Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Önemli
Yeni kullanım örnekleri için Databricks aracı kodu, sunucu yapılandırması ve dağıtım iş akışı üzerinde tam denetim için Databricks Uygulamalarına aracı dağıtmanızı önerir. Bkz. Bir yapay zeka aracısı yazma ve Databricks Uygulamalarında dağıtma.
Bu sayfada, Agent Framework ve LangGraph ve OpenAI gibi popüler aracı yazma kitaplıklarını kullanarak Python'da yapay zeka aracısı yazma gösterilmektedir.
Gereksinimler
Tavsiye
Databricks, aracı geliştirirken MLflow Python istemcisinin en son sürümünün yüklenmesini önerir.
Bu sayfadaki yaklaşımı kullanarak aracıları yazmak ve dağıtmak için aşağıdakileri yükleyin:
-
databricks-agents1.2.0 veya üzeri -
mlflow3.1.3 veya üzeri - Python 3.10 veya üzeri.
- Bu gereksinimi karşılamak için sunucusuz işlem veya Databricks Runtime 13.3 LTS veya üzerini kullanın.
%pip install -U -qqqq databricks-agents mlflow
Databricks ayrıca aracıları yazmak için Databricks AI Köprüsü tümleştirme paketlerinin yüklenmesini önerir. Bu tümleştirme paketleri, aracı yazma çerçeveleri ve SDK'lar arasında Databricks AI/BI Genie ve Vektör Arama gibi Databricks yapay zeka özellikleriyle etkileşim kuran paylaşılan bir API katmanı sağlar.
OpenAI
%pip install -U -qqqq databricks-openai
LangChain/LangGraph
%pip install -U -qqqq databricks-langchain
DSPy
%pip install -U -qqqq databricks-dspy
Saf Python aracıları
%pip install -U -qqqq databricks-ai-bridge
Aracıları oluşturmak için ResponsesAgent kullanın
Databricks, üretim sınıfı aracılar oluşturmak için MLflow arabirimini ResponsesAgent önerir.
ResponsesAgent ajanları herhangi bir üçüncü taraf çerçevesiyle oluşturmanıza ve ardından güçlü günlüğe kaydetme, izleme, değerlendirme, dağıtım ve izleme yetenekleri için Databricks AI'nin özellikleriyle entegre etmenize olanak tanır.
Şema ResponsesAgent OpenAI Responses şemasıyla uyumludur. OpenAI Responseshakkında daha fazla bilgi edinmek için bkz . OpenAI: Yanıtlar ve ChatCompletion.
Uyarı
Databricks'te eski ChatAgent arabirim hala desteklenmektedir. Ancak Databricks, yeni aracılar için MLflow'un en son sürümünü ve arabirimini ResponsesAgent kullanmanızı önerir.

ResponsesAgent aşağıdaki avantajları sağlar:
Gelişmiş ajan yetenekleri
- Çok aracılı destek
- Akış çıkışı: Çıkışı daha küçük öbekler halinde akışla aktarın.
- Kapsamlı araç arama ileti geçmişi: Gelişmiş kalite ve konuşma yönetimi için ara araç arama iletileri de dahil olmak üzere birden çok ileti döndürebilirsiniz.
- Araç çağırma onayı desteği
- Uzun süre çalışan araç desteği
Kolaylaştırılmış geliştirme, dağıtım ve izleme
- Herhangi bir çerçeve kullanarak aracılar yazma: Mevcut herhangi bir aracı, kullanıcıya hazır uyumluluk sağlamak amacıyla AI Playground, Aracı Değerlendirmesi ve Aracı İzleme ile arabirim kullanarak sarmalayın.
- Yazılan yazma arabirimleri: IDE ve not defteri otomatik tamamlama özelliğinden yararlanarak, yazılan Python sınıflarını kullanarak aracı kodu yazın.
-
Otomatik imza çıkarımı: MLflow, aracı günlüğe kaydetme sırasında imzaları otomatik olarak çıkararak
ResponsesAgentkaydı ve dağıtımı basitleştirir. Bkz. Günlükleme sırasında Model İmzasını Çıkart. -
Otomatik izleme: MLflow,
predictvepredict_streamişlevlerinizi otomatik olarak izler, akışlı yanıtları toplayarak daha kolay değerlendirme ve görüntüleme sağlar. - AI Gateway ile geliştirilmiş çıkarım tabloları: AI Gateway çıkarım tabloları dağıtılan aracılar için otomatik olarak etkinleştirilir ve ayrıntılı istek günlüğü meta verilerine erişim sağlar.
ResponsesAgent nasıl oluşturulacağını öğrenmek için, aşağıdaki bölümde yer alan örneklere ve MLflow dökümantasyonu - Model Sunumu için ResponsesAgent'a bakın.
ResponsesAgent Örnekler
Aşağıdaki not defterlerinde popüler kitaplıkları kullanarak akış ve akış dışı ResponsesAgent işlemlerinin nasıl yazılacağı gösterilmektedir. Bu aracıların özelliklerini genişletmeyi öğrenmek için bkz. Yapay zeka aracısı araçları.
OpenAI
Databricks tarafından barındırılan modelleri kullanarak OpenAI basit sohbet aracısı
OpenAI MCP araç çağırma aracısı
Databricks tarafından barındırılan modelleri kullanan OpenAI araç çağırma aracısı
OpenAI tarafından barındırılan modelleri kullanan OpenAI araç çağırma aracısı
LangGraph
LangGraph MCP araç çağırma aracısı
DSPy
DSPy tek dönüşlü araç çağırma aracısı
Çok aracılı örnek
Çok aracılı sistem oluşturmayı öğrenmek için bkz. Çok aracılı sistemlerde Genie kullanma (Model Sunma).
Durumlu ajan örneği
Lakebase'i bellek deposu olarak kullanarak kısa süreli ve uzun süreli belleğe sahip durum bilgisi olan aracılar oluşturmayı öğrenmek için bkz. Yapay zeka aracısı belleği (Model Sunma).
Konuşmasız ajan örneği
Çok aşamalı diyalogları yöneten konuşma aracılarından farklı olarak, konuşma dışı aracılar iyi tanımlanmış görevleri verimli bir şekilde yürütmeye odaklanır. Bu kolaylaştırılmış mimari, bağımsız istekler için daha yüksek aktarım hızı sağlar.
Konuşma dışı aracı oluşturmayı öğrenmek için bkz. MLflow kullanarak konuşma dışı yapay zeka aracıları.
Ya zaten bir temsilcim varsa?
Zaten LangChain, LangGraph veya benzer bir çerçeveyle oluşturulmuş bir aracınız varsa, aracınızı Databricks'te kullanmak için yeniden yazmanız gerekmez. Bunun yerine, mevcut aracınızı MLflow ResponsesAgent arabirimiyle sarmalamanız gerekir:
öğesinden
mlflow.pyfunc.ResponsesAgentdevralan bir Python sarmalayıcı sınıfı yazın.Sarmalayıcı sınıfının içinde, mevcut ajana bir öznitelik
self.agent = your_existing_agentolarak başvurun.ResponsesAgentsınıfı, akış olmayan talepleri işlemek için birpredictyöntemi ve birResponsesAgentResponsedöndüren bir uygulama gerektirir. Şemanın bir örneği aşağıda verilmiştirResponsesAgentResponses:import uuid # input as a dict {"input": [{"role": "user", "content": "What did the data scientist say when their Spark job finally completed?"}]} # output example ResponsesAgentResponse( output=[ { "type": "message", "id": str(uuid.uuid4()), "content": [{"type": "output_text", "text": "Well, that really sparked joy!"}], "role": "assistant", }, ] )işlevinde
predictgelen iletileriResponsesAgentRequestaracının beklediği biçime dönüştürün. Aracı bir yanıt oluşturduktan sonra çıkışını birResponsesAgentResponsenesneye dönüştürün.
Mevcut aracıların ResponsesAgent'e nasıl dönüştürüleceğini görmek için aşağıdaki kod örneklerine bakın.
Temel dönüştürme
Akışsız aracılar için, predict fonksiyonundaki girdileri ve çıktıları dönüştürün.
from uuid import uuid4
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
)
class MyWrappedAgent(ResponsesAgent):
def __init__(self, agent):
# Reference your existing agent
self.agent = agent
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
# Convert incoming messages to your agent's format
# prep_msgs_for_llm is a function you write to convert the incoming messages
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# Call your existing agent (non-streaming)
agent_response = self.agent.invoke(messages)
# Convert your agent's output to ResponsesAgent format, assuming agent_response is a str
output_item = (self.create_text_output_item(text=agent_response, id=str(uuid4())),)
# Return the response
return ResponsesAgentResponse(output=[output_item])
Kod yeniden kullanımıyla akış
Akış aracıları için, iletileri dönüştüren kodun çoğaltılmasını önlemek için akıllı olabilir ve mantığı yeniden kullanabilirsiniz:
from typing import Generator
from uuid import uuid4
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
ResponsesAgentStreamEvent,
)
class MyWrappedStreamingAgent(ResponsesAgent):
def __init__(self, agent):
# Reference your existing agent
self.agent = agent
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
"""Non-streaming predict: collects all streaming chunks into a single response."""
# Reuse the streaming logic and collect all output items
output_items = []
for stream_event in self.predict_stream(request):
if stream_event.type == "response.output_item.done":
output_items.append(stream_event.item)
# Return all collected items as a single response
return ResponsesAgentResponse(output=output_items)
def predict_stream(
self, request: ResponsesAgentRequest
) -> Generator[ResponsesAgentStreamEvent, None, None]:
"""Streaming predict: the core logic that both methods use."""
# Convert incoming messages to your agent's format
# prep_msgs_for_llm is a function you write to convert the incoming messages, included in full examples linked below
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# Stream from your existing agent
item_id = str(uuid4())
aggregated_stream = ""
for chunk in self.agent.stream(messages):
# Convert each chunk to ResponsesAgent format
yield self.create_text_delta(delta=chunk, item_id=item_id)
aggregated_stream += chunk
# Emit an aggregated output_item for all the text deltas with id=item_id
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_text_output_item(text=aggregated_stream, id=item_id),
)
ChatCompletions'tan geçiş
Mevcut aracınız OpenAI ChatCompletions API'sini kullanıyorsa, temel mantığını yeniden yazmadan bunu 'a ResponsesAgent geçirebilirsiniz. Şu şekilde bir sarmalayıcı ekleyin:
- Gelen
ResponsesAgentRequestiletileri aracınızın beklediği biçimeChatCompletionsdönüştürür. - Çıkışları
ChatCompletionsşemayaResponsesAgentResponseçevirir. - İsteğe bağlı olarak, artımlı deltaları
ChatCompletions'denResponsesAgentStreamEventnesnelere eşleyerek akışı destekler.
from typing import Generator
from uuid import uuid4
from databricks.sdk import WorkspaceClient
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
ResponsesAgentStreamEvent,
)
# Legacy agent that outputs ChatCompletions objects
class LegacyAgent:
def __init__(self):
self.w = WorkspaceClient()
self.OpenAI = self.w.serving_endpoints.get_open_ai_client()
def stream(self, messages):
for chunk in self.OpenAI.chat.completions.create(
model="databricks-claude-sonnet-4-5",
messages=messages,
stream=True,
):
yield chunk.to_dict()
# Wrapper that converts the legacy agent to a ResponsesAgent
class MyWrappedStreamingAgent(ResponsesAgent):
def __init__(self, agent):
# `agent` is your existing ChatCompletions agent
self.agent = agent
def prep_msgs_for_llm(self, messages):
# dummy example of prep_msgs_for_llm
# real example of prep_msgs_for_llm included in full examples linked below
return [{"role": "user", "content": "Hello, how are you?"}]
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
"""Non-streaming predict: collects all streaming chunks into a single response."""
# Reuse the streaming logic and collect all output items
output_items = []
for stream_event in self.predict_stream(request):
if stream_event.type == "response.output_item.done":
output_items.append(stream_event.item)
# Return all collected items as a single response
return ResponsesAgentResponse(output=output_items)
def predict_stream(
self, request: ResponsesAgentRequest
) -> Generator[ResponsesAgentStreamEvent, None, None]:
"""Streaming predict: the core logic that both methods use."""
# Convert incoming messages to your agent's format
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# process the ChatCompletion output stream
agent_content = ""
tool_calls = []
msg_id = None
for chunk in self.agent.stream(messages): # call the underlying agent's stream method
delta = chunk["choices"][0]["delta"]
msg_id = chunk.get("id", None)
content = delta.get("content", None)
if tc := delta.get("tool_calls"):
if not tool_calls: # only accommodate for single tool call right now
tool_calls = tc
else:
tool_calls[0]["function"]["arguments"] += tc[0]["function"]["arguments"]
elif content is not None:
agent_content += content
yield ResponsesAgentStreamEvent(**self.create_text_delta(content, item_id=msg_id))
# aggregate the streamed text content
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_text_output_item(agent_content, msg_id),
)
for tool_call in tool_calls:
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_function_call_item(
str(uuid4()),
tool_call["id"],
tool_call["function"]["name"],
tool_call["function"]["arguments"],
),
)
agent = MyWrappedStreamingAgent(LegacyAgent())
for chunk in agent.predict_stream(
ResponsesAgentRequest(input=[{"role": "user", "content": "Hello, how are you?"}])
):
print(chunk)
Tam örnekler için bkz ResponsesAgent . örnekler.
Akış yanıtları
Akış, aracıların yanıtların tamamını beklemek yerine gerçek zamanlı parçalar halinde göndermesine olanak tanır. Akış uygulamak için ResponsesAgent kullanarak bir dizi delta olayını ve son olarak bir tamamlama olayını yayınlayın.
-
Delta olayları yay: Metin öbeklerini gerçek zamanlı olarak akışa almak için aynı
output_text.deltaolan birden çokitem_idolay gönderin. -
Bitti olayıyla bitir: Tam son
response.output_item.doneçıkış metnini içeren delta olaylarıyla aynıitem_idson olayı gönderin.
Her bir delta olayı, istemciye bir metin parçasını akıtır. Son tamamlanan olay, tam yanıt metnini içerir ve Databricks'e aşağıdakileri yapması için sinyal verir:
- MLflow izleme ile aracınızın çıktısını izleyin
- AI Gateway çıkarım tablolarında akışlı yanıtları toplama
- AI Playground kullanıcı arabiriminde tam çıkışı gösterme
Akışta hata yayılımı
Mosaic AI, databricks_output.error altındaki son belirteç ile akış sırasında karşılaşılan hataları yayar. Bu hatayı düzgün bir şekilde işlemek ve ortaya çıkarabilmek çağıran istemciye bağlı.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Gelişmiş özellikler
Özel girişler ve çıkışlar
Bazı senaryolarda, client_type ve session_id gibi ilave aracı girişleri veya gelecekteki etkileşimler için sohbet geçmişine dahil edilmemesi gereken alma kaynağı bağlantıları gibi çıkışlar gerekebilir.
Bu senaryolar için MLflow ResponsesAgentcustom_inputs ve custom_outputsalanlarını yerel olarak destekler. Özel girişlere, yukarıda ResponsesAgent Examples ile bağlantılı tüm örneklerde request.custom_inputs aracılığıyla erişebilirsiniz.
Uyarı
Aracı Değerlendirme gözden geçirme uygulaması, ek giriş alanları olan aracılar için işleme izlemelerini desteklemez.
Özel giriş ve çıkışları ayarlamayı öğrenmek için aşağıdaki not defterlerine bakın.
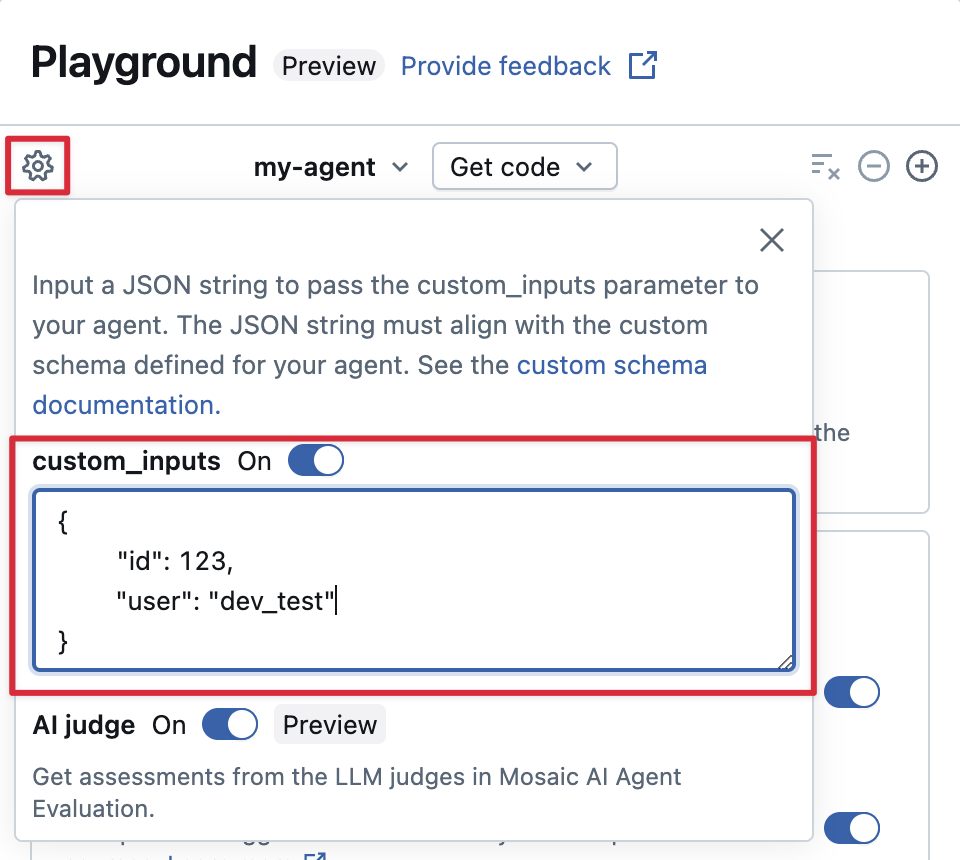
AI Playground'da custom_inputs sağlama ve inceleme yapın
Eğer temsilciniz custom_inputs alanını kullanarak ek girişleri kabul ediyorsa, bu girişleri hem AI Playground hem de inceleme uygulamasında manuel olarak sağlayabilirsiniz.
AI Playground veya Aracı İnceleme Uygulaması'nda dişli simgesini
 seçin.
seçin.özel girişlerietkinleştirin.
Aracınızın tanımlı giriş şemasıyla eşleşen bir JSON nesnesi sağlayın.
Özel retriever şemaları belirtme
Yapay zeka aracıları genellikle vektör arama dizinlerindeki yapılandırılmamış verileri bulmak ve sorgulamak için retriever kullanır. Örneğin retriever araçları için bkz. Aracıları yapılandırılmamış verilere bağlama.
Databricks ürün özelliklerini etkinleştirmek için, MLflow RETRIEVER spans ile bu retriever'ları aracınız içinde izleyin.
- AI Playground kullanıcı arabiriminde alınan kaynak belgelerin bağlantılarını otomatik olarak görüntüleme
- Agent Değerlendirmesi'nde bilgi alma geçerliliği ve ilişkililik değerlendirmelerini otomatik olarak çalıştırma
Uyarı
Databricks, MLflow retriever şemasına zaten uygun olduklarından databricks_langchain.VectorSearchRetrieverTool ve databricks_openai.VectorSearchRetrieverTool gibi Databricks AI Köprüsü paketleri tarafından sağlanan retriever araçlarının kullanılmasını önerir. Bkz. AI Bridgeile Vektör Arama alma araçlarını yerel olarak geliştirme.
Aracınız, özel bir şema ile birlikte veri toplama alanları (retriever spans) içeriyorsa, kodda aracınızı tanımlarken mlflow.models.set_retriever_schema çağrısını yapın. Bu, retriever'ınızın çıkış sütunlarını MLflow'un beklenen alanlarıyla (primary_key, text_column, doc_uri) eşler.
import mlflow
# Define the retriever's schema by providing your column names
# For example, the following call specifies the schema of a retriever that returns a list of objects like
# [
# {
# 'document_id': '9a8292da3a9d4005a988bf0bfdd0024c',
# 'chunk_text': 'MLflow is an open-source platform, purpose-built to assist machine learning practitioners...',
# 'doc_uri': 'https://mlflow.org/docs/latest/index.html',
# 'title': 'MLflow: A Tool for Managing the Machine Learning Lifecycle'
# },
# {
# 'document_id': '7537fe93c97f4fdb9867412e9c1f9e5b',
# 'chunk_text': 'A great way to get started with MLflow is to use the autologging feature. Autologging automatically logs your model...',
# 'doc_uri': 'https://mlflow.org/docs/latest/getting-started/',
# 'title': 'Getting Started with MLflow'
# },
# ...
# ]
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="mlflow_docs_vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="document_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="chunk_text",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
# Specify any other columns returned by the retriever
other_columns=["title"],
)
Uyarı
doc_uri sütunu, özellikle retriever'ın performansını değerlendirirken önemlidir.
doc_uri, retriever tarafından döndürülen belgelerin ana tanımlayıcısıdır ve bunları gerçek değerlendirme kümeleriyle karşılaştırmanıza olanak sağlar. Bkz . Değerlendirme kümeleri (MLflow 2).
Dağıtımla ilgili dikkat edilmesi gerekenler
Databricks Model Sunumu için hazırlanma
Databricks, Databricks Model Hizmet'te dağıtılmış bir ortamda modelleri ResponsesAgent konuşlandırır. Bu, dönüşlü bir konuşma sırasında aynı hizmet veren çoğaltmanın tüm istekleri işleyemeyebileceği anlamına gelir. Ajan durumunu yönetirken aşağıdaki çıkarımları dikkate alın:
Yerel önbelleğe almaktan kaçının:
ResponsesAgentdağıtırken, aynı kopyanın birden fazla turdan oluşan konuşmadaki tüm istekleri işlediğini varsaymayın. Her dönüş için bir sözlükResponsesAgentRequestşeması kullanarak iç durumu yeniden oluştur.İş parçacığı güvenli durumu: Aracı durumunu iş parçacığı açısından güvenli olacak şekilde tasarlayın ve çoklu iş parçacıklı ortamlardaki çakışmaları önleyin.
Durumu
predictfonksiyonunda başlat:predictbaşlatma sırasında değil,ResponsesAgentfonksiyonu her çağrıldığında durumu başlat. Tek birResponsesAgentçoğaltması birden çok konuşmadan gelen istekleri işleyebileceğinden, durumuResponsesAgentdüzeyinde depolamak konuşmalar arasında bilgi sızıntısına ve çakışmalara neden olabilir.
Farklı ortamlarda dağıtım için kodun parametrelendirilmesi
Farklı ortamlarda aynı aracı kodunu yeniden kullanmak için aracı kodunu parametrize edin.
Parametreler, Python sözlüğünde veya .yaml dosyasında tanımladığınız anahtar-değer çiftleridir.
Kodu yapılandırmak için Python sözlüğü veya .yaml dosyasını kullanarak bir ModelConfig oluşturun.
ModelConfig, esnek yapılandırma yönetimine olanak tanıyan bir anahtar-değer parametreleri kümesidir. Örneğin, geliştirme sırasında bir sözlük kullanabilir ve ardından bunu üretim dağıtımı ve CI/CD için .yaml dosyasına dönüştürebilirsiniz.
Aşağıda örnek bir ModelConfig gösterilmiştir:
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-meta-llama-3-3-70b-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
Aracı kodunuzda, .yaml dosyasından veya sözlüğünden varsayılan (geliştirme) yapılandırmasına başvurabilirsiniz:
import mlflow
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-meta-llama-3-3-70b-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
# You can also use model_config.to_dict() to convert the loaded config object
# into a dictionary
value = model_config.get('sample_param')
Ardından, aracınızı kaydederken, kaydedilmiş aracı yüklerken kullanılacak özel bir parametre kümesi belirtmek için model_config parametresini log_model olarak ayarlayın. MLflow belgelerine bakınız - ModelConfig
Senkron kod veya geri çağırma desenleri kullanın
Kararlılığı ve uyumluluğu sağlamak için aracı uygulamanızda zaman uyumlu kod veya geri çağırma tabanlı desenler kullanın.
Azure Databricks, aracı dağıttığınızda en iyi eşzamanlılığı ve performansı sağlamak için zaman uyumsuz iletişimi otomatik olarak yönetir. Özel olay döngüleri veya zaman uyumsuz çerçevelerin tanıtılması, RuntimeError: This event loop is already running and caused unpredictable behavior gibi hatalara neden olabilir.
Azure Databricks, aracı geliştirirken asenkron programlamadan kaçınmanızı (örneğin, asyncio kullanmak veya özel olay döngüleri oluşturmak) önerir.