Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Databricks not defterlerini düzenleyebilir ve Lakeflow İşleri, dbutils.notebook.run(), çalışma alanı dosyaları ve %runkullanarak kodu modülerleştirebilirsiniz. Zamanlama, parametre geçirme ve sürüm denetimi gereksiniminize göre bir yöntem seçin.
Düzenleme ve kod modülerleştirme yöntemleri
Aşağıdaki tabloda not defterlerini düzenlemek ve not defterlerindeki kodu modüler hale getirme için kullanılabilecek yöntemler karşılaştırılıyor.
| Yöntem | Kullanım örneği | Notlar |
|---|---|---|
| Lakeflow İşleri | Not defteri orkestrasyonu (önerilir) | Not defterlerini düzenlemeye yönelik önerilen yöntem. Görev bağımlılıkları, zamanlama ve tetikleyicilerle karmaşık iş akışlarını destekler. Üretim iş yükleri için sağlam ve ölçeklenebilir bir yaklaşım sağlar, ancak kurulum ve yapılandırma gerektirir. |
| dbutils.notebook.run() | Defter orkestrasyonu | Kullanım senaryonuz Jobs tarafından desteklenmiyorsa, örneğin bir not defterini meta veri dosyasına dayalı olarak dinamik şekilde çalıştırmak için (meta veri odaklı ETL), dbutils.notebook.run() kullanın.Her çağrı için yeni bir kısa ömürlü iş başlatır, bu da ek yükü artırabilir ve gelişmiş zamanlama özelliklerinden yoksundur. |
| Çalışma alanı dosyaları | Kod modülerleştirme (önerilen) | Kodu modüler hale getirme için önerilen yöntem. Kodu çalışma alanında depolanan yeniden kullanılabilir kod dosyalarına modüler hale getirme. Daha iyi hata ayıklama ve birim testi için depolarla sürüm denetimini ve IDE'lerle tümleştirmeyi destekler. Dosya yollarını ve bağımlılıklarını yönetmek için ek kurulum gerektirir. |
| %run | Kod modülerleştirme | Çalışma alanı dosyalarına erişemiyorsanız kullanın %run .İşlevleri veya değişkenleri satır içinde yürüterek diğer not defterlerinden içeri aktarın. Prototip oluşturma için kullanışlıdır, ancak bakımının daha zor olduğu sıkı bağımlı kodlara neden olabilir. Parametre geçirmeyi veya sürüm denetimini desteklemez. |
%run ile dbutils.notebook.run() karşılaştırması
komutu, %run not defterine başka bir not defteri eklemenize olanak tanır. Destekleyici işlevleri ayrı bir not defterine yerleştirerek kodunuzu modüler hale getirmek için %run kullanabilirsiniz. Ayrıca, bir çözümlemedeki adımları uygulayan not defterlerini birleştirmek için de kullanabilirsiniz. kullandığınızda %run, çağrılan not defteri hemen yürütülür ve içinde tanımlanan işlevler ve değişkenler çağrılan not defterinde kullanılabilir hale gelir.
dbutils.notebook API, parametreleri bir not defterine geçirmenize ve not defterinden değer döndürmenize olanak sağladığı için %run tamamlar. Bu, bağımlılıklarla karmaşık iş akışları ve işlem hatları oluşturmanıza olanak tanır. Örneğin, bir dizindeki dosyaların listesini alabilir ve adlarını %run ile imkansız olan başka bir not defterine iletebilirsiniz. Ayrıca, dönüş değerlerine göre if-then-else iş akışları da oluşturabilirsiniz.
yönteminin %run aksinedbutils.notebook.run(), not defterini çalıştırmak için yeni bir iş başlatır.
Tüm dbutils API'leri gibi bu yöntemler de yalnızca Python ve Scala'da kullanılabilir. Ancak, R not defterini çağırmak için kullanabilirsiniz dbutils.notebook.run() .
%run kullanarak not defterini içeri aktarın
İlk not defteri, bir işlev olan reverse tanımlar. Siz %run komutunu yürütmek için shared-code-notebook sihrini kullandıktan sonra bu işlev, ikinci not defterinde kullanılabilir hale gelir.

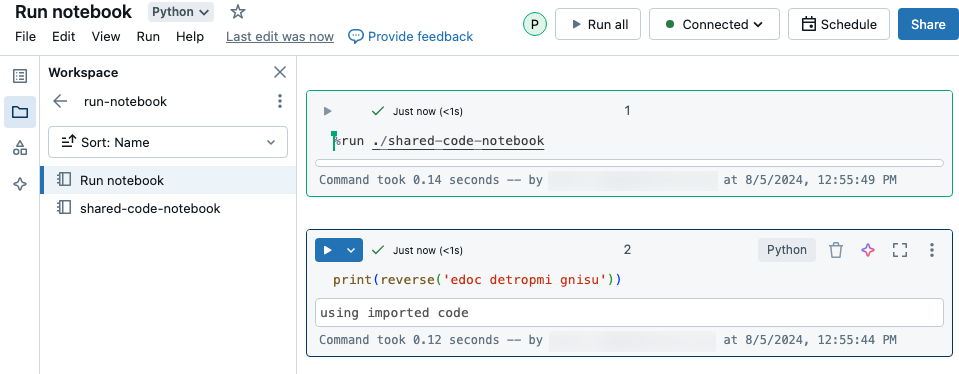
Her iki not defteri de çalışma alanında aynı dizinde olduğundan, yolun şu anda çalışan not defterine göre çözümlenmesi gerektiğini belirtmek için ./'da ./shared-code-notebook ön ekini kullanın. Not defterlerini gibi %run ./dir/notebookdizinler halinde düzenleyebilir veya gibi %run /Users/username@organization.com/directory/notebookmutlak bir yol kullanabilirsiniz.
Not
-
%runtüm not defterini satır içinde çalıştırdığından, hücrede tek başına olmalıdır. -
kullanamazsınız bir Python dosyasını çalıştırmak için
%runve bu dosyada tanımlanan varlıkları not defterineimportalmak için. Python dosyasından içeri aktarmak için, "Kodunuzu dosyalar kullanarak modüler hale getirme" bölümüne bakın. Veya dosyayı bir Python kitaplığına paketleyin, bu Python kitaplığından Azure Databrickslibrary oluşturun ve> not defterinizi çalıştırmak için kullandığınız kitaplığı kümeye yükleyin - Pencere öğeleri içeren bir not defterini çalıştırmak için kullandığınızda
%run, varsayılan olarak belirtilen not defteri pencere öğesinin varsayılan değerleriyle çalışır. Ayrıca pencere öğelerine de değer geçirebilirsiniz; bkz . databricks pencere öğelerini %runile kullanma .
Yeni bir iş başlatmak için dbutils.notebook.run kullanma
Bir notebook çalıştırın ve çıkış değerini döndürün. Bu yöntem, hemen çalışan geçici bir iş başlatır.
API'de kullanılabilen yöntemler dbutils.notebook, run ve exit'dir. Hem parametreler hem de dönüş değerleri dize olmalıdır.
run(path: String, timeout_seconds: int, arguments: Map): String
timeout_seconds parametresi çalıştırmanın zaman aşımını denetler (0, zaman aşımı olmadığı anlamına gelir).
run çağrısı, belirtilen süre içinde tamamlanmazsa bir istisna fırlatır. Azure Databricks 10 dakikadan uzun süre çalışmıyorsa, timeout_seconds ne olursa olsun not defteri çalıştırması başarısız olur.
arguments parametresi, hedef defterin widget değerlerini ayarlar. Özellikle, çalıştırdığınız not defterinde bir ‘widget’ adlı A varsa ve çağrısına ("A": "B"), bağımsız değişken parametresinin bir parçası olarak bir anahtar-değer çifti run() iletirseniz, pencere öğesi A değerini almak, "B" döndürecektir. Pencere öğeleri oluşturma ve bunlarla çalışma yönergelerini Databricks pencere öğeleri sayfasında bulabilirsiniz.
Not
-
argumentsparametresi yalnızca Latin karakterleri (ASCII karakter kümesi) kabul eder. ASCII olmayan karakterler kullanıldığında hata döndürülüyor. - API kullanılarak
dbutils.notebookoluşturulan işlerin 30 gün veya daha kısa sürede tamamlanması gerekir.
run Kullanım
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Scala programlama dili
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Yapılandırılmış verileri not defterleri arasında geçirme
Bu bölümde, yapılandırılmış verilerin not defterleri arasında nasıl geçirıldığı gösterilmektedir.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Scala programlama dili
Sunucusuz uyumluluk Databricks, Databricks sunucusuz işlem mimarisiyle uyumlu olmadığından RDD API'lerinden uzaklaşmanızı önerir. Bunun yerine DataFrame API'sini kullanın.
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Hatalarla başa çıkma
Bu bölümde hataların nasıl işleneceğini gösterilmektedir.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Scala programlama dili
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Birden çok not defterini eşzamanlı olarak çalıştırma
Aynı anda birden çok not defteri çalıştırmak için standart Scala ve Python yapılarını, örneğin İş Parçacıkları (Scala, Python) ve Vadeli İşlemler (Scala, Python) kullanabilirsiniz. Örnek not defterleri bu yapıların nasıl kullanılacağını gösterir.
- Aşağıdaki dört not defterini indirin. Not defterleri Scala'da yazılır.
- Not defterlerini çalışma alanında tek bir klasöre aktarın.
- Eşzamanlı çalıştır not defterini çalıştırın.