Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede Azure Databricks'te isteğe bağlı özelliklerin nasıl oluşturulacağı ve kullanılacağı açıklanmaktadır.
İsteğe bağlı özellikleri kullanmak için çalışma alanınızın Unity Kataloğu etkinleştirilmesi ve Databricks Runtime 13.3 LTS ML veya üzerini kullanmanız gerekir.
İsteğe bağlı özellikler nelerdir?
"İsteğe bağlı", değerleri önceden bilinmeyen ancak çıkarım zamanında hesaplanan özellikleri ifade eder. Azure Databricks'te, isteğe bağlı özelliklerin nasıl hesaplandığını belirtmek için Python kullanıcı tanımlı işlevleri (UDF) kullanırsınız. Bu işlevler Unity Kataloğu tarafından yönetilir ve Katalog Gezginiaracılığıyla bulunabilir.
Gereksinimler
- Eğitim kümesi oluşturmak veya bir Özellik Sunma uç noktası oluşturmak için kullanıcı tanımlı bir işlev (UDF) kullanmak için, Unity Catalog'daki katalog üzerinde
USE CATALOGayrıcalığınız ve şema üzerindesystemayrıcalığınız olmalıdır.
İş Akışı
İsteğe bağlı özellikleri hesaplamak için özellik değerlerinin nasıl hesaplandığını açıklayan bir Python kullanıcı tanımlı işlevi (UDF) belirtirsiniz.
- Eğitim sırasında, api parametresinde
feature_lookupscreate_training_setbu işlevi ve giriş bağlamalarını sağlarsınız. - Eğitilen modeli Feature Store yöntemini
log_modelkullanarak günlüğe kaydetmeniz gerekir. Bu, modelin çıkarım için kullanıldığında isteğe bağlı özellikleri otomatik olarak değerlendirmesini sağlar. - Toplu puanlama için,
score_batchAPI'si isteğe bağlı özellikler dahil olmak üzere tüm özellik değerlerini otomatik olarak hesaplar ve döndürür. - Mozaik Yapay Zeka Modeli Sunma özelliğine sahip bir modele hizmet ettiğinizde model, her puanlama isteğinin isteğe bağlı özelliklerini hesaplamak için otomatik olarak Python UDF'yi kullanır.
Python UDF oluşturma
SQL veya Python kodu kullanarak Python UDF oluşturabilirsiniz. tr-TR: Aşağıdaki örnekler, main kataloğunda ve default şemasında bir Python UDF oluşturur.
Piton
Python'ı kullanmak için önce paketi yüklemeniz databricks-sdk[openai] gerekir. Aşağıdaki gibi kullanın %pip install :
%pip install unitycatalog-ai[databricks]
dbutils.library.restartPython()
Ardından python UDF oluşturmak için aşağıdakine benzer bir kod kullanın:
from unitycatalog.ai.core.databricks import DatabricksFunctionClient
client = DatabricksFunctionClient()
CATALOG = "main"
SCHEMA = "default"
def add_numbers(number_1: float, number_2: float) -> float:
"""
A function that accepts two floating point numbers, adds them,
and returns the resulting sum as a float.
Args:
number_1 (float): The first of the two numbers to add.
number_2 (float): The second of the two numbers to add.
Returns:
float: The sum of the two input numbers.
"""
return number_1 + number_2
function_info = client.create_python_function(
func=add_numbers,
catalog=CATALOG,
schema=SCHEMA,
replace=True
)
Databricks SQL (Databricks platformundaki SQL arabirimi)
Aşağıdaki kod, Python UDF oluşturmak için Databricks SQL'in nasıl kullanılacağını gösterir:
%sql
CREATE OR REPLACE FUNCTION main.default.add_numbers(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int:
return n1 + n2
return add_numbers(x, y)
$$
Kodu çalıştırdıktan sonra, işlev tanımını görüntülemek için Katalog Gezgini üç düzeyli ad alanında gezinebilirsiniz:
Katalog Gezgini'nde 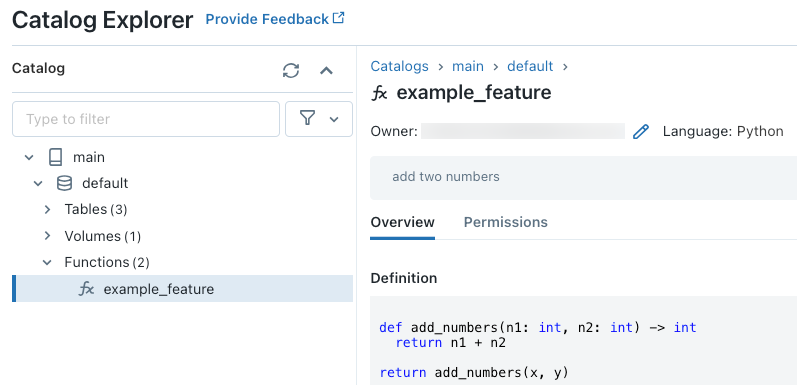
Python UDF'leri oluşturma hakkında daha fazla bilgi için bkz.
Eksik özellik değerlerini işleme
Python UDF bir FeatureLookup'ın sonucuna bağlı olduğunda, istenen arama anahtarı bulunamazsa döndürülen değer ortama bağlıdır. kullanılırken score_batch, döndürülen değer şeklindedir None. Çevrimiçi sunum kullanılırken, döndürülen değer şeklindedir float("nan").
Aşağıdaki kod, her iki durumu da işlemeye yönelik bir örnektir.
%sql
CREATE OR REPLACE FUNCTION square(x INT)
RETURNS INT
LANGUAGE PYTHON AS
$$
import numpy as np
if x is None or np.isnan(x):
return 0
return x * x
$$
İsteğe bağlı özellikleri kullanarak model eğitin
Modeli eğitmek için parametresindeki FeatureFunction API'ye create_training_set geçirilen bir feature_lookupskullanırsınız.
Aşağıdaki örnek kod, önceki bölümde tanımlanan Python UDF'yi main.default.example_feature kullanır.
# Install databricks-feature-engineering first with:
# %pip install databricks-feature-engineering
# dbutils.library.restartPython()
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering import FeatureFunction, FeatureLookup
from sklearn import linear_model
fe = FeatureEngineeringClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureEngineeringClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fe.create_training_set(
df=base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
Varsayılan değerleri belirtme
Özelliklerin varsayılan değerlerini belirtmek için içindeki parametresini default_valuesFeatureLookupkullanın.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
default_values={
"materialized_feature_value": 0
}
)
Özellik sütunları parametresi kullanılarak rename_outputs yeniden adlandırılıyorsa, default_values yeniden adlandırılan özellik adlarını kullanmalıdır.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
rename_outputs={"materialized_feature_value": "feature_value"},
default_values={
"feature_value": 0
}
)
Modeli sisteme kaydedin ve Unity Kataloğu'na ekleyin
Özellik meta verileriyle paketlenen modeller Unity Kataloğu'nakaydedilebilir. Modeli oluşturmak için kullanılan özellik tabloları Unity Kataloğu'nda depolanmalıdır.
Modelin çıkarım için kullanıldığında isteğe bağlı özellikleri otomatik olarak değerlendirdiğinden emin olmak için kayıt defteri URI'sini ayarlamanız ve ardından modeli aşağıdaki gibi günlüğe kaydetmeniz gerekir:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
İsteğe bağlı özellikleri tanımlayan Python UDF herhangi bir Python paketini içeri aktarırsa, bağımsız değişkenini extra_pip_requirementskullanarak bu paketleri belirtmeniz gerekir. Örneğin:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
Sınırlama
İsteğe bağlı özellikler, MapType ve ArrayType dışında Özellik Deposu tarafından desteklenen tüm veri türlerinin çıkışını verebilir.
Not defteri örnekleri: İsteğe bağlı özellikler
Aşağıdaki not defterinde, isteğe bağlı özellik kullanan bir modeli eğitmeye ve puanmaya ilişkin bir örnek gösterilmektedir.
temel isteğe bağlı özellikler tanıtım not defteri
Aşağıdaki not defterinde bir restoran öneri modeli örneği gösterilmektedir. Restoranın konumu Databricks çevrimiçi tablosundan aranır. Kullanıcının geçerli konumu puanlama isteğinin bir parçası olarak gönderilir. Model, kullanıcıdan restorana gerçek zamanlı mesafeyi hesaplamak için isteğe bağlı bir özellik kullanır. Bu uzaklık daha sonra modele giriş olarak kullanılır.