Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Note
El ile ayarlama önerileri, otomatik dosya boyutu ayarlamayı kullanan Unity Kataloğu yönetilen tabloları için geçerli değildir. Yeni tablolar için, varsayılan ayarlarla Unity Kataloğu yönetilen tablolarını kullanın.
Databricks Runtime 13.3 LTS ve üzerinde Databricks, tablo düzeni için kümeleme kullanılmasını önerir. Bkz Tablolar için sıvı kümeleme kullanma.
Databricks, tablolar için OPTIMIZE ve VACUUM öğelerini otomatik olarak çalıştırmak üzere tahmine dayalı iyileştirme kullanılmasını önerir. Bkz. Unity Kataloğu tarafından yönetilen tablolar için tahmine dayalı optimizasyon.
Otomatik sıkıştırma ve optimize edilmiş yazma işlemleri, MERGE, UPDATE ve DELETE işlemleri için her zaman etkindir. Bu işlevi kapatamazsınız.
Azure Databricks Unity Kataloğu yönetilen tabloları için dosya boyutlarını otomatik olarak düzenler. Dış tablolar ve eski iş yükleri için otomatik sıkıştırmayı, iyileştirilmiş yazmaları ve hedef dosya boyutlarını yapılandırarak verilerin nasıl yazılıp sıkıştırılabildiğini denetleyebilirsiniz.
Unity Kataloğu yönetilen tablolarında, SQL ambarı veya Databricks Runtime 11.3 LTS veya üzeri kullanıyorsanız Databricks çoğu yapılandırmayı otomatik olarak düzenler.
Databricks Runtime 10.4 LTS veya altında bir iş yükünü yükseltmek istiyorsanız bkz. Arka plan otomatik sıkıştırmasına yükseltme.
Ne zaman çalıştırılır? OPTIMIZE
Otomatik sıkıştırma ve iyileştirilmiş yazma işlemleri küçük dosya sorunlarını azaltır, ancak tam olarak yerine OPTIMIZEgeçmeyebilir. Databricks, 1 TB'tan büyük tablolar için dosyaları daha fazla birleştirmek için bir zamanlamaya göre çalışmanızı OPTIMIZE önerir. Databricks, gelişmiş veri atlama için sıvı kümeleme önerir. Sıvı kümeleme etkinleştirildiğinde, OPTIMIZE verileri kümeleme anahtarları tarafından otomatik olarak yeniden düzenler. Bkz Tablolar için sıvı kümeleme kullanma.
Unity Kataloğu yönetilen tablolarında tahmine dayalı iyileştirme, tahmine dayalı iyileştirmenin etkinleştirildiği tablolarda otomatik olarak çalıştırılır OPTIMIZE .
Otomatik iyileştirme
Otomatik iyileştirme, autoOptimize.autoCompact ve autoOptimize.optimizeWrite ayarlarını açıklar. Bkz. Otomatik sıkıştırma ve İyileştirilmiş yazma işlemleri.
Otomatik sıkıştırma
Otomatik sıkıştırma, küçük dosya sorunlarını azaltmak için tablo bölümleri içindeki küçük dosyaları birleştirir. Yazma işlemi başarılı olduktan sonra, yazmayı gerçekleştiren kümede senkronize bir şekilde çalışır ve daha önce sıkıştırılmamış dosyaları sıkıştırır.
Otomatik sıkıştırma ve tahmine dayalı iyileştirme, ayrı ayrı veya birlikte kullanılabilen bağımsız özelliklerdir. Otomatik sıkıştırma, yazma işlemini gerçekleştiren kümede çalıştırılırken tahmine dayalı iyileştirme, sunucusuz işlem kullanarak bakım işlemlerini zaman uyumsuz olarak çalıştırır.
Otomatik sıkıştırmayı yapılandırmak için aşağıdaki ayarları kullanın:
| Setting | Delta | Iceberg | Description |
|---|---|---|---|
| Otomatik sıkıştırmayı etkinleştirme (tablo özelliği) | autoOptimize.autoCompact |
autoOptimize.autoCompact |
Tablo düzeyinde otomatik sıkıştırmayı etkinleştirir. |
| Otomatik sıkıştırmayı etkinleştirme (Spark oturumu) | spark.databricks.delta.autoCompact.enabled |
spark.databricks.iceberg.autoCompact.enabled |
Oturum düzeyinde otomatik sıkıştırmayı etkinleştirir. |
| En büyük çıkış dosyası boyutu | spark.databricks.delta.autoCompact.maxFileSize |
spark.databricks.iceberg.autoCompact.maxFileSize |
Hedef çıkış dosyası boyutunu denetler. |
| Sıkıştırmayı tetikleyen en düşük dosyalar | spark.databricks.delta.autoCompact.minNumFiles |
spark.databricks.iceberg.autoCompact.minNumFiles |
Otomatik sıkıştırmayı tetikleyebilmek için bir bölümde veya tabloda gereken en az küçük dosya sayısını ayarlar. |
Bu ayarlar aşağıdaki seçenekleri kabul ediyor:
| Options | Davranış |
|---|---|
auto (önerilir) |
Hedef dosya boyutunu diğer otomatik ayarlama işlevlerini göz önünde bulundurarak ayarlar. |
legacy |
Diğer ad için true. |
true |
Hedef dosya boyutu olarak 128 MB kullanın. Dinamik boyutlandırma yok. |
false |
Otomatik sıkıştırmayı kapatır. İş yükünde değiştirilen tüm tablolar için otomatik sıkıştırmayı geçersiz kılmak için oturum düzeyinde ayarlanabilir. |
Note
Azure Databricks, çıktı dosyası boyutunu tablo boyutuna göre denetlemek için otomatik ayarlama kullanılmasını önerir. Bkz. Tablo boyutuna göre dosya boyutunu otomatik ayarla.
Tabloda otomatik sıkıştırmanın çalıştığını onaylamak için tablo geçmişini gözden geçirin. Otomatik sıkıştırma, operationParameters.auto alanı true olarak ayarlanmış bir OPTIMIZE işlemi olarak görünür. Elle çalıştırılan OPTIMIZE komutu, autofalse olarak ayarlanmıştır. Bkz. İşlem türünü OPTIMIZE belirleme.
İyileştirilmiş yazma işlemleri
İyileştirilmiş yazma işlemleri, veriler yazıldıkça dosya boyutunu geliştirir ve tablodaki sonraki okumalardan yararlanır.
İyileştirilmiş yazma işlemleri, bölümlenmiş tablolar için en etkili olanlardır çünkü her bölüme yazılan küçük dosyaların sayısını azaltır. Daha az büyük dosya yazmak, çok sayıda küçük dosya yazmaktan daha verimlidir, ancak veriler yazılmadan önce karıştırıldığı için yazma gecikme süresinde bir artış görebilirsiniz.
Aşağıdaki görüntüde iyileştirilmiş yazmaların nasıl çalıştığı gösterilmektedir:
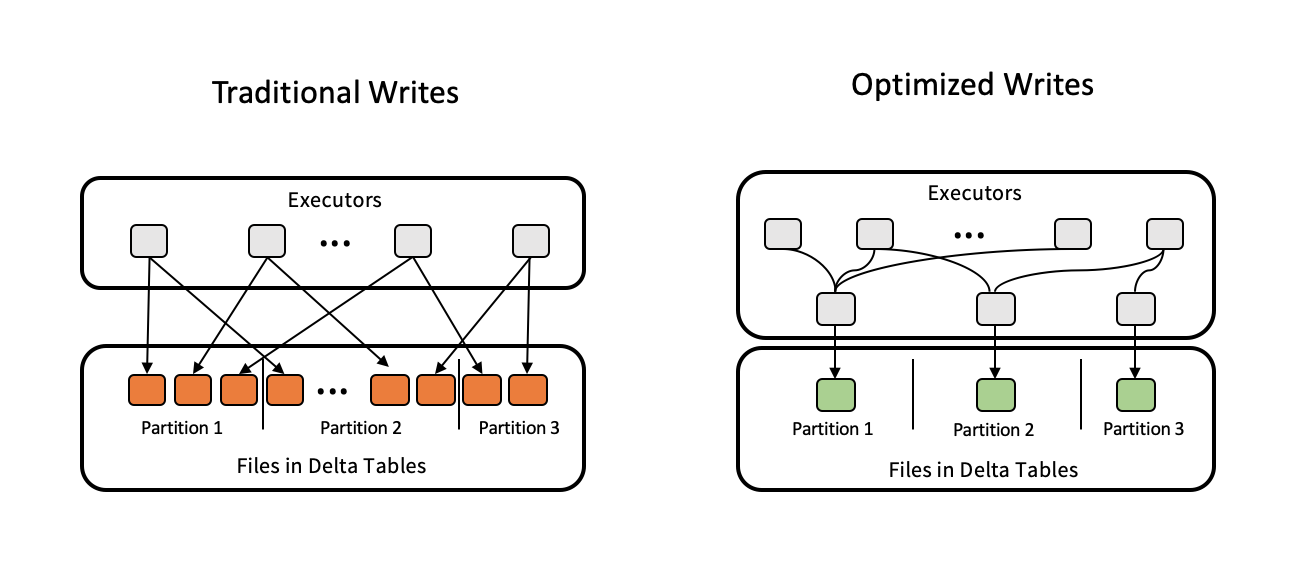
Note
Optimize edilmiş yazma işlemleri kullanıyorsanız, Databricks yazılan dosya sayısını denetlemek için bir yazma işleminden hemen önce coalesce(n) veya repartition(n) çalıştırmamanızı önerir.
İyileştirilmiş yazma işlemleri aşağıdaki işlemler için varsayılan olarak etkindir:
MERGE-
UPDATEalt sorgularla -
DELETEalt sorgularla
İyileştirilmiş yazma işlemleri, SQL ambarları kullanılırken CTAS deyimler ve INSERT işlemler için de etkinleştirilir. Databricks Runtime 13.3 LTS ve üzerindeki Unity Kataloğu'nda kayıtlı tüm tablolarda, CTAS deyimleri ve INSERT işlemleri için bölümlenmiş tablolarla ilişkili iyileştirilmiş yazmalar etkinleştirilmiştir.
İyileştirilmiş yazma işlemleri aşağıdaki ayarlar kullanılarak tablo veya oturum düzeyinde etkinleştirilebilir:
- Tablo özelliği:
autoOptimize.optimizeWrite - SparkSession ayarı:
spark.databricks.delta.optimizeWrite.enabled(Delta) veyaspark.databricks.iceberg.optimizeWrite.enabled(Iceberg)
Bu ayarlar aşağıdaki seçenekleri kabul ediyor:
| Options | Davranış |
|---|---|
true |
Hedef dosya boyutu olarak 128 MB kullanın. |
false |
Optimize edilmiş yazmaları kapatır. İş yükünde değiştirilen tüm tablolarda optimize edilmiş yazma işlemlerini geçersiz kılmak için oturum düzeyinde ayarlanabilir. |
Hedef dosya boyutu ayarlama
Tablonuzdaki dosyaların boyutunu ayarlamak için tablo özelliğinitargetFileSize istediğiniz boyuta ayarlayın. Ayarlandığında, tüm veri düzeni iyileştirme işlemleri en iyi duruma getirme, sıvı kümeleme, otomatik sıkıştırma ve iyileştirilmiş yazma işlemleri dahil olmak üzere belirtilen boyutta dosyalar oluşturmak için en iyi çabayı gösterir.
Note
Unity Kataloğu yönetilen tabloları ve SQL veri ambarlarını veya Databricks Runtime 11.3 LTS ve üzerini kullanırken, yalnızca OPTIMIZE komutları targetFileSize ayarına saygı gösterir.
| Mülkiyet | Description |
|---|---|
delta.targetFileSize (Delta)iceberg.targetFileSize (Buzdağı) |
Tür: Bayt veya daha yüksek birim cinsinden boyut. Açıklama: Hedef dosya boyutu. Örneğin, 104857600 (bayt) veya 100mb.Varsayılan değer: Yok |
Mevcut tablolar için, TBL PROPERTIES
Tablo boyutuna göre dosya boyutunu otomatik ayarla
El ile ayarlamayı en aza indirmek için Azure Databricks tablonun boyutuna göre tabloların dosya boyutunu otomatik olarak ayarlar. Azure Databricks, tablodaki dosya sayısının çok fazla büyümemesi için daha küçük tablolar için daha küçük dosya boyutları ve daha büyük tablolar için daha büyük dosya boyutları kullanır. Azure Databricks, belirli bir hedef boyutuyla ayarlamış olduğunuz tabloları otomatik olarak ayarlamaz.
Hedef dosya boyutu, tablonun geçerli boyutuna bağlıdır. 2,56 TB'tan küçük tablolar için otomatik olarak seçilen hedef dosya boyutu 256 MB'tır. Boyutu 2,56 TB ile 10 TB arasında olan tablolar için hedef boyut doğrusal olarak 256 MB'tan 1 GB'a büyür. 10 TB'tan büyük tablolar için hedef dosya boyutu 1 GB'tır.
Note
Bir tablonun hedef dosya boyutu arttığında, var olan dosyalar OPTIMIZE komutuyla daha büyük dosyalara yeniden optimize edilmez. Bu nedenle büyük bir tabloda her zaman hedef boyuttan küçük bazı dosyalar bulunabilir. Bu küçük dosyaları daha büyük dosyalara da en iyi duruma getirmek gerekiyorsa, tablo özelliğini kullanarak targetFileSize tablo için sabit bir hedef dosya boyutu yapılandırabilirsiniz.
Bir tablo artımlı olarak yazıldığında, hedef dosya boyutları ve dosya sayıları tablo boyutuna göre aşağıdaki sayılara yakın olur. Bu tablodaki dosya sayıları yalnızca bir örnektir. Gerçek sonuçlar birçok faktöre bağlı olarak farklı olacaktır.
| Tablo boyutu | Hedef dosya boyutu | Tablodaki yaklaşık dosya sayısı |
|---|---|---|
| 10 GB | 256MB | 40 |
| 1 Terabayt (TB) | 256MB | 4096 |
| 2,56 TB | 256MB | 10240 |
| 3 TB (Terabayt) | 307 MB | 12108 |
| 5 TB | 512MB | 17339 |
| 7 TB (Terabayt) | 716 MB | 20784 |
| 10 TB (terabayt) | 1GB | 24437 |
| 20 TB (Terabayt) | 1GB | 34437 |
| 50 TB | 1GB | 64437 |
| 100 TB | 1GB | 114437 |
Veri dosyasına yazılan satırları sınırlama
Bazen, dar veri içeren tablolar belirli bir veri dosyasındaki satır sayısının Parquet biçiminin destek sınırlarını aştığı bir hatayla karşılaşabilir. Bu hatayı önlemek için SQL oturumu yapılandırmasını spark.sql.files.maxRecordsPerFile kullanarak bir tablo için tek bir dosyaya yazılacak en fazla kayıt sayısını belirtebilirsiniz. Sıfır veya negatif bir değer belirtilmesi hiçbir sınırı temsil eder.
Bir tabloya yazmak için DataFrame API'lerini kullanırken DataFrameWriter seçeneğini maxRecordsPerFile de kullanabilirsiniz.
maxRecordsPerFile belirtildiğinde, SQL oturum yapılandırması spark.sql.files.maxRecordsPerFile değeri göz ardı edilir.
Note
Databricks, hatadan kaçınmak için gerekli olmadıkça kullanılmasını maxRecordsPerFile önermez. Bu ayar, çok dar verilere sahip bazı Unity Kataloğu yönetilen tabloları için gerekli olabilir.
Arka plan otomatik sıkıştırmasına yükseltme
Unity Kataloğu yönetilen tablolarında arka plan otomatik sıkıştırması kullanılabilir. Arka planda otomatik sıkıştırma için tahmine dayalı iyileştirme gerekmez. Eski bir iş yükünü veya tabloyu geçirirken aşağıdakileri yapın:
- Küme veya not defteri yapılandırma ayarlarından Spark yapılandırması
spark.databricks.delta.autoCompact.enabled(Delta) veyaspark.databricks.iceberg.autoCompact.enabled(Iceberg)'i kaldırın. - Eski otomatik sıkıştırma ayarlarını kaldırmak için her tablo için (Delta) veya
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)(Iceberg) komutunu çalıştırınALTER TABLE <table_name> UNSET TBLPROPERTIES (iceberg.autoOptimize.autoCompact).
Bu eski yapılandırmalar kaldırıldıktan sonra, Unity Catalog tarafından yönetilen tüm tablolar için arka planda otomatik sıkıştırma otomatik olarak tetiklenir.