Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
İşlem hattı, yalnızca birkaç parametreyle farklılık gösteren, neredeyse aynı olan birden çok akış içerebilir. Bu akışları açıkça tanımlamak hataya açık, yedekli ve bakımı zordur. Python iç işlevlerle meta programlama, dinamik olarak yinelenen akışlar oluşturur ve her çağrı farklı bir parametre kümesi sağlar.
Genel bakış
Lakeflow Spark Bildirimli İşlem Hatlarında meta programlama, Python iç işlevleri kullanır. Bu işlevler işlem hattı çalışma zamanı tarafından gevşek bir şekilde değerlendirildiğinden, dekoratörleri bir fabrika işlevinin içine sarmalayabilir @dp.table ve bu fabrikayı farklı bağımsız değişkenlerle birden çok kez çağırabilirsiniz. Her çağrı, kodu çoğaltmadan yeni bir akış kaydeder.
Lakeflow Spark Bildirimli İşlem Hatları ile döngüleri kullanma for hakkında ayrıntılı bilgi için bkz. Döngüde for tablo oluşturma.
Örnek: İtfaiye yanıt süreleri
Aşağıdaki örnek, her çağrı türü için en hızlı acil durum yanıt sürelerine sahip mahalleleri bulmak için yerleşik itfaiye veri kümesini kullanır. Meta programlama olmadan, her çağrı türü (Alarmlar, Yapı Yangın, Tıbbi Olay) için neredeyse aynı tablo tanımları yazmanız gerekir. Meta programlama ile tek bir fabrika işlevi bunların tümünü oluşturur.
1. Adım: Ham alma tablosunu tanımlama
import functools
from pyspark import pipelines as dp
from pyspark.sql.functions import *
@dp.table(
name="raw_fire_department",
comment="raw table for fire department response"
)
@dp.expect_or_drop("valid_received", "received IS NOT NULL")
@dp.expect_or_drop("valid_response", "responded IS NOT NULL")
@dp.expect_or_drop("valid_neighborhood", "neighborhood != 'None'")
def get_raw_fire_department():
return (
spark.read.format('csv')
.option('header', 'true')
.option('multiline', 'true')
.load('/databricks-datasets/timeseries/Fires/Fire_Department_Calls_for_Service.csv')
.withColumnRenamed('Call Type', 'call_type')
.withColumnRenamed('Received DtTm', 'received')
.withColumnRenamed('Response DtTm', 'responded')
.withColumnRenamed('Neighborhooods - Analysis Boundaries', 'neighborhood')
.select('call_type', 'received', 'responded', 'neighborhood')
)
2. Adım: Akış fabrikası işlevini tanımlama
generate_tables Factory işlevi her çağrı türü için iki tablo kaydeder: filtrelenmiş bir çağrı tablosu ve dereceli yanıt süresi tablosu. Her ikisi de @dp.table ile süslenmiş iç işlevler olarak oluşturulmuştur.
all_tables = []
def generate_tables(call_table, response_table, filter):
@dp.table(
name=call_table,
comment="top level tables by call type"
)
def create_call_table():
return spark.sql("""
SELECT
unix_timestamp(received,'M/d/yyyy h:m:s a') as ts_received,
unix_timestamp(responded,'M/d/yyyy h:m:s a') as ts_responded,
neighborhood
FROM raw_fire_department
WHERE call_type = '{filter}'
""".format(filter=filter))
@dp.table(
name=response_table,
comment="top 10 neighborhoods with fastest response time"
)
def create_response_table():
return spark.sql("""
SELECT
neighborhood,
AVG((ts_received - ts_responded)) as response_time
FROM {call_table}
GROUP BY 1
ORDER BY response_time
LIMIT 10
""".format(call_table=call_table))
all_tables.append(response_table)
3. Adım: Fabrikayı çağırma ve özet tablosunu tanımlama
Her çağrı türü için fabrikayı bir kez çağırın, ardından tüm kategorilerde en sık görünen mahalleleri bulmak için sonuçları bir araya getiren bir özet tablo tanımlayın.
generate_tables("alarms_table", "alarms_response", "Alarms")
generate_tables("fire_table", "fire_response", "Structure Fire")
generate_tables("medical_table", "medical_response", "Medical Incident")
@dp.table(
name="best_neighborhoods",
comment="which neighbor appears in the best response time list the most"
)
def summary():
target_tables = [dp.read(t) for t in all_tables]
unioned = functools.reduce(lambda x, y: x.union(y), target_tables)
return (
unioned.groupBy(col("neighborhood"))
.agg(count("*").alias("score"))
.orderBy(desc("score"))
)
Bu işlem hattını çalıştırdıktan sonra, aşağıdaki grafik gibi benzer tablolardan oluşan bir küme oluşturacaksınız:
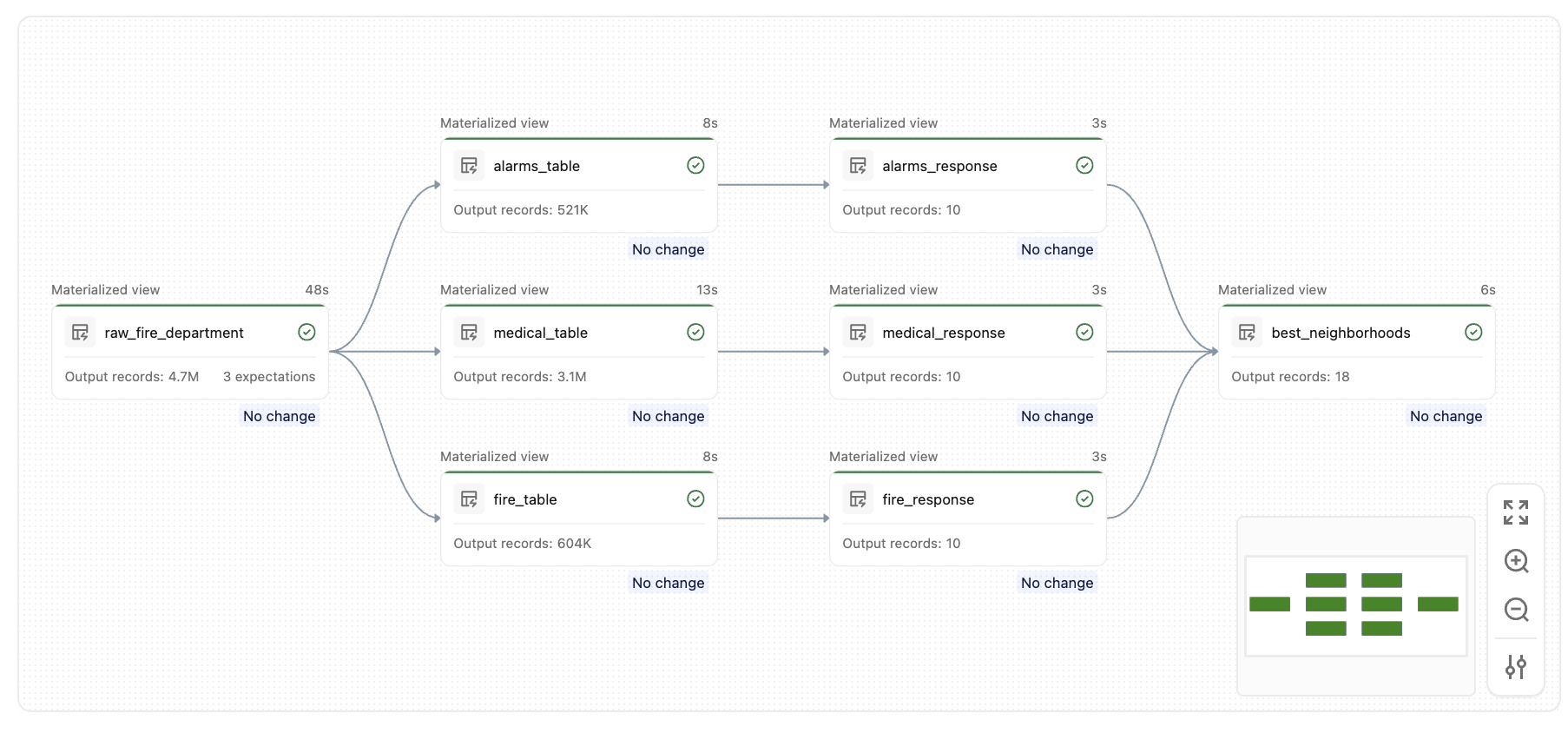
Temel kavramlar
-
İç işlevler gizli olarak kaydedilir:
@dp.tableDekoratör işlevi hemen çalıştırmaz. İşlevi işlem hattı çalışma zamanına kaydeder ve yürütme başlamadan önce tam veri akışı grafiğini çözümler. -
Kapanışlar parametreleri yakalar: Her iç işlev, fabrikaya (
call_table, ,response_table) geçirilen parametreler üzerinden kapanır,filterböylece her kayıtlı akış kendi yalıtılmış değer kümesini kullanır. -
Dinamik tablo listeleri: Programatik olarak oluşturulan tablo adlarını izlemek için
all_tablesgibi bir liste kullanmak, bunlara daha sonra başvurmayı kolaylaştırır (örneğin, birleştirme veya birleşim).
Ek kaynaklar
Python - tablo
- Beklentiler