Birçok büyük ölçekli çözümde veriler ayrı ayrı yönetilebilen ve erişilebilen bölümlere ayrılır. Bölümleme ölçeklenebilirliği geliştirebilir, çekişmeyi azaltabilir ve performansı iyileştirebilir. Ayrıca verileri kullanım desenine göre bölmek için bir mekanizma sağlar. Örneğin, daha eski verileri daha ucuz veri depolamasında arşivleyebilirsiniz.
Ancak, olumsuz etkileri en aza indirirken avantajları en üst düzeye çıkarmak için bölümleme stratejisi dikkatli bir şekilde seçilmelidir.
Not
Bu makalede bölümleme terimi, verileri fiziksel olarak ayrı veri depolarına bölme işlemi anlamına gelir. Bu, SQL Server tablo bölümleme terimiyle aynı değildir.
Veriler neden bölümlenmeli?
Ölçeklenebilirliği geliştirme. Tek bir veritabanı sisteminin ölçeğini büyüttüğünüzde, bu sistem sonunda fiziksel donanımın sınırına ulaşacaktır. Her birinde ayrı bir sunucuda barındırılan verileri birden çok bölüme bölerseniz, sistemin ölçeğini neredeyse süresiz olarak genişletebilirsiniz.
Performansı geliştirme. Her bölümde veri erişim işlemleri daha küçük bir veri hacmi üzerinde gerçekleşir. Doğru şekilde yapıldığında bölümleme, sisteminizi daha verimli hale getirir. Birden çok bölümü etkileyen işlemler paralel çalıştırılabilir.
Güvenliği geliştirme. Bazı durumlarda, hassas ve duyarsız verileri farklı bölümlere ayırabilir ve hassas verilere farklı güvenlik denetimleri uygulayabilirsiniz.
İşletimsel esneklik sağlama. Bölümleme, işlemlere ince ayar yapmak, yönetim verimliliğini en üst düzeye çıkarmak ve maliyeti en aza indirmek için birçok fırsat sunar. Örneğin, her bölümdeki verilerin önemine bağlı olarak yönetim, izleme, yedekleme, geri yükleme ve diğer idari görevler için farklı stratejiler tanımlayabilirsiniz.
Veri deposunu kullanım düzeniyle eşleştirme. Bölümleme sayesinde, veri deposunun maliyetine ve sunduğu yerleşik özelliklere bağlı olarak her bölüm farklı bir veri deposuna dağıtılabilir. Örneğin, büyük ikili veriler blob depolamada depolanabilirken, belge veritabanında daha yapılandırılmış veriler tutulabilir. Daha fazla bilgi için bkz . Doğru veri depounu seçme.
Kullanılabilirliği geliştirme. Verilerin birden çok sunucuya ayrılması tek hata noktası sorununu önler. Bir örnek başarısız olursa, yalnızca bu bölümdeki veriler kullanılamaz. Diğer bölümlerdeki işlemler devam edebilir. Yönetilen hizmet olarak platform (PaaS) veri depolarında, bu hizmetler yerleşik yedeklilikle tasarlandığından bu konu daha az ilgilidir.
Bölümleri tasarlama
Verileri bölümlemeye yönelik üç tipik strateji vardır:
Yatay bölümleme (çoğunlukla parçalama olarak adlandırılır). Bu stratejide her bölüm ayrı bir veri deposudur, ancak tüm bölümler aynı şemaya sahiptir. Her bölüm parça olarak bilinir ve belirli bir müşteri kümesinin tüm siparişleri gibi verilerin belirli bir alt kümesini tutar.
Dikey bölümleme. Bu stratejide, her bölüm veri deposundaki öğelere ilişkin alanların bir alt kümesini barındırır. Alanlar kendi kullanım düzenlerine göre bölünmüştür. Örneğin, sık erişilen alanlar bir dikey bölüme yerleştirilirken daha az erişilen alanlar başka bir dikey bölüme yerleştirilebilir.
İşlevsel bölümleme. Bu stratejide veriler, sistemdeki sınırlanmış her bağlam tarafından nasıl kullanıldıklarına göre bir araya toplanır. Örneğin, bir e-ticaret sistemi fatura verilerini bir bölümde, ürün envanteri verilerini ise başka bir bölümde depolayabilir.
Bu stratejiler birleştirilebilir ve bölümleme şeması tasarlarken bunların tümünü göz önünde bulundurmanızı öneririz. Örneğin, verileri parçalara bölebilir ve ardından her parçadaki verileri alt bölümlere ayırmak için dikey bölümleme kullanabilirsiniz.
Yatay bölümleme (parçalama)
Şekil 1'de yatay bölümleme veya parçalama gösterilmektedir. Bu örnekte, ürün envanter verileri ürün anahtarına göre parçalara bölünmüştür. Her parça, alfabetik olarak düzenlenmiş birbirini takip eden bir parça anahtarı aralığındaki (A-G ve H-Z) verileri içerir. Parçalama, yükü daha fazla bilgisayara yayarak çekişmesini azaltır ve performansı artırır.

Şekil 1 - Bir bölüm anahtarına göre verileri yatay olarak bölümleme (parçalama).
En önemli faktör parçalama anahtarı seçimidir. Sistem çalışmaya başladıktan sonra anahtarı değiştirmek zor olabilir. Anahtar, iş yükünü parçalara mümkün olduğunca eşit bir şekilde yaymak için verilerin bölümlendiğinden emin olmalıdır.
Parçaların aynı boyutta olması gerekmez. İstek sayısını dengelemek daha önemlidir. Bazı parçalar çok büyük olabilir, ancak her öğenin erişim işlemi sayısı düşüktür. Öte yandan diğer parçalar daha küçüktür ama her öğeye çok daha sık erişiliyordur. Tek bir parçanın veri deposunun ölçek sınırlarını (kapasite ve işleme kaynakları açısından) aşmadığından emin olmak da önemlidir.
Performansı ve kullanılabilirliği etkileyebilecek "sık erişimli" bölümler oluşturmaktan kaçının. Örneğin, bir müşterinin adının ilk harfini kullanmak, bazı harfler daha yaygın olduğundan dengesiz bir dağıtıma neden olur. Bunun yerine, verileri bölümler arasında daha eşit dağıtmak için müşteri tanımlayıcısının karması kullanın.
Büyük parçaları bölmek, küçük parçaları daha büyük bölümlere ayırmak veya şemayı değiştirmek için gelecekteki gereksinimleri en aza indiren bir parçalama anahtarı seçin. Bu işlemler fazlasıyla zaman alabilir ve bunları gerçekleştirmek için bir veya birden çok parçayı çevrimdışı bırakmak gerekebilir.
Parçalar çoğaltılırsa, çoğaltmalardan bazıları ayrılır, birleştirilir veya yeniden yapılandırılırken diğerlerini çevrimiçi tutmak mümkün olabilir. Ancak, sistemin yeniden yapılandırma sırasında gerçekleştirilebilecek işlemleri sınırlaması gerekebilir. Örneğin, veri tutarsızlıklarını önlemek için çoğaltmalardaki veriler salt okunur olarak işaretlenebilir.
Yatay bölümleme hakkında daha fazla bilgi için bkz . Parçalama düzeni.
Dikey bölümleme
Dikey bölümleme için en yaygın kullanım, sık erişilen öğeleri getirmeyle ilişkili G/Ç ve performans maliyetlerini azaltmaktır. Şekil 2'de bir dikey bölümleme örneği gösterilir. Bu örnekte, bir öğenin farklı özellikleri farklı bölümlerde depolanır. Bir bölümde ürün adı, açıklama ve fiyat gibi daha sık erişilen veriler bulunur. Başka bir bölüm stok verilerini barındırır: hisse senedi sayısı ve son sipariş tarihi.
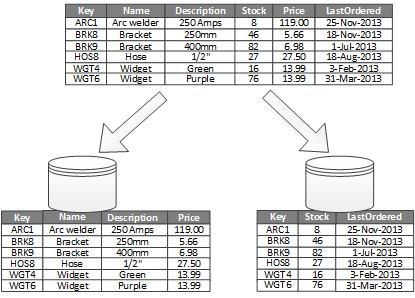
Şekil 2 - Verileri kullanım düzenine göre dikey olarak bölümleme.
Bu örnekte, uygulama müşterilere ürün ayrıntılarını görüntülerken düzenli olarak ürün adını, açıklamasını ve fiyatını sorgular. Bu iki öğe yaygın olarak birlikte kullanıldığından hisse senedi sayısı ve son sipariş tarihi ayrı bir bölümde tutulur.
Dikey bölümlemenin diğer avantajları:
Nispeten yavaş hareket eden veriler (ürün adı, açıklama ve fiyat) daha dinamik verilerden (hisse senedi düzeyi ve son sipariş tarihi) ayrılabilir. Yavaş taşınan veriler, bir uygulamanın bellekte önbelleğe almak için iyi bir adaydır.
Hassas veriler ek güvenlik denetimleriyle ayrı bir bölümde depolanabilir.
Dikey bölümleme, gereken eşzamanlı erişim miktarını azaltabilir.
Dikey bölümleme veri deposunda varlık düzeyinde çalışır; varlığı kısmen normalleştirerek bunu geniş bir öğeden bir dizi dar öğeye böler. İdeal olarak HBase ve Cassandra gibi sütun odaklı veri depolarına uygundur. Bir sütun koleksiyonundaki verilerin değişme olasılığı düşükse, SQL Server'daki sütun depolarını kullanmayı da göz önüne alabilirsiniz.
İşlevsel bölümleme
Bir uygulamadaki her ayrı iş alanı için sınırlanmış bağlamı tanımlamak mümkün olduğunda işlevsel bölümleme, yalıtım ve veri erişimi performansını geliştirmenin bir yoludur. İşlevsel bölümlemenin bir diğer yaygın kullanımı da, okuma-yazma verilerini salt okunur verilerden ayırmaktır. Şekil 3'te envanter verilerinin müşteri verilerinden ayrıldığı işlevsel bölümleme genel çizgileriyle gösterilir.
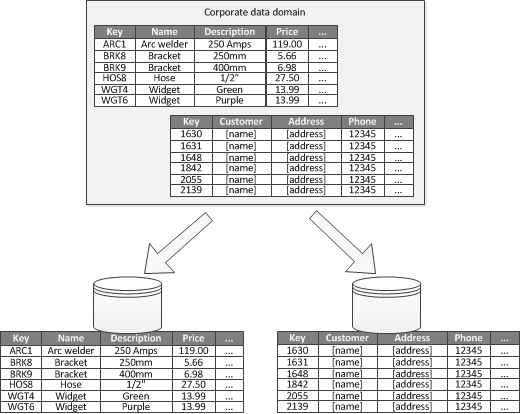
Şekil 3 - Verileri sınırlanmış bağlama veya alt etki alanına göre işlevsel olarak bölümleme.
Bu bölümleme stratejisi sistemin farklı parçaları arasında veri erişim çekişmesini azaltmaya yardımcı olur.
Bölümleri ölçeklenebilirlik için tasarlama
Her bölümün boyutunu ve iş yükünü göz önüne almak ve verilerin maksimum ölçeklenebilirlik sağlanacak şekilde dağıtılması için bunları dengelemek yaşamsal önem taşır. Öte yandan, verileri bölümlerken tek bir bölüm deposunun ölçeklendirme sınırlarını aşmamaya da dikkat etmelisiniz.
Bölümleri ölçeklenebilirlik için tasarlarken şu adımları izleyin:
- Veri erişim desenlerini, örneğin her sorgunun döndürdüğü yanıt kümesinin boyutunu, erişim sıklığını, doğal gecikme süresini ve sunucu tarafı işlem işleme gereksinimlerini anlamak için uygulamayı analiz edin. Birçok durumda, birkaç ana varlık işlem kaynaklarının büyük bölümünü talep edecektir.
- Bu analizi kullanarak güncel ve geleceğe dair ölçeklendirme hedeflerini (veri boyutu ve iş yükü gibi) saptayın. Ardından, ölçeklendirme hedefine uygun şekilde verileri bölümler arasında dağıtın. Yatay bölümleme için doğru parça anahtarının seçilmesi, dağıtımın eşit olduğundan emin olmak için önemlidir. Daha fazla bilgi için bkz . parçalama düzeni.
- Her bölümde, veri boyutu ve aktarım hızı açısından ölçeklenebilirlik gereksinimlerini işlemek için yeterli kaynak olduğundan emin olun. Veri deposuna bağlı olarak, bölüm başına depolama alanı, işlem gücü veya ağ bant genişliği miktarında bir sınır olabilir. Gereksinimlerin bu sınırları aşma olasılığı varsa, iki veya daha fazla stratejiyi birleştirerek bölümleme stratejinizi geliştirmeniz veya verileri daha fazla bölmeniz gerekebilir.
- Verilerin beklendiği gibi dağıtıldığını ve bölümlerin yükü işleyebildiğini doğrulamak için sistemi izleyin. Gerçek kullanım her zaman bir analizin tahminleriyle eşleşmez. Bu durumda, bölümleri yeniden dengelemek veya gerekli dengeyi elde etmek için sistemin bazı bölümlerini yeniden tasarlamak mümkün olabilir.
Bazı bulut ortamları altyapı sınırları açısından kaynak ayırır. Seçtiğiniz sınırların, veri depolama alanı, işlem gücü ve bant genişliği açısından veri hacmindeki beklenen artışla başa çıkabilecek kadar yer sağladığından emin olun.
Örneğin, Azure tablo depolaması kullanıyorsanız, belirli bir süre içinde tek bir bölüm tarafından işlenebilen istek hacminin bir sınırı vardır. (Daha fazla bilgi için bkz. Azure depolama ölçeklenebilirliği ve performans hedefleri.) Meşgul bir parça, tek bir bölümün işleyebileceğinden daha fazla kaynak gerektirebilir. Öyleyse, yükü yaymak için parçanın yeniden bölümlenmesi gerekebilir. Bu tabloların toplam boyutu veya aktarım hızı bir depolama hesabının kapasitesini aşıyorsa, ek depolama hesapları oluşturmanız ve tabloları bu hesaplara yaymanız gerekebilir.
Bölümleri sorgu performansı için tasarlama
Çoğunlukla daha küçük veri kümeleri kullanılarak ve paralel sorgular çalıştırılarak sorgu performansı artırılabilir. Her bölüm, veri kümesinin tamamının küçük bir kısmını içermelidir. Hacmin böyle azaltılması sorguların performansını geliştirebilir. Bununla birlikte bölümleme, veritabanını düzgün bir şekilde tasarlama ve yapılandırmanın alternatifi değildir. Örneğin, gerekli dizinlerin hazır olduğundan emin olun.
Bölümleri sorgu performansı için tasarlarken şu adımları izleyin:
Uygulama gereksinimlerini ve performansını inceleyin:
- Her zaman hızlı bir şekilde gerçekleştirmesi gereken kritik sorguları belirlemek için iş gereksinimlerini kullanın.
- Yavaş çalışan sorguları belirlemek için sistemi izleyin.
- Hangi sorguların en sık gerçekleştirildiğini bulun. Tek bir sorgunun maliyeti en düşük olsa bile, kümülatif kaynak tüketimi önemli olabilir.
Düşük performansa neden olan verileri bölümleyin:
- Sorgu yanıt süresinin hedefin dışına çıkmaması için her bölümün boyutunu sınırlandırın.
- Yatay bölümleme kullanıyorsanız, uygulamanın doğru bölümü kolayca seçebilmesi için parça anahtarını tasarlayabilirsiniz. Bu, sorgunun her bölümü taramak zorunda kalmasını önler.
- Bölümün konumu üzerinde düşünün. Mümkünse, verileri coğrafi olarak bunlara erişen uygulamaların ve kullanıcıların yakınındaki bölümlerde tutun.
Bir varlığın aktarım hızı ve sorgu performansı gereksinimleri varsa, o varlığı temel alarak işlevsel bölümleme kullanın. Bu yaklaşım da gereksinimleri karşılamaya yetmezse, aynı zamanda yatay bölümleme de uygulayın. Çoğu durumda tek bir bölümleme stratejisi yeterli olur, ancak bazı durumlarda her iki stratejiyi de birleştirmek daha verimlidir.
Performansı artırmak için sorguları bölümler arasında paralel olarak çalıştırmayı göz önünde bulundurun.
Bölümleri kullanılabilirlik için tasarlama
Verileri bölümlemek, veri kümesinin tamamının tek bir hata noktası oluşturmamasını ve veri kümesindeki tek tek alt kümelerin bağımsız olarak yönetilebilmesini sağladığından uygulamaların kullanılabilirliğini geliştirebilir.
Kullanılabilirliği etkileyen aşağıdaki faktörleri göz önünde bulundurun:
Veriler işle ilgili işlemler açısından ne derece kritik. hangi verilerin işlemler gibi kritik iş bilgileri olduğunu ve günlük dosyaları gibi hangi verilerin daha az kritik işlem verileri olduğunu belirleyin.
Kritik verileri uygun bir yedekleme planıyla yüksek oranda kullanılabilir bölümlerde depolamayı göz önünde bulundurun.
Farklı veri kümeleri için ayrı yönetim ve izleme yordamları oluşturun.
Kritiklik düzeyi aynı olan verileri aynı bölüme yerleştirerek, birlikte uygun bir sıklıkta yedeklenebilmelerini sağlayın. Örneğin, işlem verilerini tutan bölümlerin, günlüğe kaydetme veya izleme bilgilerini tutan bölümlerden daha sık yedeklenmeleri gerekebilir.
Tek tek bölümler nasıl yönetilebilir. Bağımsız yönetim ve bakımı destekleyen bölümler tasarlamanın çeşitli avantajları vardır. Örneğin:
Bir bölüm başarısız olursa, diğer bölümlerdeki verilere erişen uygulamalar olmadan bağımsız olarak kurtarılabilir.
Verilerin coğrafi alana göre bölümlenmesi, zamanlanmış bakım görevlerinin her konumda yoğun olmayan saatlerde gerçekleştirilmesine olanak tanır. Bu süre boyunca planlı bakımın tamamlanmasını önlemek için bölümlerin çok büyük olmadığından emin olun.
Kritik verilerin bölümler arasında çoğaltılıp çoğaltılmayacağı. Bu strateji kullanılabilirliği ve performansı geliştirebilir, ancak tutarlılık sorunlarına da neden olabilir. Değişiklikleri her çoğaltmayla eşitlemek zaman alır. Bu süre boyunca, farklı bölümler farklı veri değerleri içeriyor olacaktır.
Uygulama tasarımında dikkat edilmesi gerekenler
Bölümleme, sisteminizin tasarımına ve geliştirilmesine karmaşıklık ekler. Sistem başlangıçta tek bir bölüm içeriyor olsa bile bölümlemeyi sistem tasarımının temel parçalarından biri olarak düşünün. Bölümleme işlemini bir sonradan ele alırsanız, bakım yapılacak canlı bir sisteminiz olduğundan bu daha zor olacaktır:
- Veri erişim mantığının değiştirilmesi gerekir.
- Mevcut verilerin bölümler arasında dağıtılması için büyük miktarlardaki verilerin geçirilmesi gerekebilir.
- Kullanıcılar geçiş sırasında sistemi kullanmaya devam edebilmeyi bekler.
Bazı durumlarda bölümlemenin önemli olduğu düşünülmez çünkü başlangıçtaki veri kümesi küçüktür ve tek sunucu tarafından kolayca işlenebilir. Bu, bazı iş yükleri için geçerli olabilir, ancak kullanıcı sayısı arttıkça birçok ticari sistemin genişletilmesi gerekir.
Ayrıca, bölümlemeden yararlanan yalnızca büyük veri depoları değildir. Örneğin, küçük bir veri deposuna yüzlerce eş zamanlı istemci yoğun olarak erişiyor olabilir. Bu durumda verilerin bölümlenmesi çekişmeyi azaltıp aktarım hızını geliştirmeye yardımcı olabilir.
Veri bölümleme düzeni tasarlarken aşağıdaki noktaları göz önünde bulundurun:
Bölümler arası veri erişim işlemlerini en aza indirin. Mümkün olduğunda, her bölümde en yaygın veritabanı işlemlerinin verilerini bir arada tutarak bölümler arası veri erişim işlemlerini en aza indirin. Bölümler arasında sorgulama, tek bir bölüm içinde sorgulamaktan daha fazla zaman alabilir, ancak bir sorgu kümesi için bölümleri iyileştirmek diğer sorgu kümelerini olumsuz etkileyebilir. Bölümler arasında sorgulamanız gerekiyorsa paralel sorgular çalıştırarak ve sonuçları uygulama içinde toplayarak sorgu süresini en aza indirin. (Bu yaklaşım, bir sorgunun sonucu bir sonraki sorguda kullanıldığında olduğu gibi bazı durumlarda mümkün olmayabilir.)
Statik başvuru verilerini çoğaltmayı göz önünde bulundurun. Sorgular posta kodu tabloları veya ürün listeleri gibi nispeten statik başvuru verileri kullanıyorsa, farklı bölümlerdeki ayrı arama işlemlerini azaltmak için bu verileri tüm bölümlere çoğaltmayı göz önünde bulundurun. Bu yaklaşım, başvuru verilerinin sistemin tamamından gelen yoğun trafikle "sık erişimli" bir veri kümesi olma olasılığını da azaltabilir. Ancak, başvuru verisinde yapılan değişiklikleri eşitlemeyle ilişkili ek bir maliyet vardır.
Bölümler arası birleştirmeleri en aza indirin. Mümkünse, dikey ve işlevsel bölümler arasında başvurusal bütünlük gereksinimlerini en alt düzeyde tutun. Bu şemalarda uygulama, bölümler arasında bilgi tutarlılığını korumakla sorumludur. Birden çok bölüm arasında verileri birleştiren sorgular verimsizdir çünkü uygulamanın genellikle bir anahtara ve ardından bir yabancı anahtara göre ardışık sorgular gerçekleştirmesi gerekir. Bunun yerine, ilgili verileri çoğaltmayı veya normalleştirmelerini kaldırmayı göz önünde bulundurun. Bölümler arası birleştirmeler gerekiyorsa, bölümler üzerinde paralel sorgular çalıştırın ve verileri uygulama içinde birleştirin.
Nihai tutarlılık yaklaşımını benimseyin. Aslında güçlü bir tutarlılığın gerekip gerekmediğini değerlendirin. Dağıtılmış sistemlerde yaygın bir yaklaşım, nihai tutarlılığı uygulamaktır. Her bölümdeki veriler ayrı güncelleştirilir ve uygulama mantığı tüm güncelleştirmelerin başarıyla tamamlanmasını güvence altına alır. Ayrıca, son tutarlılık işlemi çalıştırılırken sorgu verilerinde ortaya çıkabilecek tutarsızlıkları da giderir.
Sorguların doğru bölümü nasıl bulduğunu göz önünde bulundurun. Sorgunun gerekli verileri bulmak için tüm bölümleri taraması gerekirse, birden çok paralel sorgu çalıştırılıyor olsa bile performansı önemli ölçüde etkiler. Dikey ve işlevsel bölümleme ile sorgular doğal olarak bölümü belirtebilir. Öte yandan, her parça aynı şemaya sahip olduğundan yatay bölümleme bir öğeyi bulma işlemini zorlaştırabilir. Belirli öğeler için parça konumunu aramak için kullanılan bir haritayı korumak için tipik bir çözümdür. Bu harita uygulamanın parçalama mantığında oluşturulabilir veya saydam parçalamayı destekliyorsa veri deposu tarafından tutulabilir.
Parçaları düzenli aralıklarla yeniden dengelemeyi göz önünde bulundurun. Yatay bölümleme ile parçaların yeniden dengelenmesi, etkin noktaları en aza indirmek, sorgu performansını en üst düzeye çıkarmak ve fiziksel depolama sınırlamalarına geçici bir çözüm bulmak için verileri boyuta ve iş yüküne göre eşit bir şekilde dağıtmaya yardımcı olabilir. Bununla birlikte, bu özel bir araç veya işlemin kullanılmasını gerektiren karmaşık bir görevdir.
Bölümleri çoğaltma. Her bölümü çoğaltırsanız, hataya karşı ek koruma sağlanır. Tek bir çoğaltma başarısız olursa, sorgular çalışan bir kopyaya yönlendirilebilir.
Bölümleme stratejisinin fiziksel sınırlarına ulaşırsanız, ölçeklenebilirliği farklı bir düzeye genişletmeniz gerekebilir. Örneğin bölümleme veritabanı düzeyinde yapılıyorsa, bölümleri birden çok veritabanına yerleştirmeniz veya çoğaltmanız gerekebilir. Bölümleme zaten veritabanı düzeyindeyse ve fiziksel sınırlamalar sorun yaratıyorsa, bu durum bölümleri birden çok barındırma hesabına yerleştirmeniz veya çoğaltmanız gerektiği anlamına gelebilir.
Birden çok bölümdeki verilere erişen işlemlerden kaçının. Bazı veri depoları verilerde değişiklik yapan işlemler için işlem tutarlılığı ve bütünlüğünü gerçekleştirir ama bunun için verilerin tek bir bölümde yer alıyor olması gerekir. Birden çok bölümde işlem desteğine ihtiyacınız varsa, büyük olasılıkla bunu uygulama mantığınızın bir parçası olarak gerçekleştirmeniz gerekir çünkü bölümleme sistemlerinin çoğu yerel destek sağlamaz.
Tüm veri depoları bazı işletimsel yönetim ve izleme etkinlikleri gerektirir. Görevler arasında verileri yükleme, veri yedekleme ve geri yükleme, verileri yeniden düzenleme ve sistemin doğru ve verimli çalıştığından emin olma sayılabilir.
İşletimsel yönetimi etkileyen aşağıdaki faktörleri göz önünde bulundurun:
Veriler bölümlendiğinde uygun yönetim ve işletim görevleri nasıl gerçekleştirilir. Bu görevler yedekleme ve geri yüklemeyi, verileri arşivlemeyi, sistemi izlemeyi ve diğer yönetim görevlerini içerebilir. Örneğin, yedekleme ve geri yükleme işlemleri sırasında mantıksal tutarlılığı korumak zor olabilir.
Birden çok bölümdeki veriler nasıl yüklenir ve başka kaynaklardan gelen yeni veriler nasıl eklenir. Bazı araçlar ve yardımcı programlar verileri doğru bölüme yükleme gibi parçalanmış veri işlemlerini desteklemiyor olabilir.
Veriler nasıl düzenli aralıklarla arşivlenir ve silinir. Bölümlerin aşırı büyümesini önlemek için verileri düzenli aralıklarla (örneğin, aylık) arşivlemeniz ve silmeniz gerekir. Farklı bir arşiv şemasıyla eşleşmesi için verileri dönüştürmeniz gerekebilir.
Veri bütünlüğü sorunları nasıl bulunur. Bir bölümdeki veriler gibi başka bir bölümdeki eksik bilgilere başvuran veriler gibi veri bütünlüğü sorunlarını bulmak için düzenli bir işlem çalıştırmayı göz önünde bulundurun. İşlem, bu sorunları otomatik olarak düzeltmeyi veya el ile gözden geçirme için bir rapor oluşturmayı deneyebilir.
Bölümleri yeniden dengeleme
Sistem olgunlaştıkça bölümleme düzenini ayarlamanız gerekebilir. Örneğin, tek tek bölümler orantısız bir trafik hacmi almaya başlayabilir ve sık erişimli hale gelir ve aşırı çekişmeye yol açar. Veya bazı bölümlerdeki veri hacmini hafife almış ve bazı bölümlerin kapasite sınırlarına yaklaşmasına neden olmuş olabilirsiniz.
Azure Cosmos DB gibi bazı veri depoları bölümleri otomatik olarak yeniden dengeleyebilir. Diğer durumlarda, yeniden dengeleme iki aşamadan oluşan bir yönetim görevidir:
Yeni bir bölümleme stratejisi belirleyin.
- Hangi bölümlerin bölünmesi (veya birleştirilmesi) gerekir?
- Yeni bölüm anahtarı nedir?
Verileri eski bölümleme düzeninden yeni bölüm kümesine geçirin.
Veri deposuna bağlı olarak, kullanımda olan bölümler arasında veri geçirebilirsiniz. Buna çevrimiçi geçiş denir. Bu mümkün değilse, veriler yeniden konumlandırılırken (çevrimdışı geçiş) bölümleri kullanılamaz duruma getirmeniz gerekebilir.
Çevrimdışı geçiş
Çevrimdışı geçiş genellikle daha basittir çünkü çekişme oluşma olasılığını azaltır. Kavramsal olarak, çevrimdışı geçiş aşağıdaki gibi çalışır:
- Bölümü çevrimdışı olarak işaretleyin.
- Bölme-birleştirme ve verileri yeni bölümlere taşıma.
- Verify the data.
- Yeni bölümleri çevrimiçine getirin.
- Eski bölümü kaldırın.
İsteğe bağlı olarak, 1. adımda bir bölümü salt okunur olarak işaretleyebilir, böylece uygulamalar taşınırken verileri okumaya devam edebilir.
Çevrimiçi geçiş
Çevrimiçi geçişin gerçekleştirilmesi daha karmaşıktır ancak daha az kesintiye neden olur. özgün bölümün çevrimdışı olarak işaretlenmemesi dışında işlem çevrimdışı geçişe benzer. Geçiş işleminin ayrıntı düzeyine bağlı olarak (örneğin, öğeye göre öğeye ve parçaya göre parçaya göre), istemci uygulamalarındaki veri erişim kodunun özgün bölüm ve yeni bölüm olmak üzere iki konumda tutulan verileri okuma ve yazma işlemlerini işlemesi gerekebilir.
Sonraki adımlar
- Belirli Azure hizmetleri için bölümleme stratejileri hakkında bilgi edinin. Daha fazla bilgi için bkz . Veri bölümleme stratejileri.
- Azure depolama ölçeklenebilirliği ve performans hedefleri
İlgili kaynaklar
Aşağıdaki tasarım desenleri senaryonuzla ilgili olabilir:
Parçalama düzeni , verileri parçalamayla ilgili bazı yaygın stratejileri açıklar.
Dizin tablosu düzeni , veriler üzerinde ikincil dizinlerin nasıl oluşturulacağını gösterir. Uygulama bu yaklaşımla, koleksiyonun birincil anahtarına başvurmayan sorgular kullanarak verileri hızla alabilir.
Gerçekleştirilmiş görünüm deseni , hızlı sorgu işlemlerini desteklemek için verileri özetleyen önceden doldurulmuş görünümlerin nasıl oluşturulacağı açıklanır. Özetlenen verileri içeren bölümler birden çok siteye dağıtılmışsa bu yaklaşım bölümlenmiş bir veri deposunda kullanışlı olabilir.