Apache Kafka ve Azure Databricks ile akış işleme
Bu makalede, Azure Databricks'te Yapılandırılmış Akış iş yüklerini çalıştırırken Apache Kafka'nın kaynak veya havuz olarak nasıl kullanılabileceği açıklanmaktadır.
Daha fazla Kafka için Kafka belgelerine bakın.
Kafka'dan veri okuma
Aşağıda Kafka'dan okunan bir akış örneği verilmiştir:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
Azure Databricks, aşağıdaki örnekte gösterildiği gibi Kafka veri kaynakları için toplu okuma semantiğini de destekler:
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
Artımlı toplu yükleme için Databricks, kafka'nın ile kullanılmasını Trigger.AvailableNowönerir. Bkz . Artımlı toplu işlemeyi yapılandırma.
Databricks Runtime 13.3 LTS ve üzerinde Azure Databricks, Kafka verilerini okumak için bir SQL işlevi sağlar. SQL ile akış yalnızca Delta Live Tablolarında veya Databricks SQL'deki akış tablolarında desteklenir. Bkz. tablo değerli işlevi read_kafka.
Kafka Yapılandırılmış Akış okuyucusu yapılandırma
Azure Databricks, Kafka 0.10+ ile bağlantıları yapılandırmak için veri biçimi olarak anahtar sözcüğünü sağlar kafka .
Kafka için en yaygın yapılandırmalar şunlardır:
Abone olunacak konuları belirtmenin birden çok yolu vardır. Şu parametrelerden yalnızca birini sağlamanız gerekir:
| Seçenek | Value | Açıklama |
|---|---|---|
| abone olma | Virgülle ayrılmış konu listesi. | Abone olunacak konu listesi. |
| subscribePattern | Java regex dizesi. | Konulara abone olmak için kullanılan desen. |
| atamak | JSON dizesi {"topicA":[0,1],"topic":[2,4]}. |
Kullanılacak belirli konu Bölümleri. |
Diğer önemli yapılandırmalar:
| Seçenek | Değer | Varsayılan Değer | Açıklama |
|---|---|---|---|
| kafka.bootstrap.servers | Virgülle ayrılmış host:port listesi. | empty | [Gerekli] Kafka bootstrap.servers yapılandırması. Kafka'dan veri olmadığını fark ederseniz, önce aracı adres listesini denetleyin. Aracı adres listesi yanlışsa herhangi bir hata olmayabilir. Bunun nedeni Kafka istemcisinin aracıların sonunda ve ağ hataları durumunda sonsuza kadar yeniden deneneceğini varsayıyor olmasıdır. |
| failOnDataLoss | true veya false. |
true |
[İsteğe bağlı] Verilerin kaybolması mümkün olduğunda sorgunun başarısız olup olmayacağı. Silinen konular, işlenmeden önce konu kesilmesi gibi birçok senaryo nedeniyle sorgular Kafka'dan verileri kalıcı olarak okuyamaz. Verilerin kaybedilip kaybedilmeyeceğini büyük ölçüde tahmin etmeye çalışıyoruz. Bazen bu hatalı alarmlara neden olabilir. Bu seçeneği false , beklendiği gibi çalışmıyorsa veya veri kaybına rağmen sorgunun işlemeye devam etmesi istiyorsanız olarak ayarlayın. |
| minPartitions | Tamsayı >= 0, 0 = devre dışı. | 0 (devre dışı) | [İsteğe bağlı] Kafka'dan okunacak en az bölüm sayısı. Spark'ı Kafka'dan minPartitions okumak için rastgele bir bölüm alt sınırı kullanacak şekilde yapılandırabilirsiniz. Normalde Spark'ta Kafka konu bölümlerinin Kafka'dan tüketen Spark bölümlerine 1-1 eşlemesi vardır. Seçeneğini Kafka topicPartitions değerinden minPartitions daha büyük bir değere ayarlarsanız Spark, büyük Kafka bölümlerini daha küçük parçalara böler. Bu seçenek yoğun yükleme, veri dengesizliği ve işleme hızını artırmak için akışınız geride kaldığı için ayarlanabilir. Her tetikleyicide Kafka tüketicilerini başlatmanın bir maliyeti vardır. Bu, Kafka'ya bağlanırken SSL kullanıyorsanız performansı etkileyebilir. |
| kafka.group.id | Kafka tüketici grubu kimliği. | ayarlanmadı | [İsteğe bağlı] Kafka'dan okurken kullanılacak grup kimliği. Bunu dikkatli kullanın. Varsayılan olarak, her sorgu verileri okumak için benzersiz bir grup kimliği oluşturur. Bu, her sorgunun başka bir tüketicinin girişimiyle karşılaşmayan kendi tüketici grubuna sahip olmasını sağlar ve bu nedenle abone olunan konuların tüm bölümlerini okuyabilir. Bazı senaryolarda (örneğin Kafka grup tabanlı yetkilendirme), verileri okumak için belirli yetkili grup kimliklerini kullanmak isteyebilirsiniz. İsteğe bağlı olarak grup kimliğini ayarlayabilirsiniz. Ancak, bunu beklenmeyen davranışlara neden olabileceğinden çok dikkatli olun. - Aynı grup kimliğine sahip eşzamanlı olarak çalıştırılan sorgular (hem toplu hem de akış), büyük olasılıkla her sorgunun verilerin yalnızca bir bölümünü okumasına neden olur. - Bu durum, sorgular hızlı bir şekilde başlatıldığında/yeniden başlatıldığında da oluşabilir. Bu tür sorunları en aza indirmek için Kafka tüketici yapılandırmasını session.timeout.ms çok küçük olarak ayarlayın. |
| startingOffsets | en erken , en son | latest | [İsteğe bağlı] Sorgunun başlatıldığı başlangıç noktası, en erken uzaklıklardan gelen "en erken" veya her TopicPartition için başlangıç uzaklığını belirten bir json dizesi. Json'da,-2 bir uzaklık olarak en eskiye,-1'den en sona başvurmak için kullanılabilir. Not: Toplu sorgular için en son (örtük olarak veya json'da -1 kullanılarak) izin verilmez. Akış sorguları için bu yalnızca yeni bir sorgu başlatıldığında geçerlidir ve bu devam etme işlemi her zaman sorgunun kaldığı yerden devam eder. Sorgu sırasında yeni bulunan bölümler en erken başlar. |
Diğer isteğe bağlı yapılandırmalar için bkz . Yapılandırılmış Akış Kafka Tümleştirme Kılavuzu .
Kafka kayıtları şeması
Kafka kayıtlarının şeması şöyledir:
| Sütun | Tür |
|---|---|
| anahtar | ikili |
| değer | ikili |
| topic | Dize |
| partition | int |
| fark | uzun |
| timestamp | uzun |
| timestampType | int |
key ve value her zaman ile bayt dizileri olarak seri durumdan ByteArrayDeserializerçıkarılır. Anahtarları ve değerleri açıkça seri durumdan çıkarmak için DataFrame işlemlerini (örneğin cast("string")) kullanın.
Kafka'ya veri yazma
Aşağıda Kafka'ya akış yazma örneği verilmiştir:
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
Azure Databricks, aşağıdaki örnekte gösterildiği gibi Kafka veri havuzlarına toplu yazma semantiğini de destekler:
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
Kafka Yapılandırılmış Akış yazıcısını yapılandırma
Önemli
Databricks Runtime 13.3 LTS ve üzeri, kitaplığın kafka-clients varsayılan olarak etkili yazmaları etkinleştiren daha yeni bir sürümünü içerir. Kafka havuzu yapılandırılmış ACL'ler ile 2.8.0 veya sonraki bir sürümü kullanıyorsa ancak etkinleştirilmediyse IDEMPOTENT_WRITE yazma işlemi hata iletisiyle org.apache.kafka.common.KafkaException: Cannot execute transactional method because we are in an error statebaşarısız olur.
Kafka sürüm 2.8.0 veya üzeri sürüme yükselterek veya Yapılandırılmış Akış yazıcınızı yapılandırırken ayarlayarak .option(“kafka.enable.idempotence”, “false”) bu hatayı düzeltin.
DataStreamWriter'a sağlanan şema Kafka havuzuyla etkileşim kurar. Aşağıdaki alanları kullanabilirsiniz:
| Sütun adı | Gerekli veya isteğe bağlı | Tür |
|---|---|---|
key |
isteğe bağlı | STRING veya BINARY |
value |
gerekli | STRING veya BINARY |
headers |
isteğe bağlı | ARRAY |
topic |
isteğe bağlı (yazıcı seçeneği olarak ayarlanırsa topic yoksayılır) |
STRING |
partition |
isteğe bağlı | INT |
Kafka'ya yazarken ayarlanan yaygın seçenekler şunlardır:
| Seçenek | Değer | Varsayılan değer | Açıklama |
|---|---|---|---|
kafka.boostrap.servers |
Virgülle ayrılmış bir liste <host:port> |
yok | [Gerekli] Kafka bootstrap.servers yapılandırması. |
topic |
STRING |
ayarlanmadı | [İsteğe bağlı] Tüm satırların yazılacağı konuyu ayarlar. Bu seçenek, verilerde bulunan tüm konu sütunlarını geçersiz kılar. |
includeHeaders |
BOOLEAN |
false |
[İsteğe bağlı] Kafka üst bilgilerinin satıra eklenip eklenmeyeceği. |
Diğer isteğe bağlı yapılandırmalar için bkz . Yapılandırılmış Akış Kafka Tümleştirme Kılavuzu .
Kafka ölçümlerini alma
, ve ölçümleriyle avgOffsetsBehindLatestabone olunan tüm konular arasında akış sorgusunun en son kullanılabilir uzaklık değerinin arkasında olduğu uzaklık sayısının ortalamasını, maxOffsetsBehindLatesten düşük ve minOffsetsBehindLatest en yüksek değerini alabilirsiniz. Bkz . Ölçümleri Etkileşimli Okuma.
Not
Databricks Runtime 9.1 ve üzerinde kullanılabilir.
değerini estimatedTotalBytesBehindLatestinceleyerek abone olunan konu başlıklarından sorgu işleminin kullanmadığı tahmini toplam bayt sayısını alın. Bu tahmin, son 300 saniye içinde işlenen toplu işlemleri temel alır. Tahminin temel aldığı zaman çerçevesi, seçeneği bytesEstimateWindowLength farklı bir değere ayarlanarak değiştirilebilir. Örneğin, 10 dakikaya ayarlamak için:
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
Akışı bir not defterinde çalıştırıyorsanız, akış sorgusu ilerleme durumu panosundaki Ham Veri sekmesinin altında şu ölçümleri görebilirsiniz:
{
"sources" : [ {
"description" : "KafkaV2[Subscribe[topic]]",
"metrics" : {
"avgOffsetsBehindLatest" : "4.0",
"maxOffsetsBehindLatest" : "4",
"minOffsetsBehindLatest" : "4",
"estimatedTotalBytesBehindLatest" : "80.0"
},
} ]
}
Azure Databricks'i Kafka'ya bağlamak için SSL kullanma
Kafka'ya SSL bağlantılarını etkinleştirmek için, Ssl ile Şifreleme ve Kimlik Doğrulaması Confluent belgelerindeki yönergeleri izleyin. Burada açıklanan yapılandırmaları seçenekler olarak ön ekli kafka.olarak sağlayabilirsiniz. Örneğin, özelliğinde kafka.ssl.truststore.locationgüven deposu konumunu belirtirsiniz.
Databricks size şu önerileri önerir:
- Sertifikalarınızı bulut nesne depolama alanında depolayın. Sertifikalara erişimi yalnızca Kafka'ya erişebilen kümelerle kısıtlayabilirsiniz. Bkz. Unity Kataloğu ile veri idaresi.
- Sertifika parolalarınızı gizli dizi kapsamında depolayın.
Aşağıdaki örnek, SSL bağlantısını etkinleştirmek için nesne depolama konumlarını ve Databricks gizli dizilerini kullanır:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
HDInsight üzerinde Kafka'yı Azure Databricks'e bağlama
HDInsight Kafka kümesi oluşturun.
Yönergeler için bkz. Azure Sanal Ağ aracılığıyla HDInsight üzerinde Kafka'ya bağlanma.
Kafka aracılarını doğru adresi tanıtacak şekilde yapılandırın.
Kafka'yı IP reklamları için yapılandırma başlığındaki yönergeleri izleyin. Kafka'yı Azure Sanal Makineler'da kendiniz yönetiyorsanız, aracıların yapılandırmasının konakların iç IP'sine ayarlandığından emin olun
advertised.listeners.Azure Databricks kümesi oluşturun.
Kafka kümesini Azure Databricks kümesiyle eşleyin.
Eş sanal ağlar başlığındaki yönergeleri izleyin.
Microsoft Entra Kimliği ve Azure Event Hubs ile Hizmet Sorumlusu kimlik doğrulaması
Azure Databricks, Event Hubs hizmetleriyle Spark işlerinin kimlik doğrulamasını destekler. Bu kimlik doğrulaması Microsoft Entra Id ile OAuth aracılığıyla yapılır.
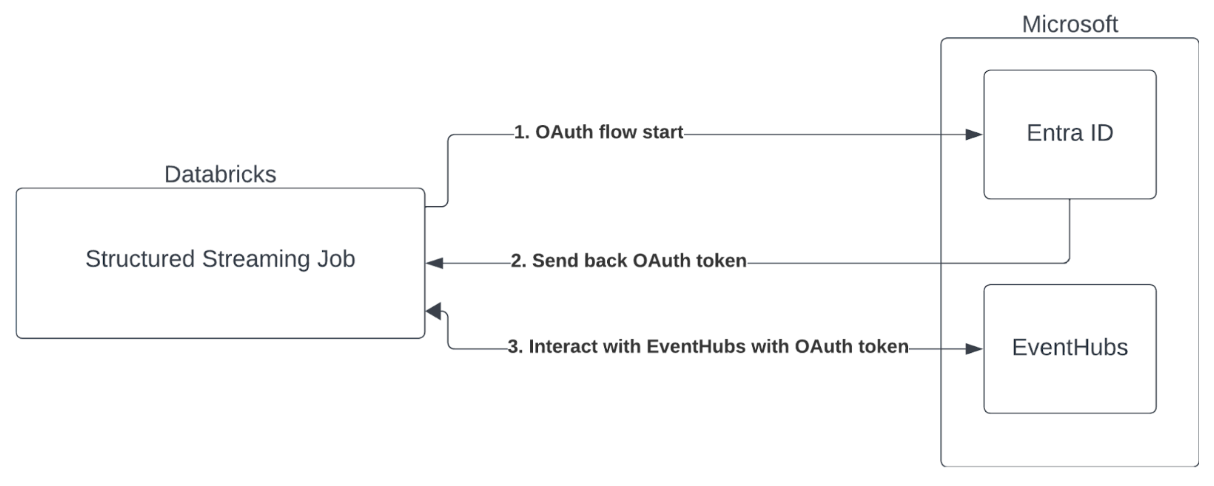
Azure Databricks, aşağıdaki işlem ortamlarında istemci kimliği ve gizli dizi ile Microsoft Entra Id kimlik doğrulamasını destekler:
- Tek kullanıcı erişim moduyla yapılandırılmış işlemde Databricks Runtime 12.2 LTS ve üzeri.
- Paylaşılan erişim moduyla yapılandırılmış işlemde Databricks Runtime 14.3 LTS ve üzeri.
- Unity Kataloğu olmadan yapılandırılan Delta Live Tables işlem hatları.
Azure Databricks, herhangi bir işlem ortamında veya Unity Kataloğu ile yapılandırılmış Delta Live Tables işlem hatlarında bir sertifikayla Microsoft Entra ID kimlik doğrulamasını desteklemez.
Bu kimlik doğrulaması paylaşılan kümelerde veya Unity Kataloğu Delta Live Tablolarında çalışmaz.
Yapılandırılmış Akış Kafka Bağlayıcısını Yapılandırma
Microsoft Entra Id ile kimlik doğrulaması gerçekleştirmek için aşağıdaki değerlere ihtiyacınız vardır:
Kiracı kimliği. Bunu Microsoft Entra Id services sekmesinde bulabilirsiniz.
Bir clientID (Uygulama Kimliği olarak da bilinir).
Bir gizli dizi. Bunu aldıktan sonra Databricks Çalışma Alanınıza gizli dizi olarak eklemeniz gerekir. Bu gizli diziyi eklemek için bkz . Gizli dizi yönetimi.
Bir EventHubs konusu. Belirli bir Event Hubs Ad Alanı sayfasındaki Varlıklar bölümünün altındaki Event Hubs bölümünde konuların listesini bulabilirsiniz. Birden çok konu başlığıyla çalışmak için IAM rolünü Event Hubs düzeyinde ayarlayabilirsiniz.
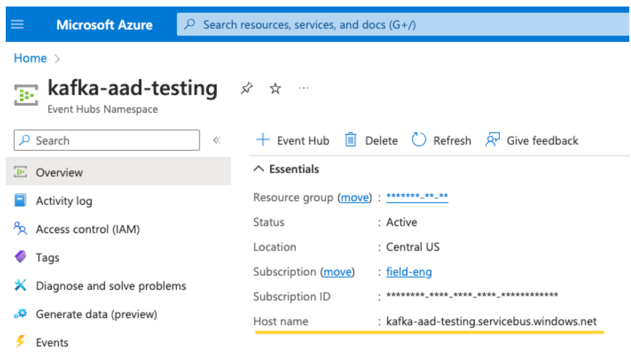
EventHubs sunucusu. Bunu, belirli Event Hubs ad alanınızın genel bakış sayfasında bulabilirsiniz:
Ayrıca, Entra Kimliğini kullanmak için Kafka'ya OAuth SASL mekanizmasını kullanmasını söylememiz gerekir (SASL genel bir protokoldür ve OAuth bir SASL "mekanizması" türüdür):
kafka.security.protocolOlmalıdırSASL_SSLkafka.sasl.mechanismOlmalıdırOAUTHBEARERkafka.sasl.login.callback.handler.classgölgeli Kafka sınıfımızın oturum açma geri çağırma işleyicisininkafkashadeddeğeri ile Java sınıfının tam adı olmalıdır. Tam sınıf için aşağıdaki örne bakın.
Örnek
Şimdi çalışan bir örneğe bakalım:
Python
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
Scala
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
Olası hataları işleme
Akış seçenekleri desteklenmez.
Bu kimlik doğrulama mekanizmasını Unity Kataloğu ile yapılandırılmış bir Delta Live Tables işlem hattında kullanmayı denerseniz aşağıdaki hatayı alabilirsiniz:
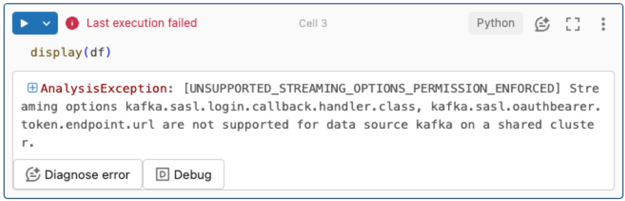
Bu hatayı çözmek için desteklenen bir işlem yapılandırması kullanın. Bkz. Microsoft Entra Id ve Azure Event Hubs ile Hizmet Sorumlusu kimlik doğrulaması.
Yeni
KafkaAdminClientbir oluşturulamadı.Bu, aşağıdaki kimlik doğrulama seçeneklerinden herhangi biri yanlışsa Kafka'nın attığı bir iç hatadır:
- İstemci Kimliği (Uygulama Kimliği olarak da bilinir)
- Kiracı kimliği
- EventHubs sunucusu
Hatayı çözmek için bu seçenekler için değerlerin doğru olduğunu doğrulayın.
Ayrıca, örnekte varsayılan olarak sağlanan yapılandırma seçeneklerini değiştirirseniz (değiştirmemenizi istenirse) bu hatayı görebilirsiniz. Örneğin
kafka.security.protocol.Döndürülen kayıt yok
DataFrame'inizi görüntülemeye veya işlemeye çalışıyor ancak sonuç almıyorsanız, kullanıcı arabiriminde aşağıdakileri görürsünüz.
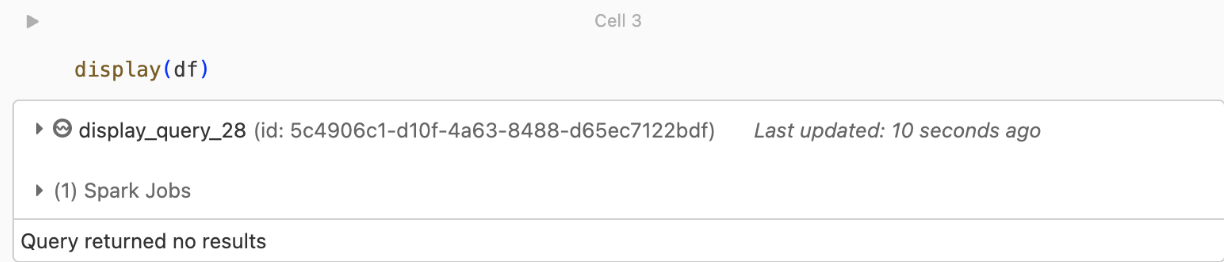
Bu ileti, kimlik doğrulamasının başarılı olduğu ancak EventHubs'ın veri döndürmediğini gösterir. Bazı olası nedenler (hiçbir şekilde kapsamlı olmasa da) şunlardır:
- Yanlış EventHubs konusunu belirttiniz.
- için
startingOffsetsvarsayılan Kafka yapılandırma seçeneği şeklindedirlatestve şu anda konu başlığı üzerinden herhangi bir veri alamayabilirsiniz. Kafka'nın en eski uzaklıklarından başlayarak verileri okumaya başlayacak şekilde ayarlayabilirsinizstartingOffsetstoearliest.