Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede, geri alma artırılmış üretim (RAG) derinlemesine incelenmektedir. Geliştiricilerin üretime hazır bir RAG çözümü oluşturması için gereken çalışmaları ve dikkat edilmesi gereken noktaları açıklıyoruz.
İşletmelerde üretken yapay zekanın en önemli kullanım örneklerinden biri olan "verileriniz üzerinden sohbet" uygulaması oluşturmaya yönelik iki seçenek hakkında bilgi edinmek için bkz. LLM'leri RAG ile artırma veyaince ayarlama .
Aşağıdaki diyagramda RAG'in adımları veya aşamaları gösterilmiştir:
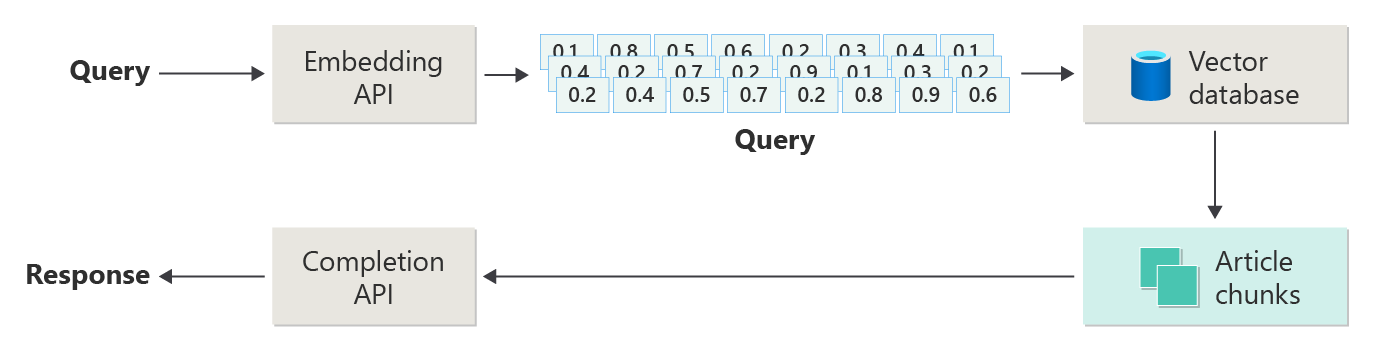
Bu betimleme, naif RAGolarak adlandırılır. BAŞLANGıÇTA RAG tabanlı bir sohbet sistemi uygulamak için gereken mekanizmaları, rolleri ve sorumlulukları anlamanın kullanışlı bir yoludur.
Ancak gerçek dünyadaki bir uygulama, makaleleri, sorguları ve yanıtları kullanıma hazırlamak için daha birçok ön işleme ve işlem sonrası adıma sahiptir. Aşağıdaki diyagram, bazen gelişmiş RAG

Bu makale, gerçek dünya RAG tabanlı bir sohbet sisteminde ön işleme ve işlem sonrası aşamaları anlamak için kavramsal bir çerçeve sağlar:
- Alma aşaması
- Çıkarım işlem hattı aşaması
- Değerlendirme aşaması
Alım
İçeri aktarma, öncelikle kuruluşunuzun belgelerini depolamak üzerine odaklanır; böylece, bir kullanıcının sorusunu yanıtlamak amacıyla belgeler kolayca geri getirilebilir. Zorluk, belgelerin kullanıcı sorgusuyla en iyi eşleşen bölümlerinin çıkarım sırasında bulunduğundan ve kullanıldığından emin olmaktır. Eşleştirme öncelikli olarak vektörleştirilmiş eklemeler ve kosinüs benzerliği araması yoluyla gerçekleştirilir. Ancak, içeriğin (örneğin, desenler ve form) ve veri düzenleme stratejisinin (vektör veritabanında depolandığında verilerin yapısı) doğası anlaşılarak eşleştirme kolaylaştırılır.
Alım için geliştiricilerin aşağıdaki adımları göz önünde bulundurması gerekir:
- İçerik ön işleme ve ayıklama
- Öbekleme stratejisi
- Kuruluş öbekleme
- Güncelleştirme stratejisi
İçerik ön işleme ve ayıklama
Temiz ve doğru içerik, RAG tabanlı sohbet sisteminin genel kalitesini artırmanın en iyi yollarından biridir. Temiz ve doğru içerik elde etmek için, dizine eklenecek belgelerin şeklini ve biçimini analiz ederek işe başlayın. Belgeler, belgeler gibi belirtilen içerik desenlerine uygun mu? Aksi takdirde, belgeler hangi tür soruları yanıtlayabilir?
En azından alma işlem hattında şu adımları oluşturun:
- Metin biçimlerini standartlaştırma
- Özel karakterleri işleme
- İlişkisiz, güncel olmayan içeriği kaldırma
- Sürümlenmiş içerik için hesap
- İçerik deneyimi için hesap oluşturma (sekmeler, resimler, tablolar)
- Meta verileri ayıklama
Bu bilgilerin bazıları (örneğin meta veriler), çıkarılma işlem hattındaki alma ve değerlendirme işlemi sırasında kullanılacak vektör veritabanında belgeyle birlikte tutulduğunda yararlı olabilir. Ayrıca, öbeğin vektör yerleştirmesini etkilemek için metin öbeğiyle birleştirilebilir.
Öbekleme stratejisi
Geliştirici olarak, daha büyük bir belgeyi daha küçük parçalara ayırmaya karar vermeniz gerekir. Öbekleme, kullanıcı sorgularını doğru bir şekilde yanıtlamak için LLM'ye gönderilen ek içeriğin ilgi düzeyini artırabilir. Ayrıca öbekleri alma işleminin ardından nasıl kullanacağınızı da göz önünde bulundurun. Sistem tasarımcıları yaygın sektör tekniklerini araştırmalı ve bazı denemeler yapmalıdır. Hatta stratejinizi kuruluşunuzda sınırlı bir kapasitede test edebilirsiniz.
Geliştiricilerin dikkate alması gerekenler:
- Öbek boyutu iyileştirmesi: İdeal öbek boyutunu ve öbeğin nasıl belirleneceğini belirlemek. Bölüme göre mi? Paragrafa göre mi? Cümleyle mi?
- Çakışan ve kayan pencere öbekleri: İçeriğin ayrık öbeklere bölünüp bölünmeyeceğini veya öbeklerin çakışıp çakışmayacağını belirleyin. Kayan pencere tasarımında ikisini de yapabilirsiniz.
- Small2Big: Öbekleme tek bir cümle gibi ayrıntılı bir düzeyde yapıldığında, içerik komşu cümleleri veya tümceyi içeren paragrafı kolayca bulabilmek için mi düzenlenir? Bu bilgilerin alınması ve LLM'ye sağlanması, kullanıcı sorgularını yanıtlamak için daha fazla bağlam sağlayabilir. Daha fazla bilgi için sonraki bölüme bakın.
Kuruluş öbekleme
RAG sisteminde, verilerinizi vektör veritabanında stratejik olarak düzenlemek, oluşturma sürecini artırmak için ilgili bilgilerin verimli bir şekilde alınmasında kilit öneme sahiptir. Göz önünde bulundurmanız gereken dizin oluşturma ve alma stratejilerinin türleri şunlardır:
- Hiyerarşik dizinler: Bu yaklaşım birden çok dizin katmanı oluşturmayı içerir. Üst düzey dizin (özet dizin), arama alanını hızla ilgili olabilecek öbeklerin bir alt kümesine daraltır. İkinci düzey dizin (öbekler dizini), gerçek veriler için daha ayrıntılı işaretçiler sağlar. Bu yöntem, önce özet dizini filtreleyerek ayrıntılı dizinde taranacak girdi sayısını azalttığı için alma işlemini önemli ölçüde hızlandırabilir.
-
Özelleştirilmiş dizinler: Verilerin doğasına ve öbekler arasındaki ilişkilere bağlı olarak, graf tabanlı veya ilişkisel veritabanları gibi özel dizinler kullanabilirsiniz:
- Graf tabanlı dizinler , öbeklerin alıntı ağları veya bilgi grafikleri gibi alma işlemini geliştirebilecek birbirine bağlı bilgilere veya ilişkilere sahip olması halinde yararlıdır.
- ilişkisel veritabanları, öbekler tablo biçiminde yapılandırılmışsa etkili olabilir. Belirli özniteliklere veya ilişkilere göre verileri filtrelemek ve almak için SQL sorgularını kullanın.
- Karma dizinler: Karma yaklaşım, birden çok dizin oluşturma yöntemini birleştirerek bunların güçlü yönlerini genel stratejinize uygular. Örneğin, ilk filtreleme için hiyerarşik dizin ve alma sırasında öbekler arasındaki ilişkileri dinamik olarak incelemek için graf tabanlı dizin kullanabilirsiniz.
Hizalama iyileştirmesi
Alınan öbeklerin ilgi düzeyini ve doğruluğunu artırmak için, bunları yanıtladıkları soru veya sorgu türleriyle yakın bir şekilde hizalayın. Stratejilerden biri, her öbek için öbeğe en uygun soruyu temsil eden varsayımsal bir soru oluşturmak ve eklemektir. Bu, çeşitli yollarla yardımcı olur:
- Geliştirilmiş eşleştirme: Alma sırasında sistem, getirilen öbeklerin ilgi düzeyini artırmak için en iyi eşleşmeyi bulmak için gelen sorguyu bu varsayımsal sorularla karşılaştırabilir.
- Makine öğrenmesi modelleri için eğitim verileri: Bu soru ve öbek eşleştirmeleri, RAG sisteminin temel bileşenleri olan makine öğrenmesi modellerini geliştirmek için eğitim verileri olabilir. RAG sistemi, her bir öbek tarafından en iyi yanıtlanan soru türlerini öğrenir.
- Doğrudan sorgu işleme: Gerçek bir kullanıcı sorgusu varsayımsal bir soruyla yakından eşleşiyorsa sistem ilgili öbekleri hızla alıp kullanabilir ve yanıt süresini hızlandırabilir.
Her öbeğin varsayımsal sorusu, getirme algoritmasını daha odaklanmış ve bağlamı daha iyi kavrayan bir şekilde yönlendiren bir etiket gibi işlev görür. Bu tür bir iyileştirme, öbekler çok çeşitli bilgi konularını veya türlerini kapsadığında kullanışlıdır.
Güncelleştirme stratejileri
Kuruluşunuz sık güncelleştirilen belgelerin dizinini oluşturursa, retriever bileşeninin en güncel bilgilere erişebildiğinden emin olmak için güncelleştirilmiş bir corpus bulundurmak önemlidir. retriever bileşeni, sistemdeki vektör veritabanında sorguyu çalıştıran ve sonuçları döndüren mantıktır. Bu tür sistemlerde vektör veritabanını güncelleştirmeye yönelik bazı stratejiler şunlardır:
Artımlı güncelleştirmeler:
- Düzenli aralıklar: Belge değişikliklerinin sıklığına bağlı olarak güncelleştirmeleri düzenli aralıklarla (örneğin, günlük veya haftalık) zamanlayın. Bu yöntem, veritabanının bilinen bir zamanlamaya göre düzenli aralıklarla yenilenmesini sağlar.
- Tetikleyici tabanlı güncelleştirmeler: Güncelleştirmenin yeniden dizine alınmasını tetiklediği bir sistem uygulayın. Örneğin, bir belgenin değiştirilmesi veya eklenmesi, etkilenen bölümlerde otomatik olarak yeniden dizine alma işlemini başlatır.
Kısmi güncelleştirmeler:
- Seçmeli yeniden dizinleme: Veritabanının tamamını yeniden dizine alma yerine yalnızca değiştirilen corpus bölümlerini güncelleştirin. Bu yaklaşım, özellikle büyük veri kümeleri için tam yeniden dizinlemeden daha verimli olabilir.
- Delta kodlama: Yalnızca mevcut belgelerle güncelleştirilmiş sürümleri arasındaki farkları depolayın. Bu yaklaşım, değişmemiş verileri işleme gereksinimini ortadan kaldırarak veri işleme yükünü azaltır.
Sürüm Yönetimi:
- Anlık görüntü oluşturma: Belge corpus sürümlerini zaman içinde farklı noktalarda koruyun. Bu teknik bir yedekleme mekanizması sağlar ve sistemin önceki sürümlere geri dönmesini veya bunlara başvurmasını sağlar.
- Belge sürümü denetimi: Değişiklik geçmişini korumak ve güncelleştirme işlemini basitleştirmek için belge değişikliklerini sistematik olarak izlemek için bir sürüm denetim sistemi kullanın.
Gerçek zamanlı güncellemeler:
- Stream işleme: Bilgilerin zamanında olması kritik olduğunda, belgede değişiklikler yapılırken gerçek zamanlı vektör veritabanı güncelleştirmeleri için akış işleme teknolojilerini kullanın.
- Canlı sorgulama: Yalnızca önceden dizine alınmış vektörlere güvenmek yerine, up-totarih yanıtları için canlı veri sorgusu yaklaşımını kullanın ve bu yaklaşım canlı verileri önbelleğe alınmış sonuçlarla birleştirerek verimlilik sağlar.
İyileştirme teknikleri:
Toplu işleme: Toplu işleme, kaynakları optimize etmek ve ek yükü azaltmak için daha az sıklıkta uygulanacak değişiklikleri biriktirir.
Karma yaklaşımlar: Çeşitli stratejileri birleştirin:
- Küçük değişiklikler için artımlı güncelleştirmeleri kullanın.
- Önemli güncelleştirmeler için tam yeniden dizinleme kullanın.
- Korpusta yapılan yapısal değişiklikleri belgele.
Doğru güncelleştirme stratejisini veya doğru bileşimi seçmek, aşağıdakiler gibi belirli gereksinimlere bağlıdır:
- Belge corpus boyutu
- Güncelleştirme sıklığı
- Gerçek zamanlı veri gereksinimleri
- Kaynak kullanılabilirliği
Belirli bir uygulamanın gereksinimlerine göre bu faktörleri değerlendirin. Her yaklaşımın karmaşıklık, maliyet ve güncelleştirme gecikme süresinde dengeleri vardır.
Çıkarım işlem hattı
Makaleleriniz öbeklenmiş, vektörleştirilmiş ve bir vektör veritabanında depolanmış. Şimdi, odaklanmanızı tamamlama zorluklarını çözmeye çevirin.
En doğru ve verimli tamamlamaları elde etmek için birçok faktörü hesaba katmalısınız:
- Kullanıcının sorgusu, kullanıcının aradığı sonuçları almak için bir şekilde mi yazıldı?
- Kullanıcının sorgusu kuruluşun ilkelerinden herhangi birini ihlal eder mi?
- Vektör veritabanındaki en yakın eşleşmeleri bulma şansını artırmak için kullanıcının sorgusunu nasıl yeniden yazarsınız?
- Makale öbeklerinin sorguya hizalanmasını sağlamak için sorgu sonuçlarını nasıl değerlendirirsiniz?
- En ilgili ayrıntıların tamamlanmaya dahil edildiğinden emin olmak için sorgu sonuçlarını LLM'ye geçirmeden önce nasıl değerlendirir ve değiştirirsiniz?
- LLM'nin tamamlanmasının kullanıcının özgün sorgusunu yanıtlamasını sağlamak için LLM'nin yanıtını nasıl değerlendirirsiniz?
- LLM'nin yanıtının kuruluşun ilkelerine uygun olduğundan nasıl emin olursunuz?
Çıkarım işlem hattının tamamı gerçek zamanlı olarak çalışır. Ön işleme ve işlem sonrası adımlarınızı tasarlamanın tek bir doğru yolu yoktur. Büyük olasılıkla programlama mantığı ve diğer LLM çağrılarının bir bileşimini seçersiniz. Dikkat edilmesi gereken en önemli noktalardan biri, mümkün olan en doğru ve uyumlu işlem hattını oluşturma ile bunu gerçekleştirmek için gereken maliyet ve gecikme süresi arasındaki dengedir.
Çıkarım işlem hattının her aşamasında belirli stratejileri belirleyelim.
Ön işleme adımlarını sorgulama
Sorgu ön işleme, kullanıcı sorgusunu gönderdikten hemen sonra gerçekleşir:

Bu adımların amacı, kullanıcının sisteminizin kapsamındaki soruları sorduğundan emin olmak ve kosinüs benzerliği veya "en yakın komşu" aramasını kullanarak mümkün olan en iyi makale öbeklerini bulma olasılığını artırmak için kullanıcının sorgusunu hazırlamaktır.
İlke denetimi: Bu adım belirli içeriği tanımlayan, kaldıran, bayraklayan veya reddeden mantığı içerir. Bazı örnekler kişisel verileri kaldırmayı, ifadeleri kaldırmayı ve "jailbreak" girişimlerini tanımlamayı içerir. Jailbreak, kullanıcının modelin yerleşik güvenlik, etik veya operasyonel yönergelerini aşmaya veya yönlendirmeye yönelik girişimlerini ifade eder.
Sorgu yeniden yazma: Bu adım, kısaltmaları açmak ve argoyu çıkarmaktan, soruyu daha soyut bir şekilde yeniden ifade ederek yüksek düzeyli kavramlar ve ilkeleri ayıklamaya kadar her şeyi içerebilir (geri adım istemikullanarak).
Geri adım istemindeki bir çeşitleme, Varsayımsal Belge Eklemeleri (HyDE). HyDE kullanıcının sorusunu yanıtlamak için LLM'yi kullanır, bu yanıt için bir ekleme oluşturur (varsayımsal belge ekleme) ve ardından ekleme işlemini kullanarak vektör veritabanında bir arama çalıştırır.
Alt Sorgular
Alt sorgu işleme adımı özgün sorguyu temel alır. Özgün sorgu uzun ve karmaşıksa, program aracılığıyla birkaç küçük sorguya bölmek ve ardından tüm yanıtları birleştirmek yararlı olabilir.
Örneğin, fizikteki bilimsel keşiflerle ilgili bir soru şu olabilir: "Modern fiziğe kim daha önemli katkılar yaptı, Albert Einstein veya Niels Bohr?"
Karmaşık sorguları alt sorgulara ayırmak onları daha yönetilebilir hale getirir:
- Subquery 1: "Albert Einstein'ın modern fiziğe önemli katkıları nelerdir?"
- Subquery 2: "Niels Bohr'un modern fiziğe önemli katkıları nelerdir?"
Bu alt sorguların sonuçları, her fizikçinin başlıca teorilerini ve keşiflerini ayrıntılandırır. Örneğin:
- Einstein için katkılar görelilik teorisini, fotoelektrik etkiyi ve E=mc^2içerebilir.
- Bohr için katkılar Arasında Bohr'un hidrojen atomu modeli, Bohr'un kuantum mekaniği üzerinde çalışması ve Bohr'un tamamlayıcılık ilkesi yer alabilir.
Bu katkılar özetlendiğinde, daha fazla alt sorgu belirlemek için değerlendirilebilir. Örneğin:
- Subquery 3: "Einstein'ın teorileri modern fiziğin gelişimini nasıl etkiledi?"
- Subquery 4: "Bohr'un teorileri modern fiziğin gelişimini nasıl etkiledi?"
Bu alt sorgular, her bilim insanının fizik üzerindeki etkisini inceler, örneğin:
- Einstein'ın teorileri kozmoloji ve kuantum teorisinde ilerlemelere nasıl yol açtı?
- Bohr'un çalışmaları atomik yapıyı ve kuantum mekaniğinin anlaşılmasına nasıl katkıda bulundu?
Bu alt sorguların sonuçlarının birleştirilmesi, dil modelinin teorik ilerlemelerine göre modern fiziğe kimin daha önemli katkılar yaptığı hakkında daha kapsamlı bir yanıt oluşturmasına yardımcı olabilir. Bu yöntem, daha belirgin, yanıtlanabilir bileşenlere erişerek ve ardından bu bulguları tutarlı bir yanıt olarak sentezleyerek özgün karmaşık sorguyu basitleştirir.
Sorgu yönlendiricisi
Kuruluşunuz, içerik corpus'unu birden çok vektör deposuna veya tüm alma sistemlerine bölmeyi seçebilir. Bu senaryoda, bir sorgu yönlendiricisi kullanabilirsiniz. sorgu yönlendiricisi belirli bir sorguya en iyi yanıtları sağlamak için en uygun veritabanını veya dizini seçer.
Sorgu yönlendiricisi genellikle kullanıcı sorguyu formüle ettikten sonra ancak sorguyu alma sistemlerine göndermeden önce çalışır.
Sorgu yönlendiricisi için basitleştirilmiş bir iş akışı aşağıdadır:
- Sorgu analizi: LLM veya başka bir bileşen gelen sorguyu analiz ederek içeriğini, bağlamını ve gerekli olabilecek bilgi türünü anlar.
- Dizin seçimi: Analize bağlı olarak, sorgu yönlendiricisi olası birkaç dizinden bir veya daha fazla dizin seçer. Her dizin, farklı veri veya sorgu türleri için iyileştirilebilir. Örneğin, bazı dizinler olgusal sorgular için daha uygun olabilir. Diğer dizinler görüş veya öznel içerik sağlama konusunda başarılı olabilir.
- Sorgu gönderme: Sorgu seçili dizine gönderilir.
- Sonuçları toplama: Seçilen dizinlerden gelen yanıtlar alınır ve kapsamlı bir yanıt oluşturmak için büyük olasılıkla toplanır veya daha fazla işlenir.
- Yanıt oluşturma: Son adım, alınan bilgilere göre tutarlı bir yanıt oluşturmayı, büyük olasılıkla birden çok kaynaktan içeriği tümleştirmeyi veya sentezleyi içerir.
Kuruluşunuz aşağıdaki kullanım örnekleri için birden çok alma motoru veya dizini kullanabilir:
- Veri türü uzmanlığı: Bazı dizinler haber makalelerinde, diğerleri akademik makalelerde ve diğerleri genel web içeriğinde veya tıbbi veya yasal bilgiler gibi belirli veritabanlarında uzmanlaşabilir.
- Sorgu türü iyileştirme: Bazı dizinler, hızlı olgusal aramalar (örneğin tarihler veya olaylar) için iyileştirilebilir. Diğerleri, karmaşık akıl yürütme görevleri veya derin alan bilgisi gerektiren sorgular için kullanılması daha iyi olabilir.
- Algoritmik farklılıklar: Vektör tabanlı benzerlik aramaları, geleneksel anahtar sözcük tabanlı aramalar veya daha gelişmiş anlamsal anlama modelleri gibi farklı altyapılarda farklı alma algoritmaları kullanılabilir.
Tıbbi danışmanlık bağlamında kullanılan RAG tabanlı bir sistem düşünün. Sistemin birden çok dizine erişimi vardır:
- Ayrıntılı ve teknik açıklamalar için iyileştirilmiş tıbbi araştırma kağıt dizini
- Belirtilerin ve tedavilerin gerçek dünya örneklerini sağlayan klinik örnek olay incelemesi dizini
- Temel sorgular ve halk sağlığı bilgileri için genel sağlık bilgileri dizini
Bir kullanıcı yeni bir ilacın biyokimyasal etkileri hakkında teknik bir soru sorarsa, sorgu yönlendiricisi derinliği ve teknik odağı nedeniyle tıbbi araştırma kağıt dizinine öncelik verebilir. Bununla birlikte, yaygın bir hastalığın tipik belirtileri hakkında bir soru için, genel sağlık dizini geniş ve kolay anlaşılır içeriği için seçilebilir.
Alma sonrası işleme adımları
Alma sonrası işleme, retriever bileşeni vektör veritabanından ilgili içerik öbeklerini aldıktan sonra gerçekleşir:

Aday içerik öbekleri alındıktan sonra, bir sonraki adım, LLM istemini LLM'ye sunulmak üzere hazırlamadan önce, arttırırken makale parçasının kullanışlılığını doğrulamaktır.
Dikkate alınması gereken bazı önemli noktalar şunlardır:
- Çok fazla ek bilgi dahil olmak, en önemli bilgilerin yoksayılmasıyla sonuçlanabilir.
- Ilgisiz bilgiler dahil olmak yanıtı olumsuz etkileyebilir.
Bir diğer önemli nokta, bir samanlıktaki iğnesi sorunudur. İstemin başındaki ve sonundaki içeriğin LLM'de ortadaki içerikten daha fazla ağırlıkta olduğu bazı LLM'lerin bilinen ilginçliğini ifade eden bir terimdir.
Son olarak, LLM'nin maksimum bağlam penceresi uzunluğunu ve olağanüstü uzun istemleri (özellikle büyük ölçekteki sorgular için) tamamlamak için gereken belirteç sayısını göz önünde bulundurun.
Bu sorunlarla başa çıkmak için, alma sonrası işlem hattı aşağıdaki adımları içerebilir:
- Filtreleme sonuçları: Bu adımda, vektör veritabanı tarafından döndürülen makale öbeklerinin sorguyla ilgili olduğundan emin olun. Eğer değilse, LLM istemi oluşturulurken sonuç yoksayılır.
- yeniden derecelendirme: İlgili ayrıntıların istemin başına ve sonuna yakın olduğundan emin olmak için vektör deposundan alınan makale öbeklerini sıralayın.
- İstem Sıkıştırma: Büyük Dil Modeline istem göndermeden önce birden fazla makale parçasını sıkıştırmak ve tek bir sıkıştırılmış istem halinde özetlemek için küçük, ucuz bir model kullanın.
Tamamlama sonrası işleme adımları
Tamamlama sonrası işleme, kullanıcının sorgusu ve tüm içerik öbekleri LLM'ye gönderildikten sonra gerçekleşir:

Doğruluk doğrulaması, LLM'nin istemi tamamlandıktan sonra gerçekleşir. Tamamlama sonrası işlem hattı aşağıdaki adımları içerebilir:
- Olgu denetimi: Amaç, makalede yapılan ve olgu olarak sunulan belirli talepleri belirlemek ve ardından bu olguların doğruluğunu denetlemektir. Gerçeklik kontrolü adımı başarısız olursa, daha iyi bir yanıt almak umuduyla LLM'yi yeniden sorgulamak veya kullanıcıya bir hata iletisi döndürmek uygun olabilir.
- İlke denetimi: Kullanıcı veya kuruluş için yanıtların zararlı içerik içermediğinden emin olmak için son savunma hattı.
Değerlendirme
Belirsiz bir sistemin sonuçlarını değerlendirmek, çoğu geliştiricinin aşina olduğu birim testlerini veya tümleştirme testlerini çalıştırmak kadar basit değildir. Birkaç faktörü dikkate almanız gerekir:
- Kullanıcılar aldıkları sonuçlardan memnun mu?
- Kullanıcılar sorularına doğru yanıtlar mı alıyor?
- Kullanıcı geri bildirimlerini nasıl yakalarsınız? Kullanıcı verileri hakkında toplayabileceğiniz verileri sınırlayan herhangi bir ilkeniz var mı?
- Yetersiz yanıtların tanılanması için, soruyu yanıtlamak için yapılan tüm çalışmaların görünürlüğünüz var mı? Kök neden analizi gerçekleştirebilmeniz için her aşamanın günlüğünü girişlerin ve çıkışların çıkarım işlem hattında tutuyor musunuz?
- Sistemde sonuçların gerilemesi veya düşüşü olmadan nasıl değişiklik yapabilirsiniz?
Kullanıcılardan gelen geri bildirimleri yakalama ve bu geri bildirimlere göre hareket etme
Daha önce açıklandığı gibi, kuruluşunuzun gizlilik ekibiyle birlikte çalışarak sorgu oturumunun adli ve kök neden analizi için geri bildirim yakalama mekanizmaları, telemetri ve günlüğe kaydetme tasarlamanız gerekebilir.
Sonraki adım bir değerlendirme işlem hattı geliştirmektir. Değerlendirme işlem hattı, ayrıntılı geri bildirimlerin analizinin karmaşıklığı ve zaman açısından yoğun olması ve yapay zeka sistemi tarafından sağlanan yanıtların kök nedenleri konusunda yardımcı olur. Bu analiz, yapay zeka sorgusunun sonuçları nasıl ürettiğini anlamak, belgelerden kullanılan içerik öbeklerinin uygunluğunu ve bu belgeleri bölmek için kullanılan stratejileri denetlemek için her yanıtı araştırmayı içerdiğinden çok önemlidir.
Ayrıca sonuçları geliştirebilecek ek ön işleme veya işlem sonrası adımların da dikkate alınması gerekir. Bu ayrıntılı inceleme, özellikle de kullanıcının sorgusuna yanıt vermek için uygun bir belge olmadığında genellikle içerik boşluklarını ortaya çıkarır.
Değerlendirme işlem hattı oluşturmak, bu görevlerin ölçeğini etkili bir şekilde yönetmek için gerekli hale gelir. Verimli bir işlem hattı, yapay zeka tarafından sağlanan yanıtların kalitesine yakın ölçümleri değerlendirmek için özel araçlar kullanır. Bu sistem, kullanıcının sorusuna neden belirli bir yanıt verildiğini, bu yanıtı oluşturmak için hangi belgelerin kullanıldığını ve sorguları işleyen çıkarım işlem hattının etkinliğini belirleme sürecini kolaylaştırır.
Altın veri kümesi
RAG sohbet sistemi gibi belirsiz olmayan bir sistemin sonuçlarını değerlendirmeye ilişkin stratejilerden biri altın renkli bir veri kümesi kullanmaktır. altın veri kümesi, seçilmiş bir dizi soru ve onaylı yanıt, meta veriler (konu ve soru türü gibi), yanıtlar için temel gerçek görevi görecek kaynak belgelere başvurular ve hatta çeşitlemeler (kullanıcıların aynı soruları nasıl sorabileceğinin çeşitliliğini yakalamak için farklı ifadeler).
Altın renkli veri kümesi "en iyi senaryoyu" temsil eder. Geliştiriciler, sistemin ne kadar iyi performans sergilediğini görmek için sistemi değerlendirebilir ve ardından yeni özellikler veya güncelleştirmeler uygularken regresyon testleri yapabilir.
Zararı değerlendirme
Zarar modellemesi, olası zararları öngörme, bireyler için risk oluşturabilecek bir üründeki eksiklikleri tespit etmeyi ve bu riskleri azaltmak için proaktif stratejiler geliştirmeyi amaçlayan bir metodolojidir.
Teknolojinin, özellikle de yapay zeka sistemlerinin etkisini değerlendirmek için tasarlanan bir araç, sağlanan kaynaklarda açıklandığı gibi zarar modelleme ilkelerine göre birkaç temel bileşen içerir.
Zarar değerlendirme aracının temel özellikleri şunlar olabilir:
Paydaş belirleme: Araç, kullanıcıların doğrudan kullanıcılar, dolaylı olarak etkilenen taraflar ve gelecek nesiller veya çevre sorunları gibi insan dışı faktörler gibi diğer varlıklar da dahil olmak üzere teknolojiden etkilenen çeşitli paydaşları tanımlamalarına ve kategorilere ayırmalarına yardımcı olabilir.
Zarar kategorileri ve açıklamaları: Araç gizlilik kaybı, duygusal sıkıntı veya ekonomik sömürü gibi olası zararların kapsamlı bir listesini içerebilir. Araç kullanıcıya çeşitli senaryolarda yol gösterebilir, teknolojinin bu zararlara nasıl neden olabileceğini gösterebilir ve hem hedeflenen hem de istenmeyen sonuçları değerlendirmeye yardımcı olabilir.
Önem derecesi ve olasılık değerlendirmeleri: Araç, kullanıcıların tanımlanan her zararın önem derecesini ve olasılığını değerlendirmesine yardımcı olabilir. Kullanıcı öncelikle ele alınması gereken sorunları öncelik sırasına ekleyebilir. Kullanılabilir durumdaki veriler tarafından desteklenen nitel değerlendirmeler örnek olarak verilebilir.
Azaltma stratejileri: Araç, zararları tanımlayıp değerlendirdikten sonra olası risk azaltma stratejilerini önerebilir. Örnek olarak sistem tasarımında yapılan değişiklikler, korumalar ekleme ve belirlenen riskleri en aza indiren alternatif teknolojik çözümler verilebilir.
Geri Bildirim mekanizmaları: Araç, zarar değerlendirme sürecinin dinamik ve yeni bilgilere ve perspektiflere yanıt vermesi için paydaşlardan geri bildirim toplama mekanizmaları içermelidir.
Belgeler ve raporlama: Saydamlık ve sorumluluk için, araç zarar değerlendirme sürecini, bulguları ve olası risk azaltma eylemlerini belgeleyen ayrıntılı raporları kolaylaştırabilir.
Bu özellikler riskleri belirlemenize ve azaltmanıza yardımcı olabilir, ancak başlangıçtan itibaren geniş bir etki yelpazesini göz önünde bulundurarak daha etik ve sorumlu yapay zeka sistemleri tasarlamanıza da yardımcı olur.
Daha fazla bilgi için şu makalelere bakın:
Korumaları test etme ve doğrulama
Bu makalede, RAG tabanlı bir sohbet sisteminin kötüye kullanılma veya güvenliğinin aşılması olasılığını azaltmayı amaçlayan çeşitli süreçler özetlenmektedir. Kırmızı ekip oluşturma, azaltmaların etkili olmasını sağlamada önemli bir rol oynar. Kırmızı ekip oluşturma, uygulamadaki olası zayıflıkları veya güvenlik açıklarını ortaya çıkarmak için olası bir saldırgan eylemlerinin benzetimini içerir. Bu yaklaşım özellikle önemli ölçüde jailbreak riskini ele almak için çok önemlidir.
Geliştiricilerin etkili bir şekilde test etmek ve doğrulamak için çeşitli kılavuz senaryoları kapsamında RAG tabanlı sohbet sistemi korumalarını titizlikle değerlendirmesi gerekir. Bu yaklaşım yalnızca sağlamlık sağlamakla kalmaz, aynı zamanda tanımlanan etik standartlara ve operasyonel yordamlara kesinlikle uyması için sistemin yanıtlarında ince ayarlamalar yapmanızı sağlar.
Uygulama tasarımıyla ilgili son noktalar
İşte dikkate alınacak şeylerin kısa bir listesi ve bu makaleden uygulama tasarımı kararlarınızı etkileyebilecek diğer şeyler:
- Tasarımınızda üretken yapay zekanın belirsiz doğasını kabul edin. Çıkışlarda değişkenliği planlayın ve yanıtlarda tutarlılık ve ilgi düzeyini sağlamak için mekanizmalar ayarlayın.
- Gecikme süresi ve maliyetlerdeki olası artışa karşı kullanıcı istemlerini ön işlemenin avantajlarını değerlendirin. Göndermeden önce istemleri basitleştirmek veya değiştirmek yanıt kalitesini artırabilir, ancak yanıt döngüsüne karmaşıklık ve zaman ekleyebilir.
- Performansı geliştirmek için LLM isteklerini paralelleştirme stratejilerini araştırın. Bu yaklaşım gecikme süresini azaltabilir, ancak artan karmaşıklığı ve olası maliyet etkilerini önlemek için dikkatli bir yönetim gerektirir.
Hemen üretken bir yapay zeka çözümü oluşturmaya başlamak istiyorsanız Pythoniçin kendi veri örneğinizi kullanarak sohbete başlama