Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
ŞUNLARA UYGULANIR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
İpucu
Microsoft Fabric'daki
pipeline içindeki Azure Databricks Python Etkinliği, Azure Databricks kümenizde bir Python dosyası çalıştırır. Bu makale , veri dönüştürme ve desteklenen dönüştürme etkinliklerine genel bir genel bakış sunan veri dönüştürme etkinlikleri makalesini oluşturur. Azure Databricks, Apache Spark çalıştırmaya yönelik yönetilen bir platformdur.
Bu özelliğe yönelik on bir dakikalık bir giriş ve tanıtım için, aşağıdaki videoyu izleyin:
Kullanıcı arabirimiyle işlem hattına Azure Databricks için Python etkinliği ekleme
İşlem hattında Azure Databricks için Python etkinliği kullanmak için aşağıdaki adımları tamamlayın:
İşlem hattı Etkinlikleri bölmesinde Python araması yapın ve Python etkinliğini işlem hattı tuvaline sürükleyin.
Henüz seçili değilse tuvaldeki yeni Python etkinliğini seçin.
Python etkinliğini yürütecek yeni bir Azure Databricks bağlı hizmeti seçmek veya oluşturmak için Azure Databricks sekmesini seçin.
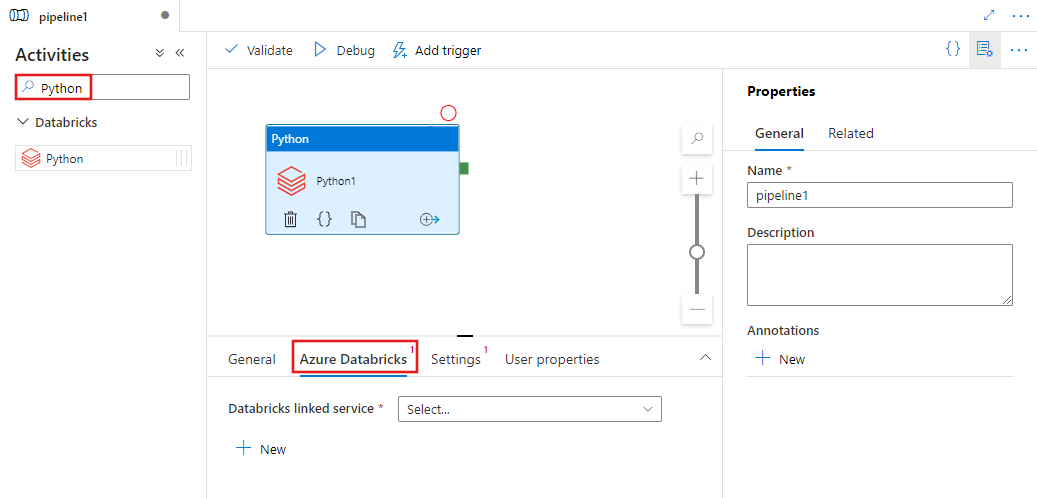
Settings sekmesini seçin ve yürütülecek Azure Databricks Python dosyasının yolunu, geçirilecek isteğe bağlı parametreleri ve işi yürütmek için kümeye yüklenecek ek kitaplıkları belirtin.
Python etkinliği için Ayarlar sekmesinin kullanıcı arabirimini gösterir.
Databricks Python etkinlik tanımı
Databricks Python Etkinliğinin örnek JSON tanımı aşağıda verilmiştir:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksSparkPython",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"pythonFile": "dbfs:/docs/pi.py",
"parameters": [
"10"
],
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
}
]
}
}
}
Databricks Python etkinlik özellikleri
Aşağıdaki tabloda JSON tanımında kullanılan JSON özellikleri açıklanmaktadır:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Adı | İşlem hattındaki etkinliğin adı. | Yes |
| açıklama | Etkinliğin ne yaptığını açıklayan metin. | Hayır |
| Tip | Databricks Python Etkinliği için etkinlik türü DatabricksSparkPython'dır. | Yes |
| bağlantılıHizmetAdı | Python etkinliğinin çalıştığı Databricks Bağlı Hizmeti'nin adı. Bu bağlı hizmet hakkında bilgi edinmek için Compute bağlı hizmetler makalesine bakın. | Yes |
| pythonFile | Yürütülecek Python dosyasının URI'sini. Yalnızca DBFS yolları desteklenir. | Yes |
| parametreler | Python dosyasına geçirilecek komut satırı parametreleri. Bu bir dize dizisidir. | Hayır |
| kitaplıklar | İşi yürütecek kümeye yüklenecek kitaplıkların listesi. Bir dize veya nesne dizisi <olabilir> | Hayır |
Databricks etkinlikleri için desteklenen yazılım kitaplıkları
Yukarıdaki Databricks etkinlik tanımında şu kitaplık türlerini belirtirsiniz: jar, egg, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Daha fazla ayrıntı için kitaplık türleri için Databricks belgelerine bakın.
Databricks'te kitaplık yükleme
Çalışma Alanı kullanıcı arabirimini kullanabilirsiniz:
Kullanıcı arabirimi kullanılarak eklenen kitaplığın dbfs yolunu almak için Databricks CLI kullanabilirsiniz.
Jar kitaplıkları genellikle kullanıcı arabirimi kullanılırken dbfs:/FileStore/jars altında depolanır. Cli aracılığıyla tümünü listeleyebilirsiniz: databricks fs ls dbfs:/FileStore/job-jars
Databricks CLI'yi de kullanabilirsiniz:
Adımları izleyin: Databricks CLI kullanarak kitaplığı kopyalayın
Databricks CLI kullanma (yükleme adımları)
Örneğin, BIR JAR dosyasını dbfs'ye kopyalamak için:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar