katman için 500 MB'tan az ve ücretsiz (F0) katman için 4 MB'tan az olmalıdır.
Görüntü boyutları 50 x 50 piksel ile 10.000 x 10.000 piksel arasında olmalıdır.
PDF boyutları, Yasal veya A3 kağıt boyutuna karşılık gelen 17 x 17 inç veya daha küçüktür.
Eğitim verilerinin toplam boyutu 500 sayfa veya daha azdır.
PDF’leriniz parola korumalıysa göndermeden önce kilidi kaldırmanız gerekir.
İpucu
Eğitim verileri:
- Mümkünse, görüntü tabanlı belgeler yerine metin tabanlı PDF belgeleri kullanın. Taranan PDF'ler görüntü olarak işlenir.
- Lütfen belge başına formun yalnızca tek bir örneğini sağlayın.
- Doldurulmuş formlar için, tüm alanlarının doldurulduğu örnekleri kullanın.
- Her alanda farklı değerlere sahip olan formlar kullanın.
- Form görüntüleriniz daha düşük kalitedeyse daha büyük bir veri kümesi kullanın. Örneğin, 10-15 resim kullanın.
Desteklenen diller ve yerel ayarlar
Desteklenen dillerin tam listesi için Dil Desteği— özel modeller sayfamıza bakın.
Sonraki adımlar
Belge Yönetim Bilgileri Örnek Etiketleme aracıyla kendi formlarınızı ve belgelerinizi işlemeyi deneyin.
Belge Zekası hızlı başlangıcını tamamlayın ve seçtiğiniz geliştirme dilinde bir belge işleme uygulaması oluşturmaya başlayın.
Document Intelligence Studio ile kendi formlarınızı ve belgelerinizi işlemeyi deneyin.
Belge Zekası hızlı başlangıcını tamamlayın ve seçtiğiniz geliştirme dilinde bir belge işleme uygulaması oluşturmaya başlayın.