Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede, Mozaik Yapay Zeka Vektör Aramakullanarak bir vektör arama dizini oluşturma ve sorgulama açıklanmaktadır.
Kullanıcı arabirimini, Python SDK'sınıveya REST APIkullanarak vektör arama uç noktası ve vektör arama dizinleri gibi vektör arama bileşenleri oluşturabilir ve yönetebilirsiniz.
Gereksinimler
- Unity Kataloğu ile etkinleştirilmiş çalışma alanı.
- Sunucusuz işlem etkinleştirildi. Yönergeler için Sunucusuz Bilişime Bağlantı Kurma başlığına bakın.
- Standart uç noktalar için kaynak tabloda Veri Akışını Değiştir etkinleştirilmelidir. Bkz Azure Databricks'te Delta Lake değişiklik veri akışını kullanma.
- Vektör arama dizini oluşturmak için, dizinin oluşturulacağı katalog şemasında CREATE TABLE ayrıcalıklarınız olmalıdır.
- Başka bir kullanıcıya ait bir dizini sorgulamak için ek ayrıcalıklara sahip olmanız gerekir. Bir vektör arama uç noktasını sorgula'yı gör.
Vektör arama uç noktalarını oluşturma ve yönetme izni, erişim denetim listeleri kullanılarak yapılandırılır. "Bkz. Vector search endpoint ACL’leri."
Kurulum
Vektör arama SDK'sını kullanmak için bunu not defterinize yüklemeniz gerekir. Paketi yüklemek için aşağıdaki kodu kullanın:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
Ardından VectorSearchClientiçeri aktarmak için aşağıdaki komutu kullanın:
from databricks.vector_search.client import VectorSearchClient
Kimlik doğrulama
Bkz. Veri koruma ve kimlik doğrulaması.
Vektör arama uç noktası oluşturma
Databricks kullanıcı arabirimini, Python SDK'sını veya API'yi kullanarak vektör arama uç noktası oluşturabilirsiniz.
Kullanıcı arabirimini kullanarak vektör arama uç noktası oluşturma
Kullanıcı arabirimini kullanarak vektör arama uç noktası oluşturmak için bu adımları izleyin.
Sol kenar çubuğunda İşlemöğesine tıklayın.
Vektör Arama sekmesine tıklayın ve Oluşturöğesine tıklayın.

Oluştur uç nokta formu açılır. Bu uç nokta için bir ad girin.
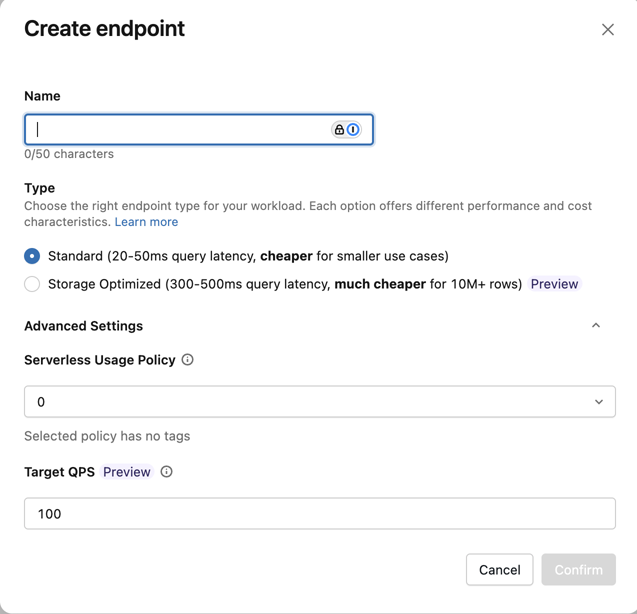
Tür alanında Standart veya Depolama için İyileştirilmiş'i seçin. Bkz . Uç nokta seçenekleri.
(İsteğe bağlı) Gelişmiş ayarlar'ın altında bir bütçe ilkesi seçin. Bkz . Mozaik AI Vektör Araması: Bütçe ilkeleri.
Onayla'yı tıklatın.
Python SDK'sını kullanarak vektör arama uç noktası oluşturma
Aşağıdaki örnekte vektör arama uç noktası oluşturmak için create_endpoint() SDK işlevi kullanılmaktadır.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
REST API kullanarak vektör arama uç noktası oluşturma
REST API başvuru belgelerine bakın: POST /api/2.0/vector-search/endpoints.
(İsteğe bağlı) Ekleme modeline hizmet vermek için uç nokta oluşturma ve yapılandırma
Databricks'in eklemeleri hesaplamasını seçerseniz, önceden yapılandırılmış bir Temel Model API'leri uç noktasını kullanabilir veya tercih ettiğiniz ekleme modeline hizmet vermek için uç nokta sunan bir model oluşturabilirsiniz. Talimatlar için Jeton Başına Ödeme Temelli Model API'leri veya Temel model sunum uç noktalarını oluşturma kısmına bakın. Örnek defterler için bir gömme modelini çağırma için defter örnekleri bölümüne bakın.
Yerleştirme uç noktasını yapılandırırken, Databricks Sıfıra ölçekle varsayılan seçimini kaldırmanızı önerir. Uç noktaların ısınması birkaç dakika sürebilir ve ölçeği küçültülmüş bir uç noktaya sahip bir dizinde ilk sorgu zaman aşımına uğrayabilir.
Uyarı
Gömme uç noktası, veri kümesi için uygun şekilde yapılandırılmamışsa vektör arama dizini başlatma zaman aşımına uğrayabilir. Cpu uç noktalarını yalnızca küçük veri kümeleri ve testler için kullanmanız gerekir. Daha büyük veri kümeleri için en iyi performans için bir GPU uç noktası kullanın.
Vektör arama dizini oluşturma
Kullanıcı arabirimini, Python SDK'sını veya REST API'yi kullanarak vektör arama dizini oluşturabilirsiniz. Kullanıcı arabirimi en basit yaklaşımdır.
İki tür dizin vardır:
- Delta Eşitleme Dizini, delta tablosundaki temel veriler değiştikçe dizini otomatik olarak ve artımlı olarak güncelleştirerek bir kaynak Delta Tablosu ile otomatik olarak eşitlenir.
- Doğrudan Vektör Erişim Dizini vektörlerin ve meta verilerin doğrudan okunmasını ve yazmasını destekler. Kullanıcı, REST API veya Python SDK'sını kullanarak bu tabloyu güncelleştirmekle sorumludur. Bu dizin türü kullanıcı arabirimi kullanılarak oluşturulamaz. REST API'sini veya SDK'sını kullanmanız gerekir.
Uyarı
Sütun adı _id rezerve edilmiştir. Kaynak tablonuzda _id adlı bir sütun varsa, bir vektör arama indeksi oluşturmadan önce adını değiştirin.
Kullanıcı arabirimini kullanarak dizin oluşturma
Sol kenar çubuğunda Katalog Gezgini kullanıcı arabirimini açmak için Katalog 'e tıklayın.
Kullanmak istediğiniz Delta tablosuna gidin.
Sağ üst köşedeki Oluştur düğmesine tıklayın ve açılan menüden Vektör arama dizini öğesini seçin.
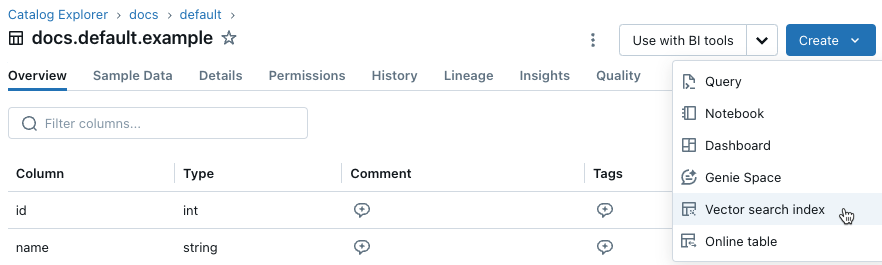
dizini yapılandırmak için iletişim kutusundaki seçicileri kullanın.
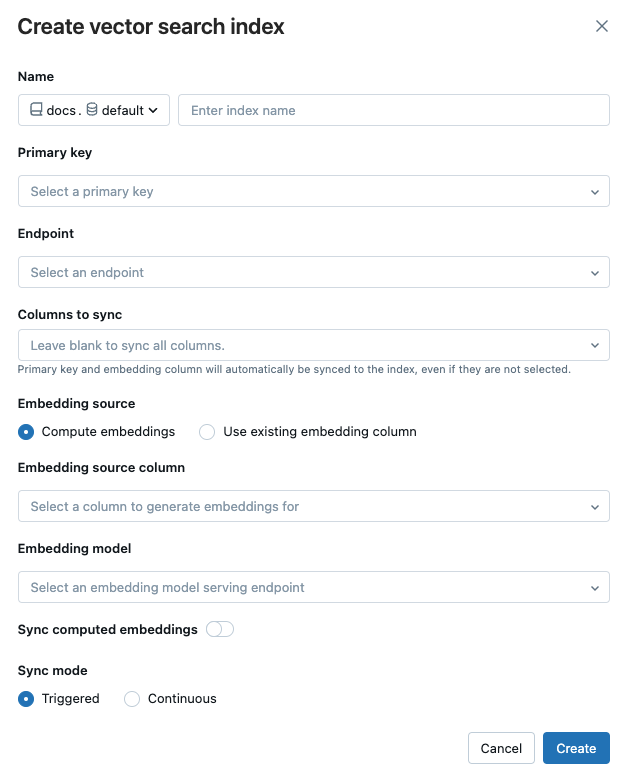
Adı: Unity Kataloğu'ndaki çevrimiçi tablo için kullanılacak ad. İsim,
<catalog>.<schema>.<name>şeklinde üç katmanlı bir ad alanı gerektirir. Yalnızca alfasayısal karakterlere ve alt çizgilere izin verilir.Birincil anahtar: Birincil anahtar olarak kullanılacak sütun.
uç nokta : Kullanmak istediğiniz vektör arama uç noktasını seçin.
Eşitlenecek sütunlar: (Yalnızca standart uç noktalar için desteklenir.) Vektör diziniyle eşitlenecek sütunları seçin. Bu alanı boş bırakırsanız, kaynak tablodaki tüm sütunlar dizinle eşitlenir. Birincil anahtar sütunu ile gömme kaynak sütunu veya gömme vektör sütunu sürekli olarak senkronize edilir. Depolama için iyileştirilmiş uç noktalar için kaynak tablodaki tüm sütunlar her zaman eşitlenir.
Ekleme kaynağı: Databricks'in Delta tablosundaki bir metin sütunu için eklemeleri hesaplamasını isteyip istemediğinizi (İşlem eklemeleri) veya Delta tablonuzun önceden derlenmiş eklemeler içerip içermediğini belirtin (Var olan ekleme sütununu kullan).
-
İşlem eklemeleriseçtiyseniz, eklemelerin hesaplanmasını istediğiniz sütunu ve ekleme modeline hizmet veren uç noktayı seçin. Yalnızca metin sütunları desteklenir. Büyük ölçekli ekleme oluşturma için Databricks, daha yüksek aktarım hızı için belirteç başına ödeme temel modelinin
databricks-gte-large-enkullanılmasını önerir. -
Var olan ekleme sütununu kullanseçeneğini belirlediyseniz, önceden derlenmiş eklemeleri ve ekleme boyutunu içeren sütunu seçin. Önceden derlenmiş ekleme sütununun biçimi
array[float]olmalıdır. Depolama için iyileştirilmiş uç noktalar için ekleme boyutunun 16'ya kadar eşit şekilde bölünebilmesi gerekir.
Hesaplanan eklemeleri eşitle: Oluşturulan eklemeleri bir Unity Kataloğu tablosuna kaydetmek için bu ayarı değiştirin. Daha fazla bilgi için bkz. Oluşturulan gömme tablosunu kaydetme.
Eşitleme modu: Sürekli, dizini saniyelik gecikmeyle eşitlenmiş durumda tutar. Ancak, sürekli eşitleme akışı işlem hattını çalıştırmak için bir işlem kümesi sağlandığından onunla ilişkili maliyeti daha yüksektir. Standart uç noktalar için hem Sürekli hem de Tetiklenen artımlı güncelleştirmeler gerçekleştirir, bu nedenle yalnızca son eşitleme işleminden sonra değişen veriler işlenir. Depolama için iyileştirilmiş uç noktalar için her eşitleme vektör arama dizinini tamamen yeniden oluşturur. Bkz . Depolama için iyileştirilmiş uç nokta sınırlamaları.
Tetiklenen eşitleme moduyla, eşitlemeyi başlatmak için Python SDK'sını veya REST API'yi kullanırsınız. Bkz. Delta Eşitleme Dizinigüncelleştirme.
Depolama için iyileştirilmiş uç noktalar için yalnızca Tetiklenen eşitleme modu desteklenir.
-
İşlem eklemeleriseçtiyseniz, eklemelerin hesaplanmasını istediğiniz sütunu ve ekleme modeline hizmet veren uç noktayı seçin. Yalnızca metin sütunları desteklenir. Büyük ölçekli ekleme oluşturma için Databricks, daha yüksek aktarım hızı için belirteç başına ödeme temel modelinin
Dizini yapılandırmayı bitirdiğinizde Oluşturöğesine tıklayın.
Python SDK'sını kullanarak dizin oluşturma
Aşağıdaki örnek, Databricks tarafından hesaplanan eklemelerle bir Delta Eşitleme Dizini oluşturur. Ayrıntılar için bkz. Python SDK başvurusu.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
Aşağıdaki örnek, kendi kendine yönetilen eklemelerle bir Delta Eşitleme Dizini oluşturur. Bu örnek, dizinde kullanılacak sütunların yalnızca bir alt kümesini seçmek için isteğe bağlı parametre columns_to_sync kullanımını da gösterir.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Varsayılan olarak, kaynak tablodaki tüm sütunlar dizinle eşitlenir.
Standart uç noktalarda, columns_to_sync kullanarak eşitlenecek sütunların bir alt kümesini seçebilirsiniz. Birincil anahtar ve ekleme sütunları her zaman dizine eklenir.
yalnızca öncelikli anahtar ve gömme sütunu ile eşitlemek için, bunları columns_to_sync'de gösterildiği şekilde belirtmeniz gerekir.
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Ek sütunları eşitlemek için bunları gösterildiği gibi belirtin. Birincil anahtarı ve gömme sütununu, her zaman eşleştirildikleri için eklemeniz gerekmez.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
Aşağıdaki örnek bir Doğrudan Vektör Erişim Dizini oluşturur.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
REST API kullanarak dizin oluşturma
REST API başvuru belgelerine bakın: POST /api/2.0/vector-search/indexes.
Oluşturulan ekleme tablosunu kaydetme
Databricks eklemeleri oluşturursa, oluşturulan eklemeleri Unity Kataloğu'ndaki bir tabloya kaydedebilirsiniz. Bu tablo vektör diziniyle aynı şemada oluşturulur ve vektör dizini sayfasından bağlanır.
Tablonun adı, _writeback_tabletarafından eklenen vektör arama dizininin adıdır. İsim düzenlenemez.
Unity Kataloğu'ndaki diğer tablolarda olduğu gibi tabloya erişebilir ve tabloya sorgulayabilirsiniz. Ancak, el ile güncelleştirilmesi amaçlanmadığından tabloyu bırakmamalı veya değiştirmemelisiniz. Dizin silinirse tablo otomatik olarak silinir.
Vektör arama dizinini güncelleştirme
Bir Delta Senkronizasyon Dizinini Güncelleme
Sürekli eşitleme moduyla oluşturulan dizinler, kaynak Delta tablosu değiştiğinde otomatik olarak güncelleştirilir. Tetiklenen eşitleme modunu kullanıyorsanız, kullanıcı arabirimini, Python SDK'sını veya REST API'yi kullanarak eşitlemeyi başlatabilirsiniz.
Databricks kullanıcı arabirimi
Katalog Gezgini'nde vektör arama dizinine gidin.
Genel Bakış sekmesindeki Veri Alma bölümünde Şimdi eşitle'ye tıklayın.
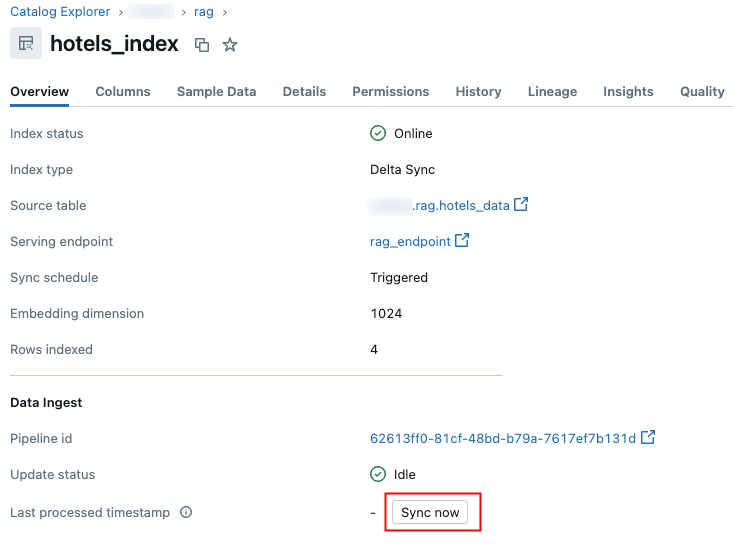 .
.
Python SDK'sı
Ayrıntılar için bkz. Python SDK başvurusu.
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
REST API
REST API başvuru belgelerine bakın: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Doğrudan Vektör Erişim Dizinini Güncelleştirme
Doğrudan Vektör Erişim Dizini'nden veri eklemek, güncelleştirmek veya silmek için Python SDK'sını veya REST API'yi kullanabilirsiniz.
Python SDK'sı
Ayrıntılar için bkz. Python SDK başvurusu.
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
REST API
REST API başvuru belgelerine bakın: POST /api/2.0/vector-search/indexes.
Databricks, üretim uygulamaları için kişisel erişim belirteçleri yerine hizmet sorumlularının kullanılmasını önerir. Performans, sorgu başına 100 msec'e kadar artırılabilir.
Aşağıdaki kod örneği, hizmet sorumlusu kullanarak dizini güncelleştirme işlemini gösterir.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Aşağıdaki kod örneği, kişisel erişim belirteci (PAT) kullanarak dizini güncelleştirme işlemini gösterir.
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
Vektör arama uç noktasını sorgulama
Vektör arama uç noktasını yalnızca Python SDK'sını, REST API'yi veya SQL vector_search() AI işlevini kullanarak sorgulayabilirsiniz.
Uyarı
Uç noktayı sorgulayan kullanıcı vektör arama dizininin sahibi değilse, kullanıcının aşağıdaki UC ayrıcalıklarına sahip olması gerekir:
- Katalogda USE CATALOG, vektör arama dizinini içerir.
- Vektör arama dizinini içeren şemada USE SCHEMA.
- Vektör arama dizininde SELECT.
Varsayılan sorgu türü ( ann yaklaşık en yakın komşudur). Karma anahtar sözcük benzerliği araması yapmak için query_type parametresini hybridolarak ayarlayın. Karma arama ile tüm metin meta veri sütunları dahil edilir ve en fazla 200 sonuç döndürülür.
Python SDK standart uç noktası
Ayrıntılar için bkz. Python SDK başvurusu.
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "field2"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "field2"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.9] * 1024,
columns=["id", "text"],
num_results=2
)
Python SDK depolama için iyileştirilmiş uç nokta
Ayrıntılar için bkz. Python SDK başvurusu.
Mevcut filtre arabirimi, standart vektör arama uç noktalarında kullanılan filtre sözlüğü yerine daha SQL benzeri bir filtre dizesini benimsemek üzere depolama için iyileştirilmiş vektör arama dizinleri için yeniden tasarlanmıştır.
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
# similarity search with query vector
results = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
# similarity search with query vector and filter string
results = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
# this is a single filter string similar to SQL WHERE clause syntax
filters="language = 'en' AND country = 'us'",
num_results=2
)
REST API
REST API başvuru belgelerine bakın: POST /api/2.0/vector-search/indexes/{index_name}/query.
Databricks, üretim uygulamaları için kişisel erişim belirteçleri yerine hizmet sorumlularının kullanılmasını önerir. Geliştirilmiş güvenlik ve erişim yönetimine ek olarak, hizmet sorumlularının kullanılması sorgu başına en fazla 100 msec performansı artırabilir.
Aşağıdaki kod örneği, hizmet sorumlusu kullanarak dizini sorgulamayı gösterir.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint, then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query vector search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query vector search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
Aşağıdaki kod örneği, kişisel erişim belirteci (PAT) kullanarak dizini sorgulamayı gösterir.
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query vector search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query vector search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
Önemli
vector_search() AI işlevi Herkese Açık Önizleme aşamasındadır.
yapay zeka işlevinikullanmak için vector_search işlevine bakınız.
Sorgularda filtre kullanma
Sorgu, Delta tablosundaki herhangi bir sütunu temel alan filtreler tanımlayabilir.
similarity_search yalnızca belirtilen filtrelerle eşleşen satırları döndürür.
Aşağıdaki tabloda desteklenen filtreler listelenmektedir.
| Filtre operatörü | Davranış | Örnekler |
|---|---|---|
NOT |
Standart: Filtreyi olumsuzlar. Anahtar "DEĞİl" ile bitmelidir. Örneğin, "kırmızı" değeriyle "RENK DEĞİL" ifadesi, rengin kırmızı olmadığı belgelerle eşleşir. Depolama için optimize edilmiş: Bkz != (bangeq işareti) işleci. |
Standart: {"id NOT": 2}{“color NOT”: “red”}Depolama için optimize edilmiş: "id != 2" "color != 'red'" |
< |
Standart: Alan değerinin filtre değerinden küçük olup olmadığını denetler. Anahtar " <" ile bitmelidir. Örneğin, 200 değerine sahip "price <", fiyatın 200'den küçük olduğu belgelerle eşleşir. Depolama için iyileştirilmiş: Bkz < . (lt sign) işleci. |
Standart: {"id <": 200}Depolama için optimize edilmiş: "id < 200" |
<= |
Standart: Alan değerinin filtre değerinden küçük veya buna eşit olup olmadığını denetler. Anahtar " <=" ile bitmelidir. Örneğin, 200 değerine sahip "price <=" değeri, fiyatın 200'den küçük veya buna eşit olduğu belgelerle eşleşir. Depolama için iyileştirilmiş: Bkz <= . (lt eq sign) işleci. |
Standart: {"id <=": 200}Depolama için optimize edilmiş: "id <= 200" |
> |
Standart: Alan değerinin filtre değerinden büyük olup olmadığını denetler. Anahtar " >" ile bitmelidir. Örneğin, 200 değerine sahip "price >", fiyatın 200'den büyük olduğu belgelerle eşleşir. Depolama için iyileştirilmiş: Bkz > . (gt işareti) işleci. |
Standart: {"id >": 200}Depolama için optimize edilmiş: "id > 200" |
>= |
Standart: Alan değerinin filtre değerinden büyük veya buna eşit olup olmadığını denetler. Anahtar " >=" ile bitmelidir. Örneğin, 200 değerine sahip "price >=" değeri, fiyatın 200'den büyük veya buna eşit olduğu belgelerle eşleşir. Depolama için optimize edilmiş: Bkz. >= (gt eq sign) operatörü. |
Standart: {"id >=": 200}Depolama için optimize edilmiş: "id >= 200" |
OR |
Standart: Alan değerinin filtre değerlerinden herhangi biri ile eşleşip eşleşmediğini denetler. Anahtar, birden çok alt anahtarı ayırmak için OR içermelidir. Örneğin, değeri color1 OR color2 olan ["red", "blue"], ya color1'nin red olduğu ya da color2'ün blueolduğu belgelerle eşleşir.Depolamaya yönelik optimize edilmiş: Bkz or işleç. |
Standart: {"color1 OR color2": ["red", "blue"]}Depolama için optimize edilmiş: "color1 = 'red' OR color2 = 'blue'" |
LIKE |
Standart: Dizedeki boşlukla ayrılmış belirteçlerle eşleşir. Aşağıdaki kod örneklerine bakın. Depolamaya yönelik optimize edilmiş: Bkz like işleç. |
Standart: {"column LIKE": "hello"}Depolama için optimize edilmiş: "column LIKE 'hello'" |
| Filtre işleci belirtilmedi |
Standart: Filtre tam eşleşmeyi denetler. Birden çok değer belirtilirse, değerlerden herhangi biri ile eşleşir. Depolama için iyileştirilmiş: Bkz = (eq sign) işleci ve in koşulu. |
Standart: {"id": 200}{"id": [200, 300]}Depolama için iyileştirilmiş: "id = 200""id IN (200, 300)" |
to_timestamp (yalnızca depolama için iyileştirilmiş uç noktalar) |
Depolama için iyileştirilmiş: Zaman damgasına göre filtreleyin. Bkz to_timestamp işlev |
Depolama için optimize edilmiş: "date > TO_TIMESTAMP('1995-01-01')" |
Aşağıdaki kod örneklerine bakın:
Python SDK standart uç noktası
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
Python SDK depolama için iyileştirilmiş uç nokta
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters='title IN ("Ares", "Athena")',
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters='title = "Ares" OR id = "Athena"',
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters='title != "Hercules"',
num_results=2
)
REST API
/api/2.0/vector-search/indexes/{index_name}/query için POSTbölümüne bakın.
BEĞEN
LIKE örnekleri
{"column LIKE": "apple"}: "elma" ve "elma armutu" dizeleriyle eşleşir, ancak "ananas" veya "armut" ile eşleşmez. Unutmayın ki "pineapple" ile eşleşmez, çünkü içinde "apple" alt dizesi bulunsa bile, "apple pear" gibi boşlukla ayrılmış dizeler üzerinde tam bir eşleşme arar.
{"column NOT LIKE": "apple"} tersini yapar. "Ananas" ve "armut" ile eşleşir, ancak "elma" veya "elma armutu" ile eşleşmiyor.
Örnek not defterleri
Bu bölümdeki örneklerde vektör arama Python SDK'sının kullanımı gösterilmektedir. Başvuru bilgileri için bkz. Python SDK başvurusu.
LangChain örnekleri
LangChain paketleri ile entegrasyon amacıyla Mozaik AI Vektör Arama'yı kullanmak üzere Mozaik AI Vektör Arama ile LangChain'i Kullanma bölümüne başvurun.
Aşağıdaki not defterinde benzerlik arama sonuçlarınızı LangChain belgelerine nasıl dönüştürdüğünüz gösterilmektedir.
Python SDK not defteriyle vektör araması
Ekleme modelini çağırmak için Not Defteri örnekleri
Aşağıdaki not defterleri, ekleme oluşturma için Mozaik Yapay Zeka Modeli Sunma uç noktasının nasıl yapılandırıldığını gösterir.