Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Uyarı
Bu makalenin düzeni, basit form hesaplama kullanıcı arabirimini kullandığınızı varsayar. Basit form güncelleştirmelerine genel bakış için bkz. Hesaplamayı yönetmek için basit formu kullanma.
Bu makalede, yeni bir çok amaçlı veya iş işlem kaynağı oluşturulurken kullanılabilen yapılandırma ayarları açıklanmaktadır. Kullanıcıların çoğu, atandığı ilkeleri kullanarak işlem kaynakları oluşturur ve bu da yapılandırılabilir ayarları sınırlar. Kullanıcı arabiriminizde belirli bir ayar görmüyorsanız, bunun nedeni seçtiğiniz ilkenin bu ayarı yapılandırmanıza izin vermemesidir.
İş yükünüz için işlem yapılandırma önerileri için bkz. Klasik işlem yapılandırması en iyi yöntemleri.
Bu makalede açıklanan yapılandırmalar ve yönetim araçları hem çok amaçlı hem de iş işlemi için geçerlidir. Daha fazla bilgi için bkz. Görevler için işlem birimini yapılandırma.
Yeni bir çok amaçlı işlem kaynağı oluşturma
Yeni bir çok amaçlı işlem kaynağı oluşturmak için:
- Çalışma alanı kenar çubuğunda İşlem'e tıklayın.
- İşlem oluştur düğmesine tıklayın.
- İşlem kaynağını yapılandırın.
- Oluştur’a tıklayın.
Yeni işlem kaynağınız otomatik olarak dönmeye başlar ve kısa süre içinde kullanıma hazır olur.
İşlem ilkesi
İlkeler, kullanıcıların işlem kaynakları oluştururken kullanabilecekleri yapılandırma seçeneklerini sınırlamak için kullanılan bir kural kümesidir. Bir kullanıcının Sınırsız küme oluşturma yetkilendirmesi yoksa, yalnızca verilen ilkelerini kullanarak işlem kaynakları oluşturabilir.
Bir ilkeye göre işlem kaynakları oluşturmak için, İlke açılır menüsünden birini seçin.
Varsayılan olarak, tüm kullanıcılar Kişisel İşlem ilkesine erişebilir ve tek makineli işlem kaynakları oluşturmalarına olanak sağlar. Kişisel İşlem'e veya ek ilkelere erişmeniz gerekiyorsa çalışma alanı yöneticinize ulaşın.
Performans ayarları
Basit form işlem kullanıcı arabiriminin Performans bölümünde aşağıdaki ayarlar görüntülenir:
- Databricks Runtime sürümleri
- Foton hızlandırmayı kullan
- İşçi düğümü türü
- tek düğüm hesaplama
- Otomatik ölçeklendirmeyi etkinleştirme
- Gelişmiş performans ayarları
Databricks Çalışma Zamanı sürümleri
Databricks Runtime, işleminizde çalışan temel bileşenler kümesidir. Databricks Runtime Sürümü açılan menüsünü kullanarak çalışma zamanını seçin. Belirli Databricks Runtime sürümleri hakkında ayrıntılı bilgi için Databricks Runtime sürüm notları ile sürümlerin ve uyumluluğun başlığına bakın. Tüm sürümler Apache Spark içerir. Databricks aşağıdakileri önerir:
- Tüm amaçlı işlemlerde, kodunuzla önceden yüklenmiş paketleriniz arasında en son iyileştirmelere ve en güncel uyumluluğa sahip olduğunuzdan emin olmak için en güncel sürümü kullanın.
- Operasyonel iş yüklerini çalıştıran işlemler için Uzun Vadeli Destek (LTS) Databricks Runtime sürümünü kullanmayı göz önünde bulundurun. LTS sürümünü kullanmak, uyumluluk sorunlarıyla karşılaşmayın ve yükseltmeden önce iş yükünüzü kapsamlı bir şekilde test edebilirsiniz.
- Veri bilimi ve makine öğrenmesi kullanım örnekleri için Databricks Runtime ML sürümünü göz önünde bulundurun.
Foton hızlandırmayı kullanma
Photon, Databricks Runtime 9.1 LTS ve üzerini çalıştıran işlemde varsayılan olarak etkindir.
Foton hızlandırmayı etkinleştirmek veya devre dışı bırakmak için Foton Hızlandırma kullan onay kutusunu seçin. Photon hakkında daha fazla bilgi edinmek için bkz . Photon nedir?.
Çalışan Düğümü Türü
İşlem kaynağı bir sürücü düğümünden ve sıfır veya daha fazla çalışan düğümünden oluşur. Sürücü düğümü varsayılan olarak çalışan düğümüyle aynı örnek türünü kullansa da, sürücü ve çalışan düğümleri için ayrı bulut sağlayıcısı örnek türleri seçebilirsiniz. Sürücü düğümü ayarı, Gelişmiş performans bölümünün altındadır.
Farklı örnek türü aileleri, yoğun bellek kullanan veya işlem yoğunluklu iş yükleri gibi farklı kullanım örneklerine uyar. Çalışan veya sürücü düğümü olarak kullanılacak bir havuz da seçebilirsiniz.
Önemli
Spot örnekler içeren bir havuzu sürücü tipiniz olarak kullanmayın. Sürücünüzün geri alınmasını önlemek için isteğe bağlı bir sürücü türü seçin. Bkz. Havuzlara bağlanma.
Çok düğümlü işlemde, çalışan düğümleri düzgün çalışan bir işlem kaynağı için gereken Spark yürütücülerini ve diğer hizmetleri çalıştırır. İş yükünüzü Spark ile dağıttığınızda dağıtılan işlemlerin tümü çalışan düğümlerinde gerçekleştirilir. Azure Databricks çalışan düğümü başına bir yürütücü çalıştırır. Bu nedenle yürütücü ve çalışan terimleri Databricks mimarisi bağlamında birbirinin yerine kullanılır.
İpucu
Spark işini çalıştırmak için en az bir çalışan düğümüne ihtiyacınız vardır. İşlem kaynağında sıfır çalışan varsa, sürücü düğümünde Spark dışı komutlar çalıştırabilirsiniz, ancak Spark komutları başarısız olur.
Esnek düğüm türleri
Çalışma alanınızda esnek düğüm türleri etkinleştirildiyse işlem kaynağınız için esnek düğüm türlerini kullanabilirsiniz. Esnek düğüm türleri, belirtilen örnek türünüz kullanılamadığında işlem kaynağınızın alternatif, uyumlu örnek türlerine geri dönmesine olanak tanır. Bu davranış, işlem başlatma işlemleri sırasında kapasite hatalarını azaltarak işlem başlatma güvenilirliğini artırır. Bkz . Esnek düğüm türlerini kullanarak işlem başlatma güvenilirliğini geliştirme.
İşçi düğüm IP adresleri
Azure Databricks her biri iki özel IP adresine sahip çalışan düğümlerini başlatır. Azure Databricks'in dahili trafiğini düğümün birincil özel IP adresi barındırır. İkincil özel IP adresi Spark kapsayıcısı tarafından küme içi iletişim için kullanılır. Bu model, Azure Databricks aynı çalışma alanında birden çok işlem kaynağı arasında yalıtım sağlamasına olanak tanır.
GPU örneği türleri
Derin öğrenmeyle ilişkililer gibi yüksek performans gerektiren hesaplama açısından zor görevler için Azure Databricks grafik işleme birimleri (GPU) ile hızlandırılan işlem kaynaklarını destekler. Daha fazla bilgi için bkz . GPU özellikli işlem.
Azure gizli bilgi işlem VM'leri
gizli bilgi işlem VM türleri Azure, bulut operatörü de dahil olmak üzere kullanımda olan verilere yetkisiz erişimi engeller. Bu VM türü, yüksek düzeyde düzenlenmiş sektörler ve bölgelerin yanı sıra bulutta hassas verilere sahip işletmeler için yararlıdır. Azure gizli bilgi işlem hakkında daha fazla bilgi için bkz. Azure gizli bilgi işlem.
Azure gizli bilgi işlem VM'lerini kullanarak iş yüklerinizi çalıştırmak için çalışan ve sürücü düğümü açılır listelerindeki DC veya EC serisi VM türleri arasından seçim yapın. Bkz. Azure Gizli VM seçenekleri.
tek düğümlü hesaplama
Tek düğüm onay kutusu, tek düğüm işlem kaynağı oluşturmanıza olanak tanır.
Tek düğümlü işlem, az miktarda veri veya tek düğümlü makine öğrenmesi kitaplıkları gibi dağıtılmış olmayan iş yükleri kullanan işler için tasarlanmıştır. Dağıtılmış iş yüklerine sahip daha büyük işler için çok düğümlü işlem kullanılmalıdır.
Tek Düğüm Özellikleri
Tek düğüm işlem kaynağı aşağıdaki özelliklere sahiptir:
- Spark'ı yerel olarak çalıştırır.
- Sürücü, işçi düğümler olmadan hem ana hem de işçi olarak işlev görür.
- Bilgisayar kaynağındaki her mantıksal çekirdek için bir yürütücü iş parçacığı oluşturur, sürücü için 1 çekirdek eksik.
- Tüm
stderr,stdoutvelog4jgünlük çıkışlarını sürücü günlüğüne kaydeder. - Çok düğümlü işlem kaynağına dönüştürülemez.
Tek veya çoklu düğüm seçimi
Tek veya çok düğümlü işlem arasında karar verirken kullanım örneğinizi göz önünde bulundurun:
Büyük ölçekli veri işleme, tek düğümlü işlem kaynağındaki kaynakları tüketecektir. Bu iş yükleri için Databricks çok düğümlü işlem kullanılmasını önerir.
Çok düğümlü işlem kaynağı 0 çalışana ölçeklendirilemez. Bunun yerine tek düğüm hesaplama kullanın.
GPU zamanlaması tek düğüm işlemde etkinleştirilmez.
Tek düğümlü işlemde Spark, UDT sütunu olan Parquet dosyalarını okuyamaz. Aşağıdaki hata iletisi sonuçları:
The Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.Bu sorunu geçici olarak çözmek için yerel Parquet okuyucuyu devre dışı bırakın:
spark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
Otomatik ölçeklendirmeyi etkinleştirme
Otomatik ölçeklendirmeyi etkinleştir seçeneği işaretlendiğinde işlem kaynağı için en az ve en fazla çalışan sayısını sağlayabilirsiniz. Databricks daha sonra işinizi çalıştırmak için gereken uygun sayıda çalışanı seçer.
İşlem kaynağınızın otomatik olarak ölçekleneceği minimum ve maksimum çalışan sayısını ayarlamak için, Çalışan türü açılan listesinin yanındaki En Az ve En Fazla alanlarını kullanın.
Otomatik ölçeklendirmeyi etkinleştirmezseniz, Çalışan türü açılan listesinin yanındaki Çalışanlar alanına sabit sayıda çalışan girmeniz gerekir.
Uyarı
İşlem kaynağı çalışırken, işlem ayrıntıları sayfasında ayrılan çalışanların sayısı görüntülenir. Ayrılan çalışan sayısını çalışan yapılandırmasıyla karşılaştırabilir ve gerektiğinde ayarlamalar yapabilirsiniz.
Otomatik ölçeklendirmenin avantajları
Otomatik ölçeklendirme ile Azure Databricks, çalışanlarınızı işinizin özelliklerini hesaba eklemek için dinamik olarak yeniden ayırır. İşlem hattınızın bazı bölümleri diğerlerinden daha hesaplama açısından daha zorlu olabilir ve Databricks işinizin bu aşamalarında otomatik olarak ek çalışanlar ekler (ve artık gerekli olmadığında bunları kaldırır).
Otomatik ölçeklendirme, bir iş yüküne uygun işlem kaynaklarını sağlamanıza gerek kalmadan yüksek kullanım elde etmeyi daha kolay hale getirir. Bu, özellikle gereksinimleri zaman içinde değişen iş yükleri için geçerlidir (örneğin, bir gün boyunca bir veri kümesini keşfetmek gibi), ancak sağlama gereksinimleri bilinmeyen bir kerelik daha kısa bir iş yükü için de geçerli olabilir. Bu nedenle otomatik ölçeklendirme iki avantaj sunar:
- İş yükleri, sabit boyutlu, az sağlanan işlem kaynağına kıyasla daha hızlı çalışabilir.
- Otomatik ölçeklendirme, statik olarak boyutlandırılmış bir işlem kaynağına kıyasla genel maliyetleri azaltabilir.
İşlem kaynağının ve iş yükünün sabit boyutuna bağlı olarak, otomatik ölçeklendirme size bu avantajlardan birini veya ikisini aynı anda sağlar. İşlem boyutu, bulut sağlayıcısı örnekleri sonlandırdığında seçilen en düşük çalışan sayısının altına inebilir. Azure Databricks, en az çalışan sayısını korumak için örnekleri sürekli olarak yeniden sağlamak amacıyla yeniden denemeler yapar.
Uyarı
spark-submit işleri için otomatik ölçeklendirme kullanılamıyor.
Uyarı
İşlem otomatik ölçeklendirmesi, Yapılandırılmış Akış iş yükleri için küme boyutunu azaltmayla ilgili sınırlamalara sahiptir. Databricks, akış iş yükleri için geliştirilmiş otomatik ölçeklendirme ile Lakeflow üzerinde Spark Bildirimli İşlem Hatlarının kullanılmasını önerir. Bkz. Otomatik ölçeklendirme ile Lakeflow işlem hattı kümesi kullanımını iyileştirme.
Otomatik ölçeklendirmenin davranışı
Premium planındaki çalışma alanı, iyileştirilmiş otomatik ölçeklendirmeyi kullanır. Standart fiyatlandırma planındaki çalışma alanları standart otomatik ölçeklendirmeyi kullanır.
İyileştirilmiş otomatik ölçeklendirme aşağıdaki özelliklere sahiptir:
- En fazla 2 ölçeklendirme olayı içinde en azdan maks'a ölçeklendirilir.
- İşlem kaynağı boşta olmasa bile dosya karıştırma durumuna bakarak ölçeği azaltabilirsiniz.
- Mevcut düğümlerin yüzdesine göre ölçeği küçültür.
- İşle ilgili hesaplamada, hesaplama kaynağı son 40 saniye içinde az kullanıldıysa ölçek küçültülür.
- Tüm amaçlı işlemlerde, eğer işlem kaynağı son 150 saniye içinde az kullanılıyorsa, ölçek küçültülür.
-
spark.databricks.aggressiveWindowDownSSpark yapılandırma özelliği, saniyeler içinde işlem ölçeği azaltma kararları alma sıklıklarını belirtir. Değerin artırılması, işlem ölçeğinin daha yavaş küçültülmesine neden olur. En yüksek değer 600'dür.
Standart otomatik ölçeklendirme, standart plan çalışma alanlarında kullanılır. Standart otomatik ölçeklendirme aşağıdaki özelliklere sahiptir:
- 8 düğüm ekleyerek başlar. Ardından üstel olarak ölçeği büyüterek maksimuma ulaşmak için gereken tüm adımlar atılır.
- Düğümlerin %90'ı 10 dakika boyunca meşgul olmadığında ve hesaplama en az 30 saniyedir boşta kaldığında sistem ölçeği küçültür.
- 1 düğümden başlayarak ölçeği üstel olarak daraltır.
Uyarı
Databricks otomatik ölçeklendirme kullanan işlem kaynaklarında Apache Spark Dinamik Ayırma'yı (spark.dynamicAllocation.enabled) etkinleştirmeyin. Databricks otomatik ölçeklendirme, çalışan düğümlerini ve yürütücü yaşam döngüsünü platform düzeyinde yönetir. Spark Dinamik Ayırma'nın paralel olarak etkinleştirilmesi çakışan ölçeklendirme kararlarına neden olabilir ve yürütücü dönüşüm sıklığına, NODES_LOST hatalara ve hiç başlatılmayan görevlere yol açabilir.
Havuzlar ile otomatik ölçeklendirme
İşlem kaynağınızı bir havuza ekliıyorsanız aşağıdakileri göz önünde bulundurun:
- İstenen hesaplama boyutunun havuzdaki boştaki minimum örnek sayısından küçük veya buna eşit olduğundan emin olun. Daha büyükse, işlem başlatma süresi havuz kullanmayan işlemle eşdeğer olacaktır.
- Maksimum işlem boyutunun havuzun maksimum kapasitesinden küçük veya buna eşit olduğundan emin olun. Daha büyükse hesaplama oluşturma başarısız olur.
Otomatik ölçeklendirme örneği
Statik işlem kaynağını otomatik ölçeklendirme için yeniden yapılandırırsanız, Azure Databricks işlem kaynağını en düşük ve en yüksek sınırlar içinde hemen yeniden boyutlandırır ve ardından otomatik ölçeklendirmeyi başlatır. Örnek olarak, işlem kaynağını 5 ile 10 düğüm arasında otomatik ölçeklendirme için yeniden yapılandırırsanız, aşağıdaki tabloda belirli bir başlangıç boyutuna sahip bir işlem kaynağına ne olacağı gösterilmektedir.
| Başlangıç boyutu | Yeniden yapılandırmadan sonra boyut |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Gelişmiş Performans Ayarları
Aşağıdaki ayar, basit form hesaplama kullanıcı arabiriminde Gelişmiş performans bölümünde görünür.
Spot örnekleri
Maliyetten tasarruf etmek için Spot örnekleri onay kutusunu işaretleyerek, Azure Spot VM'ler olarak da bilinen spot örneklerini kullanmayı seçebilirsiniz.

İlk örnek her zaman isteğe bağlı olacaktır (sürücü düğümü her zaman isteğe bağlıdır) ve sonraki örnekler spot örnekler olacaktır.
Örnekler kullanılamama nedeniyle çıkarılırsa, Azure Databricks çıkarılan örnekleri değiştirmek için yeni spot örnekleri almaya çalışır. Spot örnekler alınamazsa, kaldırılmış örneklerin yerine isteğe bağlı örnekler dağıtılır. Talep üzerine geri döndürme yalnızca tam olarak edinilmiş ve çalışan spot örnekler için desteklenir. Kurulum sırasında başarısız olan spot örnekleri otomatik olarak değiştirilmez.
Ayrıca, mevcut işlem kaynaklarına yeni düğümler eklendiğinde Azure Databricks bu düğümler için spot örnekleri almaya çalışır.
Otomatik sonlandırma
İşlem oluşturma formunun Performans bölümünde işlem için otomatik sonlandırma ayarlayabilirsiniz. İşlem oluşturma sırasında işlem kaynağının sonlandırılmasını istediğiniz işlem dışı süreyi dakika cinsinden belirtin.
İşlem kaynağındaki geçerli saat ve son komut çalıştırması arasındaki fark belirtilen etkinlik dışı süreden fazlaysa, Azure Databricks bu işlem kaynağını otomatik olarak sonlandırır. İşlem sonlandırma hakkında daha fazla bilgi için bkz . İşlemi sonlandırma.
Sürücü türü
Gelişmiş performans bölümünün altında sürücü türünü seçebilirsiniz. Sürücü düğümü, işlem kaynağına bağlı tüm not defterlerinin durum bilgilerini korur. Sürücü düğümü ayrıca SparkContext'i korur, işlem kaynağındaki bir not defterinden veya kitaplıktan çalıştırdığınız tüm komutları yorumlar ve Spark yürütücüleriyle koordine olan Apache Spark yöneticisini çalıştırır.
Sürücü düğümü türünün varsayılan değeri çalışan düğümü türününkiyle aynıdır. Spark çalışanlarından çok fazla veri almayı ve bunları not defterinde analiz etmeyi collect() planlıyorsanız daha fazla belleğe sahip daha büyük bir sürücü düğümü türü seçebilirsiniz.
İpucu
Sürücü düğümü ekli not defterlerinin tüm durum bilgilerini koruduğundan, kullanılmayan not defterlerini sürücü düğümünden ayırdığından emin olun.
Etiketler
Etiketler, kuruluşunuzdaki çeşitli gruplar tarafından kullanılan işlem kaynaklarının maliyetini kolayca izlemenizi sağlar. İşlem oluştururken etiketleri anahtar-değer çiftleri olarak belirtin ve Azure Databricks bu etiketleri VM'ler ve disk birimleri gibi bulut kaynaklarına ve Databricks kullanım günlüklerine uygular.
Havuzlardan başlatılan işlem için özel etiketler yalnızca DBU kullanım raporlarına uygulanır ve bulut kaynaklarına yayılmaz.
Havuz ve işlem etiketi türlerinin birlikte nasıl çalıştığı hakkında ayrıntılı bilgi için bkz. Kullanımı öznitelikleyip izlemek için etiketleri kullanma
Bilgisayar kaynağınıza etiket eklemek için:
- Etiketler bölümünde, her özel etiket için bir anahtar-değer çifti ekleyin.
- Ekle'yi tıklatın.
Gelişmiş ayarlar
Basit form işlem kullanıcı arabiriminin Gelişmiş bölümünde aşağıdaki ayarlar gösterilir:
- Erişim modları
- Otomatik ölçeklendirme yerel depolamayı etkinleştir
- yerel disk şifreleme
- Spark yapılandırması
- İşlem günlüğü teslim
- Hesaplama birimine SSH erişimi
- Ortam değişkenleri
Erişim modları
Erişim modu, işlem kaynağını kimlerin kullanabileceğini ve işlem kaynağını kullanarak erişebilecekleri verileri belirleyen bir güvenlik özelliğidir. Azure Databricks'daki her işlem kaynağının bir erişim modu vardır. Erişim modu ayarları, basit form işlem kullanıcı arabiriminin gelişmiş bölümünde bulunur.
Erişim modu seçimi varsayılan olarak Otomatik, bu da seçtiğiniz Databricks Runtime'a göre erişim modunun sizin için otomatik olarak seçildiği anlamına gelir. Makine öğrenmesi çalışma zamanı, GPU örneği türü veya 14.3'ten küçük bir Databricks Runtime seçilmediği sürece otomatik olarak varsayılan olarak Standart kullanılır. Bu durumda Ayrılmış kullanılır.
Databricks, gerekli işlevselliğiniz desteklenmediği sürece standart erişim modunu kullanmanızı önerir.
| Erişim Modu | Description | Desteklenen Diller |
|---|---|---|
| Standart | Kullanıcılar arasında veri yalıtımı olan birden çok kullanıcı tarafından kullanılabilir. | Python, SQL, Scala |
| Dedicated | Tek bir kullanıcı veya grup tarafından atanabilir ve kullanılabilir. | Python, SQL, Scala, R |
Bu erişim modlarının her biri için işlevsellik desteği hakkında ayrıntılı bilgi için bkz. Standart işlem gereksinimleri ve sınırlamaları ile Ayrılmış işlem gereksinimleri ve sınırlamaları.
Uyarı
Databricks Runtime 13.3 LTS ve üzerinde, başlatma betikleri ve kitaplıkları tüm erişim modları tarafından desteklenir. Gereksinimler ve destek düzeyleri farklılık gösterir. Bkz. Başlatma betikleri nereye kurulabilir? ve İşlem kapsamlı kütüphaneler.
Yerel depolamayı otomatik ölçeklendirmeyi etkinleştirme
Genellikle belirli bir işin ne kadar disk alanı alacağını tahmin etmek zor olabilir. Azure Databricks, oluşturma sırasında bilgisayarınıza kaç gigabaytlık yönetilen disk eklemeniz gerektiğini tahmin etmek zorunda kalmamanız için tüm Azure Databricks işlemlerinde yerel depolamanın otomatik ölçeklenmesini etkinleştirir.
Yerel depolamayı otomatik ölçeklendirme ile Azure Databricks, işleminizin Spark çalışanlarında kullanılabilir boş disk alanı miktarını izler. Bir çalışan diskte çok az çalışmaya başlarsa Databricks, disk alanı dolmadan önce çalışana otomatik olarak yeni bir yönetilen disk ekler. Diskler, sanal makine başına toplam 5 TB disk alanı sınırına (sanal makinenin ilk yerel depolama alanı dahil) bağlanır.
Bir sanal makineye bağlı yönetilen diskler, yalnızca sanal makine Azure'a döndürüldüğünde ayrılır. Yani, yönetilen diskler çalışan bir işlem parçası oldukları sürece hiçbir zaman bir sanal makineden ayrılmaz. yönetilen disk kullanımının ölçeğini küçültmek için Azure Databricks bu özelliğin autoscaling compute veya automatic termination ile yapılandırılmış işlemde kullanılmasını önerir.
Yerel disk şifrelemesi
Önemli
Bu özellik Genel Önizlemededir.
İşlemi çalıştırmak için kullandığınız bazı örnek türlerinde yerel olarak bağlı diskler olabilir. Azure Databricks karışık verileri veya kısa ömürlü verileri bu yerel olarak eklenmiş disklerde depolar. İşlem kaynağınızın yerel disklerinde geçici olarak depolanan karıştırma verileri de dahil olmak üzere bekleyen tüm verilerin tüm depolama türleri için şifrelendiğinden emin olmak için yerel disk şifrelemesini etkinleştirebilirsiniz.
Önemli
Şifrelenmiş verileri yerel birimlerden okuma ve yazmanın performans üzerindeki etkisi nedeniyle iş yüklerinizin hızı azalabilir.
Yerel disk şifrelemesi etkinleştirildiğinde, Azure Databricks her işlem düğümü için benzersiz olan ve yerel disklerde depolanan tüm verileri şifrelemek için kullanılan bir şifreleme anahtarı oluşturur. Anahtarın kapsamı her işlem düğümü için yereldir ve işlem düğümünün kendisiyle birlikte yok edilir. Anahtar, kullanım ömrü boyunca şifreleme ve şifre çözme için bellekte bulunur ve diskte şifrelenmiş olarak depolanır.
Yerel disk şifrelemesini etkinleştirmek için Kümeler API'sini kullanmanız gerekir. Hesaplama oluşturma veya düzenleme sırasında enable_local_disk_encryption öğesini true olarak ayarlayın.
Spark yapılandırması
Spark işlerine ince ayar yapmak için özel Spark yapılandırma özellikleri sağlayabilirsiniz.
Uyarı
Databricks Runtime 19 ve üzeri sürümlerin standart erişim modunda bazı Spark yapılandırma özellikleri kısıtlanır. Kısıtlı bir özelliği ayarlayan bir küme oluşturma veya düzenleme işlemi hatayla başarısız oluyor. Bkz. Spark yapılandırma sınırlamaları.
İşlem yapılandırması sayfasında Gelişmiş anahtarına tıklayın.
Spark sekmesine tıklayın.
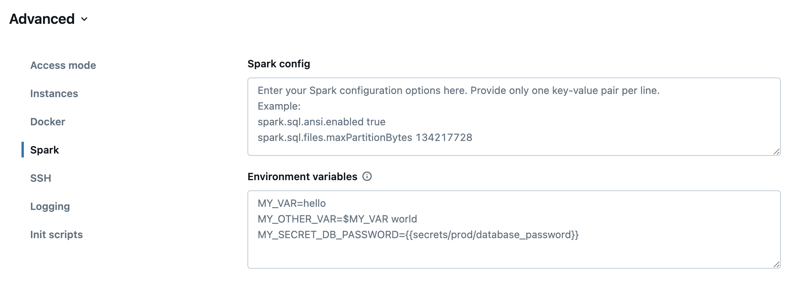
Spark yapılandırmasında yapılandırma özelliklerini satır başına bir anahtar-değer çifti olarak girin.
Kümeler API'sini kullanarak işlem yapılandırdığınızda, küme oluşturma API'sindeki veya Kümeyi güncelleştir API'sindekispark_confalanda Spark özelliklerini ayarlayın.
İşlemde Spark yapılandırmalarını zorunlu kılmak için çalışma alanı yöneticileri işlem ilkelerini kullanabilir.
Gizli veriden Spark yapılandırma özelliğini al
Databricks, parolalar gibi hassas bilgilerin düz metin yerine gizli dizide depolanmasını önerir. Spark yapılandırma içerisinde gizli anahtara başvurmak için aşağıdaki söz dizimini kullanın.
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Örneğin, password içinde depolanan gizli değeri secrets/acme_app/password olarak adlandırılan bir Spark yapılandırma özelliğine ayarlamak için:
spark.password {{secrets/acme-app/password}}
Daha fazla bilgi için Gizli bilgileri yönetme kısmına bakın.
Günlük teslimatını hesapla
Tüm amaçlı veya işler için hesaplama oluşturduğunuzda, Spark sürücüsü, çalışan düğümleri ve olaylardan gelen günlükler dahil olmak üzere küme günlükleri için bir konum belirleyebilirsiniz. Günlükler beş dakikada bir teslim edilir ve seçtiğiniz hedefte saatlik olarak arşivlenir. Databricks, işlem kaynağı sonlandırılana kadar günlükleri sunmaya devam eder.
Günlükleri aşağıdaki konumlardan birinde depolayabilirsiniz:
- Birimler (önerilir): Günlükleri Unity Catalog hacim yolunda depolar. Unity Kataloğu etkin işlem kaynakları kullanılırken önerilen ve en güvenli seçenek budur.
- DBFS (eski): Günlükleri Databricks Dosya Sistemi (DBFS) yolunda depolar. Bu seçenek yalnızca çalışma alanı için DBFS kök dizini ve bağlamalar devre dışı bırakılmadığında kullanılabilir. Var olan Azure Databricks çalışma alanınızdaki DBFS köküne ve bağlamalara erişimi devre dışı bırakmaya bakın.
Kayıt teslim konumunu yapılandırmak için:
- İşlem sayfasında gelişmiş iki durumlu düğmesine tıklayın.
- Kayıt sekmesine tıklayın.
- Bir hedef türü seçin.
- Günlük yolunugirin.
Databricks günlükleri depolamak için, seçtiğiniz günlük yolunda işlem cluster_idadını taşıyan bir alt klasör oluşturur.
Örneğin, belirtilen günlük yolu /Volumes/catalog/schema/volumeise, 06308418893214 günlükleri /Volumes/catalog/schema/volume/06308418893214'e teslim edilir.
Uyarı
Günlüklerin bir birime teslim edilmesi yalnızca Standart erişim modu veya kullanıcıya atanmış olan Ayrılmış erişim modu ile Unity Catalog etkinleştirilmiş hesaplamada desteklenir. Bir gruba atanmış Ayrılmış erişim modu ile desteklenmez. Yol olarak bir birim seçerseniz, bilgisayarın sahibi veya kendisine atanan kullanıcının, birim üzerinde hem READ VOLUME hem de WRITE VOLUME izinlerine sahip olduğunu doğrulayın. Bkz. Unity Kataloğu birimleri için ayrıcalıklar.
İşlem için SSH erişimi
Güvenlik nedeniyle, Azure Databricks SSH bağlantı noktası varsayılan olarak kapatılır. Spark kümelerinize SSH erişimini etkinleştirmek istiyorsanız, Sürücü düğümüne SSH konusuna bkz.
Uyarı
SSH yalnızca çalışma alanınız kendi Azure sanal ağınızda dağıtıldığında etkinleştirilebilir.
Ortam değişkenleri
İşlem kaynağında çalışan başlatma betiklerinden erişebileceğiniz özel ortam değişkenlerini yapılandırın. Databricks, başlatma betiklerinde kullanabileceğiniz önceden tanımlanmış ortam değişkenleri de sağlar. Önceden tanımlanmış bu ortam değişkenlerini geçersiz kılamazsınız.
Uyarı
Databricks Runtime 19 ve üzeri sürümlerin standart erişim modunda Spark altyapısı ve başlatma betikleri için yalnızca önceden tanımlanmış bir ortam değişkenleri kümesi kullanılabilir. Bir kümede ayarladığınız diğer değişkenler, UDF'ler de dahil olmak üzere kullanıcı kodunuz tarafından kullanılabilir durumda kalır. Bkz . Ortam değişkeni sınırlamaları.
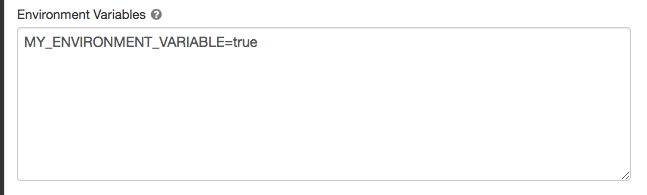
İşlem yapılandırması sayfasında Gelişmiş'e tıklayın.
Spark sekmesine tıklayın.
ortam değişkenlerini Ortam değişkenleri alanında ayarlayın.
Ortam değişkenlerini küme oluşturma API'sindeki spark_env_vars veya Kümeyi güncelleştir API'sindekialanı kullanarak da ayarlayabilirsiniz.