Azure SQL Veritabanı’nda uygulamaları ve veritabanlarını performans için ayarlama
Şunlar için geçerlidir:![]() Azure SQL Veritabanı
Azure SQL Veritabanı
Azure SQL Veritabanı ile karşılaştığınız bir performans sorunu belirledikten sonra, bu makale size yardımcı olmak için tasarlanmıştır:
- Uygulamanızı ayarlayın ve performansı geliştirebilecek en iyi yöntemleri uygulayın.
- Verilerle daha verimli çalışmak için dizinleri ve sorguları değiştirerek veritabanını ayarlayın.
Bu makalede, Azure SQL Veritabanı veritabanı danışmanı önerileri ve varsa otomatik ayarlama önerileriyle zaten çalıştığınızı varsayar. Ayrıca izleme ve ayarlamaya genel bakış, Sorgu Deposu kullanarak performansı izleme ve performans sorunlarını gidermeyle ilgili ilgili makaleleri gözden geçirmiş olduğunuz varsayılır. Ayrıca bu makalede, veritabanınıza daha fazla kaynak sağlamak için işlem boyutu veya hizmet katmanı artırılarak çözülebilecek CPU kaynağı kullanımıyla ilgili bir performans sorununuz olmadığı varsayılır.
Not
Azure SQL Yönetilen Örneği'da benzer yönergeler için bkz. Azure SQL Yönetilen Örneği performansı için uygulamaları ve veritabanlarını ayarlama.
Uygulamanızı ayarlama
Geleneksel şirket içi SQL Server'da, ilk kapasite planlaması işlemi genellikle bir uygulamayı üretimde çalıştırma işleminden ayrılır. Önce donanım ve ürün lisansları satın alınır ve daha sonra performans ayarlaması yapılır. Azure SQL'i kullandığınızda, bir uygulamayı çalıştırma ve ayarlama sürecini birbirine eklemek iyi bir fikirdir. İsteğe bağlı kapasite için ödeme yapma modeliyle, genellikle yanlış olan bir uygulama için gelecekteki büyüme planlarının tahminlerine göre donanıma aşırı sağlama yapmak yerine uygulamanızı şu anda gereken en düşük kaynakları kullanacak şekilde ayarlayabilirsiniz.
Bazı müşteriler bir uygulamayı ayarlamamayı tercih edebilir ve bunun yerine donanım kaynaklarını aşırı sağlamayı seçebilir. Yoğun bir dönemde önemli bir uygulamayı değiştirmek istemiyorsanız bu yaklaşım iyi bir fikir olabilir. Ancak, bir uygulamanın ayarlanması kaynak gereksinimlerini en aza indirip aylık faturaları düşürebilir.
Azure SQL Veritabanı için uygulama tasarımında en iyi yöntemler ve kötü model
Azure SQL Veritabanı hizmet katmanları bir uygulama için performans kararlılığını ve öngörülebilirliği geliştirmek üzere tasarlanmış olsa da, bazı en iyi yöntemler uygulamanızı işlem boyutundaki kaynaklardan daha iyi yararlanacak şekilde ayarlamanıza yardımcı olabilir. Birçok uygulamanın yalnızca daha yüksek bir işlem boyutuna veya hizmet katmanına geçerek önemli performans kazanımları olsa da, bazı uygulamaların daha yüksek bir hizmet düzeyinden yararlanmak için ek ayarlamaya ihtiyacı vardır. Daha yüksek performans için, şu özelliklere sahip uygulamalar için ek uygulama ayarlamayı göz önünde bulundurun:
"Sohbet" davranışı nedeniyle performansı yavaş olan uygulamalar
Gevendekli uygulamalar, ağ gecikme süresine duyarlı aşırı veri erişimi işlemleri yapar. Veritabanına yönelik veri erişim işlemlerinin sayısını azaltmak için bu tür uygulamaları değiştirmeniz gerekebilir. Örneğin, geçici sorguları toplu işleme veya sorguları saklı yordamlara taşıma gibi teknikleri kullanarak uygulama performansını geliştirebilirsiniz. Daha fazla bilgi için bkz . Batch sorguları.
Tek bir makinenin tamamı tarafından desteklenemiyor yoğun iş yüküne sahip veritabanları
En yüksek Premium işlem boyutundaki kaynakları aşan veritabanları, iş yükünün ölçeğini genişletmenin avantajlarından yararlanabilir. Daha fazla bilgi için bkz . Veritabanları arası parçalama ve İşlevsel bölümleme.
En iyi olmayan sorguları olan uygulamalar
Zayıf ayarlanmış sorguları olan uygulamalar daha yüksek işlem boyutundan yararlanamayabilir. Bu, WHERE yan tümcesi olmayan, eksik dizinleri olan veya eski istatistikleri olan sorguları içerir. Bu uygulamalar standart sorgu performansı ayarlama tekniklerinden yararlanıyor. Daha fazla bilgi için bkz . Eksik dizinler ve Sorgu ayarlama ve ipuçları.
En iyi olmayan veri erişimi tasarımına sahip uygulamalar
Veri erişimi eşzamanlılık sorunları olan uygulamalar (örneğin kilitlenme) daha yüksek işlem boyutundan yararlanamayabilir. Azure Önbelleğe Alma hizmeti veya başka bir önbelleğe alma teknolojisiyle verileri istemci tarafında önbelleğe alarak veritabanına yönelik gidiş dönüşleri azaltmayı göz önünde bulundurun. Bkz. Uygulama katmanı önbelleğe alma.
Azure SQL Veritabanı'da kilitlenmelerin yeniden oluşmasını önlemek için bkz. Azure SQL Veritabanı'de kilitlenmeleri analiz etme ve önleme.
Veritabanınızı ayarlama
Bu bölümde, uygulamanız için en iyi performansı elde etmek ve mümkün olan en düşük işlem boyutunda çalıştırmak üzere veritabanını ayarlamak için kullanabileceğiniz bazı tekniklere göz atacağız. Bu tekniklerden bazıları geleneksel SQL Server ayarlama en iyi yöntemleriyle eşleşir, ancak diğerleri Azure SQL Veritabanı özeldir. Bazı durumlarda, Azure SQL Veritabanı'de çalışmak üzere geleneksel SQL Server tekniklerini daha fazla ayarlayıp genişletecek alanları bulmak için veritabanı için kullanılan kaynakları inceleyebilirsiniz.
Eksik dizinleri belirleme ve ekleme
OLTP veritabanı performansındaki yaygın bir sorun, fiziksel veritabanı tasarımıyla ilgilidir. Veritabanı şemaları genellikle büyük ölçekte test edilmeden (yük veya veri hacminde) tasarlanır ve gönderilir. Ne yazık ki, bir sorgu planının performansı küçük ölçekte kabul edilebilir ancak üretim düzeyindeki veri hacimleri altında önemli ölçüde düşebilir. Bu sorunun en yaygın kaynağı, bir sorgudaki filtreleri veya diğer kısıtlamaları karşılamak için uygun dizinlerin olmamasıdır. Çoğu zaman, dizin aramanın yeterli olabileceği durumlarda eksik dizinler tablo taraması olarak kendini gösterir.
Bu örnekte, bir arama yeterli olduğunda seçili sorgu planı tarama kullanır:
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
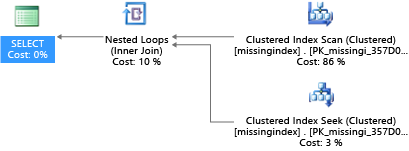
Azure SQL Veritabanı, sık karşılaşılan eksik dizin koşullarını bulmanıza ve düzeltmenize yardımcı olabilir. Azure SQL Veritabanı içinde yerleşik olan DMV'ler, bir dizinin sorgu çalıştırma tahmini maliyetini önemli ölçüde azaltacağı sorgu derlemelerine bakar. Sorgu yürütme sırasında, veritabanı altyapısı her sorgu planının ne sıklıkta yürütüldüğünü izler ve yürütülen sorgu planı ile bu dizinin bulunduğu hayal edilen plan arasındaki tahmini boşluğu izler. Bu DMV'leri, fiziksel veritabanı tasarımınızda yapılan değişikliklerin veritabanı ve gerçek iş yükü için genel iş yükü maliyetini artırabileceğini hızla tahmin etmek için kullanabilirsiniz.
Olası eksik dizinleri değerlendirmek için bu sorguyu kullanabilirsiniz:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
Bu örnekte sorgu şu öneriyle sonuçlandı:
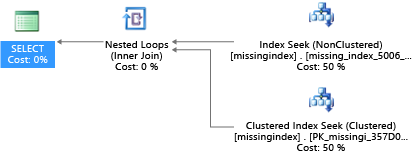
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
Oluşturulduktan sonra, aynı SELECT deyimi tarama yerine arama kullanan farklı bir plan seçer ve ardından planı daha verimli bir şekilde yürütür:
Temel içgörü, paylaşılan bir ticari sistemin GÇ kapasitesinin ayrılmış bir sunucu makinesinden daha sınırlı olmasıdır. Hizmet katmanlarının her işlem boyutundaki kaynaklarda sistemden en yüksek avantajı elde etmek için gereksiz GÇ'yi en aza indirmeye yönelik bir premium vardır. Uygun fiziksel veritabanı tasarım seçimleri tek tek sorgular için gecikme süresini önemli ölçüde artırabilir, ölçek birimi başına işlenen eşzamanlı isteklerin aktarım hızını artırabilir ve sorguyu karşılamak için gereken maliyetleri en aza indirir.
Eksik dizin isteklerini kullanarak dizinleri ayarlama hakkında daha fazla bilgi için bkz . Eksik dizin önerileriyle kümelenmemiş dizinleri ayarlama.
Sorgu ayarlama ve ipucu oluşturma
Azure SQL Veritabanı içindeki sorgu iyileştiricisi, geleneksel SQL Server sorgu iyileştiricisine benzer. Sorguları ayarlamaya ve sorgu iyileştiricisi için mantık modeli sınırlamalarını anlamaya yönelik en iyi yöntemlerin çoğu Azure SQL Veritabanı için de geçerlidir. sorguları Azure SQL Veritabanı ayarlarsanız, toplam kaynak taleplerini azaltmanın ek avantajını elde edebilirsiniz. Uygulamanız daha düşük bir işlem boyutunda çalışabildiğinden, daha düşük bir maliyetle, untuned eşdeğerinden daha düşük bir maliyetle çalışabilir.
SQL Server'da yaygın olan ve Azure SQL Veritabanı için de geçerli olan bir örnek, sorgu iyileştiricinin parametreleri nasıl "kokladığıdır." Derleme sırasında sorgu iyileştiricisi, daha uygun bir sorgu planı oluşturup oluşturamayacağını belirlemek için parametrenin geçerli değerini değerlendirir. Bu strateji genellikle bilinen parametre değerleri olmadan derlenen bir plandan önemli ölçüde daha hızlı bir sorgu planına yol açsa da, şu anda her iki Azure SQL Veritabanı de kusursuz bir şekilde çalışır. (SQL Server 2022 ile sunulan yeni bir Akıllı Sorgu Performansı özelliğiParametre Duyarlılık Planı İyileştirme, parametreli sorgu için tek bir önbelleğe alınmış planın tüm olası gelen parametre değerleri için en uygun olmadığı senaryoyu ele alır. Parametre Duyarlılığı Planı İyileştirmesi şu anda Azure SQL Veritabanı'da sağlanmamaktadır.)
Veritabanı altyapısı sorgu ipuçlarını (yönergeleri) destekler, böylece amacı daha bilinçli olarak belirtebilir ve parametre algılamanın varsayılan davranışını geçersiz kılabilirsiniz. Varsayılan davranış belirli bir iş yükü için kusurlu olduğunda ipuçlarını kullanmayı seçebilirsiniz.
Sonraki örnekte, sorgu işlemcisinin hem performans hem de kaynak gereksinimleri için en iyi olmayan bir planı nasıl oluşturabileceği gösterilmektedir. Bu örnekte, sorgu ipucu kullanırsanız veritabanınız için sorgu çalışma süresini ve kaynak gereksinimlerini azaltabileceğiniz de gösterilir:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
Kurulum kodu tabloda çarpık (veya düzensiz dağıtılmış) veriler t1 oluşturur. En uygun sorgu planı, hangi parametrenin seçildiğine göre farklılık gösterir. Ne yazık ki plan önbelleğe alma davranışı her zaman sorguyu en yaygın parametre değerine göre yeniden derlemez. Bu nedenle, farklı bir plan ortalamada daha iyi bir plan seçimi olsa bile, bir alt planın önbelleğe alınması ve birçok değer için kullanılması mümkündür. Ardından sorgu planı, birinin özel bir sorgu ipucuna sahip olması dışında, aynı olan iki saklı yordam oluşturur.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Sonuçların elde edilen telemetri verilerinde ayrı olması için, örneğin 2. bölümüne başlamadan önce en az 10 dakika beklemenizi öneririz.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Bu örneğin her bölümü, parametreli insert deyimini 1.000 kez çalıştırmayı dener (test veri kümesi olarak kullanmak için yeterli yük oluşturmak için). Saklı yordamları yürütürken, sorgu işlemcisi ilk derlemesi sırasında yordama geçirilen parametre değerini ("koklama" parametresi) inceler. İşlemci, sonuçta elde edilen planı önbelleğe alır ve parametre değeri farklı olsa bile daha sonraki çağrılar için kullanır. En uygun plan her durumda kullanılamayabilir. Bazen iyileştiriciye, sorgunun ilk derlendiği zamandaki belirli bir durum yerine ortalama servis talebi için daha iyi bir plan seçmesi için yol göstermeniz gerekir. Bu örnekte, ilk plan parametresiyle eşleşen her değeri bulmak için tüm satırları okuyan bir "tarama" planı oluşturur:

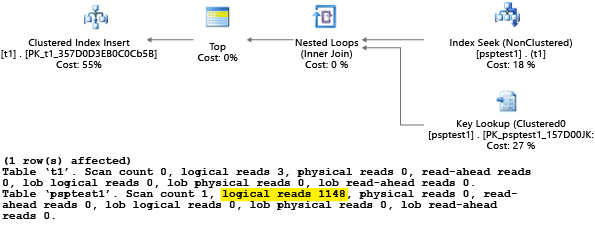
yordamını değerini 1kullanarak yürüttüğünden, sonuçta elde edilen plan değer 1 için en uygundu ancak tablodaki diğer tüm değerler için uygun değildi. Plan daha yavaş çalıştığından ve daha fazla kaynak kullandığından, her planı rastgele seçmeniz büyük olasılıkla istediğiniz sonuç değildir.
testi SET STATISTICS IO olarak ayarlanmış olarak ONçalıştırırsanız, bu örnekteki mantıksal tarama işi arka planda yapılır. Plan tarafından 1.148 okuma yapıldığını görebilirsiniz (ortalama bir satır döndürülecekse verimsizdir):

Örneğin ikinci bölümü, iyileştiriciye derleme işlemi sırasında belirli bir değeri kullanmasını bildirmek için bir sorgu ipucu kullanır. Bu durumda, sorgu işlemcisini parametresi olarak geçirilen değeri yoksaymaya ve bunun yerine varsaymaya UNKNOWNzorlar. Bu, tabloda ortalama sıklığı olan bir değere başvurur (dengesizliği yoksayma). Sonuçta elde edilen plan, bu örneğin 1. bölümündeki plandan daha hızlı olan ve ortalama olarak daha az kaynak kullanan bir arama tabanlı plandır:
Etkiyi, Azure SQL Veritabanı özgü olan sys.resource_stats sistem görünümünde görebilirsiniz. Testi yürütürken ve veriler tabloyu doldururken bir gecikme olur. Bu örnekte, bölüm 1 22:25:00 zaman penceresi sırasında, bölüm 2 ise 22:35:00'te yürütülür. Önceki zaman penceresinde bu zaman penceresinde daha sonrakine göre daha fazla kaynak kullanıldı (plan verimliliği geliştirmeleri nedeniyle).
SELECT TOP 1000 *
FROM sys.resource_stats
WHERE database_name = 'resource1'
ORDER BY start_time DESC

Not
Bu örnekteki birim kasıtlı olarak küçük olsa da, özellikle büyük veritabanlarında en iyi olmayan parametrelerin etkisi önemli olabilir. Aşırı durumlarda fark, hızlı vakalar için saniyeler ve yavaş vakalar için saatler arasında olabilir.
Test kaynağının başka bir testten daha fazla veya daha az kaynak kullanıp kullanmadığını belirlemek için inceleyebilirsiniz sys.resource_stats . Verileri karşılaştırdığınızda, testlerin zamanlamasını görünümde aynı 5 dakikalık pencerede sys.resource_stats olmayacak şekilde ayırın. Alıştırmanın amacı, kullanılan toplam kaynak miktarını en aza indirmek ve en yüksek kaynakları en aza indirmek değildir. Genellikle, bir kod parçasını gecikme süresi için en iyi duruma getirmek kaynak tüketimini de azaltır. Uygulamada yaptığınız değişikliklerin gerekli olduğundan ve değişikliklerin uygulamada sorgu ipuçlarını kullanabilecek biri için müşteri deneyimini olumsuz etkilemediğinden emin olun.
Bir iş yükünün yinelenen bir dizi sorgusu varsa, veritabanını barındırmak için gereken en düşük kaynak boyutu birimini yönlendirdiğinden, genellikle plan seçimlerinizin en iyi şekilde yakalanması ve doğrulanması mantıklıdır. Doğruladıktan sonra, zaman zaman bunların bozulmadığından emin olmanıza yardımcı olacak planları yeniden inceleyin. Sorgu ipuçları (Transact-SQL) hakkında daha fazla bilgi edinebilirsiniz.
Azure SQL Veritabanı'da çok büyük veritabanı mimarileri için en iyi yöntemler
Azure SQL Veritabanı'da tek veritabanları için Hiper Ölçek hizmet katmanı yayımlanmadan önce müşteriler tek tek veritabanları için kapasite sınırlarıyla karşılaşabilir. Hiper Ölçek elastik havuzları (önizleme) önemli ölçüde daha yüksek depolama sınırları sunsa da, diğer hizmet katmanlarındaki elastik havuzlar ve havuza alınan veritabanları yine de Hiper Ölçek dışı hizmet katmanlarında bu depolama kapasitesi sınırlarıyla kısıtlanabilir.
Aşağıdaki iki bölümde, Hiper Ölçek hizmet katmanını kullanamıyorsanız Azure SQL Veritabanı'daki çok büyük veritabanlarıyla ilgili sorunları çözmeye yönelik iki seçenek açıklanmıştır.
Not
Hiper ölçek elastik havuzları Azure SQL Veritabanı için önizleme aşamasındadır. Elastik havuzlar Azure SQL Yönetilen Örneği, şirket içi SQL Server örnekleri, Azure VM'lerinde SQL Server veya Azure Synapse Analytics için kullanılamaz.
Veritabanları arası parçalama
Azure SQL Veritabanı ticari donanım üzerinde çalıştığından, tek bir veritabanının kapasite sınırları geleneksel şirket içi SQL Server yüklemesinden daha düşüktür. Bazı müşteriler, işlemler Azure SQL Veritabanı'daki tek bir veritabanının sınırlarına sığmadığında veritabanı işlemlerini birden çok veritabanına yaymak için parçalama teknikleri kullanır. Azure SQL Veritabanı'de parçalama teknikleri kullanan müşterilerin çoğu verilerini tek bir boyuta birden çok veritabanına böler. Bu yaklaşım için OLTP uygulamalarının genellikle şemadaki tek bir satıra veya küçük bir satır grubuna uygulanan işlemler gerçekleştirdiğini anlamanız gerekir.
Not
Azure SQL Veritabanı artık parçalama konusunda yardımcı olacak bir kitaplık sağlar. Daha fazla bilgi için bkz . Elastik Veritabanı istemci kitaplığına genel bakış.
Örneğin, bir veritabanında müşteri adı, sipariş ve sipariş ayrıntıları varsa (veritabanında olduğu AdventureWorks gibi), bir müşteriyi ilgili sipariş ve sipariş ayrıntıları bilgileriyle gruplandırarak bu verileri birden çok veritabanına bölebilirsiniz. Müşterinin verilerinin tek bir veritabanında kalmasını garanti edebilirsiniz. Uygulama farklı müşterileri veritabanları arasında bölerek yükü birden çok veritabanına etkili bir şekilde yayar. Parçalama ile müşteriler veritabanı boyutu üst sınırından kaçınmakla kalmaz, Azure SQL Veritabanı her veritabanı kendi hizmet katmanı sınırlarına uyduğu sürece farklı işlem boyutlarının sınırlarından önemli ölçüde daha büyük iş yüklerini de işleyebilir.
Veritabanı parçalama, bir çözüm için toplam kaynak kapasitesini azaltmasa da, birden çok veritabanına yayılan çok büyük çözümleri desteklemede son derece etkilidir. Her veritabanı, yüksek kaynak gereksinimlerine sahip çok büyük ve "etkili" veritabanlarını desteklemek için farklı bir işlem boyutunda çalışabilir.
İşlevsel bölümleme
Kullanıcılar genellikle tek bir veritabanında birçok işlevi birleştirir. Örneğin, bir uygulamanın bir mağazanın envanterini yönetme mantığı varsa, bu veritabanının stok, satın alma siparişlerini izleme, saklı yordamlar ve ay sonu raporlamasını yöneten dizine alınmış veya gerçekleştirilmiş görünümlerle ilişkili mantığı olabilir. Bu teknik, yedekleme gibi işlemler için veritabanını yönetmeyi kolaylaştırır, ancak aynı zamanda bir uygulamanın tüm işlevlerinde en yüksek yükü işlemek için donanımı boyutlandırmanızı gerektirir.
Azure SQL Veritabanı ölçeği genişletme mimarisi kullanıyorsanız, bir uygulamanın farklı işlevlerini farklı veritabanlarına bölmek iyi bir fikirdir. Bu tekniği kullanırsanız, her uygulama bağımsız olarak ölçeklendirilir. Bir uygulama daha yoğun hale geldikçe (ve veritabanındaki yük arttıkça), yönetici uygulamadaki her işlev için bağımsız işlem boyutları seçebilir. Sınırda, bu mimaride yük birden çok makineye yayıldığı için bir uygulama tek bir ticari makinenin işleyebileceğinden daha büyük olabilir.
Batch sorguları
Yüksek hacimli, sık ve geçici sorgulama kullanarak verilere erişen uygulamalar için, uygulama katmanı ile veritabanı katmanı arasındaki ağ iletişimi için önemli miktarda yanıt süresi harcanıyor. Hem uygulama hem de veritabanı aynı veri merkezinde olsa bile, ikisi arasındaki ağ gecikmesi çok sayıda veri erişim işlemiyle büyütülebilir. Veri erişim işlemlerinin ağ gidiş dönüşlerini azaltmak için geçici sorguları toplu olarak işleme veya bunları saklı yordamlar olarak derleme seçeneğini kullanmayı göz önünde bulundurun. Geçici sorguları toplu olarak oluşturursanız, veritabanına tek bir yolculukta birden çok sorguyu tek bir büyük toplu iş olarak gönderebilirsiniz. Bir saklı yordamda geçici sorgular derlerseniz, bunları toplu işlediğiniz gibi aynı sonucu elde edebilirsiniz. Saklı yordam kullanmak, saklı yordamı yeniden kullanabilmeniz için sorgu planlarını veritabanında önbelleğe alma olasılığını artırma avantajını da sağlar.
Bazı uygulamalar yoğun yazma işlemi kullanır. Bazen birlikte yazma işlemlerini toplu olarak yapmayı göz önünde bulundurarak veritabanındaki toplam GÇ yükünü azaltabilirsiniz. Bu genellikle saklı yordamlarda ve geçici toplu işlemlerde otomatik işlem yerine açık işlemleri kullanmak kadar basittir. Kullanabileceğiniz farklı tekniklerin değerlendirilmesi için bkz . Azure'da veritabanı uygulamaları için toplu iş teknikleri. Toplu işlem için doğru modeli bulmak için kendi iş yükünüzle denemeler yapın. Modelin işlem tutarlılığı garantilerinin biraz farklı olabileceğini anladığınızdan emin olun. Kaynak kullanımını en aza indiren doğru iş yükünü bulmak için tutarlılık ve performans dengelerinin doğru birleşimini bulmak gerekir.
Uygulama katmanı önbelleğe alma
Bazı veritabanı uygulamalarının yoğun okuma içeren iş yükleri vardır. Önbelleğe Alma katmanlar veritabanındaki yükü azaltabilir ve Azure SQL Veritabanı kullanarak veritabanını desteklemek için gereken işlem boyutunu küçültebilir. Redis için Azure Cache ile yoğun okuma içeren bir iş yükünüz varsa, verileri bir kez (veya nasıl yapılandırıldığına bağlı olarak uygulama katmanı makine başına bir kez) okuyabilir ve ardından bu verileri veritabanınızın dışında depolayabilirsiniz. Bu, veritabanı yükünü azaltmanın bir yoludur (CPU ve okuma GÇ), ancak önbellekten okunan veriler veritabanındaki verilerle eşitlenmemiş olabileceğinden işlem tutarlılığı üzerinde bir etki vardır. Birçok uygulamada bazı tutarsızlık düzeyleri kabul edilebilir olsa da, bu tüm iş yükleri için geçerli değildir. Uygulama katmanı önbelleğe alma stratejisi uygulamadan önce tüm uygulama gereksinimlerini tam olarak anlamanız gerekir.
Yapılandırma ve tasarım ipuçlarını alma
Azure SQL Veritabanı kullanıyorsanız, Azure SQL Veritabanı'da veritabanı yapılandırmasını ve tasarımını geliştirmek için açık kaynak T-SQL betiği yürütebilirsiniz. Betik, veritabanınızı isteğe bağlı olarak analiz eder ve veritabanı performansını ve sistem durumunu geliştirmeye yönelik ipuçları sağlar. Bazı ipuçları en iyi yöntemlere göre yapılandırma ve işlem değişiklikleri önerirken, diğer ipuçları gelişmiş veritabanı altyapısı özelliklerini etkinleştirme gibi iş yükünüz için uygun tasarım değişiklikleri önerir.
Betik hakkında daha fazla bilgi edinmek ve kullanmaya başlamak için Azure SQL İpuçları wiki sayfasını ziyaret edin.
İlgili içerik
- DTU tabanlı satın alma modeli hakkında bilgi edinin
- Sanal çekirdek tabanlı satın alma modeli hakkında daha fazla bilgi edinin
- Bkz . Azure elastik havuzu nedir?
- Elastik havuzu ne zaman dikkate almalısınız keşfedin
- Dinamik yönetim görünümlerini kullanarak performansı izleme hakkında bilgi edinin
- Azure SQL Veritabanı yüksek CPU tanılamayı ve sorunlarını gidermeyi öğrenin
- Kümelenmemiş dizinleri eksik dizin önerileriyle ayarlama
- Video: Azure SQL Veritabanı'da En İyi Veri Yükleme Yöntemleri
- Azure İzleyici ile Azure SQL Veritabanı'nı izleme
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin