Büyük Bir Dil Modelini Alma Artırılmış Oluşturma ve İnce Ayarlama ile Geliştirme
Bu serideki makalelerde LLM'lerin yanıtlarını oluşturmak için kullandığı bilgi alma modelleri ele alınıyor. Varsayılan olarak, Büyük Dil Modeli (LLM) yalnızca eğitim verilerine erişebilir. Ancak modeli gerçek zamanlı verileri veya özel verileri içerecek şekilde artırabilirsiniz. Bu makalede, modelin genişletilmesine yönelik iki mekanizmadan biri ele alınmaktadır.
İlk mekanizma, semantik aramayı bağlamsal astarlama ile birleştiren bir ön işleme biçimi olan Alma Artırılmış Nesil (RAG)'dir (başka bir makalede anlatılmaktadır).
İkinci mekanizma , modeli ilk ve geniş eğitimden sonra belirli bir veri kümesi üzerinde daha fazla eğitmek ve bu veri kümesiyle ilgili görevleri daha iyi gerçekleştirmek veya kavramlar anlamak için uyarlamayı sağlayan ince ayardır. Bu işlem, modelin belirli giriş veya etki alanı türlerini işlemede doğruluğunu ve verimliliğini geliştirmesine veya özelleştirmesine yardımcı olur.
Aşağıdaki bölümlerde bu iki mekanizma daha ayrıntılı olarak açıklanmaktadır.
RAG'i anlama
RAG genellikle büyük bir metin içeriğine (iç belgeler, belgeler vb.) sahip olan ve kullanıcı istemlerine yanıtlar için temel olarak bu corpus'u kullanmak isteyen şirketlerin "verilerim üzerinden sohbet" senaryolarını etkinleştirmek için kullanılır.
Yüksek düzeyde, her belge (veya belgenin "öbek" olarak adlandırılan bir bölümü) için bir veritabanı girdisi oluşturursunuz. Öbek, belgenin modellerini temsil eden sayılardan oluşan bir vektör (dizi) olan eklemesinde dizine alınır. Kullanıcı sorgu gönderdiğinde, veritabanında benzer belgeler ararsınız, ardından sorguyu ve belgeleri llm'ye göndererek yanıt oluşturursunuz.
Not
Alma-Artırılmış Nesil (RAG) terimini kabul etmek. Bu makalede özetlenen RAG tabanlı bir sohbet sistemi uygulama süreci, destekleyici kapasitede (RAG) kullanılacak dış verileri kullanma isteği veya yanıtın merkez parçası (RCG) olarak kullanılmak isteyip istemediğinize bakılmaksızın uygulanabilir. Bu nüanslı ayrım RAG ile ilgili çoğu okumada ele alınmaz.
Vektörleştirilmiş belgelerin dizinini oluşturma
RAG tabanlı sohbet sistemi oluşturmanın ilk adımı, belgenin vektör eklemesini (veya belgenin bir bölümünü) içeren bir vektör veri deposu oluşturmaktır. Belgelerin vektörleştirilmiş dizinini oluşturmanın temel adımlarını özetleyen aşağıdaki diyagramı göz önünde bulundurun.

Bu diyagram, sistem tarafından kullanılan verilerin alımından, işlenmesinden ve yönetiminden sorumlu olan bir veri işlem hattını temsil eder. Bu, vektör veritabanında depolanacak ön işleme verilerini ve LLM'ye beslenen verilerin doğru biçimde olmasını sağlamayı içerir.
İşlemin tamamı, girişin anlamsal özelliklerini makine öğrenmesi modelleri tarafından işlenecek şekilde yakalayan verilerin (genellikle sözcükler, tümcecikler, cümleler ve hatta belgelerin tamamının) sayısal bir gösterimi olan ekleme gösterimiyle yönlendirilir.
Ekleme oluşturmak için içerik öbeği (tümceler, paragraflar veya belgelerin tamamı) Azure OpenAI Ekleme API'sine gönderirsiniz. Ekleme API'sinden döndürülenler bir vektördür. Vektördeki her değer içeriğin bir özelliğini (boyutunu) temsil eder. Boyutlar konu başlığı, anlamsal anlam, söz dizimi ve dil bilgisi, sözcük ve tümcecik kullanımı, bağlamsal ilişkiler, stil ve ton gibi konuları içerebilir. Vektördeki tüm değerler birlikte içeriğin boyutsal alanını temsil eder. Başka bir deyişle, üç değere sahip bir vektörünün 3B gösterimini düşünebiliyorsanız, belirli bir vektör x, y, z düzleminin belirli bir alanında yaşar. 1000 (veya daha fazla) değer kullanıyorsanız ne olur? daha anlaşılır hale getirmek için insanların bir kağıda 1000 boyutlu graf çizmesi mümkün olmasa da, bilgisayarların boyutsal alanın bu derecesini anlamakta bir sorunu yoktur.
Diyagramın sonraki adımında, vektörünün içeriğin kendisi (veya içeriğin konumuna yönelik bir işaretçi) ve diğer meta verilerin bir vektör veritabanında depolanması gösterilir. Vektör veritabanı her tür veritabanı gibidir ve iki fark vardır:
- Vektör veritabanları, veri aramak için dizin olarak vektör kullanır.
- Vektör veritabanları, arama ölçütlerine en yakın vektörleri kullanan en yakın komşu olarak da bilinen kosinüs benzeri arama adlı bir algoritma uygular.
Vektör veritabanında depolanan belgelerden oluşan bir grupla, geliştiriciler LLM'ye kullanıcının sorgusunu yanıtlamak için gerekenleri sağlamak için veritabanından kullanıcının sorgusuyla eşleşen belgeleri alan bir retriever bileşeni oluşturabilir.
Belgelerinizle sorguları yanıtlama
RAG sistemi, bir yanıt oluştururken LLM'ye yardımcı olabilecek makaleleri bulmak için önce anlamsal arama kullanır. Sonraki adım, bir yanıt oluşturmak için kullanıcının özgün istemiyle birlikte eşleşen makaleleri LLM'ye göndermektir.
Aşağıdaki diyagramı basit bir RAG uygulaması (bazen "saf RAG" olarak da adlandırılır) olarak düşünün.
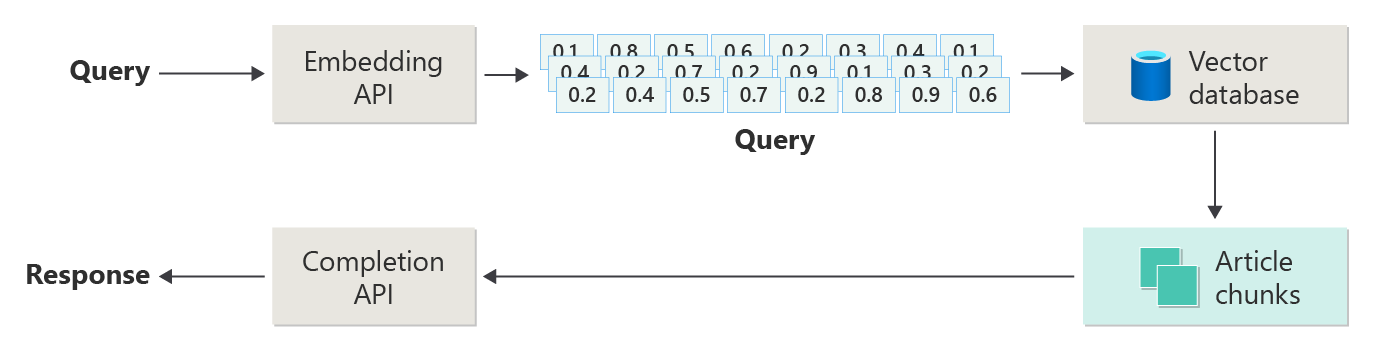
Diyagramda kullanıcı bir sorgu gönderir. İlk adım, kullanıcının vektör geri alma istemi için bir ekleme oluşturmaktır. Sonraki adım, vektör veritabanında "en yakın komşu" eşleşmesi olan belgeleri (veya belgelerin bölümlerini) aramaktır.
Kosinüs benzerliği , aralarındaki açının kosinüsünü değerlendiren iki vektörnün ne kadar benzer olduğunu belirlemek için kullanılan bir ölçüdür. 1'e yakın kosinüs benzerliği yüksek bir benzerlik derecesini (küçük açı), -1'e yakın bir benzerlik ise benzerliği (180 dereceye yaklaşan açı) gösterir. Bu ölçüm, benzer içeriğe veya anlamlara sahip belgeleri bulmak olan belge benzerliği gibi görevler için çok önemlidir.
"En Yakın Komşu" Algoritmaları , vektör alanında belirli bir noktaya en yakın vektörleri (komşular) bularak çalışır. K-nears (KNN) algoritmasında 'k' dikkate alınacak en yakın komşu sayısını ifade eder. Bu yaklaşım, algoritmanın eğitim kümesindeki en yakın 'k' komşularının çoğunluk etiketine göre yeni bir veri noktasının etiketini tahmin ettiği sınıflandırma ve regresyonda yaygın olarak kullanılır. KNN ve kosinüs benzerliği genellikle öneri altyapıları gibi sistemlerde birlikte kullanılır ve burada amaç, ekleme alanında vektör olarak temsil edilen kullanıcının tercihlerine en benzer öğeleri bulmaktır.
Bu aramadan en iyi sonuçları alır ve eşleşen içeriği kullanıcının eşleşen içerikle bilgilendirilen bir yanıt oluşturma istemiyle birlikte gönderirsiniz.
Zorluklar ve Dikkat Edilmesi Gerekenler
RAG sisteminin uygulanması, bir dizi güçlükle birlikte gelir. Özellikle dış kaynaklardan bilgi alıp işlerken sistemin kullanıcı verilerini sorumlu bir şekilde işlemesi gerektiğinden veri gizliliği çok önemlidir. Hem alma hem de oluşturma işlemleri yoğun kaynak kullanımlı olduğundan hesaplama gereksinimleri de önemli olabilir. Verilerde veya modelde var olan sapmaları yönetirken yanıtların doğruluğunu ve ilgi düzeyini sağlamak da önemli bir diğer önemli noktadır. Geliştiricilerin verimli, etik ve değerli RAG sistemleri oluşturmak için bu zorluklarda dikkatli bir şekilde gezinmesi gerekir.
Bu serideki bir sonraki makale olan Gelişmiş Alma-Artırılmış Nesil sistemleri oluşturma, üretime hazır bir RAG sistemini etkinleştirmek için veri oluşturma ve çıkarım işlem hatları hakkında daha fazla ayrıntı sağlar.
Hemen üretken bir yapay zeka çözümü oluşturmaya başlamak istiyorsanız Python için kendi veri örneğinizi kullanarak sohbeti kullanmaya başlama bölümüne göz atmanızı öneririz. Öğreticinin .NET, Java ve JavaScript sürümlerinde de kullanılabilir.
Modelde ince ayarlama
LLM bağlamında ince ayarlama, başlangıçta büyük ve çeşitli bir veri kümesinde eğitildikten sonra modelin parametrelerini etki alanına özgü bir veri kümesinde ayarlama işlemini ifade eder.
LLM'ler geniş bir veri kümesi üzerinde eğitilir (önceden eğitilir), dil yapısını, bağlamı ve çok çeşitli bilgileri kavrar. Bu aşama genel dil desenlerini öğrenmeyi içerir. İnce ayar, daha küçük, belirli bir veri kümesini temel alarak önceden eğitilen modele daha fazla eğitim ekliyor. Bu ikincil eğitim aşaması, modeli belirli görevlerde daha iyi performans sergileyerek veya belirli etki alanlarını anlayarak bu özel uygulamalar için doğruluğunu ve ilgi düzeyini artıracak şekilde uyarlamayı amaçlar. İnce ayarlama sırasında modelin ağırlıkları, bu küçük veri kümesinin nüanslarını daha iyi tahmin etmek veya anlamak için ayarlanır.
Dikkat edilmesi gereken birkaç nokta:
- Özelleştirme: İnce ayar, modeli yasal belge analizi, tıbbi metin yorumlama veya müşteri hizmetleri etkileşimleri gibi belirli görevlere göre uyarlar. Bu, modelin bu alanlarda daha etkili olmasını sağlar.
- Verimlilik: Belirli bir görev için önceden eğitilmiş bir modelde ince ayar yapmak, modeli sıfırdan eğitmekten daha verimlidir çünkü ince ayarlama daha az veri ve işlem kaynağı gerektirir.
- Uyarlanabilirlik: hassas ayarlama, özgün eğitim verilerinin parçası olmayan yeni görevlere veya etki alanlarına uyum sağlar ve LLM'leri çeşitli uygulamalar için çok yönlü araçlar haline getirir.
- Geliştirilmiş performans: Modelin ilk eğitildiği verilerden önemli ölçüde farklı görevler için, modeli yeni etki alanında kullanılan belirli bir dili, stili veya terminolojiyi anlamak üzere ayarladığı için ince ayarlama daha iyi performansa yol açabilir.
- Kişiselleştirme: Bazı uygulamalarda ince ayar, modelin yanıtlarını veya tahminlerini kullanıcının veya kuruluşun belirli gereksinimlerine veya tercihlerine uyacak şekilde kişiselleştirmeye yardımcı olabilir. Bununla birlikte, ince ayarlama bazı dezavantajları ve sınırlamaları da sunar. Bunları anlamak, alma artırılmış nesil (RAG) gibi alternatiflere göre ince ayarlamayı ne zaman seçebileceğinize karar verirken yardımcı olabilir.
- Veri gereksinimi: hassas ayarlama, hedef göreve veya etki alanına özgü yeterince büyük ve yüksek kaliteli bir veri kümesi gerektirir. Bu veri kümesinin toplanması ve küratörleştirilmesi zor ve yoğun kaynak kullanımlı olabilir.
- Fazla uygunluk riski: Özellikle küçük bir veri kümesinde fazla uygunluk riski vardır. Fazla uygunluk, modelin eğitim verileri üzerinde iyi performans göstermesini ancak yeni, görünmeyen veriler üzerinde kötü performans göstermesini sağlayarak genelleştirilebilirliğini azaltır.
- Maliyet ve kaynaklar: Sıfırdan eğitime kıyasla daha az kaynak yoğunluklu olsa da, ince ayarlama işlemi, özellikle büyük modeller ve veri kümeleri için hesaplama kaynakları gerektirir ve bu da bazı kullanıcılar veya projeler için yasaklayıcı olabilir.
- Bakım ve güncelleştirme: Hassas ayarlı modellerin, etki alanına özgü bilgiler zaman içinde değiştikçe etkili olmaya devam etmek için düzenli güncelleştirmelere ihtiyacı olabilir. Bu devam eden bakım için ek kaynaklar ve veriler gerekir.
- Model kayması: Model belirli görevler için ince ayarlı olduğundan, genel dil anlayışını ve çok yönlülüğünü kaybedebilir ve model kayağı olarak bilinen bir fenomene yol açar.
Modeli ince ayar ile özelleştirme, modelin nasıl ince ayar yapılacağını açıklar. Yüksek düzeyde, olası sorular ve tercih edilen yanıtlardan oluşan bir JSON veri kümesi sağlarsınız. Belgelerde 50 ila 100 soru/yanıt çifti sağlanarak fark edilebilir iyileştirmeler olduğu belirtilmektedir, ancak doğru sayı kullanım örneğine göre büyük ölçüde farklılık gösterir.
Alma artırılmış oluşturma ile ince ayar karşılaştırması
Yüzeyde, ince ayar ve alma artırılmış oluşturma arasında oldukça fazla çakışma var gibi görünebilir. İnce ayar ve alma artırılmış oluşturma arasında seçim yapmak, performans beklentileri, kaynak kullanılabilirliği ve etki alanı özgüllüğü ile genelleştirilebilirlik gereksinimi dahil olmak üzere görevinizin belirli gereksinimlerine bağlıdır.
Alma-Artırılmış Oluşturma yerine ince ayarlamayı tercih etme zamanı:
- Göreve Özgü Performans - Belirli bir görevde yüksek performans kritik öneme sahip olduğunda ve modeli önemli fazla uygunluk risklerine gerek kalmadan etkili bir şekilde eğitmek için yeterli etki alanına özgü veriler varsa, ince ayar tercih edilir.
- Veriler Üzerinde Denetim - Temel modelin eğitildiği verilerden önemli ölçüde farklı özel veya yüksek oranda özelleştirilmiş verileriniz varsa, ince ayar bu benzersiz bilgiyi modele dahil etmenizi sağlar.
- Gerçek Zamanlı Güncelleştirmeler için Sınırlı Gereksinim - Görev modelin en son bilgilerle sürekli güncelleştirilmesi gerekmiyorsa, RAG modellerinin güncel dış veritabanlarına veya son verileri çekmek için İnternet'e erişmesi gerektiğinden ince ayarlama daha verimli olabilir.
Ne zaman ince ayar yerine Alma Artırılmış Oluşturma tercih edilir:
- Dinamik veya Gelişen İçerik - RAG, en güncel bilgilere sahip olmanın kritik olduğu görevler için daha uygundur. RAG modelleri gerçek zamanlı olarak dış kaynaklardan veri çekebildiğinden, haber oluşturma veya son olaylarla ilgili soruları yanıtlama gibi uygulamalar için daha uygundur.
- Özelleştirme Üzerinde Genelleştirme - Amaç dar bir etki alanında üstünlük sağlamak yerine çok çeşitli konularda güçlü performans sağlamaksa RAG tercih edilebilir. Dış bilgi bankası kullanarak belirli bir veri kümesine fazla uygunluk riski olmadan farklı etki alanlarında yanıtlar oluşturmasına olanak sağlar.
- Kaynak Kısıtlamaları - Veri toplama ve model eğitimi için kaynakları sınırlı olan kuruluşlarda, ÖZELLIKLE temel model istenen görevlerde makul bir performans sergilediyse, RAG yaklaşımı kullanmak ince ayarlamaya uygun maliyetli bir alternatif sunabilir.
Uygulama tasarımı kararlarınızı etkileyebilecek son noktalar
İşte dikkate alınacak şeylerin kısa bir listesi ve bu makaleden uygulama tasarımı kararlarınızı etkileyen diğer şeyler:
- Uygulamanızın özel gereksinimlerine göre ince ayar ve alma artırılmış oluşturma arasında karar verin. hassas ayarlamalar özel görevler için daha iyi performans sunarken, RAG dinamik uygulamalar için esneklik ve güncel içerik sağlayabilir.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin