Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Önemli
PostgreSQL için Azure Cosmos DB artık yeni projeler için desteklenmemektedir. Bu hizmeti yeni projeler için kullanmayın. Bunun yerine, şu iki hizmetlerden birini kullanın:
99,999% kullanılabilirlik hizmet düzeyi sözleşmesi (SLA), anında otomatik ölçeklendirme ve birden çok bölgede otomatik yük devretme ile yüksek ölçekli senaryolar için tasarlanmış dağıtılmış bir veritabanı çözümü için NoSQL için Azure Cosmos DB kullanın.
Açık kaynak Citus uzantısını kullanarak bölümlenmiş Azure Veritabanı'nın PostgreSQL için Elastik Kümeler özelliğini kullanın.
Her tablonun dağıtım sütununu seçme, en önemli modelleme kararlarından biridir. PostgreSQL için Azure Cosmos DB, satırların dağıtım sütununun değerine göre parçalar halinde depolar.
Doğru seçim, sorguları hızlı hale getiren ve tüm SQL özellikleri için destek ekleyen ilgili verileri aynı fiziksel düğümlerde birlikte gruplandırır. Yanlış bir seçim sistemin yavaş çalışmasına neden olur.
Genel ipuçları
Dağıtılmış tablolarınız için ideal dağıtım sütununu seçmeye yönelik dört ölçüt aşağıdadır.
Uygulama iş yükünde merkezi bir parça olan bir sütun seçin.
Bu sütunu verileri bölümleme için "kalp", "merkezi parça" veya "doğal boyut" olarak düşünebilirsiniz.
Örnekler:
-
device_idIoT iş yükünde -
security_idmenkul kıymetleri izleyen bir finansal uygulama için -
user_idkullanıcı analizinde -
tenant_idçok kiracılı bir SaaS uygulaması için
-
İyi bir kardinaliteye ve çift istatistiksel dağılıma sahip bir sütun seçin.
Sütunda birçok değer olmalıdır ve tüm parçalar arasında kapsamlı ve eşit bir şekilde dağıtılmalıdır.
Örnekler:
- 1000'den fazla kardinalite
- Büyük bir satır yüzdesinde aynı değere sahip bir sütun seçmeyin (veri dengesizliği)
- SaaS iş yükünde, bir kiracının diğerlerinden çok daha büyük olması veri dengesizliğine neden olabilir. Bu durumda kiracı yalıtımını kullanarak kiracıyı işlemek üzere ayrılmış bir parça oluşturabilirsiniz.
Mevcut sorgularınızdan yararlanan bir sütun seçin.
İşlemsel veya operasyonel iş yükü için (çoğu sorgunun yalnızca birkaç milisaniye sürdüğü durumlarda), sorguların en az %80'inde cümlelerinde
WHEREfiltresi olarak görünen bir sütun seçin. Örneğin,device_idiçindekiSELECT * FROM events WHERE device_id=1sütun.Analitik iş yükü (çoğu sorgu 1-2 saniye sürer) için sorguların çalışan düğümleri arasında paralelleştirilmesini sağlayan bir sütun seçin. Örneğin, GROUP BY yan tümcelerinde sıklıkla oluşan veya aynı anda birden çok değer üzerinde sorgulanan bir sütun.
Büyük tabloların çoğunda bulunan bir sütun seçin.
50 GB'ın üzerindeki tablolar dağıtılmalıdır. Tümü için aynı dağıtım sütununu seçmek, çalışan düğümlerinde bu sütuna ait verileri birlikte bulmanıza olanak tanır. Eş konumlandırma, JOIN'leri ve veri özetlemeyi çalıştırmayı ve yabancı anahtarları uygulamayı verimli hale getirir.
Diğer (daha küçük) tablolar yerel veya başvuru tabloları olabilir. Daha küçük tablonun dağıtılmış tablolarla JOIN yapması gerekiyorsa, bunu bir başvuru tablosu yapın.
Kullanım örneği örnekleri
Dağıtım sütununu seçmek için genel ölçütler gördük. Şimdi bunların yaygın kullanım örneklerine nasıl uygulanacağını görelim.
Çok kiracılı uygulamalar
Çok kiracılı mimari, sorguları kümedeki düğümler arasında dağıtmak için bir hiyerarşik veritabanı modelleme biçimi kullanır. Veri hiyerarşisinin üst kısmı kiracı kimliği olarak bilinir ve her tablodaki bir sütunda depolanması gerekir.
PostgreSQL için Azure Cosmos DB, hangi kiracı kimliğini içerdiğini görmek için sorguları inceler ve eşleşen tablo parçası bulur. Sorguyu, parçanın bulunduğu tek bir çalışan düğümüne yönlendirir. Aynı düğüme yerleştirilen tüm ilgili verileri içeren bir sorgu çalıştırmaya birlikte bulundurma adı verilir.
Aşağıdaki diyagramda çok kiracılı bir veri modelindeki ortak yerleşim gösterilmektedir.
account_id tarafından dağıtılan Hesaplar ve Kampanyalar adlı iki tablo içerir. Gölgeli kutular parçaları temsil eder. Yeşil parçalar bir çalışan düğümünde birlikte depolanır ve mavi parçalar başka bir çalışan düğümünde depolanır. Hesaplar ve Kampanyalar arasındaki birleştirme sorgusunun, her iki tablo da aynı "account_id" ile kısıtlandığında gerekli tüm verileri nasıl tek bir düğümde topladığını fark edin.
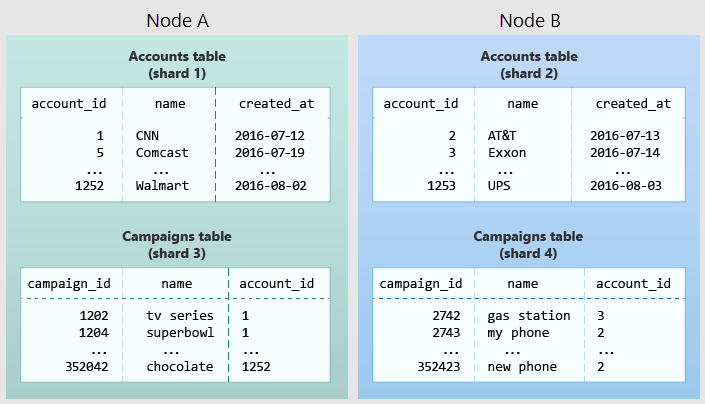
Bu tasarımı kendi şemanıza uygulamak için, uygulamanızda kiracının ne olduğunu belirleyin. Yaygın örnekleri şirket, hesap, kuruluş veya müşteridir. Sütun adı company_id veya customer_id gibi bir şey olacaktır. Sorgularınızın her birini inceleyin ve kendinize sorun: Aynı kiracı kimliğine sahip satırlarla ilgili tüm tabloları kısıtlamak için daha fazla WHERE yan tümcesi olsaydı, işe yarar mıydı? Çok kiracılı modeldeki sorgular bir kiracı ile sınırlıdır. Örneğin, satış veya envanterle ilgili sorguların kapsamı belirli bir mağaza içindedir.
En iyi yöntemler
- Tabloları ortak bir tenant_id sütununa göre dağıtma. Örneğin, kiracıların şirketler olduğu bir SaaS uygulamasında, kiracı_kimliği büyük olasılıkla şirket_kimliği olacaktır.
- Küçük kiracı arası tabloları referans tablolarına dönüştürün. Birden çok kiracı küçük bir bilgi tablosunu paylaştığında, bunu başvuru tablosu olarak dağıtın.
- Tüm uygulama sorgularını tenant_id göre filtrelemeyi kısıtlayın. Her sorgu aynı anda bir kiracı için bilgi istemelidir.
Bu tür bir uygulama oluşturma örneği için çok kiracılı öğreticiyi okuyun.
Gerçek zamanlı uygulamalar
Çok kiracılı mimari hiyerarşik bir yapıya sahiptir ve kiracı başına sorguları yönlendirmek için veri birlikte bulundurmayı kullanır. Buna karşılık, gerçek zamanlı mimariler yüksek düzeyde paralel işleme elde etmek için verilerinin belirli dağıtım özelliklerine bağlıdır.
Gerçek zamanlı modelde dağıtım sütunları için terim olarak "varlık kimliği" kullanırız. Tipik varlıklar, kullanıcılar, ana bilgisayarlar veya cihazlardır.
Gerçek zamanlı sorgular genellikle tarihe veya kategoriye göre gruplandırılmış sayısal toplamalar ister. PostgreSQL için Azure Cosmos DB, kısmi sonuçlar için bu sorguları her parçaya gönderir ve koordinatör düğümünde son yanıtı bir araya getirmektedir. Sorgular, mümkün olduğunca çok düğüm katkıda bulununca ve tek bir düğümün orantısız bir iş yapması gerekmediğinde en hızlı şekilde çalışır.
En iyi yöntemler
- Dağıtım sütunu olarak yüksek kardinaliteye sahip bir sütun seçin. Karşılaştırma için, sipariş tablosundaki Yeni, Ücretli ve Sevk Edildi değerlerine sahip bir Durum alanı, düşük bir dağıtım sütunu seçimidir. Yalnızca verileri tutabilen parça sayısını ve işleyebilen düğüm sayısını sınırlayan birkaç değer olduğunu varsayar. Yüksek kardinaliteye sahip sütunlar arasında, gruplandırma ölçütü yan tümcelerinde veya birleştirme anahtarları olarak sık kullanılan sütunları seçmek de iyidir.
- Çift dağıtımlı bir sütun seçin. Tabloyu belirli ortak değerlere eğik bir sütuna dağıtırsanız, tablodaki veriler belirli parçalarda birikme eğilimindedir. Bu parçaları barındıran düğümler, diğer düğümlerden daha fazla iş yapar.
- Olgu ve boyut tablolarını ortak sütunlarına dağıtabilirsiniz. Olgu tablonuzda yalnızca bir dağıtım anahtarı olabilir. Başka bir anahtara katılan tablolar olgu tablosuyla birlikte bulunmaz. Ne sıklıkta birleştiğine ve birleştirilen satırların boyutuna bağlı olarak, tek bir boyutu eş konumlandırmak için seçin.
- Bazı boyut tablolarını başvuru tablolarına dönüştür. Boyut tablosu olgu tablosuyla birlikte bulunamıyorsa, boyut tablosunun kopyalarını başvuru tablosu biçimindeki tüm düğümlere dağıtarak sorgu performansını geliştirebilirsiniz.
Bu tür bir uygulama oluşturma örneği için gerçek zamanlı pano öğreticisini okuyun.
Zaman serisi verileri
Bir zaman serisi iş yükünde, uygulamalar eski bilgileri arşivlerken son bilgileri sorgular.
PostgreSQL için Azure Cosmos DB'de zaman serisi bilgilerini modellemede en yaygın hata, zaman damgasının kendisini dağıtım sütunu olarak kullanmaktır. Zamana dayalı karma dağıtım, zaman aralıklarını parçalarda bir arada tutmak yerine rastgele görünen zamanları farklı parçalara dağıtır. Zaman içeren sorgular genellikle en son veriler gibi zaman aralıklarına başvurur. Bu tür bir karmalı dağıtım, ağda ek yüke neden olur.
En iyi yöntemler
- Dağıtım sütunu olarak zaman damgası seçmeyin. Farklı bir dağıtım sütunu seçin. Çok kiracılı bir uygulamada kiracı kimliğini kullanın veya gerçek zamanlı bir uygulamada varlık kimliğini kullanın.
- Bunun yerine zaman için PostgreSQL tablo bölümleme kullanın. Zaman sıralı verilerden oluşan büyük bir tabloyu, her tablo farklı zaman aralıkları içeren birden çok devralınan tabloya bölmek için tablo bölümlemesi kullanın. Postgres bölümlenmiş bir tablo dağıtıldığında, devralınan tablolar için parçalar oluşturulur.
Sonraki adımlar
- Dağıtılmış verilerde kolokasyonun sorguların hızlı çalışmasına nasıl yardımcı olduğunu öğrenin.
- Dağıtılmış tablonun dağıtım sütununu ve diğer yararlı tanılama sorgularını keşfedin.