Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
UYGULANANLAR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
İpucu
Kuruluşlar için hepsi bir arada analiz çözümü olan Microsoft Fabric'te Data Factory'yi deneyin. Microsoft Fabric , veri taşımadan veri bilimine, gerçek zamanlı analize, iş zekasına ve raporlamaya kadar her şeyi kapsar. Yeni bir deneme sürümünü ücretsiz olarak başlatmayı öğrenin!
Azure Data Factory kullanmaya yeni başlıyorsanız bkz. Azure Data Factory'ye giriş.
Bu öğreticide, veri akışları kullanılarak ADLS Gen2 veya Azure Blob Depolama'ya dosya yazmak için uygulanabilecek en iyi yöntemleri öğreneceksiniz. Parquet dosyasını okumak ve sonuçları klasörlerde depolamak için bir Azure Blob Depolama Hesabına veya Azure Data Lake Store 2. Nesil hesabına erişmeniz gerekir.
Önkoşullar
- Azure aboneliği. Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir Azure hesabı oluşturun.
- Azure depolama hesabı. ADLS depolama alanını kaynak ve havuz veri depoları olarak kullanırsınız. Depolama hesabınız yoksa, oluşturma adımları için bkz. Azure depolama hesabı oluşturma.
Bu öğreticideki adımlarda, belirli bilgilere sahip olduğunuz varsayılacaktır.
Veri fabrikası oluşturma
Bu adımda bir veri fabrikası oluşturacak ve Data Factory UX'yi açarak veri fabrikasında işlem hattı oluşturacaksınız.
Microsoft Edge veya Google Chrome'u açın. Şu anda Data Factory kullanıcı arabirimi yalnızca Microsoft Edge ve Google Chrome web tarayıcılarında desteklenmektedir.
Sol menüde Kaynak oluşturma>Entegrasyon>Veri Fabrikası'nı seçin
Yeni veri fabrikası sayfasındaki Ad alanına ADFTutorialDataFactory girin
Veri fabrikasını oluşturmak istediğiniz Azure aboneliğinizi seçin.
Kaynak Grubu için aşağıdaki adımlardan birini uygulayın:
a. Var olanı kullan’ı seçin ve ardından açılır listeden var olan bir kaynak grubu belirleyin.
b. Yeni oluştur’u seçin ve bir kaynak grubunun adını girin. Kaynak grupları hakkında daha fazla bilgi için bkz. Azure kaynaklarınızı yönetmek için kaynak gruplarını kullanma.
Sürüm bölümünde V2'yi seçin.
Konum bölümünden veri fabrikası için bir konum seçin. Açılan listede yalnızca desteklenen konumlar görüntülenir. Veri fabrikası tarafından kullanılan veri depoları (örneğin, Azure Depolama ve SQL Veritabanı) ve işlem (örneğin, Azure HDInsight) diğer bölgelerde olabilir.
Oluştur'u belirleyin.
Oluşturma işlemi tamamlandıktan sonra Bildirim merkezi'nde bildirimi görürsünüz. Kaynağa git'i seçerek Data factory sayfasına gidin.
Data Factory Kullanıcı Arabirimini (UI) ayrı bir sekmede başlatmak için
Author & Monitor ’i seçin.
Veri akışı etkinliğiyle işlem hattı oluşturma
Bu adımda, veri akışı etkinliği içeren bir işlem hattı oluşturacaksınız.
Azure Data Factory'nin giriş sayfasında Düzenle'yi seçin.
İşlem hattının Genel sekmesinde, işlem hattının Adı için DeltaLake girin.
Fabrika üst çubuğunda Veri Akışı hata ayıklama kaydırıcısını açın. Hata ayıklama modu, dinamik bir Spark kümesinde dönüştürme mantığının etkileşimli olarak test edilmesini sağlar. Veri Akışı kümelerin ısınması 5-7 dakika sürer ve kullanıcıların Veri Akışı geliştirme yapmayı planlıyorlarsa önce hata ayıklamayı açmaları önerilir. Daha fazla bilgi için Hata Ayıklama Modu'na bakın.

Etkinlikler bölmesinde Taşı ve Dönüştür akordeonunu genişletin. bölmeden Veri Akışı etkinliğini sürükleyip işlem hattı tuvaline bırakın.

Veri akışı tuvalinde dönüştürme mantığı oluşturma
Tüm kaynak verileri alacaktır (bu öğreticide bir Parquet dosya kaynağı kullanacağız) ve data lake ETL için en etkili mekanizmaları kullanarak verileri Parquet biçiminde almak için havuz dönüşümü kullanacaksınız.

Öğretici hedefleri
- Yeni veri akışı 1'de kaynak veri kümelerinden herhangi birini seçin. Havuz veri kümenizi etkili bir şekilde bölümlendirmek için veri akışlarını kullanma
- Bölümlenmiş verilerinizi ADLS 2. Nesil göl klasörlerine aktarma
Boş bir veri akışı tuvalinden başlama
İlk olarak, ADLS 2. Nesil'deki giriş verileri için aşağıda açıklanan mekanizmaların her biri için veri akışı ortamını ayarlayalım
- Kaynak dönüşümüne tıklayın.
- Alt panelde veri kümesinin yanındaki yeni düğmesine tıklayın.
- Bir veri kümesi seçin veya yeni bir veri kümesi oluşturun. Bu tanıtım için Kullanıcı Verileri adlı bir Parquet veri kümesi kullanacağız.
- Türetilmiş Sütun dönüştürmesi ekleyin. Bunu, istediğiniz klasör adlarını dinamik olarak ayarlamanın bir yolu olarak kullanacağız.
- Havuz dönüşümü ekleyin.
Hiyerarşik klasör çıkışı
Verilerinizi gölde bölümlendirmek üzere klasör hiyerarşileri oluşturmak için verilerinizde benzersiz değerler kullanmak çok yaygındır. Bu, göldeki ve Spark'taki (veri akışlarının arkasındaki işlem altyapısı) verileri düzenlemek ve işlemek için çok uygun bir yoldur. Ancak, çıkışınızı bu şekilde düzenlemek için küçük bir performans maliyeti olacaktır. Bu mekanizmayı çıkış noktasında kullanarak boru hattı performansında küçük bir düşüş görmeyi bekleyin.
- Veri akışı tasarımcısına geri dönün ve yukarıda oluşturduğunuz veri akışını düzenleyin. Lavabo dönüşümüne tıklayın.
- Bölümleme > Anahtarını En İyi Duruma Getir'e > tıklayın
- Hiyerarşik klasör yapınızı ayarlamak için kullanmak istediğiniz sütunları seçin.
- Aşağıdaki örnekte klasör adlandırma için sütun olarak yıl ve ay kullanıldığına dikkat edin. Sonuçlar,
releaseyear=1990/month=8biçimindeki klasörler olacaktır. - Bir veri akışı kaynağındaki veri bölümlerine erişirken, yalnızca yukarıdaki
releaseyearen üst düzey klasörü işaret edecek ve sonraki her klasör için joker karakter deseni kullanacaksınız, örneğin:**/**/*.parquet - Veri değerlerini işlemek için veya klasör adları için yapay değerler oluşturmanız gerekse bile Türetilmiş Sütun dönüştürmesini kullanarak klasör adlarınızda kullanmak istediğiniz değerleri oluşturun.
Anahtar bölümleme
Klasörü veri değerleri olarak adlandır
ADLS 2. Nesil kullanan ve anahtar/değer bölümleme ile aynı avantajı sunmayan göl verileri için biraz daha iyi performans gösteren bir havuz tekniğidir Name folder as column data. Hiyerarşik yapının anahtar bölümleme stili veri dilimlerini daha kolay işlemenize olanak sağlarken, bu teknik daha hızlı veri yazabilen düzleştirilmiş bir klasör yapısıdır.
- Veri akışı tasarımcısına geri dönün ve yukarıda oluşturduğunuz veri akışını düzenleyin. Lavabo dönüşümüne tıklayın.
- Optimize'a tıklayın > Bölümlemeyi ayarla > Mevcut bölümlemeyi kullan.
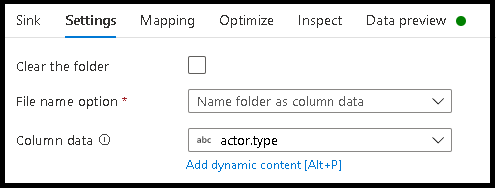
- Ayarlar > Adı klasörünü sütun verileri olarak tıklatın.
- Klasör adlarını oluşturmak için kullanmak istediğiniz sütunu seçin.
- Veri değerlerini işlemek için veya klasör adları için yapay değerler oluşturmanız gerekse bile Türetilmiş Sütun dönüştürmesini kullanarak klasör adlarınızda kullanmak istediğiniz değerleri oluşturun.
Dosyayı veri değerleri olarak adlandırma
Yukarıdaki öğreticilerde listelenen teknikler, data lake'inizde klasör kategorileri oluşturmak için iyi kullanım örnekleridir. Bu teknikler tarafından kullanılan varsayılan dosya adlandırma düzeni Spark yürütücüsü iş kimliğini kullanmaktır. Bazen bir veri akışı metin havuzundaki çıkış dosyasının adını ayarlamak isteyebilirsiniz. Bu teknik yalnızca küçük dosyalarla kullanım için önerilir. Bölüm dosyalarını tek bir çıkış dosyasında birleştirme işlemi uzun süre çalışan bir işlemdir.
- Veri akışı tasarımcısına geri dönün ve yukarıda oluşturduğunuz veri akışını düzenleyin. Lavabo dönüşümüne tıklayın.
- Tıklayın En İyi Duruma Getir > Bölümlemeyi Ayarla > Tek bölüm. Dosyalar birleştirildiğinde yürütme işleminde bir performans sorunu oluşturan bu tek bölüm gereksinimidir. Bu seçenek yalnızca küçük dosyalar için önerilir.
- Ayarlar > Dosyayı sütun verileri olarak adlandırın.
- Dosya adlarını oluşturmak için kullanmak istediğiniz sütunu seçin.
- Veri değerlerini işlemek için veya dosya adları için yapay değerler oluşturmanız gerekse bile Türetilmiş Sütun dönüştürmesini kullanarak dosya adlarınızda kullanmak istediğiniz değerleri oluşturun.
İlgili içerik
Veri akışı havuzları hakkında daha fazla bilgi edinin.