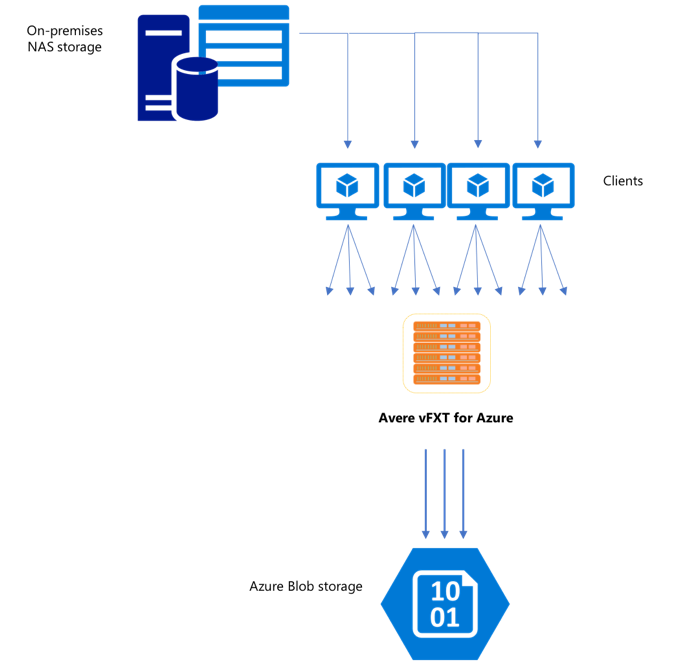
Yeni bir vFXT kümesi oluşturduktan sonra ilk göreviniz verileri Azure'da yeni bir depolama birimine taşımak olabilir. Ancak, verileri taşımayla ilgili olağan yönteminiz tek bir istemciden basit bir kopyalama komutu verirse, büyük olasılıkla yavaş kopyalama performansı görürsünüz. Tek iş parçacıklı kopyalama, Avere vFXT kümesinin arka uç depolama alanına veri kopyalamak için iyi bir seçenek değildir.
Azure kümesi için Avere vFXT ölçeklenebilir bir çok istemcili önbellek olduğundan, bu kümeye veri kopyalamanın en hızlı ve en verimli yolu birden çok istemcidir. Bu teknik, dosyaların ve nesnelerin alımını paralelleştirir.
Bir cp depolama sisteminden diğerine veri aktarmak için yaygın olarak kullanılan veya copy komutları, tek seferde yalnızca bir dosyayı kopyalayan tek iş parçacıklı işlemlerdir. Bu, dosya sunucusunun aynı anda yalnızca bir dosya aldığı anlamına gelir ve bu da kümenin kaynaklarının boşa harcandığı anlamına gelir.
Bu makalede, verileri Avere vFXT kümesine taşımak için çok istemcili, çok iş parçacıklı dosya kopyalama sistemi oluşturma stratejileri açıklanmaktadır. Birden çok istemci ve basit kopyalama komutları kullanılarak verimli veri kopyalama için kullanılabilecek dosya aktarımı kavramlarını ve karar noktalarını açıklar.
Ayrıca yardımcı olabilecek bazı yardımcı programlar da açıklanmaktadır. yardımcı msrsync programı, bir veri kümesini demetlere bölme ve komutları kullanma rsync işlemini kısmen otomatikleştirmek için kullanılabilir. Betik parallelcp , kaynak dizini okuyan ve kopyalama komutlarını otomatik olarak veren başka bir yardımcı programdır. Ayrıca araç, rsync veri tutarlılığı sağlayan daha hızlı bir kopya sağlamak için iki aşamada kullanılabilir.
Bu makalede bahsedilen paralel veri alımı araçlarıyla otomatik olarak vm oluşturmak için GitHub'da bir Resource Manager şablonu sağlanır.
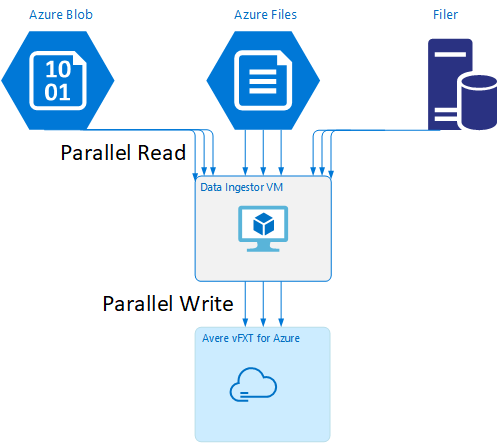
Veri alma sanal makinesi, yeni oluşturulan VM'nin Avere vFXT kümesini bağladığı ve bootstrap betiğini kümeden indirdiği bir öğreticinin parçasıdır. Ayrıntılar için Bootstrap a data ingestor VM bölümünü okuyun.
Stratejik planlama
Verileri paralel olarak kopyalamak için bir strateji tasarlarken, dosya boyutu, dosya sayısı ve dizin derinliğindeki dengeleri anlamanız gerekir.
Dosyalar küçük olduğunda, ilgilendiğin ölçüm saniyedeki dosyalardır.
Dosyalar büyük olduğunda (10MiBi veya üzeri), ilgi alanı ölçümü saniye başına bayttır.
Her kopyalama işleminin bir aktarım hızı ve dosya aktarım hızı vardır. Bu hız kopyalama komutunun uzunluğunu zamanlayarak ve dosya boyutu ile dosya sayısını ekleyerek ölçülebilir. Oranların nasıl ölçüldiğinin açıklanması bu belgenin kapsamı dışındadır, ancak küçük veya büyük dosyalarla ilgilenip ilgilenmeyeceksiniz anlamak önemlidir.
El ile kopyalama örneği
Önceden tanımlanmış dosya veya yol kümelerine karşı arka planda aynı anda birden fazla kopyalama komutu çalıştırarak istemcide el ile çok iş parçacıklı bir kopya oluşturabilirsiniz.
Linux/UNIX cp komutu sahipliği ve mtime meta verilerini korumak için bağımsız değişkenini -p içerir. Bu bağımsız değişkeni aşağıdaki komutlara eklemek isteğe bağlıdır. (Bağımsız değişkeninin eklenmesi, meta veri değişikliği için istemciden hedef dosya sistemine gönderilen dosya sistemi çağrılarının sayısını artırır.)
Bu basit örnek, iki dosyayı paralel olarak kopyalar:
Bu komutu verdikten sonra, jobs komut iki iş parçacığının çalıştığını gösterir.
Tahmin edilebilir dosya adı yapısı
Dosya adlarınız tahmin edilebilirse, paralel kopya iş parçacıkları oluşturmak için ifadeleri kullanabilirsiniz.
Örneğin, dizininiz 'den 00011000öğesine sıralı olarak numaralandırılmış 1000 dosya içeriyorsa, her birinin 100 dosyayı kopyalayan on paralel iş parçacığı oluşturmak için aşağıdaki ifadeleri kullanabilirsiniz:
Dosyalar toplandıktan sonra, alt dizinleri ve bunların tüm içeriklerini yinelemeli olarak kopyalamak için paralel kopyalama komutlarını çalıştırabilirsiniz:
Tek bir hedef dosya sistemi bağlama noktasına karşı yeterli paralel iş parçacığına sahip olduktan sonra, daha fazla iş parçacığı eklemenin daha fazla aktarım hızı sağlamadığı bir nokta olacaktır. (Aktarım hızı, veri türünüz bağlı olarak dosya/saniye veya bayt/saniye cinsinden ölçülür.) Daha da kötüsü, aşırı iş parçacığı kullanımı bazen aktarım hızının düşmesine neden olabilir.
Bu durumda, aynı uzak dosya sistemi bağlama yolunu kullanarak diğer vFXT kümesi IP adreslerine istemci tarafı bağlama noktaları ekleyebilirsiniz:
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
İstemci tarafı bağlama noktaları eklemek ek kopyalama komutlarını ek /mnt/destination[1-3] bağlama noktalarına çatallayarak daha fazla paralellik elde etmenizi sağlar.
Örneğin, dosyalarınız çok büyükse, kopyalama komutlarını farklı hedef yolları kullanacak şekilde tanımlayabilir ve kopyayı gerçekleştiren istemciden paralel olarak daha fazla komut gönderebilirsiniz.
Yukarıdaki örnekte, üç hedef bağlama noktasının tümü de istemci dosya kopyalama işlemleri tarafından hedeflenmektedir.
İstemciler ne zaman eklenir?
Son olarak, istemcinin özelliklerine ulaştığınızda, daha fazla kopya iş parçacığı veya ek bağlama noktası eklemek ek dosya/sn veya bayt/sn artışı sağlamaz. Bu durumda, kendi dosya kopyalama işlemi kümelerini çalıştıracak aynı bağlama noktaları kümesine sahip başka bir istemci dağıtabilirsiniz.
Yukarıdaki yaklaşımları (hedef başına birden çok kopya iş parçacığı, istemci başına birden çok hedef, ağ tarafından erişilebilen kaynak dosya sistemi başına birden çok istemci) anladıktan sonra şu öneriyi göz önünde bulundurun: Dosya bildirimleri oluşturun ve bunları birden çok istemci arasında kopyalama komutları ile kullanın.
Bu senaryo, dosya veya dizin bildirimlerini oluşturmak için UNIX find komutunu kullanır:
Son olarak, istemcilere gerçek dosya kopyalama komutlarını oluşturmanız gerekir.
Dört istemciniz varsa şu komutu kullanın:
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
Beş istemciniz varsa aşağıdaki gibi bir şey kullanın:
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
Ve altı için.... Gerektiğinde tahminde bulun.
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
Komut çıkışının find bir parçası olarak elde edilen dördüncü düzey dizinlerin yol adlarını içeren her N istemciniz için bir tane olmak üzere N sonuç dosyaları alırsınız.
Kopyalama komutunu oluşturmak için her dosyayı kullanın:
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
Yukarıdakiler, istemcide BASH betiği olarak çalıştırabileceğiniz, her birinin satır başına kopyalama komutuna sahip olan N dosyalarını verir.
Amaç, bu betiklerin birden çok iş parçacığını istemci başına eşzamanlı olarak birden çok istemcide paralel olarak çalıştırmaktır.
İki aşamalı rsync işlemi kullanma
Standart rsync yardımcı program, veri bütünlüğünü garanti etmek için çok sayıda dosya oluşturma ve yeniden adlandırma işlemi oluşturduğundan Azure için Avere vFXT sistemi aracılığıyla bulut depolamayı doldurmada iyi çalışmaz. Ancak, dosya bütünlüğünü denetleen ikinci bir çalıştırmayla bunu izlerseniz daha dikkatli kopyalama yordamını atlamak için ile rsync seçeneğini kullanabilirsiniz--inplace.
Standart rsync kopyalama işlemi geçici bir dosya oluşturur ve dosyayı verilerle doldurur. Veri aktarımı başarıyla tamamlanırsa, geçici dosya özgün dosya adıyla yeniden adlandırılır. Bu yöntem, kopyalama sırasında dosyalara erişiliyor olsa bile tutarlılığı garanti eder. Ancak bu yöntem, önbellekte dosya hareketini yavaşlatan daha fazla yazma işlemi oluşturur.
seçeneği --inplace , yeni dosyayı doğrudan son konumuna yazar. Aktarım sırasında dosyaların tutarlı olması garanti değildir, ancak daha sonra kullanmak üzere bir depolama sistemi hazırlarsanız bu önemli değildir.
İkinci rsync işlem, ilk işlemde tutarlılık denetimi görevi görür. Dosyalar zaten kopyalandığından, ikinci aşama, hedefte yer alan dosyaların kaynak dosyalarla eşleştiğinden emin olmak için hızlı bir taramadır. Eşleşmeyen dosyalar yeniden kapsamlandırılır.
Her iki aşamayı da tek bir komutla birlikte vekleyebilirsiniz:
Bu yöntem, iç dizin yöneticisinin işleyebileceği dosya sayısına kadar veri kümeleri için basit ve zaman etkili bir yöntemdir. (Bu genellikle 3 düğümlü küme için 200 milyon dosya, altı düğümlü küme için 500 milyon dosya vb.)
msrsync yardımcı programını kullanma
Araç, msrsync verileri Avere kümesi için bir arka uç çekirdek dosyalayıcısına taşımak için de kullanılabilir. Bu araç, birden çok paralel rsync işlem çalıştırarak bant genişliği kullanımını iyileştirmek için tasarlanmıştır. GitHub'dan https://github.com/jbd/msrsyncadresinden edinilebilir.
msrsync kaynak dizini ayrı "demetlere" ayırır ve ardından her demet üzerinde ayrı rsync işlemler çalıştırır.
Dört çekirdekli bir VM kullanılarak yapılan ön test, 64 işlem kullanılırken en iyi verimliliği gösterdi. msrsync İşlem sayısını 64 olarak ayarlamak için seçeneğini -p kullanın.
Bağımsız değişkenini --inplace komutlarla msrsync da kullanabilirsiniz. Bu seçeneği kullanırsanız, veri bütünlüğünü sağlamak için ikinci bir komut (yukarıda açıklanan rsync'de olduğu gibi) çalıştırmayı göz önünde bulundurun.
msrsync yalnızca yerel birimlere ve yerel birimlerden yazabilir. Kaynak ve hedefe kümenin sanal ağında yerel bağlamalar olarak erişilebilir olmalıdır.
msrsync Azure bulut birimini Avere kümesiyle doldurmak için şu yönergeleri izleyin:
Yükleme msrsync ve önkoşulları (rsync ve Python 2.6 veya üzeri)
Kopyalanacak toplam dosya ve dizin sayısını belirleyin.
Betik, parallelcp vFXT kümenizin arka uç depolama alanına veri taşımak için de yararlı olabilir.
Aşağıdaki betik yürütülebilir dosyasını parallelcpekler. (Bu betik Ubuntu için tasarlanmıştır; başka bir dağıtım kullanıyorsanız ayrı olarak yüklemeniz parallel gerekir.)
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
Paralel kopyalama örneği
Bu örnek, Avere kümesindeki kaynak dosyaları kullanarak derlemek glibc için paralel kopya betiğini kullanır.
Kaynak dosyalar Avere kümesi bağlama noktasında depolanır ve nesne dosyaları yerel sabit sürücüde depolanır.
Bu betik yukarıdaki paralel kopya betiğini kullanır. seçeneği -j ve ile parallelcp birlikte kullanılır ve make paralelleştirme elde etmek için kullanılır.
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j
Azure HPC, en iyi uygulama performansı, ölçeklenebilirlik ve değer sunmak için önde gelen işlemcileri ve HPC sınıfı InfiniBand ara bağlantısını kullanan HPC ve AI iş yükü için amaca yönelik bir bulut özelliğidir. Azure HPC, iş ve teknik gereksinimleriniz değiştikçe dinamik olarak ayrılabilen yüksek oranda kullanılabilir hpc ve yapay zeka teknolojileri aracılığıyla kullanıcıların yenilik, üretkenlik ve iş çevikliğini ortaya çıkarmalarını sağlar. Bu öğrenme yolu, Azure HPC'yi kullanmaya başlamanıza yardımcı o