Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede, Azure Databricks'teki Google BigQuery tablolarından okuma ve bu tablolara yazma işlemleri açıklanmaktadır.
Önemli
Eski sorgu federasyon belgeleri kullanımdan kaldırıldı ve güncelleştirilmeyebilir. Bu içerikte belirtilen yapılandırmalar Databricks tarafından resmi olarak onaylanmaz veya test edilmemektedir. Lakehouse Federation kaynak veritabanınızı destekliyorsa Databricks bunun yerine bunu kullanmanızı önerir.
Anahtar tabanlı kimlik doğrulaması kullanarak BigQuery'ye bağlanmanız gerekir.
İzinler
Projelerinizin BigQuery kullanarak okumak ve yazmak için belirli Google izinlerine sahip olması gerekir.
Uyarı
Bu makalede BigQuery malzemeleşmiş görünümleri ele alınmaktadır. Ayrıntılar için Malzemeleştirilmiş görünümler için giriş Google makalesine bakın. Diğer BigQuery terminolojisini ve BigQuery güvenlik modelini öğrenmek için Google BigQuery belgelerine bakın.
BigQuery ile veri okuma ve yazma iki Google Cloud projesine bağlıdır:
- Proje (
project): Azure Databricks'in BigQuery tablosunu okuduğu veya yazdığı Google Cloud projesinin kimliği. - Üst proje (
parentProject): Okuma ve yazma işlemleri için faturalandırma amacıyla kullanılan Google Cloud Proje Kimliği olan üst projenin kimliği. Bunu anahtar oluşturacağınız Google hizmet hesabıyla ilişkilendirilmiş Google Cloud projesi olarak ayarlayın.
BigQuery'ye erişen kodda project ve parentProject değerlerini açıkça sağlamanız gerekir. Aşağıdakine benzer bir kod kullanın:
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Google Cloud projeleri için gerekli izinler, project ve parentProject'in aynı olup olmamasına bağlıdır. Aşağıdaki bölümlerde her senaryo için gerekli izinler listelanmıştır.
project ve parentProject eşleşiyorsa gerekli izinler
ve project kimlikleriniz parentProject aynıysa, en düşük izinleri belirlemek için aşağıdaki tabloyu kullanın:
| Azure Databricks görevi | Projede gereken Google izinleri |
|---|---|
| Gerçekleştirilmiş görünüm olmadan BigQuery tablosunu okuma | Projede project :
|
| BigQuery tablosunu gerçekleştirilmiş görünüme sahip olarak okuma | Projede project :
Gerçekleştirme projesinde:
|
| BigQuery tablosu yazma | Projede project :
|
project ve parentProject farklıysa gerekli izinler alınmalıdır.
Kimlikleriniz project ve parentProject farklıysa, en düşük izinleri belirlemek için aşağıdaki tabloyu kullanın.
| Azure Databricks görevi | Google izinleri gerekli |
|---|---|
| Gerçekleştirilmiş görünüm olmadan BigQuery tablosunu okuma | Projede parentProject :
Projede project :
|
| BigQuery tablosunu gerçekleştirilmiş görünüme sahip olarak okuma | Projede parentProject :
Projede project :
Gerçekleştirme projesinde:
|
| BigQuery tablosu yazma | Projede parentProject :
Projede project :
|
1. Adım: Google Cloud'ı ayarlama
BigQuery Depolama API'sini etkinleştirme
BigQuery'nin etkinleştirildiği yeni Google Cloud projelerinde BigQuery Depolama API'si varsayılan olarak etkindir. Ancak, var olan bir projeniz varsa ve BigQuery Depolama API'niz etkinleştirilmediyse, bu bölümdeki adımları izleyerek etkinleştirin.
BigQuery Depolama API'sini Google Cloud CLI veya Google Cloud Console kullanarak etkinleştirebilirsiniz.
Google Cloud CLI kullanarak BigQuery Depolama API'sini etkinleştirme
gcloud services enable bigquerystorage.googleapis.com
Google Cloud Console kullanarak BigQuery Depolama API'sini etkinleştirme
Sol gezinti bölmesinde API'ler ve Hizmetler'e tıklayın.
APIS VE HİzMETLerİ ETKİnLEŞTİr düğmesine tıklayın.
Arama çubuğuna yazın
bigquery storage apive ilk sonucu seçin.
BigQuery Depolama API'sinin etkinleştirildiğinden emin olun.
Azure Databricks için Google hizmet hesabı oluşturma
Azure Databricks kümesi için bir hizmet hesabı oluşturun. Databricks, bu hizmet hesabına görevlerini gerçekleştirmek için gereken en düşük ayrıcalıkların verilmesini önerir. Bkz. BigQuery Rolleri ve İzinleri.
Google Cloud CLI veya Google Cloud Console kullanarak bir hizmet hesabı oluşturabilirsiniz.
Google Cloud CLI kullanarak Google hizmet hesabı oluşturma
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
Hizmet hesabınızın anahtarlarını oluşturun:
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Google Cloud Console kullanarak Google hizmet hesabı oluşturma
Hesabı oluşturmak için:
Sol gezinti bölmesinde IAM ve Yönetici'ye tıklayın.
Hizmet Hesapları'nı tıklatın.
+ HİzMET HESABI OLUŞTUR'a tıklayın.
Hizmet hesabı adını ve açıklamasını girin.
OLUŞTUR'a tıklayın.
Hizmet hesabınız için rolleri belirtin. Rol seçin açılır listesinin içine yazın ve şu rolleri ekleyin:
BigQuery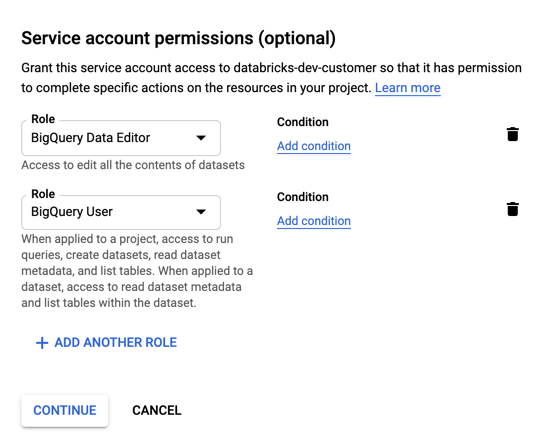
DEVAM'a tıklayın.
TAMAM'a tıklayın.
Hizmet hesabınızın anahtarlarını oluşturmak için:
Hizmet hesapları listesinde yeni oluşturduğunuz hesaba tıklayın.
Anahtarlar bölümünde ANAHTAR EKLE Yeni anahtar > oluştur düğmesini seçin.
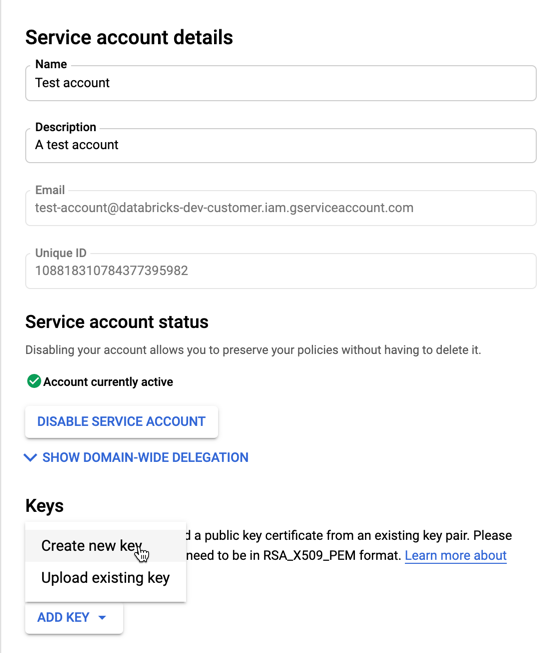
JSON anahtar türünü kabul edin.
OLUŞTUR'a tıklayın. JSON anahtar dosyası bilgisayarınıza indirilir.
Önemli
Hizmet hesabı için oluşturduğunuz JSON anahtar dosyası, Google Cloud hesabınızdaki veri kümelerine ve kaynaklara erişimi denetlediğinden yalnızca yetkili kullanıcılarla paylaşılması gereken özel bir anahtardır.
Geçici depolama için Google Cloud Storage (GCS) demeti oluşturma
BigQuery'ye veri yazmak için veri kaynağının gcs demetine erişmesi gerekir.
Sol gezinti bölmesinde Depolama'ya tıklayın.
OLUŞTUR DEMET'e tıklayın.
Kova ayrıntılarını yapılandırın.
OLUŞTUR'a tıklayın.
İzinler sekmesine ve Üye ekle'ye tıklayın.
Kovadaki hizmet hesabına aşağıdaki izinleri verin.
KAYDET'e tıklayın.
2. Adım: Azure Databricks'i ayarlama
Kümeyi BigQuery tablolarına erişecek şekilde yapılandırmak için JSON anahtar dosyanızı Spark yapılandırması olarak sağlamanız gerekir. JSON anahtar dosyanızı Base64 ile kodlamak için yerel bir araç kullanın. Güvenlik amacıyla anahtarlarınıza erişebilecek web tabanlı veya uzak bir araç kullanmayın.
Kümenizi yapılandırırken:
Spark Yapılandırması sekmesinde aşağıdaki Spark yapılandırmasını ekleyin. değerini Base64 ile kodlanmış JSON anahtar dosyanızın dizesiyle değiştirin<base64-keys>. Köşeli ayraç içindeki diğer öğeleri (örneğin <client-email>), JSON anahtar dosyanızdaki bu alanların değerleriyle değiştirin.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
BigQuery tablosuna okuma ve yazma
BigQuery tablosunu okumak için belirtin.
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
BigQuery tablosuna yazmak için belirtmeniz gerekenler:
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
burada<bucket-name>, geçici depolama için Google Cloud Storage (GCS) demeti oluşturma bölümünde oluşturduğunuz demetin adıdır.
İzinlere ve <project-id> ile <parent-id> değerlerine ilişkin gereksinimler hakkında bilgi edinmek için bkz.
BigQuery'den dış tablo oluşturma
Önemli
Bu özellik Unity Kataloğu tarafından desteklenmez.
Databricks'te verileri doğrudan BigQuery'den okuyacak yönetilmeyen bir tablo bildirebilirsiniz:
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Python not defteri örneği: DataFrame'e Google BigQuery tablosu yükleme
Aşağıdaki Python not defteri bir Google BigQuery tablosunu Azure Databricks DataFrame'e yükler.
Google BigQuery Python örnek not defteri
Scala not defteri örneği: DataFrame'e Google BigQuery tablosu yükleme
Aşağıdaki Scala not defteri bir Google BigQuery tablosunu Azure Databricks DataFrame'e yükler.