Bire birkaç ilişkisel verileri NoSQL için Azure Cosmos DB hesabına geçirme
UYGULANANLAR: ![]() NoSQL
NoSQL
İlişkisel veritabanından NoSQL için Azure Cosmos DB'ye geçiş yapmak için, iyileştirme için veri modelinde değişiklik yapılması gerekebilir.
Yaygın dönüştürmelerden biri, bir JSON belgesine ilgili alt öğeleri ekleyerek verileri normal dışı hale getirmedir. Burada Azure Data Factory veya Azure Databricks kullanarak bunun için birkaç seçeneğe göz atacağız. Azure Cosmos DB için veri modelleme hakkında daha fazla bilgi için bkz . Azure Cosmos DB'de veri modelleme.
Örnek Senaryo
SQL veritabanımızda aşağıdaki iki tablo olduğunu varsayalım: Orders ve OrderDetails.
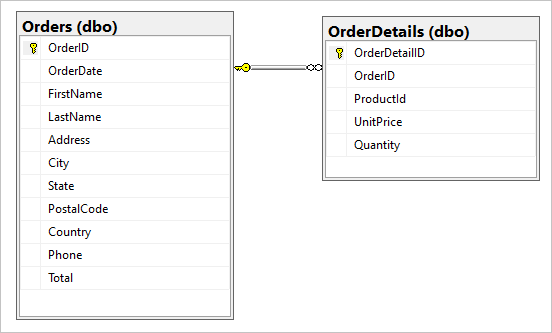
Geçiş sırasında bu bire birkaç ilişkiyi tek bir JSON belgesinde birleştirmek istiyoruz. Tek bir belge oluşturmak için kullanarak FOR JSONbir T-SQL sorgusu oluşturun:
SELECT
o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o;
Bu sorgunun sonuçları Orders tablosundaki verileri içerebilir:

İdeal olarak, SQL verilerini kaynak olarak sorgulamak ve çıkışı doğrudan Azure Cosmos DB havuzuna uygun JSON nesneleri olarak yazmak için tek bir Azure Data Factory (ADF) kopyalama etkinliği kullanmak istiyorsunuz. Şu anda tek bir kopyalama etkinliğinde gerekli JSON dönüşümlerini gerçekleştirmek mümkün değildir. Yukarıdaki sorgunun sonuçlarını NoSQL için Azure Cosmos DB kapsayıcısına kopyalamaya çalışırsak OrderDetails alanını beklenen JSON dizisi yerine belgemizin dize özelliği olarak görürüz.
Bu geçerli sınırlamaya geçici bir çözüm olarak aşağıdaki yollardan birini kullanabiliriz:
- Azure Data Factory'i iki kopyalama etkinliğiyle kullanın:
- JSON biçimli verileri SQL'den ara blob depolama konumundaki bir metin dosyasına alma
- JSON metin dosyasından Azure Cosmos DB'deki bir kapsayıcıya veri yükleyin.
- SQL'den okumak ve Azure Cosmos DB'ye yazmak için Azure Databricks'i kullanın. Burada iki seçenek sunuyoruz.
Şimdi bu yaklaşımlara daha ayrıntılı bir şekilde bakalım:
Azure Data Factory
OrderDetails'i hedef Azure Cosmos DB belgesine JSON dizisi olarak ekleyemiyoruz ancak iki ayrı Kopyalama Etkinliği kullanarak sorunu çözebiliriz.
Kopyalama Etkinliği #1: SqlJsonToBlobText
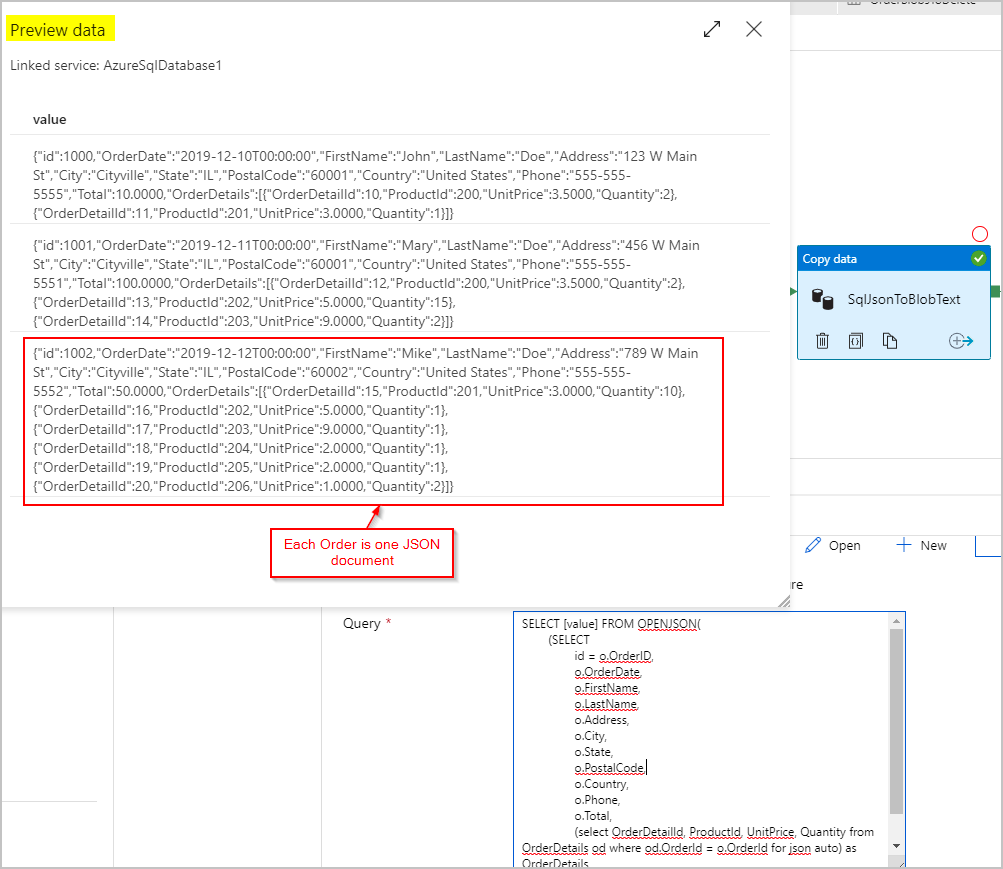
Kaynak veriler için, SQL Server OPENJSON ve FOR JSON PATH özelliklerini kullanarak sonuç kümesini satır başına tek bir JSON nesnesiyle (Sırayı temsil eden) tek bir sütun olarak almak için bir SQL sorgusu kullanırız:
SELECT [value] FROM OPENJSON(
(SELECT
id = o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o FOR JSON PATH)
)
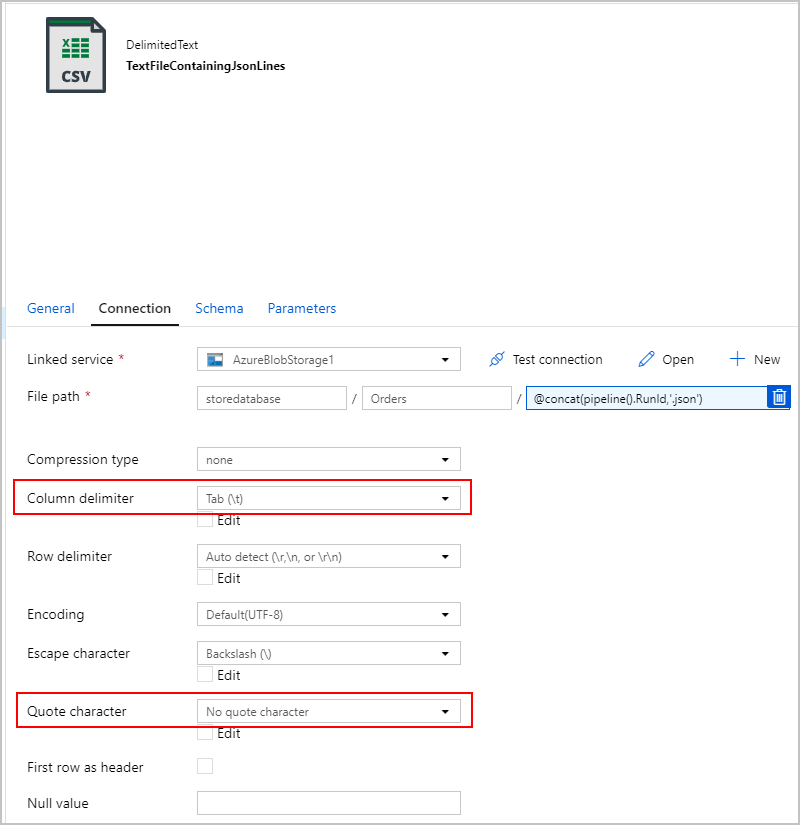
Kopyalama etkinliğinin SqlJsonToBlobText havuzu için "Sınırlandırılmış Metin"i seçip Azure Blob Depolama'daki belirli bir klasöre işaret ediyoruz. Bu havuz, dinamik olarak oluşturulan benzersiz bir dosya adı (örneğin, @concat(pipeline().RunId,'.json')) içerir.
Metin dosyamız gerçekten "sınırlandırılmış" olmadığından ve virgüller kullanılarak ayrı sütunlara ayrıştırılmasını istemiyoruz. Ayrıca çift tırnak işaretini ("), "Sütun sınırlayıcısını" Sekme ("\t") olarak veya verilerde oluşmayan başka bir karakter olarak ayarlamak ve ardından "Tırnak karakteri" değerini "Tırnak karakteri yok" olarak ayarlamak istiyoruz.
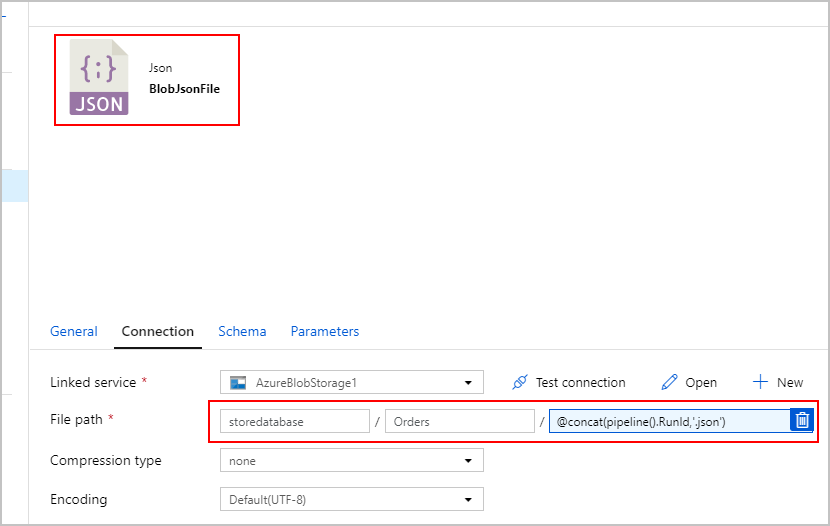
Kopyalama Etkinliği #2: BlobJsonToCosmos
Ardından, ilk etkinlik tarafından oluşturulan metin dosyası için Azure Blob Depolama görünen ikinci Kopyalama Etkinliğini ekleyerek ADF işlem hattımızı değiştireceğiz. Metin dosyasında bulunan JSON satırı başına bir belge olarak Azure Cosmos DB havuzuna eklemek için bunu "JSON" kaynağı olarak işler.
İsteğe bağlı olarak, her çalıştırmadan önce /Orders/ klasöründe kalan tüm önceki dosyaları silmesi için işlem hattına bir "Sil" etkinliği de ekleriz. ADF işlem hattımız şu şekilde görünür:
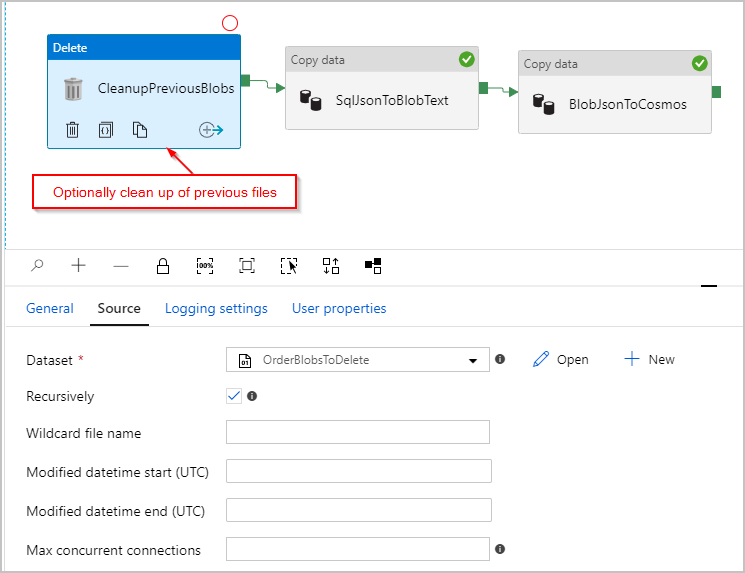
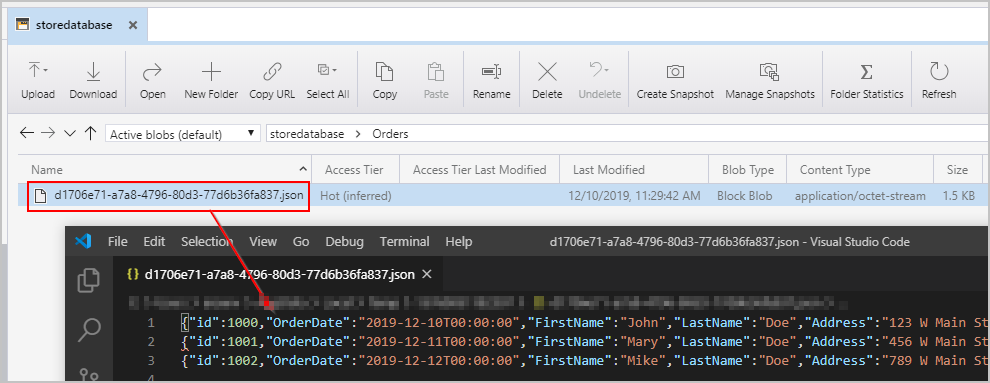
Daha önce bahsedilen işlem hattını tetikledikten sonra, aracı Azure Blob Depolama konumumuzda satır başına bir JSON nesnesi içeren bir dosya oluşturulur:
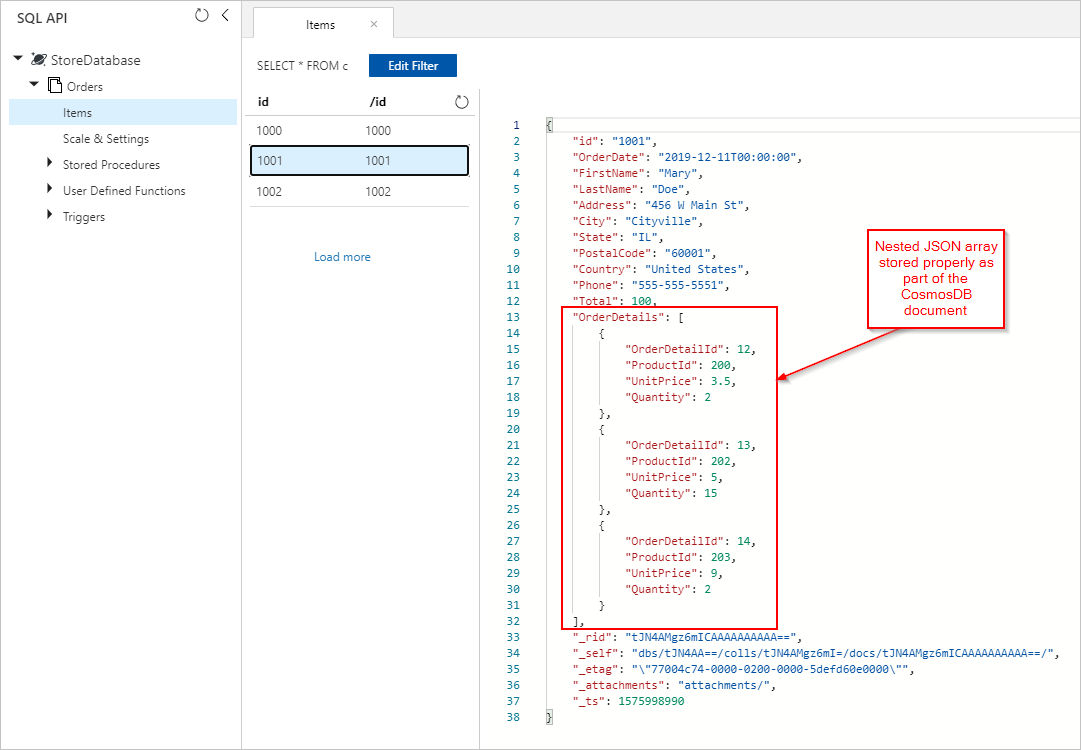
Ayrıca Azure Cosmos DB koleksiyonumuza düzgün şekilde eklenmiş OrderDetails içeren Siparişler belgelerini de görüyoruz:
Azure Databricks
Spark'ı Azure Databricks'te kullanarak SQL Veritabanı kaynağımızdaki verileri Azure Blob Depolama aracı metin/JSON dosyalarını oluşturmadan Azure Cosmos DB hedefine kopyalayabiliriz.
Not
Netlik ve basitlik için kod parçacıklarında açıkça satır içi sahte veritabanı parolaları bulunur, ancak ideal olarak Azure Databricks gizli dizilerini kullanmanız gerekir.
İlk olarak gerekli SQL bağlayıcısını ve Azure Cosmos DB bağlayıcı kitaplıklarını oluşturup Azure Databricks kümemize ekleyeceğiz. Kitaplıkların yüklendiğinden emin olmak için kümeyi yeniden başlatın.

Ardından Scala ve Python için iki örnek sunacağız.
Scala
Burada, DataFrame'de "FOR JSON" çıkışına sahip SQL sorgusunun sonuçlarını alacağız:
// Connect to Azure SQL /connectors/sql/
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val configSql = Config(Map(
"url" -> "xxxx.database.windows.net",
"databaseName" -> "xxxx",
"queryCustom" -> "SELECT o.OrderID, o.OrderDate, o.FirstName, o.LastName, o.Address, o.City, o.State, o.PostalCode, o.Country, o.Phone, o.Total, (SELECT OrderDetailId, ProductId, UnitPrice, Quantity FROM OrderDetails od WHERE od.OrderId = o.OrderId FOR JSON AUTO) as OrderDetails FROM Orders o",
"user" -> "xxxx",
"password" -> "xxxx" // NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
))
// Create DataFrame from Azure SQL query
val orders = sqlContext.read.sqlDB(configSql)
display(orders)
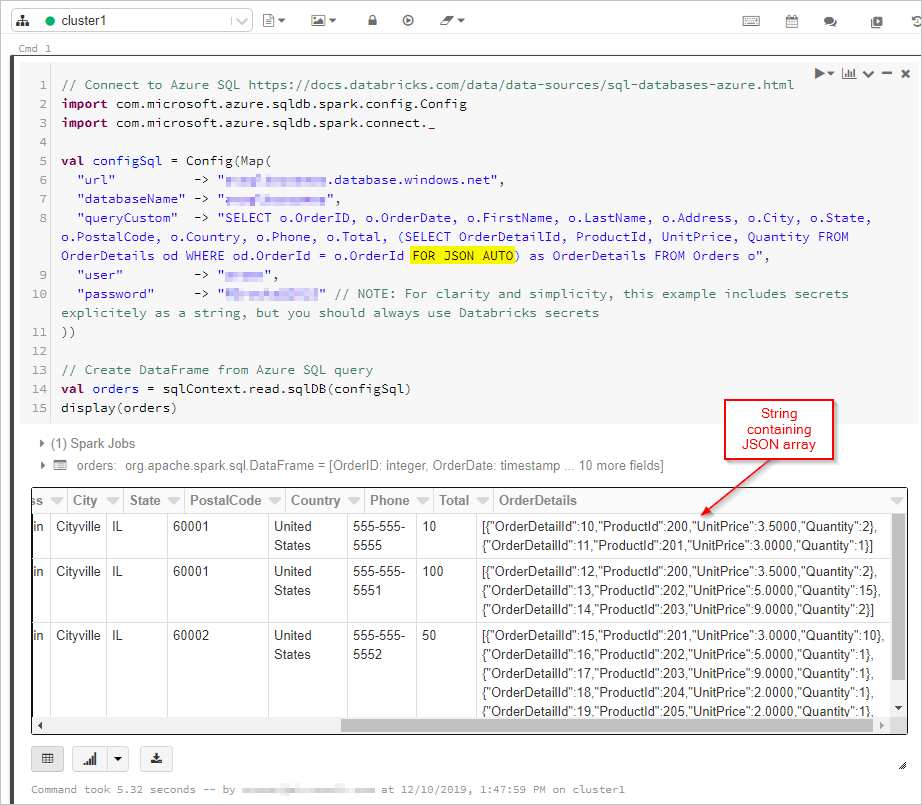
Ardından Azure Cosmos DB veritabanımıza ve koleksiyonumuza bağlanacağız:
// Connect to Azure Cosmos DB https://docs.databricks.com/data/data-sources/azure/cosmosdb-connector.html
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
val configMap = Map(
"Endpoint" -> "https://xxxx.documents.azure.com:443/",
// NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
"Masterkey" -> "xxxx",
"Database" -> "StoreDatabase",
"Collection" -> "Orders")
val configAzure Cosmos DB= Config(configMap)
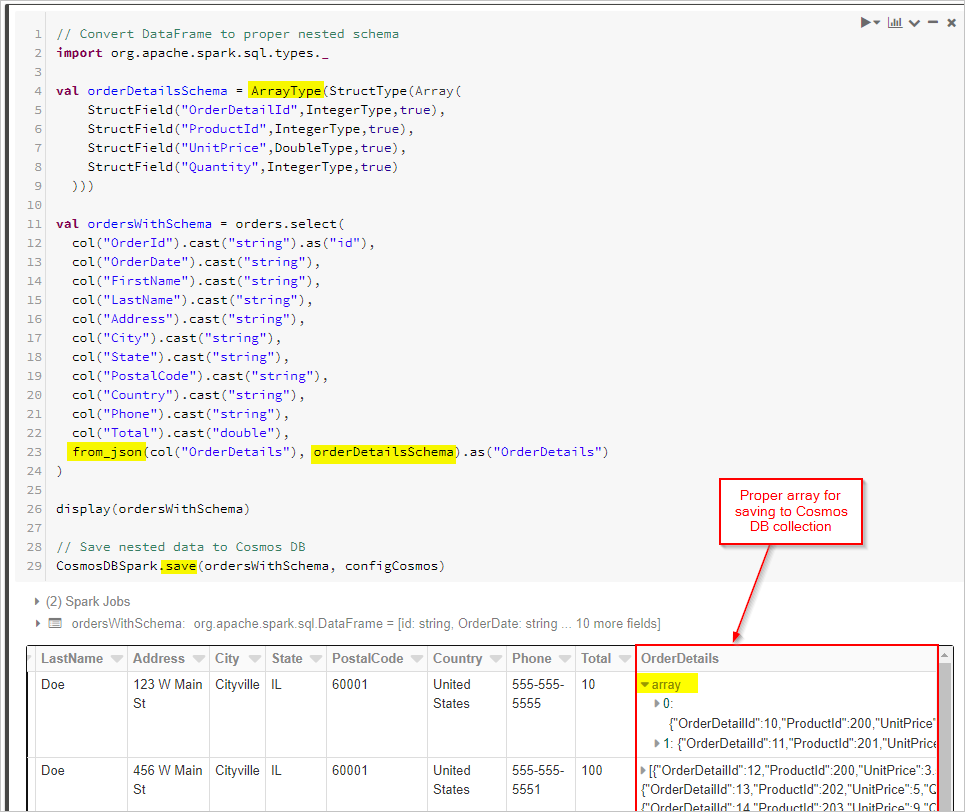
Son olarak şemamızı tanımlar ve Cosmos DB koleksiyonuna kaydetmeden önce DataFrame'i uygulamak için from_json kullanırız.
// Convert DataFrame to proper nested schema
import org.apache.spark.sql.types._
val orderDetailsSchema = ArrayType(StructType(Array(
StructField("OrderDetailId",IntegerType,true),
StructField("ProductId",IntegerType,true),
StructField("UnitPrice",DoubleType,true),
StructField("Quantity",IntegerType,true)
)))
val ordersWithSchema = orders.select(
col("OrderId").cast("string").as("id"),
col("OrderDate").cast("string"),
col("FirstName").cast("string"),
col("LastName").cast("string"),
col("Address").cast("string"),
col("City").cast("string"),
col("State").cast("string"),
col("PostalCode").cast("string"),
col("Country").cast("string"),
col("Phone").cast("string"),
col("Total").cast("double"),
from_json(col("OrderDetails"), orderDetailsSchema).as("OrderDetails")
)
display(ordersWithSchema)
// Save nested data to Azure Cosmos DB
CosmosDBSpark.save(ordersWithSchema, configCosmos)
Python
Alternatif bir yaklaşım olarak, kaynak veritabanı veya benzer bir işlemi desteklemiyorsa FOR JSON Spark'ta JSON dönüşümlerini yürütmeniz gerekebilir. Alternatif olarak, büyük bir veri kümesi için paralel işlemleri kullanabilirsiniz. Burada bir PySpark örneği sunuyoruz. İlk hücrede kaynak ve hedef veritabanı bağlantılarını yapılandırarak başlayın:
import uuid
import pyspark.sql.functions as F
from pyspark.sql.functions import col
from pyspark.sql.types import StringType,DateType,LongType,IntegerType,TimestampType
#JDBC connect details for SQL Server database
jdbcHostname = "jdbcHostname"
jdbcDatabase = "OrdersDB"
jdbcUsername = "jdbcUsername"
jdbcPassword = "jdbcPassword"
jdbcPort = "1433"
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, jdbcUsername, jdbcPassword)
#Connect details for Target Azure Cosmos DB for NoSQL account
writeConfig = {
"Endpoint": "Endpoint",
"Masterkey": "Masterkey",
"Database": "OrdersDB",
"Collection": "Orders",
"Upsert": "true"
}
Ardından, sonuçları Spark Veri Çerçevelerine yerleştirerek hem sipariş hem de sipariş ayrıntısı kayıtları için kaynak Veritabanını (bu örnekte SQL Server) sorgularız. Ayrıca tüm sipariş kimliklerini içeren bir liste ve paralel işlemler için bir İş Parçacığı havuzu oluştururuz:
import json
import ast
import pyspark.sql.functions as F
import uuid
import numpy as np
import pandas as pd
from functools import reduce
from pyspark.sql import SQLContext
from pyspark.sql.types import *
from pyspark.sql import *
from pyspark.sql.functions import exp
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.functions import array
from pyspark.sql.types import *
from multiprocessing.pool import ThreadPool
#get all orders
orders = sqlContext.read.jdbc(url=jdbcUrl, table="orders", properties=connectionProperties)
#get all order details
orderdetails = sqlContext.read.jdbc(url=jdbcUrl, table="orderdetails", properties=connectionProperties)
#get all OrderId values to pass to map function
orderids = orders.select('OrderId').collect()
#create thread pool big enough to process merge of details to orders in parallel
pool = ThreadPool(10)
Ardından, NoSQL koleksiyonu için hedef API'ye Orders yazmak için bir işlev oluşturun. Bu işlev, verilen sipariş kimliği için tüm sipariş ayrıntılarını filtreler, bunları bir JSON dizisine dönüştürür ve diziyi bir JSON belgesine ekler. Ardından JSON belgesi, bu sipariş için NoSQL kapsayıcısının hedef API'sine yazılır:
def writeOrder(orderid):
#filter the order on current value passed from map function
order = orders.filter(orders['OrderId'] == orderid[0])
#set id to be a uuid
order = order.withColumn("id", lit(str(uuid.uuid1())))
#add details field to order dataframe
order = order.withColumn("details", lit(''))
#filter order details dataframe to get details we want to merge into the order document
orderdetailsgroup = orderdetails.filter(orderdetails['OrderId'] == orderid[0])
#convert dataframe to pandas
orderpandas = order.toPandas()
#convert the order dataframe to json and remove enclosing brackets
orderjson = orderpandas.to_json(orient='records', force_ascii=False)
orderjson = orderjson[1:-1]
#convert orderjson to a dictionaory so we can set the details element with order details later
orderjsondata = json.loads(orderjson)
#convert orderdetailsgroup dataframe to json, but only if details were returned from the earlier filter
if (orderdetailsgroup.count() !=0):
#convert orderdetailsgroup to pandas dataframe to work better with json
orderdetailsgroup = orderdetailsgroup.toPandas()
#convert orderdetailsgroup to json string
jsonstring = orderdetailsgroup.to_json(orient='records', force_ascii=False)
#convert jsonstring to dictionary to ensure correct encoding and no corrupt records
jsonstring = json.loads(jsonstring)
#set details json element in orderjsondata to jsonstring which contains orderdetailsgroup - this merges order details into the order
orderjsondata['details'] = jsonstring
#convert dictionary to json
orderjsondata = json.dumps(orderjsondata)
#read the json into spark dataframe
df = spark.read.json(sc.parallelize([orderjsondata]))
#write the dataframe (this will be a single order record with merged many-to-one order details) to Azure Cosmos DB db using spark the connector
#https://learn.microsoft.com/azure/cosmos-db/spark-connector
df.write.format("com.microsoft.azure.cosmosdb.spark").mode("append").options(**writeConfig).save()
Son olarak, daha önce oluşturduğumuz sıra kimlikleri listesini geçirerek paralel olarak yürütmek için iş parçacığı havuzundaki bir eşleme işlevini kullanarak Python writeOrder işlevini çağırırız:
#map order details to orders in parallel using the above function
pool.map(writeOrder, orderids)
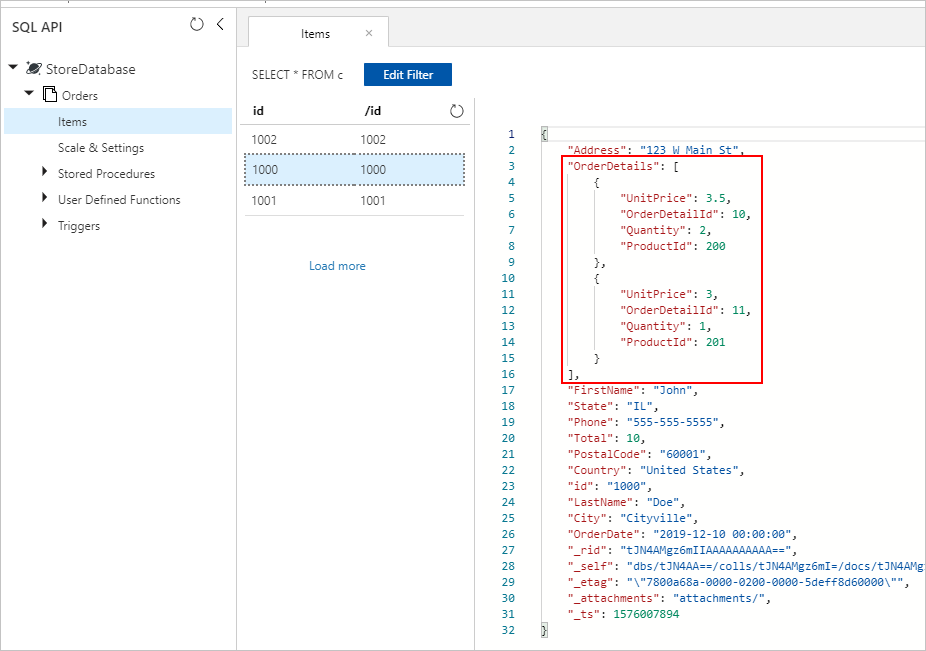
Her iki yaklaşımda da, sonunda Azure Cosmos DB koleksiyonundaki her Sipariş belgesine düzgün şekilde kaydedilmiş ekli OrderDetails almalıyız:
Sonraki adımlar
- Azure Cosmos DB'de veri modelleme hakkında bilgi edinin
- Azure Cosmos DB'de verileri modellemeyi ve bölümlemeyi öğrenin