Çözüm fikirleri
Bu makalede bir çözüm fikri açıklanmaktadır. Bulut mimarınız bu mimarinin tipik bir uygulaması için ana bileşenleri görselleştirmeye yardımcı olmak için bu kılavuzu kullanabilir. İş yükünüzün özel gereksinimlerine uygun iyi tasarlanmış bir çözüm tasarlamak için bu makaleyi başlangıç noktası olarak kullanın.
Azure'da özel bir doğal dil işleme (NLP) çözümü uygulayın. Konu, yaklaşım algılama ve analiz gibi görevler için Spark NLP kullanın.
Apache®, Apache Spark ve alev logosu, Apache Software Foundation'ın Birleşik Devletler ve/veya diğer ülkelerdeki kayıtlı ticari markaları veya ticari markalarıdır. Bu işaretlerin kullanılması Apache Software Foundation tarafından onaylanmamaktadır.
Mimari

Bu mimarinin bir Visio dosyasını indirin.
İş Akışı
- Azure Event Hubs, Azure Data Factory veya her iki hizmet de belgeleri veya yapılandırılmamış metin verilerini alır.
- Event Hubs ve Data Factory verileri Azure Data Lake Storage'da dosya biçiminde depolar. İş gereksinimlerine uygun bir dizin yapısı ayarlamanızı öneririz.
- Azure Görüntü İşleme API'sinde verileri kullanmak için optik karakter tanıma (OCR) özelliği kullanılır. Ardından API, verileri bronz katmana yazar. Bu tüketim platformu bir göl evi mimarisi kullanır.
- Bronz katmanda, çeşitli Spark NLP özellikleri metni önceden işler. Örnek olarak bölme, yazım düzeltme, temizleme ve dil bilgisini anlama verilebilir. Bronz katmanda belge sınıflandırmasını çalıştırmanızı ve ardından sonuçları gümüş katmana yazmanızı öneririz.
- Gümüş katmanda, gelişmiş Spark NLP özellikleri adlandırılmış varlık tanıma, özetleme ve bilgi alma gibi belge çözümleme görevlerini gerçekleştirir. Bazı mimarilerde sonuç altın katmana yazılır.
- Altın katmanda Spark NLP, metin verileri üzerinde çeşitli dilsel görsel analizleri çalıştırır. Bu analizler, dil bağımlılıkları hakkında içgörü sağlar ve NER etiketlerinin görselleştirmesine yardımcı olur.
- Kullanıcılar altın katman metin verilerini veri çerçevesi olarak sorgular ve sonuçları Power BI veya web uygulamalarında görüntüler.
İşleme adımları sırasında Azure Databricks, Azure Synapse Analytics ve Azure HDInsight, NLP işlevselliği sağlamak için Spark NLP ile birlikte kullanılır.
Bileşenler
- Data Lake Storage, tümleşik hiyerarşik ad alanına ve büyük ölçekli ve Azure Blob Depolama ekonomisine sahip Hadoop uyumlu bir dosya sistemidir.
- Azure Synapse Analytics , veri ambarları ve büyük veri sistemleri için bir analiz hizmetidir.
- Azure Databricks , kullanımı kolay, işbirliğini kolaylaştıran ve Apache Spark'ı temel alan büyük verilere yönelik bir analiz hizmetidir. Azure Databricks, veri bilimi ve veri mühendisliği için tasarlanmıştır.
- Event Hubs , istemci uygulamalarının oluşturduğu veri akışlarını alır. Event Hubs akış verilerini depolar ve alınan olayların sırasını korur. Tüketiciler, işlenmek üzere iletileri almak üzere hub uç noktalarına bağlanabilir. Event Hubs, bu çözümde gösterildiği gibi Data Lake Storage ile tümleşir.
- Azure HDInsight , kuruluşlar için bulutta yönetilen, tam spektrumlu bir açık kaynak analiz hizmetidir. Azure HDInsight ile Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm ve R gibi açık kaynak çerçeveleri kullanabilirsiniz.
- Data Factory , görevlerin ayrılmasını sağlamak için verileri farklı güvenlik düzeylerindeki depolama hesapları arasında otomatik olarak taşır.
- Görüntü İşleme görüntülerdeki metinleri tanımak ve bu bilgileri ayıklamak için metin tanıma API'lerini kullanır. Okuma API'si en son tanıma modellerini kullanır ve büyük, metin yoğunluklu belgeler ve gürültülü görüntüler için iyileştirilmiştir. OCR API'si büyük belgeler için iyileştirilmemiştir ancak Okuma API'sinden daha fazla dili destekler. Bu çözüm, hOCR biçiminde veri üretmek için OCR kullanır.
Senaryo ayrıntıları
Doğal dil işlemenin (NLP) birçok kullanımı vardır: yaklaşım analizi, konu algılama, dil algılama, anahtar tümcecik ayıklama ve belge kategorisi.
Apache Spark, NLP gibi büyük veri analizi uygulamalarının performansını artırmak için bellek içi işlemeyi destekleyen paralel bir işleme çerçevesidir. Azure Synapse Analytics, Azure HDInsight ve Azure Databricks Spark'a erişim sağlar ve işlem gücünden yararlanır.
Özelleştirilmiş NLP iş yükleri için Spark NLP açık kaynak kitaplığı, büyük miktarda metni işlemek için verimli bir çerçeve görevi görür. Bu makalede Azure'da büyük ölçekli özel NLP için bir çözüm sunulur. Çözüm, metinleri işlemek ve analiz etmek için Spark NLP özelliklerini kullanır. Spark NLP hakkında daha fazla bilgi için bu makalenin devamında yer alan Spark NLP işlevselliği ve işlem hatları bölümüne bakın.
Olası kullanım örnekleri
Belge sınıflandırması: Spark NLP, metin sınıflandırması için çeşitli seçenekler sunar:
- Spark ML'yi temel alan Spark NLP ve makine öğrenmesi algoritmalarında metin ön işleme
- Spark NLP'de metin ön işleme ve sözcük ekleme ve GloVe, BERT ve ELMo gibi makine öğrenmesi algoritmaları
- Spark NLP'de metin ön işleme ve tümce ekleme ve Evrensel Cümle Kodlayıcı gibi makine öğrenmesi algoritmaları ve modelleri
- Spark NLP'de ClassifierDL açıklama ekleyicisini kullanan ve TensorFlow'u temel alan metin ön işlemesi ve sınıflandırması
Ad varlığı ayıklama (NER): Spark NLP'de, birkaç kod satırıyla BERT kullanan bir NER modeli eğitebilir ve son derece yüksek doğruluk elde edebilirsiniz. NER, bilgi ayıklamanın bir alt görevidir. NER, adlandırılmış varlıkları yapılandırılmamış metinde bulur ve bunları kişi adları, kuruluşlar, konumlar, tıbbi kodlar, zaman ifadeleri, miktarlar, parasal değerler ve yüzdeler gibi önceden tanımlanmış kategorilere sınıflandırır. Spark NLP, BERT ile son derece yeni bir NER modeli kullanır. Model, çift yönlü LSTM-CNN adlı eski bir NER modelinden ilham alır. Bu eski model, sözcük düzeyi ve karakter düzeyi özelliklerini otomatik olarak algılayan yeni bir sinir ağı mimarisi kullanır. Bu amaçla model karma çift yönlü LSTM ve CNN mimarisi kullandığından özellik mühendisliğinin çoğuna olan ihtiyacı ortadan kaldırır.
Yaklaşım ve duygu algılama: Spark NLP dilin pozitif, negatif ve nötr yönlerini otomatik olarak algılayabilir.
Konuşmanın parçası (POS): Bu işlev, giriş metnindeki her belirteç için bir dil bilgisi etiketi atar.
Cümle algılama (SD): SD, metin içindeki cümleleri tanımlayan cümle sınırı algılaması için genel amaçlı bir sinir ağı modelini temel alır. Birçok NLP görevi giriş birimi olarak bir cümle alır. Bu görevlere örnek olarak POS etiketleme, bağımlılık ayrıştırma, adlandırılmış varlık tanıma ve makine çevirisi verilebilir.
Spark NLP işlevselliği ve işlem hatları
Spark NLP spaCy, NLTK, Stanford CoreNLP ve Open NLP gibi geleneksel NLP kitaplıklarının tüm işlevlerini sunan Python, Java ve Scala kitaplıkları sağlar. Spark NLP ayrıca yazım denetimi, yaklaşım analizi ve belge sınıflandırması gibi işlevler de sunar. Spark NLP, son derece yüksek doğruluk, hız ve ölçeklenebilirlik sağlayarak önceki çabaları geliştirir.
Spark NLP açık ara en hızlı açık kaynak NLP kitaplığıdır. Son genel karşılaştırmalar Spark NLP'yi spaCy'den 38 ve 80 kat daha hızlı olarak gösterir ve özel modelleri eğitme için karşılaştırılabilir doğruluk sunar. Spark NLP, dağıtılmış Spark kümesi kullanabilen tek açık kaynak kitaplıktır. Spark NLP, spark ML'nin doğrudan veri çerçeveleri üzerinde çalışan yerel bir uzantısıdır. Sonuç olarak, bir kümedeki hız artışları başka bir performans artışı sırasına neden olabilir. Her Spark NLP işlem hattı bir Spark ML işlem hattı olduğundan, Spark NLP belge sınıflandırması, risk tahmini ve öneren işlem hatları gibi birleşik NLP ve makine öğrenmesi işlem hatları oluşturmak için çok uygundur.
Spark NLP, mükemmel performansın yanı sıra, artan sayıda NLP görevi için son derece yüksek doğruluk sunar. Spark NLP ekibi düzenli olarak en son ilgili akademik çalışmaları okur ve en doğru modelleri üretir.
Bir NLP işlem hattının yürütme sırası için Spark NLP, geleneksel Spark makine öğrenmesi modelleri ile aynı geliştirme kavramını izler. Ancak Spark NLP, NLP tekniklerini uygular. Aşağıdaki diyagramda Spark NLP işlem hattının temel bileşenleri gösterilmektedir.
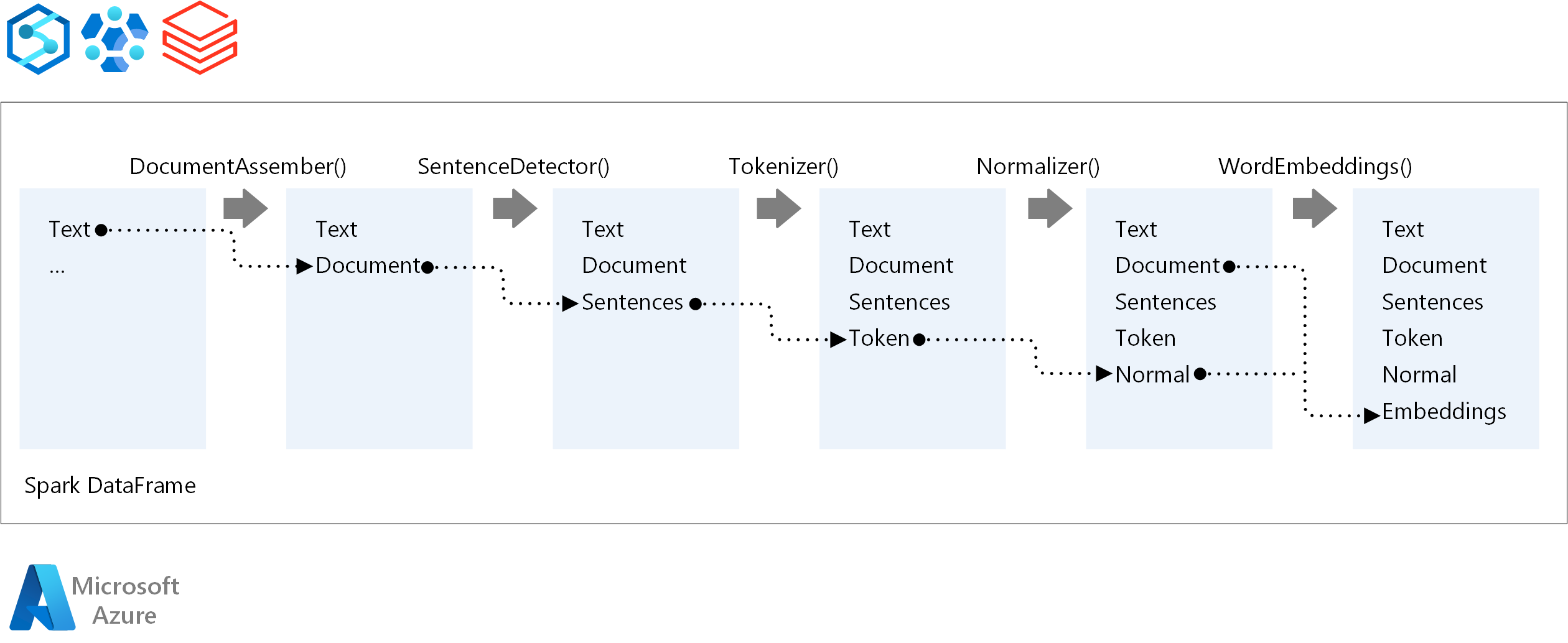
Katkıda Bulunanlar
Bu makale Microsoft tarafından yönetilir. Başlangıçta aşağıdaki katkıda bulunanlar tarafından yazılmıştır.
Asıl yazar:
- Moritz Steller | Üst Düzey Bulut Çözümü Mimarı
Sonraki adımlar
Spark NLP belgeleri:
Azure bileşenleri: