Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
MLflow Modeli , makine öğrenmesi modellerini paketlemek için apache Spark üzerinde toplu çıkarım veya REST API aracılığıyla gerçek zamanlı hizmet sunma gibi çeşitli aşağı akış araçlarında kullanılabilen standart bir biçimdir. biçimi, modeli farklı model sunma ve çıkarım platformları tarafından anlaşılabilen farklı türlerde (python işlevi, pytorch, sklearn vb.) kaydetmenize olanak tanıyan bir kural tanımlar.
Akış modelini günlüğe kaydetmeyi ve puanlamayı öğrenmek için, Akış modelini kaydetme ve yükleme bölümüne bakın.
MLflow 3 , ölçümler ve parametreler gibi kendi meta verilerine sahip yeni, ayrılmış LoggedModel bir nesne sunarak MLflow modellerinde önemli geliştirmeler sunar. Diğer ayrıntılar için bkz. MLflow Günlük Modelleriyle Modelleri İzleme ve Karşılaştırma.
Modelleri kaydetme ve yükleme
Bir modeli günlüğe kaydettiğinizde, MLflow otomatik olarak requirements.txt ve conda.yaml dosyalarını kaydeder. Model geliştirme ortamını yeniden oluşturmak ve (önerilen) veya virtualenvkullanarak conda bağımlılıkları yeniden yüklemek için bu dosyaları kullanabilirsiniz.
Önemli
Anaconda Inc. anaconda.org kanalları için hizmet koşullarını güncelleştirdi. Yeni hizmet koşullarına bağlı olarak, Anaconda'nın paketleme ve dağıtımına güveniyorsanız ticari lisansa ihtiyacınız olabilir. Daha fazla bilgi için Anaconda Ticari Sürüm SSS bölümüne bakın. Herhangi bir Anaconda kanalını kullanımınız, hizmet koşullarına tabidir.
v1.18'den (Databricks Runtime 8.3 ML veya öncesi) önce günlüğe kaydedilen MLflow modelleri, varsayılan olarak bağımlılık olarak conda kanalıyla (defaults) günlüğe kaydediliyordu. Bu lisans değişikliği nedeniyle, Databricks, MLflow v1.18 ve üstü sürümlerle günlüğe kaydedilen modellerin defaults kanalının kullanımını durdurdu. Günlüğe kaydedilen varsayılan kanal artık, topluluk tarafından yönetilen conda-forge öğesine işaret eden https://conda-forge.org/ olarak ayarlanmıştır.
MLflow v1.18'den önce kanalı modelin conda ortamından dışlamadan defaults bir modeli günlüğe kaydetmişseniz, bu modelin defaults kanala yönelik olarak amaçlamadığınız bir bağımlılığı olabilir.
Modelin bu bağımlılıkta olup olmadığını el ile onaylamak için, günlüğe kaydedilen modelle paketlenmiş dosyadaki channel değeri inceleyebilirsinizconda.yaml. Örneğin, conda.yaml için defaults kanal bağımlılığı aşağıdaki gibi görünebilir:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Databricks, Anaconda ile olan ilişkiniz kapsamında Anaconda deposunu kullanarak modellerinizle etkileşim kurmanıza izin verilip verilmeyeceğini belirleyemediğinden, Databricks müşterilerini herhangi bir değişiklik yapmaya zorlamaz. Databricks'in kullanımı aracılığıyla Anaconda.com depoyu kullanımınıza Anaconda'nın koşulları altında izin verilirse herhangi bir işlem yapmanız gerekmez.
Modelin ortamında kullanılan kanalı değiştirmek isterseniz, modeli yeni conda.yaml ile model siciline yeniden kaydedebilirsiniz. Kanalı parametresinde conda_envlog_model()belirterek bunu yapabilirsiniz.
API hakkında log_model() daha fazla bilgi için, üzerinde çalıştığınız model çeşidine ilişkin MLflow belgelerine (örneğin, scikit-learn için log_model) bakın.
Dosyalar hakkında conda.yaml daha fazla bilgi için MLflow belgelerine bakın.
API komutları
Modeli MLflow izleme sunucusuna kaydetmek için kullanın mlflow.<model-type>.log_model(model, ...).
Çıkarım veya daha fazla geliştirme amacıyla önceden kaydedilmiş bir modeli yüklemek için mlflow.<model-type>.load_model(modelpath)kullanın; burada modelpath aşağıdakilerden biridir:
- model yolu (örneğin
models:/{model_id}) (yalnızca MLflow 3 ) - bir run-relative yolu (örneğin
runs:/{run_id}/{model-path}) - Bir Unity Kataloğu birimi yolu (örneğin,
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}gibi) - MLflow tarafından yönetilen,
dbfs:/databricks/mlflow-tracking/ile başlayan bir artefakt depolama yolu - kayıtlı bir model yolu (örneğin
models:/{model_name}/{model_stage}).
MLflow modellerini yükleme seçeneklerinin tam listesi için, MLflow belgelerinde Yapıtlara Başvurmabakın.
Python MLflow modellerinde, modeli genel bir Python işlevi olarak yüklemek için başka bir seçenek de kullanılır mlflow.pyfunc.load_model() .
Modeli yüklemek ve veri puanını almak için aşağıdaki kod parçacığını kullanabilirsiniz.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
Alternatif olarak, modeli bir Spark kümesinde puanlama için kullanmak üzere Apache Spark UDF olarak dışarı aktarabilirsiniz; toplu iş olarak veya gerçek zamanlı Spark Akış işi olarak.
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
Model bağımlılıklarını güncelle.
Modeli doğru bir şekilde yüklemek için, model bağımlılıklarının not defteri ortamına doğru sürümlerle yüklendiğinden emin olmanız gerekir. Databricks Runtime 10.5 ML ve üzerinde, MLflow geçerli ortam ile modelin bağımlılıkları arasında uyuşmazlık algılanırsa sizi uyarır.
Model bağımlılıklarını geri yüklemeyi basitleştirmeye yönelik ek işlevler Databricks Runtime 11.0 ML ve üzeri sürümlerine dahildir. Databricks Runtime 11.0 ML ve üzeri sürümlerde, pyfunc türü modellerin bağımlılıklarını almak ve indirmek için mlflow.pyfunc.get_model_dependencies çağrısını yapabilirsiniz. Bu işlev, kullanarak yükleyebileceğiniz %pip install <file-path> bağımlılıklar dosyasının yolunu döndürür. Bir modeli PySpark UDF olarak yüklediğinizde, env_manager="virtualenv" çağrısında mlflow.pyfunc.spark_udf belirtin. Bu, PySpark UDF bağlamında model bağımlılıklarını geri yükler ve dış ortamı etkilemez.
Bu işlevi Databricks Runtime 10.5 veya altında MLflow sürüm 1.25.0 veya üzerini el ile yükleyerek de kullanabilirsiniz:
%pip install "mlflow>=1.25.0"
Model bağımlılıklarını (Python ve Python olmayan) ve artefaktları günlüğe kaydetme hakkında ek bilgi için bkz: Model bağımlılıklarını günlüğe kaydetme.
Model sunumunu gerçekleştirmek için model bağımlılıklarını ve özel yapıtları kaydetmeyi öğrenin.
- Bağımlılıkları olan modelleri dağıtma
- Model Sunma ile özel Python kitaplıkları kullanma
- Model Hizmeti için özel yapıtları paketleme
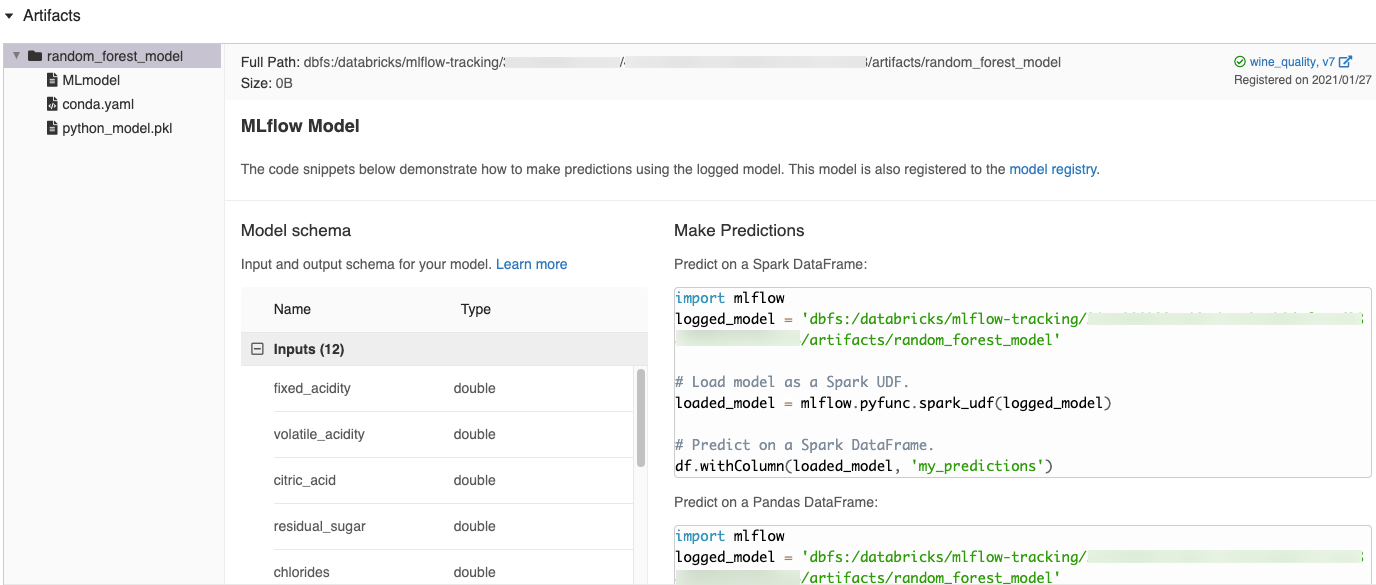
MLflow kullanıcı arabiriminde otomatik olarak oluşturulan kod parçacıkları
Azure Databricks not defterindeki bir modeli günlüğe kaydettiğinizde, Azure Databricks modeli yüklemek ve çalıştırmak için kopyalayıp kullanabileceğiniz kod parçacıklarını otomatik olarak oluşturur. Bu kod parçacıklarını görüntülemek için:
- Modeli üreten çalıştırmaya ait Çalıştırmalar ekranına gidin. (Bkz. Çalıştırmalar ekranını görüntülemeye yönelik not defteri denemesini görüntüleyin.)
- Yapıtlar bölümüne kaydırın.
- Kayıtlı modelin adına tıklayın. Sağ tarafta, günlüğe kaydedilen modeli yüklemek ve Spark veya pandas DataFrames üzerinde tahminlerde bulunmak için kullanabileceğiniz kodu gösteren bir panel açılır.
Örnekler
Günlük modellerin örnekleri için Makine öğrenmesi eğitim çalıştırmalarını izleme örneklerine bkz.
Modelleri Model Kayıt Defteri'ne kaydetme
MLflow Modellerinin tüm yaşam döngüsünü yönetmek için kullanıcı arabirimi ve API kümesi sağlayan merkezi bir model deposu olan MLflow Model Kayıt Defteri'ne modelleri kaydedebilirsiniz. Databricks Unity Kataloğu'ndaki modelleri yönetmek için Model Kayıt Defteri'ni kullanma yönergeleri için bkz. Unity Kataloğu'nda model yaşam döngüsünü yönetme
MLflow 3 ile oluşturulan modeller Unity Kataloğu model kayıt defterine kaydedildiğinde, parametreler ve ölçümler gibi verileri tüm denemelerde ve çalışma alanlarında tek bir merkezi konumda görüntüleyebilirsiniz. Daha fazla bilgi için bkz. MLflow 3 ile Model Kayıt Defteri geliştirmeleri.
API kullanarak bir modeli kaydetmek için aşağıdaki komutu kullanın:
MLflow 3
mlflow.register_model("models:/{model_id}", "{registered_model_name}")
MLflow 2.x
mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}")
Modelleri Unity Kataloğu birimlerine kaydetme
Modeli yerel olarak kaydetmek için kullanın mlflow.<model-type>.save_model(model, modelpath).
modelpath, Unity Kataloğu birimleri için bir yolu olmalıdır. Örneğin, proje çalışmanızı depolamak için Unity Kataloğu birimleri konumu dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models kullanıyorsanız, /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_modelsmodel yolunu kullanmanız gerekir:
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
MLlib modellerinde ML İşlem Hatları'nı kullanın.
Model yapıtlarını indirme
Çeşitli API'lere sahip kayıtlı bir model için günlüğe kaydedilen model yapıtlarını (model dosyaları, çizimler ve ölçümler gibi) indirebilirsiniz.
Python API örneği:
mlflow.set_registry_uri("databricks-uc")
mlflow.artifacts.download_artifacts(f"models:/{model_name}/{model_version}")
Java API örneği:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
CLI komut örneği:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
Çevrimiçi servis için modelleri dağıtmak
Not
Modelinizi dağıtmadan önce modelin kullanıma sunulduğunun doğrulanması yararlı olur. dağıtım mlflow.models.predictiçin nasıl kullanabileceğiniz hakkında MLflow belgelerine bakın.
Unity Kataloğu model kayıt defterine REST uç noktaları olarak kaydedilen makine öğrenmesi modellerini barındırmak için Model Sunma özelliğini kullanın. Bu uç noktalar, model sürümlerinin kullanılabilirliğine göre otomatik olarak güncelleştirilir.